Backend for the frontend, or How in Yandex.Market create an API without crutches
Why are some APIs more convenient to use than others? What can we do as front-end vendors on our side to work with an API of acceptable quality? Today, I will tell Habr's readers both about technical options and organizational measures that will help front-end and back-bidders find a common language and work efficiently.

This fall Yandex.Market is 18 years old. All this time, Market's partner interface has been developing. In short, this is an admin panel, with which stores can upload catalogs, work with an assortment, follow statistics, respond to reviews, etc. The specifics of the project are such that you have to interact a lot with various backends. At the same time, data is not always available in one place, from one specific backend.
Problem symptoms
So, imagine, there was some kind of task. The manager goes with the task to the designers - they draw the layout. Then he goes to the back-tenders - they make some pens and write the list of parameters and the response format on the inside wiki.
Then the manager goes to the front-end with the words “I brought you an API” and offers everything in a quick script, since, in his opinion, almost all the work has already been done.
You look at the documentation and see this:
№ | ---------------------- 53 | feed_shoffed_id 54 | fesh 55 | filter-currency 56 | showVendors Noticing anything strange? Camel, Snake and Kebab Case in one handle. I'm not talking about the fesh parameter. What is fesh anyway? That word doesn't even exist. Try to guess before you open the spoiler.
Fesh is a filter by store ID. You can pass several aydishnikami comma. Before the ID there can be a minus sign, which means that this store should be excluded from the results.
In this case, of course, from JavaSctipt, I can not access the properties of such an object through dot notation. Not to mention the fact that if you have more than 50 parameters in one place, then, obviously, you've turned somewhere in the wrong place.
There are a lot of inconvenient API options. The classic example is that the API searches and returns results:
result: [ {id: 1, name: 'IPhone 8'}, {id: 2, name: 'IPhone 8 Plus'}, {id: 3, name: 'IPhone X'}, ] result: {id: 1, name: 'IPhone 8'} result: null If the goods are found, we get an array. If one item is found, we get an object with this item. If nothing is found, then at best we get null. In the worst case, the backend answers 404 or even 400 (Bad Request).
There are situations easier. For example, you need to get a list of stores in one backend, and store options in another. In some pens there is not enough data, in some data there is too much. Filtering all of this on the client or doing multiple Ajax requests is a bad idea.
So, what could be the solutions to this problem? What can we do as front-end vendors on our side to work with an API of acceptable quality?
Backend for frontend
We use the React / Redux client in the partner interface. Under the client is Node.js, which does a lot of auxiliary things, for example, it pushes onto the InitialState page for Redax. If you have server-side rendering, it doesn’t matter with which client framework, most likely, it is rendered by the node. But what if you go a step further and not contact the client directly to the backend, but make your own proxying API on the node, as sharpened as possible for client needs?
This technique is called BFF (Backend For Frontend). This term was first introduced by SoundCloud in 2015, and the idea can be schematically depicted as follows:
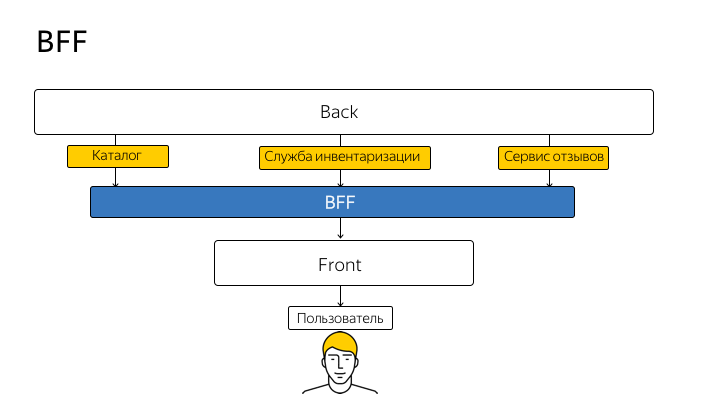
Thus, you stop going directly to the API from client code. Each handle, each method of the real API, you duplicate on the node and from the client go exclusively to the node. And the node already proxies the request to the real API and returns the answer to you.
This concerns not only primitive get-requests, but generally all requests, including those with multipart / form-data. For example, a store uploads a .xls file with its catalog through a form on the site. So, in this implementation, the directory is loaded not directly into the API, but into your node's handle, which proxies stream to a real backend.
Remember that result example when the backend returned a null, an array or an object? Now we can bring it to a normal form - something like this:
function getItems (response) { if (isNull(response)) return [] if (isObject(response)) return [response] return response } This code looks awful. Because he is terrible. But we still need to do it. We have a choice: do it on the server or on the client. I choose a server.
We can also put all these kebab and snake cases into a style that is convenient for us and immediately put down the default value if necessary.
query: { 'feed_shoffer_id': 'feedShofferId', 'pi-from': 'piFrom', 'show-urls': ({showUrls = 'offercard'}) => showUrls, } What other advantages do we get?
- Filtering The client receives only what he needs, no more, no less.
- Aggregation No need to spend client network and battery to make multiple Ajax requests. A noticeable gain in speed due to the fact that opening a connection is an expensive operation.
- Caching Your repeated aggregated call will not once again pull anyone, but simply return 304 Not Modified.
