Optimize load balancing in Veeam Backup & Replication infrastructure
My wonderful colleagues from the technical support department write not only harmful, but also useful tips and recommendations on how to configure Veeam Backup & Replication. Since the publication of the article for novice users, its author, Evgeny Ivanov, continuing to work with the Romanian team in Bucharest, has moved from the post of senior engineer to the position of team lead. But Eugene did not leave the technical-literary field, for which he thanks a lot!
Eugene's new article contains recommendations for the already experienced specialists working with Veeam Backup & Replication, who are faced with the task of using the backup infrastructure resources most effectively. However, the article will be useful to those who are just planning to install and configure our product.

Optimized load distribution during warm lamp times
For useful tips welcome under cat.
Veeam Backup & Replication is a modular software consisting of various components, each of which performs specific functions. Among these components is a central manager, Veeam backup server, a proxy server, a repository, a WAN accelerator and others. A number of components can be installed on one machine (of course, quite powerful), which is what many users do. However, a distributed installation has its advantages, namely:
')
It must be borne in mind that distributed systems will be effective only with a reasonable load distribution. Otherwise, “bottlenecks”, overloading of individual components may occur - and this is fraught with a general drop in productivity and slowdown.
To have a clearer idea of where data is transferred from and from during the backup process, consider the following diagram (for example, take the infrastructure on the vSphere platform):

As you can see, the data is transferred from the source location (source) to the target (target) using “transport agents” (VeeamAgent.exe), which work in both locations. So, when a backup job is running, the following happens:
Thus, 2 components are always involved in data transfer, even if they are actually on the same machine. This must be taken into account when planning deployment solutions.
First, let's define the concept of “task”. In the terminology of Veeam Backup & Replication, each task (task) is the processing of 1 disk of a virtual machine. That is, if you have a backup job (job) that includes 5 VMs with 2 disks each, this means that you have to handle 10 tasks (and if the machine has only 1 disk, then 1 task = 1 VM). Veeam Backup & Replication is capable of processing several tasks in parallel, but their number, of course, is not infinite.
For each proxy server in its properties you can specify the maximum number of tasks for parallel execution:
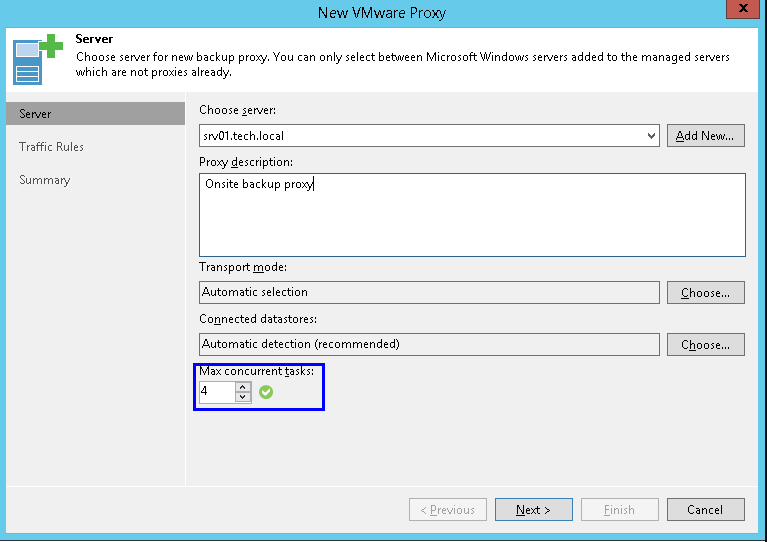
In standard backup operations, a similar interpretation will be made for the repository: one task is to transfer data from one virtual disk. In the interface, it looks very similar:

Here we must fix a very important rule number 1: be sure to keep a balance when assigning proxy and repository resources and specifying the maximum number of tasks for parallel processing!
Assume that you have 3 proxy servers, each of which can process 4 tasks in parallel (that is, a total of 12 virtual disks of the source VMs are obtained). But the repository is configured to handle only 4 tasks in parallel (by the way, this is the default value). With such settings, only the 4 disks will be saved in parallel from the source location to the target, although they could be for all 12. That is, the resources will be underloaded.
