Generating arbitrary realistic entities using AI
Controlled image synthesis and editing using the new TL-GAN model
An example of controlled synthesis in my TL-GAN model (transparent latent-space GAN, generative-contention network with transparent hidden space)
All code and online demos are available on the project page .
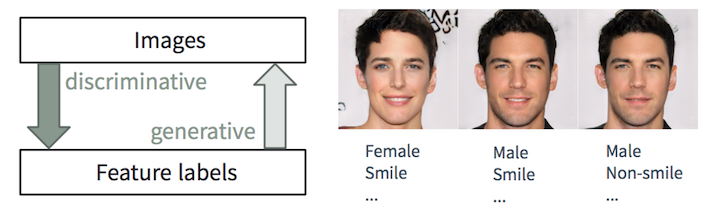
Discriminant and Generative Tasks
')
It is easy for a person to describe a picture, we learn to do it from a very early age. In machine learning, this is a discriminant classification / regression problem, i.e. prediction of features from input images. Recent advances in ML / AI methods, especially in deep learning models, begin to succeed in these tasks, sometimes reaching or exceeding human abilities, as shown in tasks like visual object recognition (for example, from AlexNet to ResNet by ImageNet classification) and detection / segmentation objects (for example, RCNN to YOLO in the COCO data set), etc.
However, the inverse problem of creating realistic images from the description is much more complicated and requires many years of training in graphic design. In machine learning, this is a generative task that is much more complex than discriminatory tasks, since the generative model must generate much more information (for example, a complete image at some level of detail and variation) based on smaller source data.
Despite the complexity of creating such applications, generative models (with some controls) are extremely useful in many cases:
This article will tell you about our recent work called Transparent Latent-space GAN (TL-GAN) , which extends the functionality of the most modern models, providing a new interface. We are currently working on a document with more technical details.
The deep learning community is rapidly improving generative models. Among them are three promising types: autoregression models , variational autoencoders (VAE) and generative adversarial networks (GAN) , shown in the figure below. If you are interested in the details, please read the excellent article on the OpenAI blog.

Comparison of generative networks. Image from STAT946F17 at the University of Waterloo
At the moment, the highest quality images generate GAN networks (photorealistic and diverse, with convincing details in high resolution). Look at the stunning images created by pg-GAN ( progressively growing GAN ) from Nvidia. Therefore, in this article we will focus on the GAN models.

Synthetic images generated by the Nvidia pg-GAN network. None of the images are related to reality.

Random and controlled image generation
The original version of the GAN and many popular models based on it (such as DC-GAN and pg-GAN ) are unsupervised learning models. After training, the generative neural network accepts random noise as input data and creates a photorealistic image that is barely distinguishable from the training data set. However, we cannot additionally control the features of the generated images. In most applications (for example, in the scenarios described in the first section), users would like to create patterns with arbitrary attributes (for example, age, hair color, facial expression, etc.) Ideally, smoothly adjust each function.
Numerous variants of GAN have been created for such controlled synthesis. They can be divided into two types: the style transfer networks and conditional generators.
CycleGAN and pix2pix style transfer networks are trained to transfer an image from one area (domain) to another: for example, from horse to zebra, from sketch to color images. As a result, we cannot smoothly change a specific feature between two discrete states (for example, add a little beard on the face). In addition, one network is designed for one type of transmission, so ten different neural networks will be required to configure ten functions.
Conditional generators - conditional GAN , AC-GAN and Stack-GAN - in the process of learning simultaneously study the images and object labels, which allows you to generate images with the setting of signs. When you want to add new features to the generation process, you need to retrain the entire GAN model, which requires huge computational resources and time (for example, from several days to weeks on a single K80 graphics processor with the ideal set of hyperparameters). In addition, to perform the training, you must rely on one data set containing all user-defined object labels, rather than using different labels from multiple data sets.
Our generative-contention network with transparent hidden space ( GAR , TL-GAN) uses a different approach for controlled generation - and solves these problems. It offers the ability to seamlessly configure one or more features using one network . In addition, you can effectively add new customizable features in less than one hour.
Take the Nvidia pg-GAN model, which generates high-resolution photorealistic images of individuals, as shown in the previous section. All features of the generated 1024 × 1024px image are determined exclusively by the 512-dimensional noise vector in the hidden space (as a low-dimensional representation of the image content). Therefore, if you understand what constitutes a hidden space (that is, to make it transparent), then you can fully control the generation process .

