The book "Working with BigData in the clouds. Processing and storing data with examples from Microsoft Azure »
 Before you - the first initially Russian-language book, in which the real examples deal with the secrets of big data processing (Big Data) in the clouds.
Before you - the first initially Russian-language book, in which the real examples deal with the secrets of big data processing (Big Data) in the clouds.The focus is on Microsoft Azure and AWS solutions. We consider all stages of work - obtaining data prepared for processing in the cloud, the use of cloud storage, cloud-based data analysis tools. Particular attention is paid to the SAAS services, demonstrating the advantages of cloud technologies compared to solutions deployed on dedicated servers or in virtual machines.
The book is designed for a wide audience and will serve as an excellent resource for the development of Azure, Docker and other essential technologies, without which a modern enterprise is unthinkable.
')
We offer you to familiarize yourself with the passage "Direct download of streaming data"
10.1. Common architecture
In the previous chapter, we looked at the situation where a multitude of client applications have to send a large number of messages that need to be dynamically processed, put into storage and then processed again in it. At the same time, it is necessary to be able to change the logic of the data processing and storage flow, without resorting to changing the client code. And finally, from the point of view of security considerations, clients should have the right to do only one thing - send messages or receive them, but in no way read the data or delete the bases, and they should not have direct rights to record this data.
Similar tasks are very common in systems that work with IoT devices connected via an Internet connection, as well as in online log analysis systems. In addition to the above requirements for our dedicated service, there are two more requirements related to the specifics of the “Internet of things” and to ensure reliable processing of messages. First of all, the interaction protocol between the client and the service receiver must be very simple, so that it can be implemented on a device with limited computing capabilities and with very limited memory (for example, the Arduino platform, Intel Edison, STM32 Discovery and other “non-binding”, such as before RaspberryPi). The next requirement is reliable message delivery, regardless of possible failures of processing services. This is a stronger requirement than high reliability. Indeed, to ensure the overall reliability of the entire system, it is necessary that the reliability of all its components be high enough and the addition of a new component does not lead to a noticeable increase in the number of failures. In addition to the failure in the cloud infrastructure, there may be an error in the service created by the user. And even then the message should be processed as soon as the user service is restored. To do this, the message receiving service must reliably store the message until it has been processed or until its lifetime has expired (this is necessary to prevent memory overflow with a continuous message flow). A service with these properties is called a message hub (Event Hub). For IoT devices, there are specialized hubs (IoT Hub) that have a number of other properties that are very important for use in conjunction with “Internet of things” devices (for example, bidirectional communication from one point, built-in message routing, digital twins) of the device and others). However, these services are still specialized, and we will not consider them in detail.
Before turning to the concept of message concentration, we turn to the ideas underlying it.
Suppose we have a source of messages (for example, requests coming from a client) and a service that must process them. Processing a separate request takes time and requires computational resources (CPU, memory, IOPS). Moreover, during the processing of a single request, other requests cannot be processed. In order for client applications not to hang while waiting for the service to be released, it is necessary to separate them with the help of an additional service that will be responsible for intermediate storage of messages while they are waiting for processing while in the queue. This separation is also necessary to increase the overall reliability of the system. Indeed, the client sends a message to the system, but the processing service may “fall”, but the message should not be lost, it should be saved in a service that has greater reliability than the processing service. The simplest version of this service is called the queue (fig. 10.1).
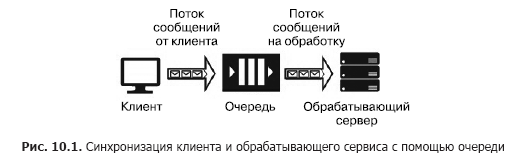
The queue service works as follows: the client knows the URL of the queue and has access keys to it. Using the SDK or the queue API, the client places in it a message containing in its composition a timestamp, an identifier, and a message body with a payload in JSON, XML or binary format.
The service program code includes a loop that “listens” to the queue, retrieving the next message at each step, and if there is a message in the queue, then it is retrieved and processed. If the service processes the message successfully, it is removed from the queue. If an error occurs during processing, it is not deleted and can be processed again when the new version of the service, with the corrected code, is launched. The queue is designed to synchronize one client (or a group of similar clients) and exactly one processing service (although the latter may be located on a server cluster or on a server farm). Cloud queuing services include Azure Storage Queue, Azure Service Bus Queue and AWS SQS. The services hosted on virtual machines include RabbitMQ, ZeroMQ, MSMQ, IBM MQ, and others.
Different queue services guarantee different types of message delivery:
- at least one-time delivery of the message;
- strictly single delivery;
- delivery of messages with preservation of the order;
- message delivery without order.