However, when it comes to creating a synthetic full backup (and similar operations), the concept of a task relative to the repository acquires a slightly different meaning. We remember that such operations do not use proxy servers, but are performed locally on the repository (Windows or Linux) or (in the case of CIFS share) using a gateway (gateway).
In this case, when building a normal chain of backups, a task = a backup task. That is, a limit of 4 tasks for parallel processing here will mean that the synthetic repositories for 4 backup tasks can be simultaneously created on the repository.
When building the same chain of backups, decomposed in accordance with the original VMs (the so-called “machine-sided” storage is per-VM), the task = 1 VM. That is, a limit of 4 tasks for parallel processing here will mean that 4 VBK files for 4 virtual machines can be generated on the repository at the same time.
Thus, we arrive at rule number 2: Depending on the backup settings, the same number of tasks may mean a completely different load on the repository. Therefore, when scheduling resources, you certainly need to check these very settings: backup mode, schedule of tasks, method of organizing backup chains.
Note: Unlike proxy server settings, you can disable the limit on the number of tasks for the repository. In this case, the repository will receive all data from proxy servers. But this is only apparent freedom from limitations, since there is a risk of overloading the repository and failures in the work of backup tasks. Therefore, we strongly do not recommend to refuse this limit.
Suppose you have a backup task that includes a sufficiently large number of VMs with a total number of virtual disks of 100 pieces. At the same time, the repository is configured to store backup chains “per-VM”. The settings for parallel processing are as follows: for a proxy, 10 disks at a time, and for a repository, there are no restrictions. During an incremental backup, the load on the repository will be limited due to the proxy settings, and thus the balance will be maintained. But then comes the moment of creating a synthetic full backup. Such a backup does not use a proxy, and all operations to create "synthetics" take place exclusively on the repository. Since there is no restriction on parallel processing of tasks for the repository, the repository server will try to process the entire hundred simultaneously. This will require considerable strain on resources and will most likely lead to overload.
If you are working with a repository based on a Windows or Linux server, then the “target” agent starts directly on this server. However, if you use the CIFS share folder as the repository (CIFS share), then the “target” agent starts on a specially designed machine - this is the so-called. "Gateway" (gateway), which will receive incoming data flow from the agent on the side of the source VM. The “target” agent will receive this data and then send data blocks to the CIFS ball. This auxiliary machine should be placed as close as possible to a machine that provides SMB shared folders — this is especially important for scenarios involving a WAN connection.
Rule number 3: You should not place an auxiliary machine (proxy / gateway) on one site, and the CIFS share shared folder - on another site (including on the cloud) - otherwise you will face persistent problems with the network.
You can also apply all the above considerations for balancing the load on the system to gateways. In addition, you need to keep in mind that the gateway has 2 additional settings: the server for it can be assigned explicitly or automatically selected:

In principle, you can use any Windows server included in the Veeam backup infrastructure as such a gateway. Depending on the deployment scenario, one of the options may suit you:
The "target" agent starts on the proxy server that performs the backup.
When creating synthetic backups, proxy servers are not used, and here the machine to start the “target” agent is selected as follows: an auxiliary mount server is taken (the mount server on which the files are mounted, for example, during recovery operations) associated with the repository and it starts the agent. If the mount server is unavailable for some reason, it is possible to switch to the north Veeam backup. As you understand, the load distribution in this version will not be.
Therefore, I repeat: ( IMPORTANT! ) It is not recommended for such scenarios to remove the restriction on the number of parallel processed tasks, because when performing operations with “synthetics” this can lead to a huge overload of the mount server or even the Veeam backup server.
Scalable repository. SOBR is a set of standard repositories (here they are called “extents”). If you already use SOBR, then in the backup task you specify it, not the extent. At extent-ah, you can use some settings, for example, load distribution.
All the basic principles that work for regular repositories work for SOBR. For optimal use of resources, it is advisable to set up SOBR with “back-end” storage of backups (per-VM - this option is set by default), with the “Performance” placement policy (“optimize for better performance”) and distribution of chains across repositories-extent-s.
