MIT course "Computer Systems Security". Lecture 14: "SSL and HTTPS", part 1
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
Lecture 2: "Control of hacker attacks" Part 1 / Part 2 / Part 3
Lecture 3: "Buffer overflow: exploits and protection" Part 1 / Part 2 / Part 3
Lecture 4: "Separation of privileges" Part 1 / Part 2 / Part 3
Lecture 5: "Where Security Errors Come From" Part 1 / Part 2
Lecture 6: "Opportunities" Part 1 / Part 2 / Part 3
Lecture 7: "Sandbox Native Client" Part 1 / Part 2 / Part 3
Lecture 8: "Model of network security" Part 1 / Part 2 / Part 3
Lecture 9: "Web Application Security" Part 1 / Part 2 / Part 3
Lecture 10: "Symbolic execution" Part 1 / Part 2 / Part 3
Lecture 11: "Ur / Web programming language" Part 1 / Part 2 / Part 3
Lecture 12: "Network Security" Part 1 / Part 2 / Part 3
Lecture 13: "Network Protocols" Part 1 / Part 2 / Part 3
Lecture 14: "SSL and HTTPS" Part 1 / Part 2 / Part 3
Now we will look at how cryptographic protocols are used to protect network connections on the Internet and how they generally interact with network factors. Before we dive into the details, I want to remind you that there will be a test on Wednesday, but not in this audience, but in the Walker, on the 3rd floor, during normal lecture time.
')

So today we will talk about how the Internet uses cryptography to protect a network connection, and consider two closely related topics.
The first is how to cryptographically protect connections on a larger scale than is protected by the Kerberos system, which we covered in the last lecture. The second is how to integrate this cryptographic protection provided at the network level into the whole application, and how the web browser guarantees the use of protection provided by the cryptographic protocol. These topics are closely related, so it turns out that the protection of network communications is fairly easy to provide, because cryptography always works. But integrating it into the browser is a much more difficult task than building a system around cryptography.
Before we dive into this discussion, I want to remind you of the basic elements of cryptography that we will use.
In the last lecture on Kerberos, we used symmetric cryptography, or
encryption and decryption. Its meaning is that you have a secret key K and two functions. Thus, you can take some piece of data, call it P, this is plain text, to which the encryption function can be applied, and this is the function of some key K. And if you encrypt this plain text, you will receive the encrypted text C. Similarly, we there is a decryption function D that uses the same key K, as a result of which the ciphertext C will turn into plain text P. This is the primitive around which Kerberos was built.