The queue provides reliable delivery of messages from one source to one processing service, that is, one-to-one interaction. But what if you need to ensure the delivery of messages to several services? In this case, you need to use a service called “topic” (topic) (Fig. 10.2).
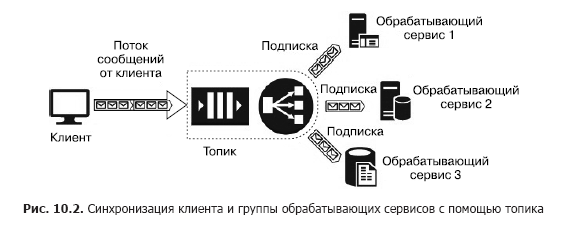
An important element of such an architecture is “subscriptions”. This is the path that the message is sent to in the section. Messages are published in the topic by the client and transmitted to one of the subscriptions, from which they are retrieved by one of the services and processed by them. Topics provide a one-to-many architecture for client and service interaction. Examples of such services include the Azure Service Bus Topic and AWS SNS.
And now suppose that there are a large number of disparate customers who have to send many messages to various services, that is, you need to build a “many to many” interaction system. Of course, such an architecture can be built using several sections, but such a construction is not scalable and requires effort for administration and monitoring. However, there are separate services - message concentrators (Fig. 10.3).
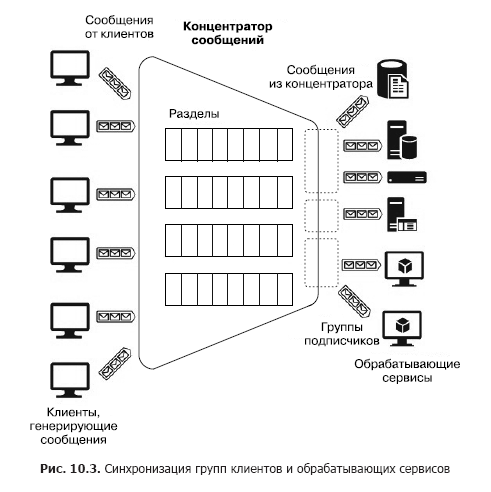
A hub accepts messages from many clients. All clients can send messages to one common service endpoint or connect separately to different endpoints via special keys. These keys allow you to flexibly manage clients: disconnect some, connect new ones, etc. There are also partitions inside the hub. But in this case, they can be distributed among all clients in order to increase productivity (round robin - “with a cyclic addition”) or the client can publish messages in one of the sections. On the other hand, processing services are grouped into groups of consumers (consumer group). One or several services can be connected to one group. Thus, a message hub is the most flexible service that can be configured as a queue, section or group of queues, or a set of sections. In general, a message hub provides a many-to-many scheme between clients and services. These hubs include Apache Kafka, Azure Event Hub and AWS Kinesis Stream.
Before we look at the cloud PaaS services, let's pay attention to a very powerful and well-known service - Apache Kafka. In cloud environments, it can be accessed as a distribution kit deployed in a virtual machine cluster directly or through the HDInsight service. So, Apache Kafka is a service that provides the following features:
- posting and subscribing to a message flow;
- reliable storage of messages;
- use of third-party services for streaming message processing.
Physically, Kafka runs in a cluster of one or more servers. Kafka provides an API for interacting with external clients (Figure 10.4).
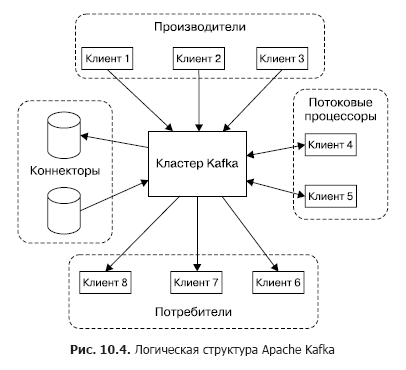
Consider these APIs in order.
- Manufacturer APIs allow client applications to publish message flows in one or more Kafka topics.
- Consumer APIs allow client applications to subscribe to one or more topics and process message flows delivered by topics to customers.
- Stream Processor APIs allow applications to interact with a Kafka cluster as a stream processing engine. Sources for one processor can be one or several topics. At the same time, processed messages are also placed in one or several topics.
- Connector APIs help connect external data sources (for example, DDB) as sources of messages (for example, interception of data change events in the database is possible) and as receivers.
In Kafka, the interaction between clients and the cluster occurs via TCP, which is facilitated by the existing SDKs for various programming languages, including .Net. But the basic languages of the SDK are Java and Scala.
