A new look at documenting API and SDK in Yandex. Lecture on Hyperbaton
My name is Andrey Polyakov, I am the head of the API and SDK documentation group at Yandex. Today I would like to share with you a report that my colleague and I, Julia Pivovarova, a senior documentation developer, read a few weeks ago at the 6th Hyperbaton.
Svetlana Kayushina, head of documentation and localization department:
- The volume of software code in the world in recent years has grown dramatically, continues to grow, and this affects the work of technical writers, who are coming to more and more tasks to develop software documentation and document the code. We could not ignore this topic, we devoted a whole section to it. These are three interrelated reports devoted to the unification of the development of program documentation. I invite our specialists in documenting software interfaces and libraries Andrei Polyakov and Yulia Pivovarov. Give them the word.
- Hello! Today, Julia and I will tell you how in Yandex we have a new look at documenting the API and the SDK. The report will consist of four parts, the report of the hour, we will discuss and talk.
')
Let's talk about the unification of the API and the SDK, how we came to it, what we did there. We will share the experience of using a universal generator, one for all languages, and tell why it didn’t work for us, what were the pitfalls, and why we switched to generating documentation with native generators.
In the end we will tell how our processes were built.
Let's start with the unification. Everyone thinks about unification when there are more than two people in a team: everyone writes differently, everyone has their own approaches, and this is logical. It is better to discuss all the rules on the shore, before you start writing documentation, but not everyone succeeds.
We gathered an expert group to analyze our documentation. We did this to systematize our approaches. Everyone writes differently, and let's agree to write in the same style. This is the second point, for which we were going to try to make the documentation uniform, so that the user has one user experience in all the Yandex documentation, namely the technical one.
The work was divided into three stages. We have compiled a description of the technologies that we have in Yandex, which we use, have tried to select from them those that we can somehow unify. And also made the general structure of standard documents and templates.

Let us turn to the description of technology. We began to study what technologies are used in Yandex. There are so many of them that we are tired of writing them in some kind of notebook, and in the end we chose only the most basic ones, which are most often used, most often encountered by technical writers, and began to describe them.
What is meant by technology description? We have identified the main points and the essence of each technology. If we are talking about programming languages, then this is a description of such entities as class, property, interfaces, etc. If we are talking about protocols, then we describe HTTP methods, talking about the format of the error code, response code, etc. We have compiled a glossary containing the following things: terms in Russian, terms in English, usage nuances. For example, we are not talking about some kind of SDK method, that it ALLOWS to do something. It DOES something, if the programmer jerks some kind of pen, it gives some kind of answer.
In addition to the nuances, the description also contained standard structures, standard speech patterns, which we use in the documentation so that the recorder can take a specific wording and use it further.
In addition, technical writers often write pieces of code, snippets, samples, and for this we also described our own style guide for each technology. We turned to the developers of guides that are in Yandex. Drew attention to the design code, description of comments, indents and all that. We do this so that when a technical writer comes to a programmer with a piece of code or a written sample, the programmer looks at the essence, not how it is designed, and this reduces the time. And when a technical writer is able to write on Yandex style guides, this is very cool, maybe he wants to become a programmer later. The previous report was about various examinations. For example, you can move into programmers.
For tech writers, we also developed a quick start: how to set up a development environment when he becomes familiar with a new technology. For example, if the SDK technician is written in C #, then it comes in, sets up the development environment, reads the manuals, becomes familiar with the terminology. We also left links to official documentation and RFCs, if any. We made an entry point for technical writers, and it looks like this.
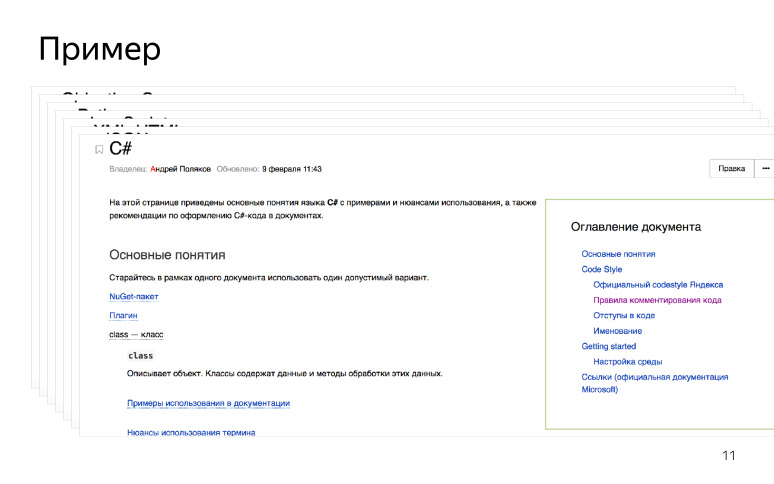
When a technical writer arrives, he studies a new technology and starts documenting it.
After we described the technology, we moved on to describing the structure of the HTTP API.
We have many different HTTP APIs, and all are described differently. Let's agree and do the same!
We have identified the main sections that will be in each HTTP API:

"Overview" or "Introduction": what this API is for, what it allows you to do, which host you need to contact to get some kind of answer.
“Quick start”, when a person goes through some steps and gets a successful result at the end, in order to understand how this API works.
"Connection / Authorization". For many APIs, an authorization token or API key is required. This is an important point, so we decided that this is a mandatory part of all APIs.
“Limits / Limits” when we talk about limits on the number of requests or the size of the request body, etc.
"Reference", reference. A very large part, which contains all the HTTP handles that the user can pull and get some result.
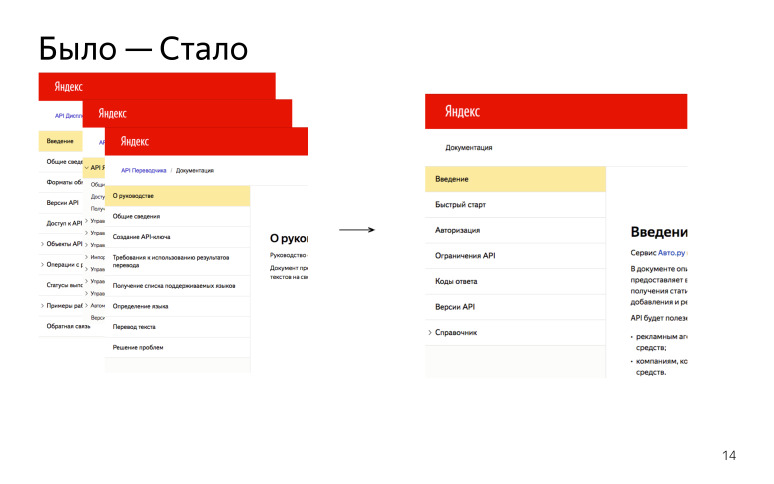
As a result, we had many different APIs, they were described differently, now we try to write everything the same. Such a profit.
Delving into the directories, we realized that the HTTP handle is almost always the same. You pull it, that is, you make a request, the server returns an answer - voila. Let's try to unify it. We wrote a template that tried to cover all cases. The technical writer takes the template, and, if he has a PUT request, he leaves the necessary parts in the template. If he has a GET request, he uses only those parts that are needed for a GET request. A generic template for all queries that can be reused. Now you do not need to create a document structure from scratch, but you can simply take a ready-made template.

Each pen describes what it is for, what it does. There is a section "Request format", which contains path-parameters, query-parameters, everything that comes in the body of the request, if it is sent. We also highlighted the section "Answer format": we write it if there is an answer body. A separate section, we have identified the "response codes", because the response from the server comes regardless of the body. And left the section "Example". If we supply an SDK with this API, then we say that use the SDK like this, pull such a handle, call such a method. Usually we leave some example with cURL, where the user simply inserts his token. And if we have a test bench, then simply takes the request and executes it. And gets some result.

It turns out that there were many pens, they were described differently, and now we want to bring it all to a single form.
After we finished with the HTTP API, we moved to the mobile SDK.
There is a general structure of the document, it is about the same:
- “Introduction”, where we say that this SDK is used for such purposes, integrate it for such purposes, for such OSs it will do, we have such versions, etc.
- “Connection”. Unlike the HTTP API, we are not just talking about how to get the key for using the SDK, if you need one, we are talking about how to integrate the library into your project.
- "Examples of using". The largest section in terms of volume. Most often, developers want to come into the documentation and not read a lot of information, they want to copy a piece, paste it, and everything will work for them. Therefore, we considered this part to be very important and made it a mandatory section.

- “Reference book”, reference, but unlike the HTTP API reference, we cannot unify everything here, since we basically generate reference books and we will talk about this later in the report.
- “Releases”, or changelog, changelog. Mobile SDKs usually have a short release cycle, somewhere around two weeks a new version is released. And it would be better for the user to talk about what has changed, should he be updated or not.
At the same time, the API has both mandatory sections that we see and sections that we recommend to use. If the API is updated frequently, we say that then paste yourself also the change history, what has changed in the API. And often we have API rarely updated, and as a mandatory section it is pointless to specify it.