Transferring backups (backup copy). Here, the source agents will work on the source repository. Everything mentioned above applies to the original repositories (except for the fact that in the case of the Backup Copy Job transfer job, operations with “synthetics” on the original repository are not performed).
Note: If the source repository is a CIFS share, then the “source” agent starts on the corresponding mount server (with the ability to switch to Veeam backup server).
Devices with built-in deduplication. For DataDomain, StoreOnce storage systems (and in the future, probably, for others), for which integration with Veeam is configured, the same considerations apply as for the CIFS share. For a repository on StoreOnce with deduplication on the source side ( Low Bandwidth mode), the requirement to place the gateway as close as possible to the repository is no longer relevant - the gateway on one site can be configured to send data to StoreOnce on another site via WAN.
Preferred proxy server. This feature appeared, as you remember, in release 9.5, and is responsible for supporting the “priority list of proxies”, which the program will follow when working with a specific repository.
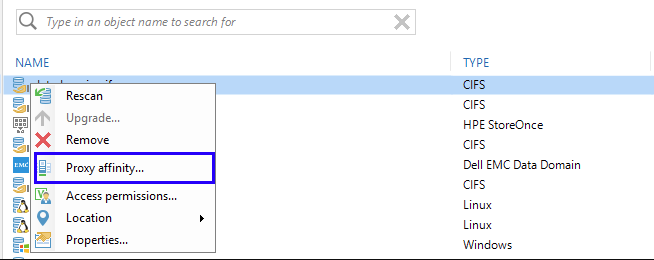
If the proxy from this list is not available, then the task will work with any other available. However, if there is access to the proxy, but the proxy server does not have free slots for processing the task, then the backup task will be suspended pending those. Therefore, it is necessary to use this feature very carefully (and not in the “included and forgotten” style) - we had users who thus “hung up” the backup tasks. More information about the feature can be read here (in English. Language).
It doesn't matter if you are installing Veeam Backup & Replication for the first time or you are a long-time user - I want to believe that in this article you will find useful information and with its help optimize the performance of your backup infrastructure or even eliminate potential risks of data loss. Here are some more useful links:
Eugene's new article contains recommendations for the already experienced specialists working with Veeam Backup & Replication, who are faced with the task of using the backup infrastructure resources most effectively. However, the article will be useful to those who are just planning to install and configure our product.
Optimized load distribution during warm lamp times
For useful tips welcome under cat.
About the advantages of a distributed installation
Veeam Backup & Replication is a modular software consisting of various components, each of which performs specific functions. Among these components is a central manager, Veeam backup server, a proxy server, a repository, a WAN accelerator and others. A number of components can be installed on one machine (of course, quite powerful), which is what many users do. However, a distributed installation has its advantages, namely:
')
- For companies with a network of branches, it is possible to install the necessary components locally in these branches. This helps optimize traffic, organizing most of it again, locally.
- As the infrastructure grows, it becomes necessary to scale the backup solution. If the backup takes longer (the “backup window” grows), you can install an additional proxy server. If you need to increase the capacity of the backup repository, you can configure a scalable repository (scale-out backup repository) and add new extents as needed.
- For some components, you can ensure constant availability (High Availability) - for example, if you have several proxy servers deployed and one of them suddenly turns off, then the others will continue to work and the backup will not be affected.
It must be borne in mind that distributed systems will be effective only with a reasonable load distribution. Otherwise, “bottlenecks”, overloading of individual components may occur - and this is fraught with a general drop in productivity and slowdown.
How is the data transmitted?
To have a clearer idea of where data is transferred from and from during the backup process, consider the following diagram (for example, take the infrastructure on the vSphere platform):
As you can see, the data is transferred from the source location (source) to the target (target) using “transport agents” (VeeamAgent.exe), which work in both locations. So, when a backup job is running, the following happens:
- The “source” transport agent runs on a proxy server; it reads data from the datastore, performs compression and deduplication, and sends the data in this form to the “target” transport agent.