- Hiding data. For example, you may have tokens that are needed between backends and should not fall on the client. The client may not have rights even to know about the existence of these tokens, not to mention their contents.
- Microservices . If you have a monolith on the back, then BFF is the first step to microservices.
Now about the minuses.
- Increased complexity . Any abstraction is another layer that needs to be coded, deployed, supported. Another moving part of the mechanism that can fail.
- Duplication pens. For example, multiple endpoints can perform the same type of aggregation.
- BFF is a boundary layer that should support general routing, restrictions on user rights, query logging, etc.
To neutralize these disadvantages, it is enough to follow simple rules. The first is to separate the interface and business logic. Your BFF should not change the business logic of the main API. The second is that your interlayer should only convert data when absolutely necessary. We are not talking about a self-contained comprehensive API, but only about a proxy that fills the gap, correcting the flaws in the backend.
Graphql
GraphQL solves similar problems. With GraphQL, instead of a lot of “stupid” endpoint, you have one smart pen that can work with complex queries and generate data in the form in which the client requests them.
In this case, GraphQL can work on top of REST, that is, the data source is not a base, but a restart API. Due to GraphQL's declarativeness, due to the fact that all this is friendly with React and Redox, your client becomes easier.
In fact, I see GraphQL as a BFF implementation with my own protocol and strict query language.
This is an excellent solution, but it has several drawbacks, in particular, with typing, with differentiation of rights, and in general it is a relatively fresh approach. Therefore, we have not yet switched to it, but in the long term this seems to me the most optimal way to create an API.
Best Friends Forever
No technical solution will work correctly without organizational changes. You still need documentation, guarantees that the format of the answer does not suddenly change, and so on.
It should be understood that we are all in the same boat. To an abstract customer, be it a manager or your manager, by and large it doesn’t matter - you have GraphQL there or BFF. It is more important for him that the task be solved and no errors appear on the sale. For him, there is not much difference, due to whose fault an error occurred in the sale - the fault of the front or back. Therefore, you need to negotiate with backenders.
In addition, the backward flaws that I mentioned at the beginning of the report do not always arise because of someone’s malicious actions. It is possible that the fesh parameter has some meaning.

Note the commit date. It turns out quite recently fesh celebrated its seventeenth anniversary.
See any weird identifiers on the left? This is SVN, simply because in 2001 there was no guide. Not a githaba as a service, but specifically a gita as a version control system. He appeared only in 2005.
Documentation
So, all we need is not to quarrel with back-tenders, but to agree. This can be done only if we find one single source of truth. This source should be documentation.
The most important thing here is to write documentation before we start working on functionality. As with the marriage contract, it is better to agree on everything on the shore.
How it works? Relatively speaking, three are going to: the manager, the fronder and the backender. Fronteder is well versed in the subject area, so his participation is critically important. They gather and begin to think about the API: in what ways, what answers should be returned, including the name and format of the fields.
Swagger
A good option for API documentation is Swagger format, now it is called OpenAPI. It is better to use Swagger in YAML format, because, unlike JSON, it is better readable by man, and for the machine there is no difference.
As a result, all agreements are recorded in Swagger-format and published in a common repository. Documentation for the sales backend should be in the wizard.
The master is protected from commits, the code gets into it only through the pool of requests, it is impossible to push into it. The representative of the front-team is obliged to conduct a review of the request rekvesta, without his apruva code in the master does not go. This protects you from unexpected API changes without prior notice.
So, you gathered, wrote Swagger, thus actually signed the contract. From this point on, you, as a front-endender, can begin your work without waiting for the creation of a real API. After all, what was the point of separation between client and server if we cannot work in parallel and client developers have to wait for server developers? If we have a “contract”, then we can calmly parallel this matter.
Faker.js
For these purposes, great faker . This is a library for generating huge amounts of fake data. She can generate different types of data: dates, names, addresses, etc., all this is well localized, there is support for the Russian language.
At the same time, the faker is friendly with the Swager, and you can safely raise the mock server, which, based on the Swagger-scheme, will generate you fake answers along the right paths.
Validation
Swagger can be converted to a json-scheme, and using tools such as ajv, you can run backends in your BFF, right in runtime, and backtesting replies to testers, backenders, etc., in case of discrepancies.
Suppose a tester finds a bug on a site, for example, nothing happens when you click on a button. What does the tester do? He puts the ticket on the front-end: “this is your button, so it’s not pressed, fix it”.
If there is a validator between you and the backend, then the tester will know that the button is actually pressed, just the backend sends the wrong answer. The wrong one is a response that the front does not expect, that is, it does not comply with the “contract”. And here it is already necessary either to repair the backing or to change the contract.
findings
- We take an active part in the design of the API. We design API so that it was convenient to use them in 17 years.
- We require Swagger documentation. No documentation - the backing job was not done.
- There is documentation - we publish it in git, while any changes in the API should be approved by a representative of the front team.
- Raise the fake server and start working on the front without waiting for the real API.
- We put the node under the frontend and validate all the answers. Plus we get the ability to aggregate, normalize and cache data.
see also
→ How to build a REST-like API in a large project
→ Backend In the Frontend
→ Using GraphQL as BFF Pattern Implementation
')
Source: https://habr.com/ru/post/428141/
All Articles