But it turns out that there are other primitives that will be useful for today's discussion, and which are called asymmetric encryption and decryption. Here the idea is to have different keys for encryption and decryption. Let's see why this is so useful.
Here, there is a function E, which can encrypt a certain set of messages P with a certain public key pk, in order to get ciphertext C as a result.
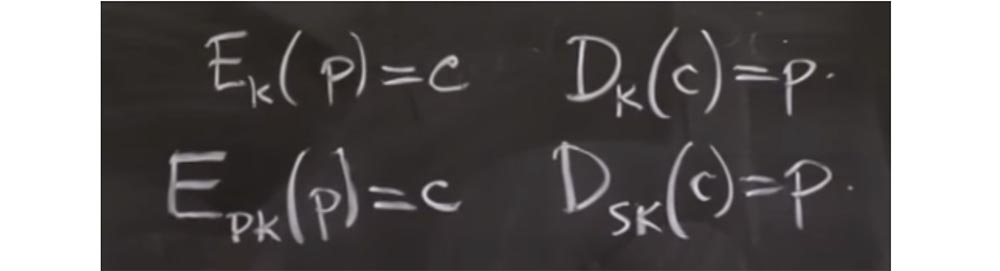
The convenience of asymmetric encryption is that you can publish a public key on the Internet, and people can encrypt messages for you, but you need a secret key to decrypt their messages. Today we will see how it is used in the protocol. In practice, you will often use public key cryptography a little differently. For example, instead of encrypting and decrypting messages, you might need to sign or verify messages.
It turns out that at the implementation level these are related operations, but at the API application level, they may look a little different. For example, you can sign message M with your private key sk and get some signature S. Then you can verify this message with the corresponding public key pk and as a result get a boolean flag indicating whether signature S is correct for message M.
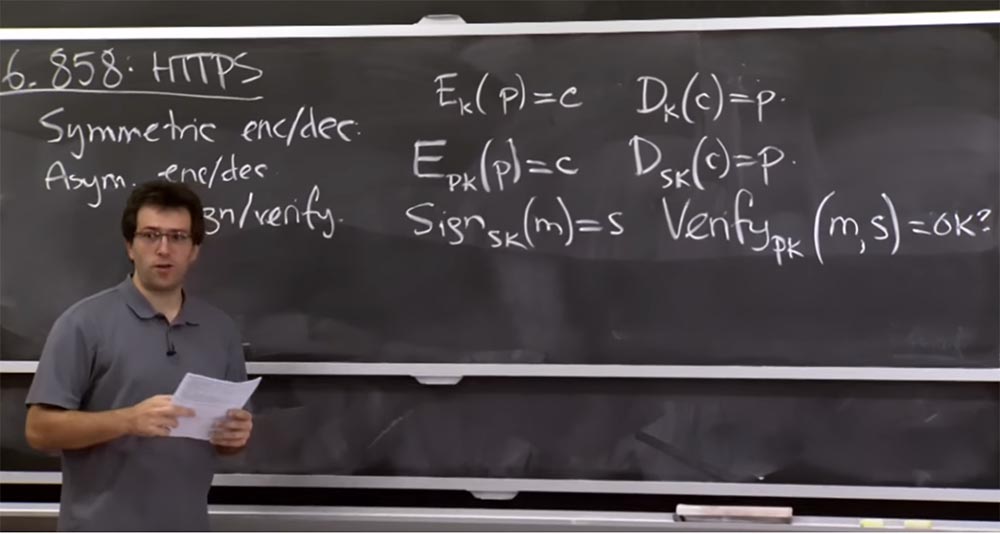
Here are some relatively intuitive guarantees that provide these functions. If you, for example, received this signature and it is verified correctly, it means that it had to be generated by someone with the correct secret key. It's clear?
Then we’ll try to figure out how to protect network connections on a larger scale than Kerberos does. In Kerberos, we had a fairly simple model, where all users and servers used a kind of connection with the KDC object, which had this giant table of users, services, and their keys. Whenever a user wants to talk to a server, he must ask the KDC to create the ticket he needs based on this giant table.
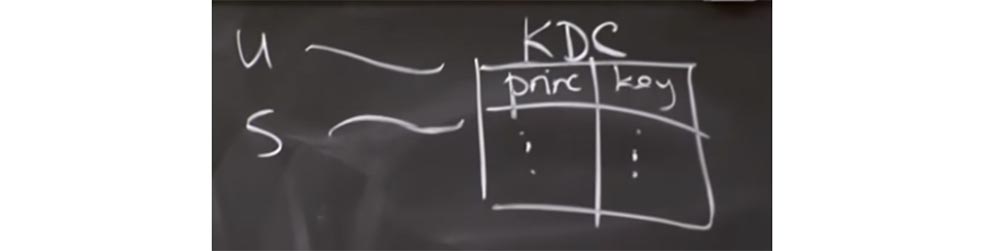
Thus, this seems like a fairly simple model. So why do we need something else? Why is Kerberos not good enough to work with sites? Why doesn't the Internet use Kerberos exclusively to secure all connections?
You answered correctly - because the only KDC has to trust everything, and this is bad. You may have problems if you think that a certain machine is absolutely safe.
Perhaps people at MIT are willing to trust someone on a local network managed by the KDC, but not everyone on the Internet.
And the answer of the second student is also correct - it is very difficult to manage such a huge number of keys. In fact, it can be very difficult to build a single KDC that can manage a billion keys or ten billion keys for all people in the world. Another difficulty in using Kerberos for the entire Internet is that all users must have a key, or the KDC must be known. You cannot even use Kerberos at our institute to connect to some servers if you do not have an account in the Kerberos database. While for the entire Internet it is quite reasonable to expect that when you get to the computer, it doesn’t know at all who you are, but will allow you to go to the Amazon site, protected by cryptography.

Yes?
There are several other things you would expect from a cryptographic protocol, and we will look at how they appear in SSL. But the key idea is that this solution is the same for Kerberos and for SSL or TLS. You are right when you mention that the original Kerberos protocols that we read about in the lecture materials were developed a long time ago. And if we want to use them for the modern Internet, then they will need to change something. What other thoughts do you have, why shouldn't we use Kerberos?
That's right, there is a scaling problem here when restoring access, and, possibly, when registering new users, because you will have to personally go to some office accounts and get an account there. What else?
Student: Kerberos server should always be online.
Professor: yes, this is another problem. We have listed some sort of management issues, but at the protocol level the KDC should always be online, because it actually serves as an intermediary for any interaction with services. This means that every time you visit a new website, you need to talk to the KDC. First, it will be a bottleneck in terms of performance. Like another form of scalability, this principle will lead to performance scalability, while the principles listed above only lead to management scalability.