In a cluster, the storage of message flows (in Kafka terminology, also referred to as records) occurs logically in objects called topics (Fig. 10.5). Each entry consists of a key, a value, and a timestamp. In essence, a topic is a sequence of records (messages) that have been published by customers. Kafka topics support from 0 to several subscribers. Each topic is physically represented as a partitioned log. Each section is an ordered sequence of records, to which new ones are constantly added to the input of Kafka.
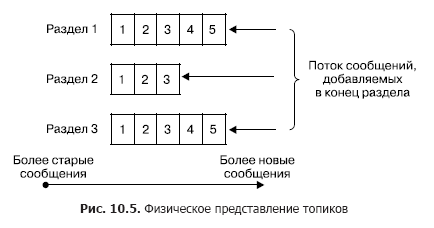
Each entry in the section corresponds to a number in the sequence, also called an offset, which uniquely identifies the message in the sequence. Unlike the queue, Kafka deletes the message not after processing the service, but after the lifetime of the messages. This is a very important feature that provides the ability to read from one topic to different consumers. Moreover, an offset is associated with each consumer (Fig. 10.6). And each reading act only leads to an increase in the value for each client individually and is determined by the client.
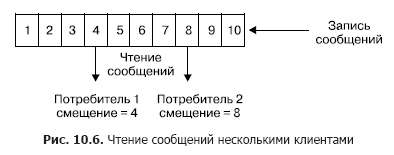
In the normal case, this offset is increased by one after successfully reading one message from the topic. But if necessary, the client can shift this offset and repeat the read operation.
The use of the concept of sections has the following objectives.
First, sections provide the ability to scale topics in the case when one topic does not fit within a single node. At the same time, each section has one master (do not confuse it with the head node of the entire cluster) a node and zero or several successor nodes. The head node is responsible for processing read-write operations, while followers are passive copies. If the lead node fails, one of the follower nodes will automatically become the head. Each cluster node is head for some sections and a follower for others. Secondly, such replication increases reading performance due to the possibility of parallel read operations.
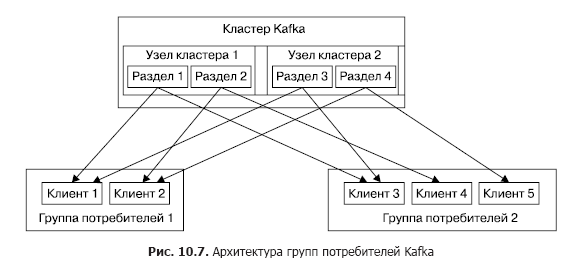
The manufacturer can place the message in any topic of his choice either explicitly or in the round robin mode implicitly (that is, with a uniform filling). Consumers are united in the so-called consumer groups, and each message published in the topic is delivered to one customer in each consumer group. Clients in this case can be physically located on one or several servers / virtual machines. More detailed message delivery is as follows. For all customers belonging to the same consumer group, messages can be distributed among customers in order to optimize the load. If customers belong to different consumer groups, then each message will be sent to each group. The separation of messages from sections into different groups of consumers is shown in Fig. 10.7.
Now briefly describe the basic parameters of delivery and storage of messages, guaranteed by Kafka.
- Messages sent by the manufacturer to a specific topic will be added strictly in the order in which they were sent.
- The client sees the order of messages in the topic, which was received when saving messages. As a result, the delivery of messages from the manufacturer to the consumer is made strictly in the order of their receipt.
- N-fold replication of the topic ensures the resistance of the topic to the failure of N - 1 nodes without loss of efficiency.
So, the Apache Kafka service can be used in the following modes.
- Service - message broker (queue) or publication service - message subscriptions (topic). Indeed, at the core of Kafka is a group of topics, which can be transformed into a queue with one subscriber. (It should be remembered: unlike conventional message broker services, built on the queuing principle, Kafka deletes messages only after its lifetime has passed, while Peek-Delete, ie, extraction and deletion, is implemented after successful processing. ) The principle of consumer groups summarizes these two concepts, and the ability to publish messages in all topics with round robin distribution makes Kafka a universal multimode message broker.
- Service streaming message analysis. This is possible thanks to the Kafka API for stream processors, which allows you to build complex systems created on the principle of Event Driven, with services that filter messages or react to them, as well as services that aggregate messages.