TL-GAN Motivation: Understand the Hidden Space to Manage the Generation Process
Experimenting with the pre-trained pg-GAN network, I discovered that the hidden space actually has two good properties:
Intuition says that in the hidden space there are directions that predict the signs we need (for example, a man / woman). If so, then the unit vectors of these directions will become axes for controlling the generation process (more masculine or more feminine face).
To find these axis of signs in the hidden space, we construct a connection between the hidden vector and marks of signs with training with a teacher on pairs . Now the problem is how to get these pairs, since existing data sets contain only images and their corresponding object labels .
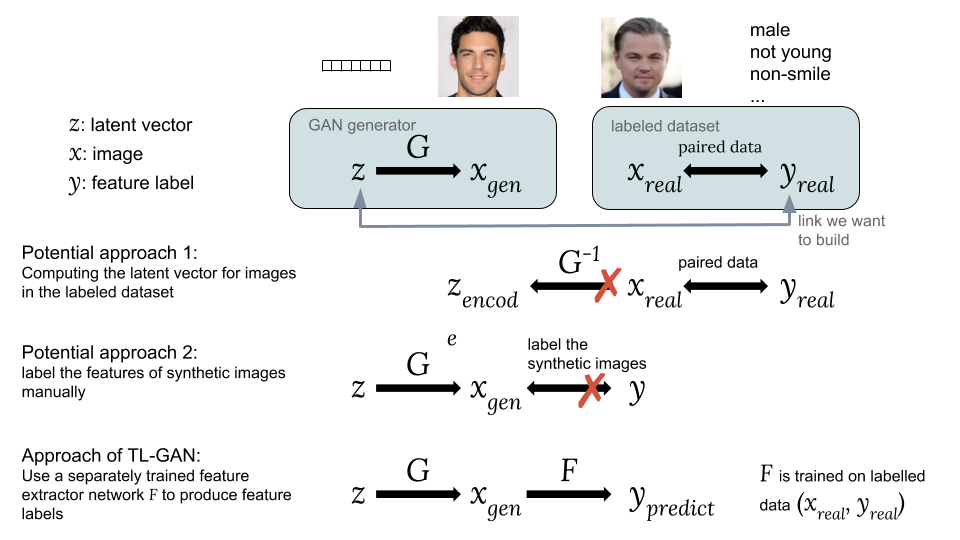
Ways to associate the hidden vector z with the tag of the sign y
Possible approaches:
One option is to compute the corresponding hidden vectors. of images from existing dataset with tags of interest to us . However, the GAN does not provide a simple way to calculate , which makes it difficult to implement this idea.
The second option is to generate synthetic images using GAN from random hidden vector as . The problem is that synthetic images are not tagged, so it is difficult to use the available set of tagged data.
The main innovation of our TL-GAN model is the training of a separate extractor (classifier for discrete labels or a regressor for continuous) with a model using an existing set of tagged data ( , ), and then launch in a bundle of trained GAN-generator with feature extraction network . This allows you to predict the signs of signs. synthetic images using a trained trait extraction network (extractor). Thus, by means of synthetic images, a connection is established between and as and .
Now we have a paired hidden vector and signs. You can train the regressor model , to reveal all the axis of the signs to control the process of generating images.
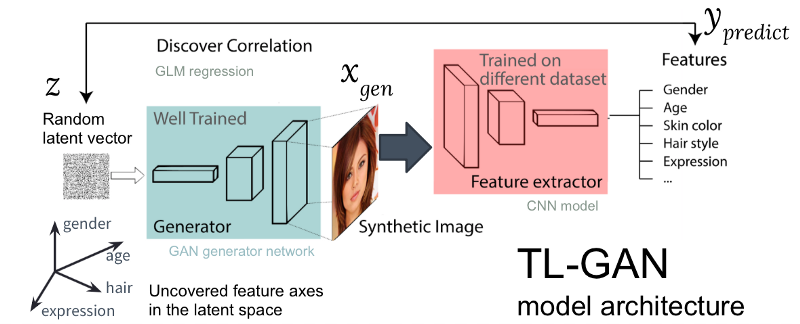
Figure: architecture of our TL-GAN model
The figure above shows the architecture of the TL-GAN model, which contains five steps:
I have significantly optimized the process: on a pre-trained GAN model, identification of the axes of spatial objects takes only an hour on a machine with a single GPU. This is achieved through several engineering tricks, including transferring training, reducing the size of pictures, pre-caching synthetic images, etc.