- The “target” transport agent runs directly on the repository (Windows / Linux) or on the gateway (gateway server), if CIFS share is used. This agent, in turn, also performs deduplication on its side and saves the data to a backup file (.VBK, .VIB, etc.).
Thus, 2 components are always involved in data transfer, even if they are actually on the same machine. This must be taken into account when planning deployment solutions.
Load sharing between proxy and repository
First, let's define the concept of “task”. In the terminology of Veeam Backup & Replication, each task (task) is the processing of 1 disk of a virtual machine. That is, if you have a backup job (job) that includes 5 VMs with 2 disks each, this means that you have to handle 10 tasks (and if the machine has only 1 disk, then 1 task = 1 VM). Veeam Backup & Replication is capable of processing several tasks in parallel, but their number, of course, is not infinite.
For each proxy server in its properties you can specify the maximum number of tasks for parallel execution:
In standard backup operations, a similar interpretation will be made for the repository: one task is to transfer data from one virtual disk. In the interface, it looks very similar:
Here we must fix a very important rule number 1: be sure to keep a balance when assigning proxy and repository resources and specifying the maximum number of tasks for parallel processing!
Example
Assume that you have 3 proxy servers, each of which can process 4 tasks in parallel (that is, a total of 12 virtual disks of the source VMs are obtained). But the repository is configured to handle only 4 tasks in parallel (by the way, this is the default value). With such settings, only the 4 disks will be saved in parallel from the source location to the target, although they could be for all 12. That is, the resources will be underloaded.
However, when it comes to creating a synthetic full backup (and similar operations), the concept of a task relative to the repository acquires a slightly different meaning. We remember that such operations do not use proxy servers, but are performed locally on the repository (Windows or Linux) or (in the case of CIFS share) using a gateway (gateway).
In this case, when building a normal chain of backups, a task = a backup task. That is, a limit of 4 tasks for parallel processing here will mean that the synthetic repositories for 4 backup tasks can be simultaneously created on the repository.
When building the same chain of backups, decomposed in accordance with the original VMs (the so-called “machine-sided” storage is per-VM), the task = 1 VM. That is, a limit of 4 tasks for parallel processing here will mean that 4 VBK files for 4 virtual machines can be generated on the repository at the same time.
Thus, we arrive at rule number 2: Depending on the backup settings, the same number of tasks may mean a completely different load on the repository. Therefore, when scheduling resources, you certainly need to check these very settings: backup mode, schedule of tasks, method of organizing backup chains.
Note: Unlike proxy server settings, you can disable the limit on the number of tasks for the repository. In this case, the repository will receive all data from proxy servers. But this is only apparent freedom from limitations, since there is a risk of overloading the repository and failures in the work of backup tasks. Therefore, we strongly do not recommend to refuse this limit.
Another example
Suppose you have a backup task that includes a sufficiently large number of VMs with a total number of virtual disks of 100 pieces. At the same time, the repository is configured to store backup chains “per-VM”. The settings for parallel processing are as follows: for a proxy, 10 disks at a time, and for a repository, there are no restrictions. During an incremental backup, the load on the repository will be limited due to the proxy settings, and thus the balance will be maintained. But then comes the moment of creating a synthetic full backup. Such a backup does not use a proxy, and all operations to create "synthetics" take place exclusively on the repository. Since there is no restriction on parallel processing of tasks for the repository, the repository server will try to process the entire hundred simultaneously. This will require considerable strain on resources and will most likely lead to overload.
Features of using CIFS share as a repository
If you are working with a repository based on a Windows or Linux server, then the “target” agent starts directly on this server. However, if you use the CIFS share folder as the repository (CIFS share), then the “target” agent starts on a specially designed machine - this is the so-called. "Gateway" (gateway), which will receive incoming data flow from the agent on the side of the source VM. The “target” agent will receive this data and then send data blocks to the CIFS ball. This auxiliary machine should be placed as close as possible to a machine that provides SMB shared folders — this is especially important for scenarios involving a WAN connection.
Rule number 3: You should not place an auxiliary machine (proxy / gateway) on one site, and the CIFS share shared folder - on another site (including on the cloud) - otherwise you will face persistent problems with the network.