All of these properties allow Kafka to be used as a key component of a streaming data platform that is highly capable of building complex message flow processing systems. But at the same time, Kafka is quite complicated in terms of deploying and configuring a cluster of several nodes, which requires substantial administrative efforts. But, on the other hand, since the ideas underlying Kafka are very well suited for building systems, streaming and processing messages, cloud providers provide PaaS services that implement these ideas and hide all the complexities of building and administering a Kafka cluster. But since these services have a number of restrictions in terms of customization and expansion beyond the limits allocated for services, cloud providers provide special IaaS / PaaS services for the physical deployment of Kafka in a virtual machine cluster. In this case, the user has almost complete freedom of configuration and expansion. These services include Azure HDInsight. He has already been mentioned above. It was created to, on the one hand, provide the user with services from the Hadoop ecosystem on their own, without external wrappers, and on the other, relieve them of the difficulties that arise during the direct installation, administration and configuration of IaaS. Docker-hosting stands a little apart. Since this is an extremely important topic, we will look at it, but first we will get acquainted with PaaS-services implemented using the basic concepts of Kafka.
10.2. Azure Event Hub
Consider the Azure Event Hub message hub service. It is a service built on the PaaS model. Different groups of clients can act as sources of messages for Azure Event Hub (Fig. 10.8). First of all, this is a very large group of cloud services, whose outputs or triggers can be configured to send messages directly to the Event Hub. These can be Stream Analytics Job, Event Grid, and a significant group of services that redirect events — logs in the Event Hub (primarily built using the AppService: Api App, Web App, Mobile App and Function App).
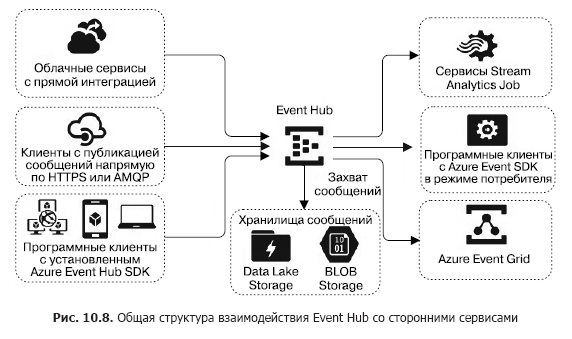
Messages delivered to the hub can be captured directly and placed in the Blob Storage or Data Lake Store.
The next group of sources is external software clients or devices for which there is no Azure Event Hub SDK and which cannot be directly integrated with Azure services. These clients primarily include IoT devices. They can send messages to the Event Hub entry using HTTPS or AMQP protocols. Considering how to connect these devices is beyond the scope of this book.
Finally, software clients that generate messages and send them to the Event Hub, using the Azure Event Hub SDK. This group includes Azure PowerShell and Azure CLI.
Stream analytics job streaming analytics services or the Event Grid integration service can act as message receivers (consumers - “consumers”) from the Event Hub. In addition, software clients can receive messages using the Azure Event Hub SDK. Consumers connect to the Event Hub using the AMQP 1.0 protocol.
Consider the basic concepts of Azure Event Hub, which are necessary for understanding how to use and configure it. Any source (in the documentation also referred to as publisher) who sends a message to a hub must use HTTPS or AMQP 1.0. The choice of a particular protocol is determined by the type of client, communication network and message transfer rate requirements. AMQP needs to create a permanent connection between two bidirectional TCP sockets. It is protected by using the TLS or SSL / TLS transport layer encryption protocol. All this means, in particular, that for the initial connection establishment, the AMQP protocol takes more time than HTTPS, but with a constant message flow, the first one has much better performance. With rare messages, HTTPS is preferred.
In order to identify themselves, sources can use identification mechanisms based on the SAS (Shared Access Signature) tokens mechanism. In the simplest case, all publishers can apply one common SAS token to all or use a flexible distribution policy for different SAS tokens for different publishers. In addition to the separation of sources by different SAS tokens, the division by key of the section is used (more on this below).
Each source can send a message of no more than 256 KB. This means that you need to split a long message into several messages sent in sequence or switch to a binary format and use data compression.
Now consider how the message is processed directly in the Event Hub. As mentioned in the previous chapter, the concept of message hubs is based on a group of topics that have entry points and multiple exits to which consumer subscribers can connect. In the case of EventHub, such topics are referred to as partitions. Conceptually, EventHub sections are an ordered sequence of messages organized according to the “first in, first out” (FIFO) queue principle (Figure 10.9).