Let's see how this simple idea works.
First, I checked whether the detected axis of the signs can be used to control the corresponding attribute of the generated image. To do this, create a random vector. in the hidden space GAN and generate a synthetic image by passing it through the generative network . Then move the hidden vector along one axis of signs. (a single vector in a hidden space, say, the corresponding half of the face) at a distance in a new position and generate a new image . Ideally, the corresponding feature of the new image should change in the expected direction.
The results of moving the vector along several axes of signs (gender, age, etc.) are presented below. This works surprisingly well! You can smoothly transform an image between a man / woman, boy / old man, etc.

The first results of moving the hidden vector along the tangled axis of the signs
In the examples above, there is a lack of the original method, namely the tangled axis of signs. For example, when you need to reduce facial hair, the generated faces become more feminine, which is not the expected result. The problem is that gender and beard are inherently correlated . A change in one trait leads to a change in another. Similar things have happened with other features, such as hairstyle and curly hair. As shown in the figure below, the original axis of the “beard” feature in the hidden space is not perpendicular to the “sex” axis.
To solve the problem, I used simple linear algebra techniques. In particular, he projected a beard axis onto a new direction, orthogonal to the sex axis, which effectively eliminates their correlation and, thus, can potentially unravel these two signs on the generated faces.
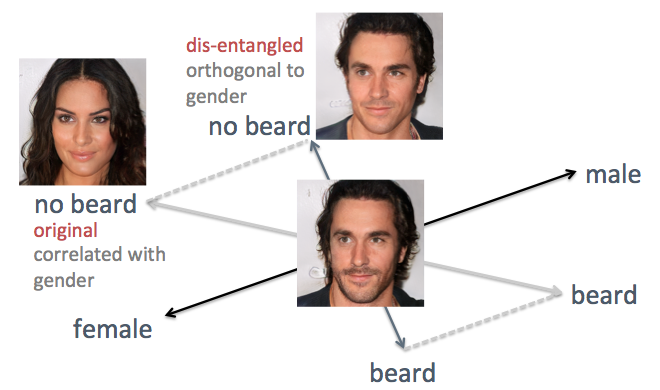
Unraveling the correlated axes of features by linear algebra techniques
I applied this method to the same person. This time, the axes of gender and age are chosen as reference ones, projecting all other axes so that they become orthogonal to gender and age. Persons are generated with the movement of the hidden vector along the newly generated axis of the signs (shown in the figure below). As expected, now signs like hairstyles and beards do not affect the floor.

Improved result of moving a latent vector along disentangled feature axes
To see how flexible our TL-GAN model is able to manage the image generation process, I created an interactive graphical interface with smooth changes in the values of objects along different axes, as shown below.
Interactive editing with TL-GAN
And again, the model works surprisingly well, if you change the images along the axis of the signs!
This project demonstrates a new method of managing a generative model without a teacher, such as the GAN (generative adversarial network). Using a previously well-trained GAN generator (pg-GAN from Nvidia), I made its hidden space transparent by displaying the axes of significant features. When a vector moves along such an axis in a hidden space, the corresponding image is transformed along this feature, providing controlled synthesis and editing.
This method has clear advantages:
This work allows for detailed control of image generation, but it still largely depends on the characteristics of the data set. Studying on photos of Hollywood stars means that the model will very well generate photos of mostly white and attractive people. This will lead users to create faces representing only a small part of humanity. If we deploy this service as a real application, then it is desirable to expand the original data set in order to take into account the diversity of our users.
Although the tool can greatly help in the creative process, you need to remember about the possibilities of its use in improper purposes. If we create realistic faces of any type, then to what degree can we trust the person we see on the screen? Today it is important to discuss issues of this kind. As we have seen in recent examples of the use of the Deepfake technique, AI is rapidly progressing, so it is vital for humanity to begin a discussion on how best to deploy such applications.
All code and online demos of this work are available on the GitHub page .
You do not need to download code, model or data. Just follow the instructions in this Readme. You can change the faces in the browser, as shown in the video.
Just go to the Readme page of the GitHub repository. The code is compiled on Anaconda Python 3.6 with Tensorflow and Keras.
Welcome! Feel free to submit a pull request or report a problem on github.