So how can we solve this problem with these principles? The idea is to use key encryption to stop using the KDC.
Let's first find out if you can establish a secure connection if you just know some of the other party’s public keys. And then we will see how we connect the version of the KDC public key to the authentication of the parties in this protocol. If you do not want to use the KDC, then you could do the following with public-key cryptography: somehow find out the partner's public key from the other side of the connection. So, in Kerberos, if I want to connect to a file server, I just know the public key of the file server from somewhere. As a freshman, I get a printout that says the public key of the file server is such and such, and I can use it to connect.
You could just encrypt the message for the public key of the file server to which you want to connect. But it turns out that, in practice, these operations with these public keys are rather slow. They are several orders of magnitude slower than the operation of symmetric encryption keys. So in practice, you usually always want to abandon the use of public encryption.
Thus, a typical protocol might look like this. You have A and B, they want to communicate, and A knows the public key B. At the same time, A generates some session key S simply by selecting a random number for it. Then A is going to send B the session key S, so it looks like Kerberos. We are going to encrypt session key S for B.
If you remember, in Kerberos, to do this, we needed a KDC, because A did not know the key for B or he was not allowed to know it, because it is a secret that only B. can know. But with the public key you can do it immediately, just encrypting the secret with this public key Bspk, and send message B. Now B can decrypt this message and say: I need to use this secret key. Now we have a communication channel, where all messages are simply encrypted with this secret key S.

So there are some useful properties in this protocol. First, we got rid of the need to have a KDC online and generate a session key for us. We could simply ensure the confidentiality of the information sent if one of the parties to the connection generates it and then encrypts it for the other party without using the KDC.
Another good thing is to make sure that messages sent from A to B can only read B, because only B can decipher this message. Therefore, B must have the corresponding secret key S.
Student: Does it matter who gives this key - user or server?
Professor: maybe. I think it depends on the properties you want to get from this protocol. Therefore, if A is mistaken or uses incorrect randomness, the server that sends the data back thinks: “oh, now this is the only data that A sees.” It may not be entirely right, so you should think about it. There are several other problems with this protocol.
Student: Can an attacker use a key to send repeated messages?
Professor: yes, the problem may be that I can just send these messages again, and it will look like it’s A again sends message B, and so on.
Therefore, usually the solution to this problem is that both sides of the connection are involved in generating S and this ensures that the key that we use is “fresh”. Because here, in the figure, in fact, B does not generate anything, so these protocol messages look the same every time.
It usually happens that one side selects a random number like S, and then the other side, B, also selects a random number, usually called nonce. There are two numbers and a key that is not actually chosen by one side alone, this is a hash that both sides have chosen to work together. In addition to the hash, you can use the Diffie-Hellman protocol, which we discussed in the last lecture, thanks to which you get privacy at the beginning. This is more complicated mathematics than the simple hashing of two random numbers that have chosen these two sides. But then you will receive such a good property as the original shared secret key, which eliminates the need to transfer the decryption key when transferring encrypted data.
Thus, to avoid repeated attacks as follows. B generates nonce and then sets the real secret key S ', which is used to hash the secret key S with this nonce. And, of course, B would have to send nonce back to A to find out what happens when they both agree on a key.
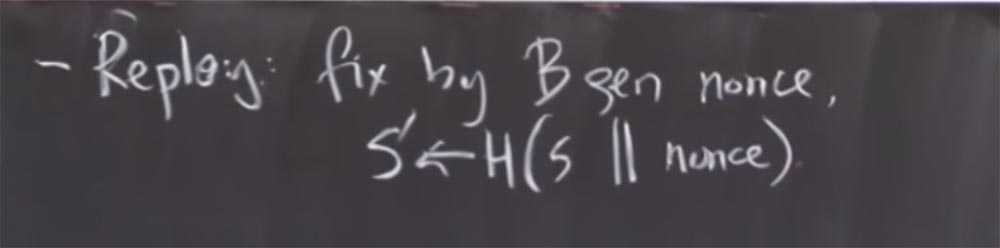
Another problem is that there is no real authentication A. A. knows who B is, or at least knows who can decrypt the data. But B has no idea who is on the other side, whether it’s some adversary, impersonating another, or someone else. How can this be fixed in the public key world?
There are several ways to do this. One possibility is to initially sign this message, because we have this good Sign principle. So we could possibly sign it with a secret key. This Sign simply provides a signature, but presumably, you assign it, and you also provide this message.
Then B needs to know that A is a public key to verify the signature. But if B knows that A is a public key, then B will be confident enough that A is the one who sent the message.