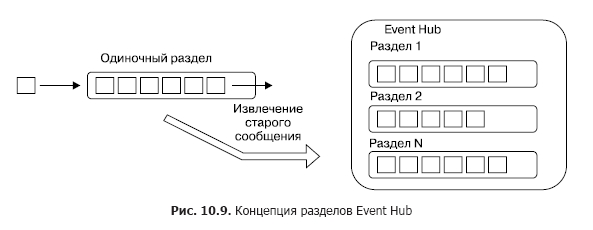
Each section is an independent sequence of messages within the entire Event Hub. One Event Hub can include from 2 to 32 sections, and this value cannot be changed after creating the Event Hub. It is very important to understand that the number of SIMULTANEOUS retrieved messages from a hub is equal to the number of sections.
Messages in the section (and in fact in the queue) are stored until the consumer retrieves it (it is not deleted, but ceases to be available - see below), or until a certain storage time (retention period), which may tune up. It should be clarified. In any case, the message is physically deleted only after the storage time has expired. To provide the ability to read messages from a section, the concept of offset is implemented in Azure Event Hub. The offset in this case is the position in the section that shows the current position for reading, that is, in essence, the cursor with the number of the current readable position. After successfully retrieving the message, the consumer shifts the cursor one position. Azure Event Hub SDK allows you to set an arbitrary position from which you can read messages, but this is not recommended. In this case, the client-consumer is responsible for the storage of the bias, and he himself must store and update this value.

Thus, the consumer can read the same message several times, but only if he will each time indicate the offset corresponding to the position of this message. However, standard Azure Event Hub SDKs by default exclude this possibility because they provide a mechanism for safe storage and updating of the offset. As a rule, Storage Account is used to store the offset. Azure services, which are message listeners from Event Hub, take responsibility for storing messages.
Each section within the Event Hub has its own partition key (partition key), which allows you to send messages from specific sources to a specific section. The purpose of this action - the organization of message flows. For example, a hub contains many sections and sources of different performance (the number of messages per unit of time) and you need to create a dedicated channel with the publication and reading of messages. If the source does not explicitly specify a partition key, then they are distributed between partitions evenly (round robin).
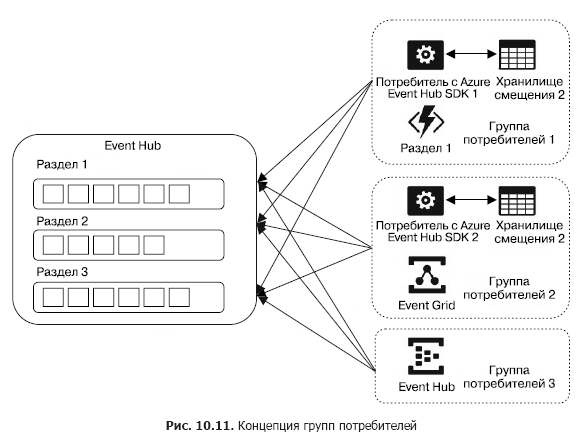
Now consider the issue of extracting messages from the hub. All consumers logically coalesce into groups that are managed jointly and are called the consumer group (Fig. 10.11). Groups allow independent reading from the same sections by different users. In addition, each group gives each client application the opportunity to have its own view (the magnitude of the current offsets for each section) and, thus, independently read the data from the sections. For each group of consumers, such views are completely different, which allows for the implementation of complex data processing scenarios. The maximum number of consumer groups is 20, while in each group there can be no more than five actual consumers, and only one consumer from the group can read a message from the section at a time.
The division of the hub into sections provides parallel reading of messages by many consumers. In addition, the performance of the hub in terms of receiving a specified number per unit of time can be adjustable. For this, there is a parameter called the throughput unit. Each unit of bandwidth includes the following values:
- for the input stream - 1 MB per second or 1000 messages per second (depending on which of these limits will be reached first);
- for the output stream - 2 MB per second.
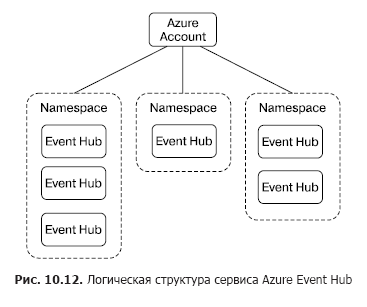
The specific amount of bandwidth is configured for each hub separately. If sources exceed the allowable bandwidth, an exception is thrown. In this case, the receiver simply cannot receive messages faster than the specified value. Bandwidth units also affect the cost of using the service. Be careful! You should be aware that there are bandwidth limits allocated to the namespace, and not to individual instances of the Event Hub service.
Message hubs are logically grouped into namespaces (Figure 10.12).
»More information about the book can be found on the publisher's website.
» Table of Contents
» Excerpt
For Habrozhiteley a 20% discount on the coupon - BigData
Source: https://habr.com/ru/post/428375/
All Articles