So, we had a lot of SDK, which were described in different ways, we tried to turn about one style. Naturally, there are additional differences inherent only in this SDK or this HTTP API. Here we have the freedom to choose. We do not say that apart from these sections, no one can be done. Of course, you can, we simply try to do the listed sections everywhere, so that it is clear that if the user has moved to the documentation for another SDK, he knows what will be described in the “Connection” section.
So, we came up with templates, made guides, what is our action plan now? We decided that if we scale API changes, change pens or change SDK, we take new templates, take a new structure and start working on it.
If we write documentation from scratch, then, of course, we again take a new structure, take new templates and work on them.
And if the API is outdated, rarely updated, or no one supports it, but it exists, then it is a little resource-intensive to redo it. We just decided to leave it until it will be so, but then, when resources appear, we will definitely return to them, we will do all this well and beautifully.
What are the advantages of unification? They should all be obvious:
“UX”, we are thinking of making the user feel at home in our documentation. He came, and he knows what is described in sections, where he can find authorization, examples of use, description of the pen. It's great.
For tech writers, the description of the technology allows you to define a certain entry point, where it comes, and begins to get acquainted with this technology, if he did not know it, begins to understand the terminology, dive into it.
The next point is interchangeability. If the technical writer went on vacation or simply stopped writing, then another technical recorder knows how it works inside when entering the document. It is immediately clear what is described in the connection, where to look for information on the integration of the SDK. Understanding and making small edits in a document becomes easier. It is clear that each project has its own specifics, you can not just come and document a project without knowing it completely. But at the same time, the structure, that is, file navigation, will be approximately the same.
And, of course, common terminology. We agreed with the developers and with the translators the terminology that we made for languages. We say that we have C #, there is such a term, we use it that way. We asked the developers what terminology they used and wanted to achieve synchronization in this place. We have agreements, and the next time we come with the documentation, the developers know that we have agreed terms with them, guides, we use these templates, we take into account the nuances of their use. And the translators, in turn, know that we describe the SDK in C # or Objective-C, which means this terminology will correspond to what is described in the guide.
Guides were written in wiki pages, so if there is an update of languages, technologies, protocols, this is all easily added to an existing document. Idyll.
The sooner you start to unify and negotiate, the better. It is better that later there is no legacy of documentation that is written in a different style that breaks the user's flow in the documentation. Better to do it all before.
Attract developers. These are the people for whom you are writing documentation. If you have written yourself some guides, they may not like it. It is better to agree with them so that you have a common understanding of terminology: what you write in the documentation, how you write it.
And also negotiate with the translators, they all translate. If they translate differently than developers are used to, there will again be conflicts. ( Here is a link to a fragment of a video with questions and answers - Ed.) Go ahead.
Yuliya:
- Hi, my name is Julia, I have been working at Yandex for five years now and have been documenting the API and SDK in Andrei’s group. Usually, everyone talks about good experience, how great it all turns out. I will tell you how we chose a not entirely successful strategy. At that time, she seemed successful, but then came the harsh reality, and we were a little unlucky.
We initially had several mobile SDKs, and they were written mostly in two languages: Objective-C and Java. We wrote documentation to them manually. Over time, classes, protocols, and interfaces grew. They became more and more, and we realized that we need to automate this business, we looked at what technologies are there.
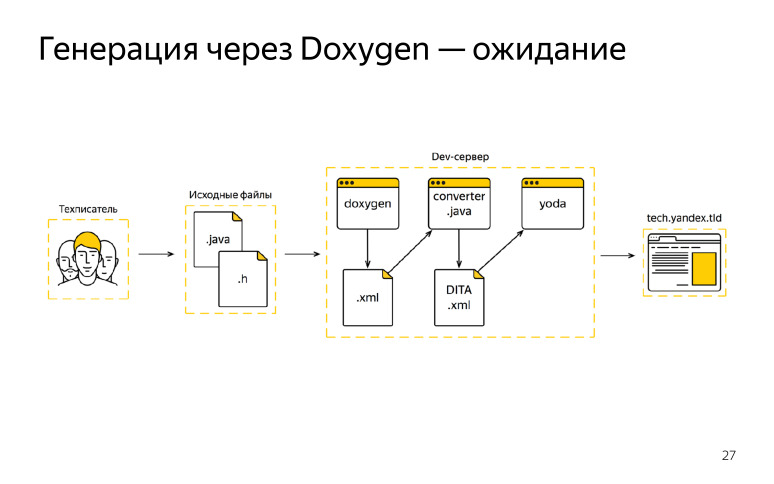
At that moment, we liked Doxygen, it met our needs, as it seemed to us, and we chose it as a single generator. And we drew such a scheme that we expected to get, we wanted to work on it somehow.
What did we have? The technical writer came to work, received source code from the developer, started writing his comments, edits, after that the documentation had to be sent to our devserver, we started Doxygen, received the XML format, but it did not fit our DITA XML standard. We knew about it beforehand, wrote a certain converter.
After we received the output from Doxygen, we passed all this through the converter and received our format. Further the collector of documentation was connected, and we published all this on the external domain. We even got lucky with a couple of iterations, everything worked out for us, we were delighted. But then something went wrong. The technical writer also went to work, got the tasks and source codes from the developer, made his own edits there. After that he went to the devserver, started Doxygen and there was a fire.
We decided to figure out what was wrong. Then we realized that Doxygen does not quite fit all languages. We had to analyze the code, on which it stumbled, we found constructs that Doxygen did not support and did not plan to support.
We decided, since we are working in this scheme, we will write a preprocessing script, and we will replace these constructions in some way with what Doxygen accepts, or in some way ignore them.