Recently, I received a PhD in computational and cognitive neuroscience from Brown University and a master’s degree in computer science with a specialization in machine learning. In the past, I have studied how neurons in the brain collectively process information to achieve high-level functions, such as visual perception. I like the algorithmic approach to analyzing, simulating and implementing intelligence, as well as using AI to solve complex real-world problems. I am actively seeking a job as an ML / AI researcher in the technology industry.
This work was done in three weeks as a project for the InSight AI scholarship program . I thank the program director Emmanuel Amuizen and Matt Rubashkin for their general guidance, especially Emmanuel for his suggestions and editing the article. I also thank all Insight employees for their excellent learning environment and other Insight AI participants from whom I learned a lot. Special thanks to Rubin Xia for his many suggestions and inspirations when I decided in which direction to develop the project, and for my great help in structuring and editing this article.
An example of controlled synthesis in my TL-GAN model (transparent latent-space GAN, generative-contention network with transparent hidden space)
All code and online demos are available on the project page .
We teach the computer to take pictures by description
Discriminant and Generative Tasks
')
It is easy for a person to describe a picture, we learn to do it from a very early age. In machine learning, this is a discriminant classification / regression problem, i.e. prediction of features from input images. Recent advances in ML / AI methods, especially in deep learning models, begin to succeed in these tasks, sometimes reaching or exceeding human abilities, as shown in tasks like visual object recognition (for example, from AlexNet to ResNet by ImageNet classification) and detection / segmentation objects (for example, RCNN to YOLO in the COCO data set), etc.
However, the inverse problem of creating realistic images from the description is much more complicated and requires many years of training in graphic design. In machine learning, this is a generative task that is much more complex than discriminatory tasks, since the generative model must generate much more information (for example, a complete image at some level of detail and variation) based on smaller source data.
Despite the complexity of creating such applications, generative models (with some controls) are extremely useful in many cases:
- Content creation : Imagine that the advertising company automatically creates attractive images that match the content and style of the web page where these pictures are inserted. The designer is looking for inspiration, ordering the algorithm to generate 20 samples of shoes associated with the signs of "rest", "summer" and "passionate." The new game allows you to generate realistic avatars for a simple description.
- Clever editing with regard to content : the photographer changes the facial expression, the number of wrinkles and hair on the photo in a few mouse clicks. A Hollywood studio artist transforms shots taken on a cloudy evening, as if they were made on a bright morning, with sunlight on the left side of the screen.
- Data augmentation : the developer of unmanned vehicles can synthesize realistic videos for a specific accident scenario in order to increase the set of training data. A bank can synthesize certain types of fraud data that are poorly represented in an existing data set in order to improve the anti-fraud system.
This article will tell you about our recent work called Transparent Latent-space GAN (TL-GAN) , which extends the functionality of the most modern models, providing a new interface. We are currently working on a document with more technical details.
Overview of Generative Models
The deep learning community is rapidly improving generative models. Among them are three promising types: autoregression models , variational autoencoders (VAE) and generative adversarial networks (GAN) , shown in the figure below. If you are interested in the details, please read the excellent article on the OpenAI blog.
Comparison of generative networks. Image from STAT946F17 at the University of Waterloo
At the moment, the highest quality images generate GAN networks (photorealistic and diverse, with convincing details in high resolution). Look at the stunning images created by pg-GAN ( progressively growing GAN ) from Nvidia. Therefore, in this article we will focus on the GAN models.
Synthetic images generated by the Nvidia pg-GAN network. None of the images are related to reality.
Managing the issuance of GAN models
Random and controlled image generation
The original version of the GAN and many popular models based on it (such as DC-GAN and pg-GAN ) are unsupervised learning models. After training, the generative neural network accepts random noise as input data and creates a photorealistic image that is barely distinguishable from the training data set. However, we cannot additionally control the features of the generated images. In most applications (for example, in the scenarios described in the first section), users would like to create patterns with arbitrary attributes (for example, age, hair color, facial expression, etc.) Ideally, smoothly adjust each function.
Numerous variants of GAN have been created for such controlled synthesis. They can be divided into two types: the style transfer networks and conditional generators.
Style Transfer Networks
CycleGAN and pix2pix style transfer networks are trained to transfer an image from one area (domain) to another: for example, from horse to zebra, from sketch to color images. As a result, we cannot smoothly change a specific feature between two discrete states (for example, add a little beard on the face). In addition, one network is designed for one type of transmission, so ten different neural networks will be required to configure ten functions.