You can also apply all the above considerations for balancing the load on the system to gateways. In addition, you need to keep in mind that the gateway has 2 additional settings: the server for it can be assigned explicitly or automatically selected:
In principle, you can use any Windows server included in the Veeam backup infrastructure as such a gateway. Depending on the deployment scenario, one of the options may suit you:
- Explicitly specified server - this, of course, simplifies a lot, because you will know exactly which machine the “target” agent is running on. This option is recommended, in particular, for cases where access to the ball is allowed only from certain servers, as well as for scenarios with distributed infrastructure - you probably want reasonable people to use the agent on a machine located near the file server from the target shary
- Automatic server selection ( Automatic selection option). Here it takes an interesting turn: if you use several proxy servers, the choice of this option, it turns out, leads to the fact that the program uses more than one gateway, distributing the load. I note that “automatically” does not mean “arbitrarily” - here quite specific selection rules apply.
How it works?
The "target" agent starts on the proxy server that performs the backup.
- In the case of a normal chain of backups, the logic is as follows: if there are several tasks performed at the same time, each with its own proxy server, then you can run several “target” agents. However, within one job, the job logic is different: even if the VMs contained in it are processed by different proxies, the “target” agent will be started on only one — the one that starts work first.
- In the case of the "back-up" chain of backups, a separate "target" agent is started for each VM. Thus, even within the same task, the load is distributed.
When creating synthetic backups, proxy servers are not used, and here the machine to start the “target” agent is selected as follows: an auxiliary mount server is taken (the mount server on which the files are mounted, for example, during recovery operations) associated with the repository and it starts the agent. If the mount server is unavailable for some reason, it is possible to switch to the north Veeam backup. As you understand, the load distribution in this version will not be.
Therefore, I repeat: ( IMPORTANT! ) It is not recommended for such scenarios to remove the restriction on the number of parallel processed tasks, because when performing operations with “synthetics” this can lead to a huge overload of the mount server or even the Veeam backup server.
Additional features
Scalable repository. SOBR is a set of standard repositories (here they are called “extents”). If you already use SOBR, then in the backup task you specify it, not the extent. At extent-ah, you can use some settings, for example, load distribution.
All the basic principles that work for regular repositories work for SOBR. For optimal use of resources, it is advisable to set up SOBR with “back-end” storage of backups (per-VM - this option is set by default), with the “Performance” placement policy (“optimize for better performance”) and distribution of chains across repositories-extent-s.
Transferring backups (backup copy). Here, the source agents will work on the source repository. Everything mentioned above applies to the original repositories (except for the fact that in the case of the Backup Copy Job transfer job, operations with “synthetics” on the original repository are not performed).
Note: If the source repository is a CIFS share, then the “source” agent starts on the corresponding mount server (with the ability to switch to Veeam backup server).
Devices with built-in deduplication. For DataDomain, StoreOnce storage systems (and in the future, probably, for others), for which integration with Veeam is configured, the same considerations apply as for the CIFS share. For a repository on StoreOnce with deduplication on the source side ( Low Bandwidth mode), the requirement to place the gateway as close as possible to the repository is no longer relevant - the gateway on one site can be configured to send data to StoreOnce on another site via WAN.
Preferred proxy server. This feature appeared, as you remember, in release 9.5, and is responsible for supporting the “priority list of proxies”, which the program will follow when working with a specific repository.
If the proxy from this list is not available, then the task will work with any other available. However, if there is access to the proxy, but the proxy server does not have free slots for processing the task, then the backup task will be suspended pending those. Therefore, it is necessary to use this feature very carefully (and not in the “included and forgotten” style) - we had users who thus “hung up” the backup tasks. More information about the feature can be read here (in English. Language).
Finally
It doesn't matter if you are installing Veeam Backup & Replication for the first time or you are a long-time user - I want to believe that in this article you will find useful information and with its help optimize the performance of your backup infrastructure or even eliminate potential risks of data loss. Here are some more useful links:
Source: https://habr.com/ru/post/428069/
All Articles