Our cycle began to look like this. We received the source code, concluded them on the devserver, then connected the preprocessing script, cut out all the extras from the code, followed by Doxygen, then received the output format Doxygen, also started the converter, received our final DITA XML files, then the documentation collector connected, and we published our external domain documentation. It seems everything looks good. Added a script, what is it? Initially, it was all nothing. The script had three lines, then five, ten, and it all grew to hundreds of lines. We realized that we are starting to spend most of the time not on writing documentation, but on analyzing the code, looking for something that doesn’t crawl, and just appending the script in endless regulars, sitting to distraction and thinking what's the matter.
We realized that we need to change something, to somehow stop before it is too late, and until our release cycle has not completely collapsed.
As an example, something like the preprocessing script initially looked like, and was harmless.

Why did we initially choose this path? Why did he seem good?

One generator is great, took it, once connected it, set it up and it works. It seemed like a good approach. In addition, you can use the same comment syntax for all languages at once. You wrote some kind of guide, use it once, immediately insert all these constructions into the code and do your work, write comments, and not somehow dwell on the syntax.

But it turned out to be one of the big drawbacks. Our uniform syntax was not supported by the developers, they used to use their IDE, there are already native generators, and their syntax did not coincide with ours. This was a sticking point.
Also, Doxygen poorly supported new features in languages. He has a selective approach, since he himself is written in C ++, he mainly supports C-like languages, and the rest on the residual principle. But languages are improving, Doxygen doesn’t quite keep up with them, and we feel very uncomfortable.
Then it happened quite misfortune. A new team has come to us and said that we are writing to Swift, and Doxygen is not at all friendly with it. We understood that it’s time to stop and invent something new. Then another couple of teams came, and we realized that our scheme could not be scaled at all. And we are constantly adding something, we have several of these scripts, they live in different branches and that's it. We realized that we need to accept that we were unlucky, try new approaches and find solutions. About them will tell you Andrew.
- We realized that in our case somewhere a universal generator came up, but for the most part, when we started to scale it all, the plan did not work. Invented cool, agreed with all that let's do, but it did not work out.
As a result, we began to invent a new scheme. She was with native generators. What we have now in the scheme? ( , ), , Objective-C Java, , .
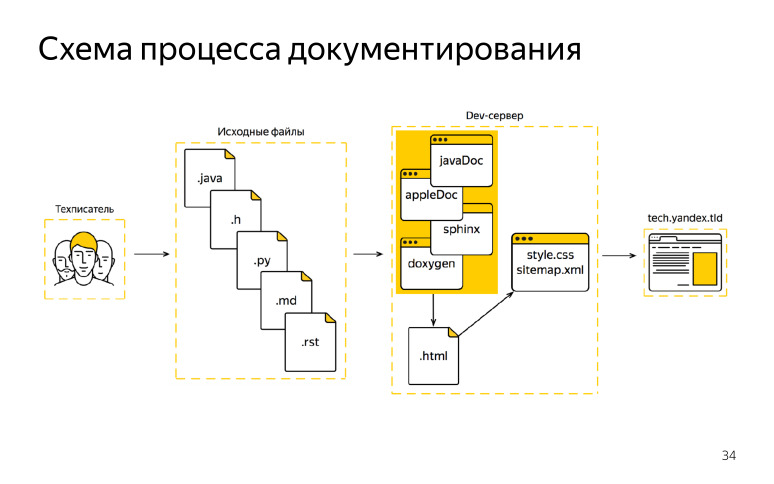
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. ( — . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .

, . . - , - , , , , , , . , , , , .
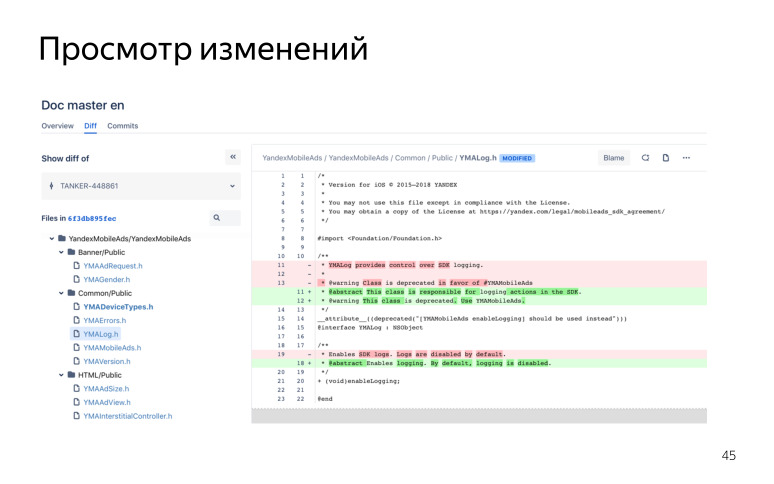
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .

, .
. - , . .

, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
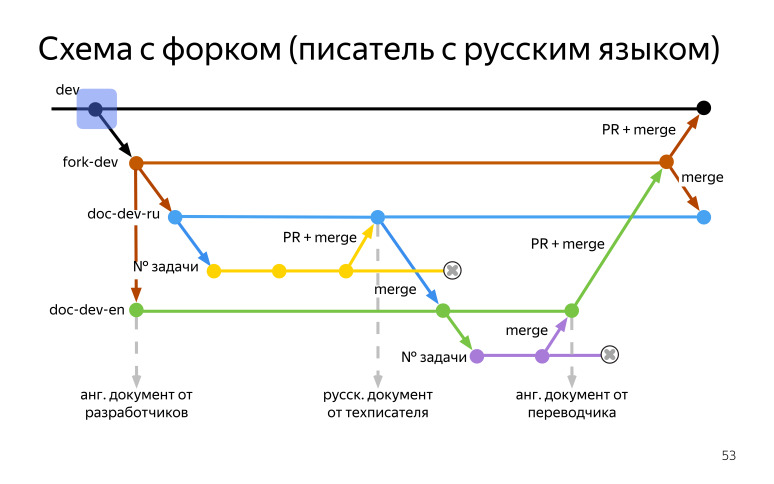
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .

, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
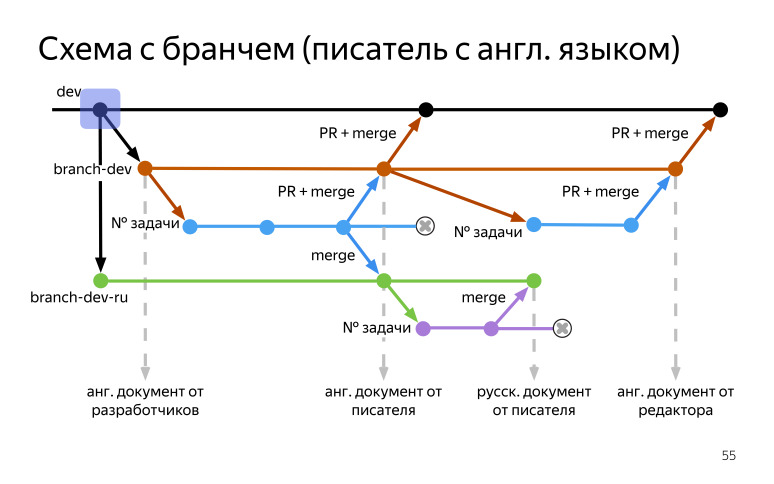
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .

, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
. , : . , . : , , . , — , — . , — , . That's all.
Svetlana Kayushina, head of documentation and localization department:
- The volume of software code in the world in recent years has grown dramatically, continues to grow, and this affects the work of technical writers, who are coming to more and more tasks to develop software documentation and document the code. We could not ignore this topic, we devoted a whole section to it. These are three interrelated reports devoted to the unification of the development of program documentation. I invite our specialists in documenting software interfaces and libraries Andrei Polyakov and Yulia Pivovarov. Give them the word.
- Hello! Today, Julia and I will tell you how in Yandex we have a new look at documenting the API and the SDK. The report will consist of four parts, the report of the hour, we will discuss and talk.
')
Let's talk about the unification of the API and the SDK, how we came to it, what we did there. We will share the experience of using a universal generator, one for all languages, and tell why it didn’t work for us, what were the pitfalls, and why we switched to generating documentation with native generators.
In the end we will tell how our processes were built.
Let's start with the unification. Everyone thinks about unification when there are more than two people in a team: everyone writes differently, everyone has their own approaches, and this is logical. It is better to discuss all the rules on the shore, before you start writing documentation, but not everyone succeeds.
We gathered an expert group to analyze our documentation. We did this to systematize our approaches. Everyone writes differently, and let's agree to write in the same style. This is the second point, for which we were going to try to make the documentation uniform, so that the user has one user experience in all the Yandex documentation, namely the technical one.
The work was divided into three stages. We have compiled a description of the technologies that we have in Yandex, which we use, have tried to select from them those that we can somehow unify. And also made the general structure of standard documents and templates.
Let us turn to the description of technology. We began to study what technologies are used in Yandex. There are so many of them that we are tired of writing them in some kind of notebook, and in the end we chose only the most basic ones, which are most often used, most often encountered by technical writers, and began to describe them.
What is meant by technology description? We have identified the main points and the essence of each technology. If we are talking about programming languages, then this is a description of such entities as class, property, interfaces, etc. If we are talking about protocols, then we describe HTTP methods, talking about the format of the error code, response code, etc. We have compiled a glossary containing the following things: terms in Russian, terms in English, usage nuances. For example, we are not talking about some kind of SDK method, that it ALLOWS to do something. It DOES something, if the programmer jerks some kind of pen, it gives some kind of answer.
In addition to the nuances, the description also contained standard structures, standard speech patterns, which we use in the documentation so that the recorder can take a specific wording and use it further.
In addition, technical writers often write pieces of code, snippets, samples, and for this we also described our own style guide for each technology. We turned to the developers of guides that are in Yandex. Drew attention to the design code, description of comments, indents and all that. We do this so that when a technical writer comes to a programmer with a piece of code or a written sample, the programmer looks at the essence, not how it is designed, and this reduces the time. And when a technical writer is able to write on Yandex style guides, this is very cool, maybe he wants to become a programmer later. The previous report was about various examinations. For example, you can move into programmers.
For tech writers, we also developed a quick start: how to set up a development environment when he becomes familiar with a new technology. For example, if the SDK technician is written in C #, then it comes in, sets up the development environment, reads the manuals, becomes familiar with the terminology. We also left links to official documentation and RFCs, if any. We made an entry point for technical writers, and it looks like this.
When a technical writer arrives, he studies a new technology and starts documenting it.
After we described the technology, we moved on to describing the structure of the HTTP API.
We have many different HTTP APIs, and all are described differently. Let's agree and do the same!
We have identified the main sections that will be in each HTTP API:
"Overview" or "Introduction": what this API is for, what it allows you to do, which host you need to contact to get some kind of answer.
“Quick start”, when a person goes through some steps and gets a successful result at the end, in order to understand how this API works.
"Connection / Authorization". For many APIs, an authorization token or API key is required. This is an important point, so we decided that this is a mandatory part of all APIs.
“Limits / Limits” when we talk about limits on the number of requests or the size of the request body, etc.
"Reference", reference. A very large part, which contains all the HTTP handles that the user can pull and get some result.
As a result, we had many different APIs, they were described differently, now we try to write everything the same. Such a profit.
Delving into the directories, we realized that the HTTP handle is almost always the same. You pull it, that is, you make a request, the server returns an answer - voila. Let's try to unify it. We wrote a template that tried to cover all cases. The technical writer takes the template, and, if he has a PUT request, he leaves the necessary parts in the template. If he has a GET request, he uses only those parts that are needed for a GET request. A generic template for all queries that can be reused. Now you do not need to create a document structure from scratch, but you can simply take a ready-made template.