Generators by condition
Conditional generators - conditional GAN , AC-GAN and Stack-GAN - in the process of learning simultaneously study the images and object labels, which allows you to generate images with the setting of signs. When you want to add new features to the generation process, you need to retrain the entire GAN model, which requires huge computational resources and time (for example, from several days to weeks on a single K80 graphics processor with the ideal set of hyperparameters). In addition, to perform the training, you must rely on one data set containing all user-defined object labels, rather than using different labels from multiple data sets.
Our generative-contention network with transparent hidden space ( GAR , TL-GAN) uses a different approach for controlled generation - and solves these problems. It offers the ability to seamlessly configure one or more features using one network . In addition, you can effectively add new customizable features in less than one hour.
TL-GAN: A New and Effective Approach to Controlled Synthesis and Editing
We make this mysterious transparent hidden space.
Take the Nvidia pg-GAN model, which generates high-resolution photorealistic images of individuals, as shown in the previous section. All features of the generated 1024 × 1024px image are determined exclusively by the 512-dimensional noise vector in the hidden space (as a low-dimensional representation of the image content). Therefore, if you understand what constitutes a hidden space (that is, to make it transparent), then you can fully control the generation process .
TL-GAN Motivation: Understand the Hidden Space to Manage the Generation Process
Experimenting with the pre-trained pg-GAN network, I discovered that the hidden space actually has two good properties:
- It is well filled, that is, most points in space generate intelligent images.
- It is fairly continuous, that is, interpolation between two points in a hidden space usually leads to a smooth transition of the corresponding images.
Intuition says that in the hidden space there are directions that predict the signs we need (for example, a man / woman). If so, then the unit vectors of these directions will become axes for controlling the generation process (more masculine or more feminine face).
Approach: uncovering feature axes
To find these axis of signs in the hidden space, we construct a connection between the hidden vector and marks of signs with training with a teacher on pairs . Now the problem is how to get these pairs, since existing data sets contain only images and their corresponding object labels .
Ways to associate the hidden vector z with the tag of the sign y
Possible approaches:
One option is to compute the corresponding hidden vectors. of images from existing dataset with tags of interest to us . However, the GAN does not provide a simple way to calculate , which makes it difficult to implement this idea.
The second option is to generate synthetic images using GAN from random hidden vector as . The problem is that synthetic images are not tagged, so it is difficult to use the available set of tagged data.
The main innovation of our TL-GAN model is the training of a separate extractor (classifier for discrete labels or a regressor for continuous) with a model using an existing set of tagged data ( , ), and then launch in a bundle of trained GAN-generator with feature extraction network . This allows you to predict the signs of signs. synthetic images using a trained trait extraction network (extractor). Thus, by means of synthetic images, a connection is established between and as and .
Now we have a paired hidden vector and signs. You can train the regressor model , to reveal all the axis of the signs to control the process of generating images.
Figure: architecture of our TL-GAN model
The figure above shows the architecture of the TL-GAN model, which contains five steps:
- The study of distribution . Choose a well-trained GAN model and a generative network. I took a well-trained pg-GAN (from Nvidia), which provides the best quality of face generation.
- Classification . We select a pre-trained trait extraction model (the extractor can be a convolutional neural network or other computer vision models) or train our own extractor using a set of labeled data. I trained a simple convolutional neural network on the CelebA set (more than 30,000 people with 40 labels).
- Generation Create several random hidden vectors, pass through a trained GAN generator to create synthetic images, then use a trained feature extractor to generate features on each image.
- Correlation We use the generalized linear model (GLM) to implement the regression between hidden vectors and features. The slope of the regression line becomes the axis of the signs .
- Research We start with one hidden vector, move it along one or several axis of the signs and study how it affects the generation of images.
I have significantly optimized the process: on a pre-trained GAN model, identification of the axes of spatial objects takes only an hour on a machine with a single GPU. This is achieved through several engineering tricks, including transferring training, reducing the size of pictures, pre-caching synthetic images, etc.
results
Let's see how this simple idea works.
Moving a hidden vector along object axes
First, I checked whether the detected axis of the signs can be used to control the corresponding attribute of the generated image. To do this, create a random vector. in the hidden space GAN and generate a synthetic image by passing it through the generative network . Then move the hidden vector along one axis of signs. (a single vector in a hidden space, say, the corresponding half of the face) at a distance in a new position and generate a new image . Ideally, the corresponding feature of the new image should change in the expected direction.