Another thing you could do is trust in encryption. So perhaps B can send nonce back to A, encrypting it with the public key provided by A. And then only A can decrypt nonce and generate the final session key S '. So there are a few tricks you could do. This is how client certificates work in Internet browsers today.
Thus, A has a secret key, and therefore, when you receive a personal MIT certificate, your browser creates a long-lived secret key and receives a certificate for it. And whenever you send a request to the web server, you prove that you know the secret key of your user certificate, and then set the secret key S for the rest of the connection.
These are problems that are simply corrected at the protocol level. However, the basis for all of the above is that all parties know each other’s public keys. How can you know someone's public key? Suppose I want to connect to a website, I have a URL to which I want to connect, or a host name, how do I know which public key corresponds to it?
Similarly, if I connect to the MIT server to view my grades, how does the server know what my public key should be in order to distinguish it from another MIT student's public key?
This is the main problem that the KDC considered. In fact, the KDC solved two problems for us. First, it generated a message (Ebspk (S)), created a session key and encrypted it for the server. Now we fixed this by creating public key cryptography. But we also needed to perform the mapping of the main string names to the Kerberos cryptographic keys provided to us earlier.
For such things in the HTTPS world there is a TLC protocol. Its meaning lies in the fact that we will continue to rely on some aspects of the process that support these gigantic tables that match the names of the process participants with the cryptographic keys. The plan is that we will have something called a certificate authority, which is denoted by the letters CA in all kinds of network security literature. This CA also logically maintains a table, in one part of which the names of all participants are displayed, and in the other, the corresponding public keys. The main difference between this center and Kerberos is that this CA does not have to be online for all transactions.
In Kerberos, in order to connect with someone or find someone's key, you need to talk to the KDC. Instead, in the world of CA do this way.

If you have some name here and the corresponding key key in another part of the table, then the certification authority is going to simply sign messages that there are certain rows in this table. Thus, the certificate authority will need to have its own private and public keys here. He will use the secret key to find messages for other users on the system on whom you can rely.
So if you have a “name + key” entry in the CA database, the CA will create a message that this name corresponds to this public key, and sign this message with its CA secret key.
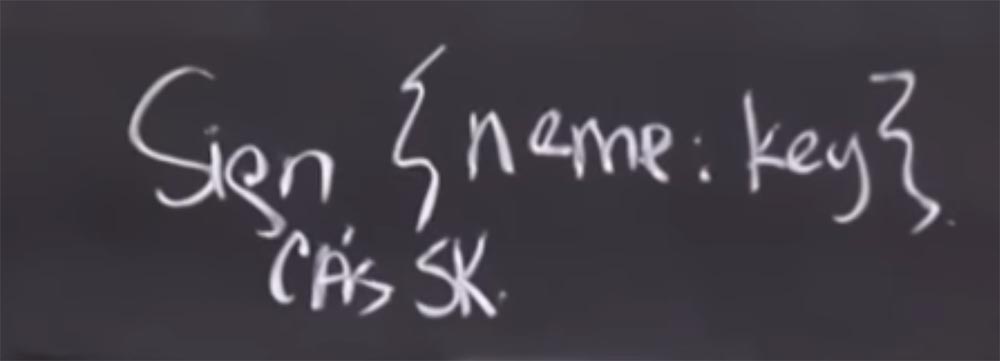
This allows you to do things that are very similar to what Kerberos does, but at the same time we eliminate the need to find CA online for all transactions. And, it will actually be much more scalable. This is exactly what is commonly called a certificate. Scalability is ensured by the fact that for a client or anyone else using this system, a certificate provided from one source is not inferior to a certificate from any other source. It is signed with the secret key of the certification authority. So you can verify its authenticity without actually having to contact a certification authority or any other party specified here.
It works like this. The server you want to talk to stores the certificate that it originally received from the certification authority. And whenever you connect to it, the server tells you: “OK, here is my certificate. It was signed by this CA. You can verify the signature and just make sure that it is my public key and that is my name. ”
On the other hand, the same thing happens with client certificates. When a user connects to a web server, his client certificate indicates that your public key corresponds to the private key that was originally generated in the browser. Thus, when you connect to the server, you are going to submit a certificate signed by a certificate authority MIT, which indicates that your username corresponds to this public key. , , , , Athena.
: , ?
: , , – , ? - , , , , . - , . . , VeriSign. US Postal Service CA, , . , CA , KDC.
, , Kerberos. , , KDC. , KDC, , . , , . CA , KDS.
: ?
: , . , , KDC, . , . , , . , , , . Kerberos, . Kerberos , . , , . , , . , .
, . , , CA - , . , amazon.com, amazon.com. CA, . , , , .

. , CA , , , , - , . , , . - , amazon.com, , - .
, -, , , , . , . «» , , .
, . -, CRL, ertificate Revocation List. . , - , . , , , : «, , , - . , ».
, , , CRL, , web-, CRL. , - , , . , , , , , .
, . , . , . , . , CRL, - .
, ? , . , CRL .
, , , Kerberos, KDC. CA , . , « SSL », OCSP. CA KDC. , , , , , , - . , OCSP, : «, . , »? , CRL . , , . , , .
26:30 min
MIT course "Computer Systems Security". Lecture 14: "SSL and HTTPS", part 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/427783/
All Articles