Each pen describes what it is for, what it does. There is a section "Request format", which contains path-parameters, query-parameters, everything that comes in the body of the request, if it is sent. We also highlighted the section "Answer format": we write it if there is an answer body. A separate section, we have identified the "response codes", because the response from the server comes regardless of the body. And left the section "Example". If we supply an SDK with this API, then we say that use the SDK like this, pull such a handle, call such a method. Usually we leave some example with cURL, where the user simply inserts his token. And if we have a test bench, then simply takes the request and executes it. And gets some result.
It turns out that there were many pens, they were described differently, and now we want to bring it all to a single form.
After we finished with the HTTP API, we moved to the mobile SDK.
There is a general structure of the document, it is about the same:
- “Introduction”, where we say that this SDK is used for such purposes, integrate it for such purposes, for such OSs it will do, we have such versions, etc.
- “Connection”. Unlike the HTTP API, we are not just talking about how to get the key for using the SDK, if you need one, we are talking about how to integrate the library into your project.
- "Examples of using". The largest section in terms of volume. Most often, developers want to come into the documentation and not read a lot of information, they want to copy a piece, paste it, and everything will work for them. Therefore, we considered this part to be very important and made it a mandatory section.
- “Reference book”, reference, but unlike the HTTP API reference, we cannot unify everything here, since we basically generate reference books and we will talk about this later in the report.
- “Releases”, or changelog, changelog. Mobile SDKs usually have a short release cycle, somewhere around two weeks a new version is released. And it would be better for the user to talk about what has changed, should he be updated or not.
At the same time, the API has both mandatory sections that we see and sections that we recommend to use. If the API is updated frequently, we say that then paste yourself also the change history, what has changed in the API. And often we have API rarely updated, and as a mandatory section it is pointless to specify it.
So, we had a lot of SDK, which were described in different ways, we tried to turn about one style. Naturally, there are additional differences inherent only in this SDK or this HTTP API. Here we have the freedom to choose. We do not say that apart from these sections, no one can be done. Of course, you can, we simply try to do the listed sections everywhere, so that it is clear that if the user has moved to the documentation for another SDK, he knows what will be described in the “Connection” section.
So, we came up with templates, made guides, what is our action plan now? We decided that if we scale API changes, change pens or change SDK, we take new templates, take a new structure and start working on it.
If we write documentation from scratch, then, of course, we again take a new structure, take new templates and work on them.
And if the API is outdated, rarely updated, or no one supports it, but it exists, then it is a little resource-intensive to redo it. We just decided to leave it until it will be so, but then, when resources appear, we will definitely return to them, we will do all this well and beautifully.
What are the advantages of unification? They should all be obvious:
“UX”, we are thinking of making the user feel at home in our documentation. He came, and he knows what is described in sections, where he can find authorization, examples of use, description of the pen. It's great.
For tech writers, the description of the technology allows you to define a certain entry point, where it comes, and begins to get acquainted with this technology, if he did not know it, begins to understand the terminology, dive into it.
The next point is interchangeability. If the technical writer went on vacation or simply stopped writing, then another technical recorder knows how it works inside when entering the document. It is immediately clear what is described in the connection, where to look for information on the integration of the SDK. Understanding and making small edits in a document becomes easier. It is clear that each project has its own specifics, you can not just come and document a project without knowing it completely. But at the same time, the structure, that is, file navigation, will be approximately the same.
And, of course, common terminology. We agreed with the developers and with the translators the terminology that we made for languages. We say that we have C #, there is such a term, we use it that way. We asked the developers what terminology they used and wanted to achieve synchronization in this place. We have agreements, and the next time we come with the documentation, the developers know that we have agreed terms with them, guides, we use these templates, we take into account the nuances of their use. And the translators, in turn, know that we describe the SDK in C # or Objective-C, which means this terminology will correspond to what is described in the guide.
Guides were written in wiki pages, so if there is an update of languages, technologies, protocols, this is all easily added to an existing document. Idyll.
The sooner you start to unify and negotiate, the better. It is better that later there is no legacy of documentation that is written in a different style that breaks the user's flow in the documentation. Better to do it all before.
Attract developers. These are the people for whom you are writing documentation. If you have written yourself some guides, they may not like it. It is better to agree with them so that you have a common understanding of terminology: what you write in the documentation, how you write it.
And also negotiate with the translators, they all translate. If they translate differently than developers are used to, there will again be conflicts. ( Here is a link to a fragment of a video with questions and answers - Ed.) Go ahead.
Yuliya:
- Hi, my name is Julia, I have been working at Yandex for five years now and have been documenting the API and SDK in Andrei’s group. Usually, everyone talks about good experience, how great it all turns out. I will tell you how we chose a not entirely successful strategy. At that time, she seemed successful, but then came the harsh reality, and we were a little unlucky.
We initially had several mobile SDKs, and they were written mostly in two languages: Objective-C and Java. We wrote documentation to them manually. Over time, classes, protocols, and interfaces grew. They became more and more, and we realized that we need to automate this business, we looked at what technologies are there.
At that moment, we liked Doxygen, it met our needs, as it seemed to us, and we chose it as a single generator. And we drew such a scheme that we expected to get, we wanted to work on it somehow.
What did we have? The technical writer came to work, received source code from the developer, started writing his comments, edits, after that the documentation had to be sent to our devserver, we started Doxygen, received the XML format, but it did not fit our DITA XML standard. We knew about it beforehand, wrote a certain converter.
After we received the output from Doxygen, we passed all this through the converter and received our format. Further the collector of documentation was connected, and we published all this on the external domain. We even got lucky with a couple of iterations, everything worked out for us, we were delighted. But then something went wrong. The technical writer also went to work, got the tasks and source codes from the developer, made his own edits there. After that he went to the devserver, started Doxygen and there was a fire.
We decided to figure out what was wrong. Then we realized that Doxygen does not quite fit all languages. We had to analyze the code, on which it stumbled, we found constructs that Doxygen did not support and did not plan to support.
We decided, since we are working in this scheme, we will write a preprocessing script, and we will replace these constructions in some way with what Doxygen accepts, or in some way ignore them.
Our cycle began to look like this. We received the source code, concluded them on the devserver, then connected the preprocessing script, cut out all the extras from the code, followed by Doxygen, then received the output format Doxygen, also started the converter, received our final DITA XML files, then the documentation collector connected, and we published our external domain documentation. It seems everything looks good. Added a script, what is it? Initially, it was all nothing. The script had three lines, then five, ten, and it all grew to hundreds of lines. We realized that we are starting to spend most of the time not on writing documentation, but on analyzing the code, looking for something that doesn’t crawl, and just appending the script in endless regulars, sitting to distraction and thinking what's the matter.
We realized that we need to change something, to somehow stop before it is too late, and until our release cycle has not completely collapsed.
As an example, something like the preprocessing script initially looked like, and was harmless.
Why did we initially choose this path? Why did he seem good?
One generator is great, took it, once connected it, set it up and it works. It seemed like a good approach. In addition, you can use the same comment syntax for all languages at once. You wrote some kind of guide, use it once, immediately insert all these constructions into the code and do your work, write comments, and not somehow dwell on the syntax.
But it turned out to be one of the big drawbacks. Our uniform syntax was not supported by the developers, they used to use their IDE, there are already native generators, and their syntax did not coincide with ours. This was a sticking point.
Also, Doxygen poorly supported new features in languages. He has a selective approach, since he himself is written in C ++, he mainly supports C-like languages, and the rest on the residual principle. But languages are improving, Doxygen doesn’t quite keep up with them, and we feel very uncomfortable.
Then it happened quite misfortune. A new team has come to us and said that we are writing to Swift, and Doxygen is not at all friendly with it. We understood that it’s time to stop and invent something new. Then another couple of teams came, and we realized that our scheme could not be scaled at all. And we are constantly adding something, we have several of these scripts, they live in different branches and that's it. We realized that we need to accept that we were unlucky, try new approaches and find solutions. About them will tell you Andrew.
- We realized that in our case somewhere a universal generator came up, but for the most part, when we started to scale it all, the plan did not work. Invented cool, agreed with all that let's do, but it did not work out.
As a result, we began to invent a new scheme. She was with native generators. What we have now in the scheme? ( , ), , Objective-C Java, , .
, DITA XML, , , , XML. HTML, . — JavaDoc, AppleDoc, Jazzy. HTML, . HTML, , . , HTML . , , , HTML, . XML , . .
.
— . Doxygen , , . Objective-C, , Java . . , , IDE , IntelliSense, , , , SDK, , . .
, , SDK , , , , HTML, . , , , , , .
. , - , . XML , XML . Doxygen , XML . HTML, XML . . — .
, , . 1500 , : HTML, CSS, .
, , .
. ( — . .)
, , .
— . , . -, . , . ? .
? -, , , , .
- , - , . .
? -, , , , .
. , , , , , , , .
, . , , , , , , .
? — , , , , , . . Bitbucket, - . , .
, . . - , - , , , , , , . , , , , .
, , .
, SDK , - , , . -, , , , .
, . . — , , .
, . . .
, , , , , , .
, .
. - , . .
, , , , . . , , , - . , . , , .
, .
. , . , , .
, , , — . , , , .
dev , (fork-dev) , . , doc-dev-en, . , , - , , .
(fork-dev) (doc-dev-ru) . , - . . , , doc-dev-ru, . , , - , .
, . (doc-dev-en). , , (doc-dev-en), , . , (fork-dev). , , , , . , , . , dev . , , , .
(fork-dev), , . (fork-dev), , (doc-dev-en), . , , , . , .
, , . dev, (fork-dev) , (doc-dev-ru) (doc-dev-en) . (doc-dev-en), (doc-dev-ru) . , .
. dev , , (branch-dev). (branch-dev-ru), (branch-dev). , . , . — , — - , , , , .
, , . , , (branch-dev) . , , .
dev. , , , , . .
(branch-dev-ru), , (branch-dev-ru), . .
. (branch-dev), . , , , , , , , , . , , . , , .
, , , , . .
, ? , , . . . , - , . . , .
, , , , , .
, . . . . , , .
— — . — .
. . , . , , , , , , . .
, . . . . , . , . - , . — . .
. , : . , . : , , . , — , — . , — , . That's all.
Source: https://habr.com/ru/post/428057/
All Articles