The results of moving the vector along several axes of signs (gender, age, etc.) are presented below. This works surprisingly well! You can smoothly transform an image between a man / woman, boy / old man, etc.
The first results of moving the hidden vector along the tangled axis of the signs
Unraveling the correlated signs axes
In the examples above, there is a lack of the original method, namely the tangled axis of signs. For example, when you need to reduce facial hair, the generated faces become more feminine, which is not the expected result. The problem is that gender and beard are inherently correlated . A change in one trait leads to a change in another. Similar things have happened with other features, such as hairstyle and curly hair. As shown in the figure below, the original axis of the “beard” feature in the hidden space is not perpendicular to the “sex” axis.
To solve the problem, I used simple linear algebra techniques. In particular, he projected a beard axis onto a new direction, orthogonal to the sex axis, which effectively eliminates their correlation and, thus, can potentially unravel these two signs on the generated faces.
Unraveling the correlated axes of features by linear algebra techniques
I applied this method to the same person. This time, the axes of gender and age are chosen as reference ones, projecting all other axes so that they become orthogonal to gender and age. Persons are generated with the movement of the hidden vector along the newly generated axis of the signs (shown in the figure below). As expected, now signs like hairstyles and beards do not affect the floor.
Improved result of moving a latent vector along disentangled feature axes
Flexible online editing
To see how flexible our TL-GAN model is able to manage the image generation process, I created an interactive graphical interface with smooth changes in the values of objects along different axes, as shown below.
Interactive editing with TL-GAN
And again, the model works surprisingly well, if you change the images along the axis of the signs!
Summary
This project demonstrates a new method of managing a generative model without a teacher, such as the GAN (generative adversarial network). Using a previously well-trained GAN generator (pg-GAN from Nvidia), I made its hidden space transparent by displaying the axes of significant features. When a vector moves along such an axis in a hidden space, the corresponding image is transformed along this feature, providing controlled synthesis and editing.
This method has clear advantages:
- Efficiency: to add a new feature tuner for a generator, you do not need to re-train the GAN model, so adding tuners for 40 features takes less than an hour.
- Flexibility: you can use any tracer extractor trained on any data set, adding more traits to a well-trained GAN.
A few words about ethics
This work allows for detailed control of image generation, but it still largely depends on the characteristics of the data set. Studying on photos of Hollywood stars means that the model will very well generate photos of mostly white and attractive people. This will lead users to create faces representing only a small part of humanity. If we deploy this service as a real application, then it is desirable to expand the original data set in order to take into account the diversity of our users.
Although the tool can greatly help in the creative process, you need to remember about the possibilities of its use in improper purposes. If we create realistic faces of any type, then to what degree can we trust the person we see on the screen? Today it is important to discuss issues of this kind. As we have seen in recent examples of the use of the Deepfake technique, AI is rapidly progressing, so it is vital for humanity to begin a discussion on how best to deploy such applications.
Online demo and code
All code and online demos of this work are available on the GitHub page .
If you want to play with the model in the browser
You do not need to download code, model or data. Just follow the instructions in this Readme. You can change the faces in the browser, as shown in the video.
If you want to try the code
Just go to the Readme page of the GitHub repository. The code is compiled on Anaconda Python 3.6 with Tensorflow and Keras.
If you want to contribute
Welcome! Feel free to submit a pull request or report a problem on github.
About me
Recently, I received a PhD in computational and cognitive neuroscience from Brown University and a master’s degree in computer science with a specialization in machine learning. In the past, I have studied how neurons in the brain collectively process information to achieve high-level functions, such as visual perception. I like the algorithmic approach to analyzing, simulating and implementing intelligence, as well as using AI to solve complex real-world problems. I am actively seeking a job as an ML / AI researcher in the technology industry.
Thanks
This work was done in three weeks as a project for the InSight AI scholarship program . I thank the program director Emmanuel Amuizen and Matt Rubashkin for their general guidance, especially Emmanuel for his suggestions and editing the article. I also thank all Insight employees for their excellent learning environment and other Insight AI participants from whom I learned a lot. Special thanks to Rubin Xia for his many suggestions and inspirations when I decided in which direction to develop the project, and for my great help in structuring and editing this article.
Source: https://habr.com/ru/post/428221/
All Articles