MIT course "Computer Systems Security". Lecture 13: "Network Protocols", part 1
Massachusetts Institute of Technology. Lecture course # 6.858. "Security of computer systems". Nikolai Zeldovich, James Mykens. year 2014
Computer Systems Security is a course on the development and implementation of secure computer systems. Lectures cover threat models, attacks that compromise security, and security methods based on the latest scientific work. Topics include operating system (OS) security, capabilities, information flow control, language security, network protocols, hardware protection and security in web applications.
Lecture 1: "Introduction: threat models" Part 1 / Part 2 / Part 3
Lecture 2: "Control of hacker attacks" Part 1 / Part 2 / Part 3
Lecture 3: "Buffer overflow: exploits and protection" Part 1 / Part 2 / Part 3
Lecture 4: "Separation of privileges" Part 1 / Part 2 / Part 3
Lecture 5: "Where Security Errors Come From" Part 1 / Part 2
Lecture 6: "Opportunities" Part 1 / Part 2 / Part 3
Lecture 7: "Sandbox Native Client" Part 1 / Part 2 / Part 3
Lecture 8: "Model of network security" Part 1 / Part 2 / Part 3
Lecture 9: "Web Application Security" Part 1 / Part 2 / Part 3
Lecture 10: "Symbolic execution" Part 1 / Part 2 / Part 3
Lecture 11: "Ur / Web programming language" Part 1 / Part 2 / Part 3
Lecture 12: "Network Security" Part 1 / Part 2 / Part 3
Lecture 13: "Network Protocols" Part 1 / Part 2 / Part 3
So today we’ll talk about Kerberos, a cryptographically secure protocol designed for mutual authentication of computers and applications on the network. This is a protocol for authenticating a client and server before establishing a connection between them.
')
So now, finally, we will use cryptography, unlike the last lecture, where we looked at security only with the help of TCP SYN sequence numbers.

So let's talk about Kerberos. What is trying to support this protocol? It was created at our institute 25 or 30 years ago as part of the Athena project to ensure the interaction of multiple server computers and multiple client computers.
Imagine that you have a file server somewhere. This could be a network-connected mail server or other network services, such as printers. And all this is simply connected to a network, and not processes on the same computer.

The prerequisite for the creation of Athens and Kerberos was the fact that you had a machine for simultaneous sharing, where everything was a separate process, and everyone could just enter the same system and store their files there. Therefore, the developers wanted to create a more convenient distributed system.
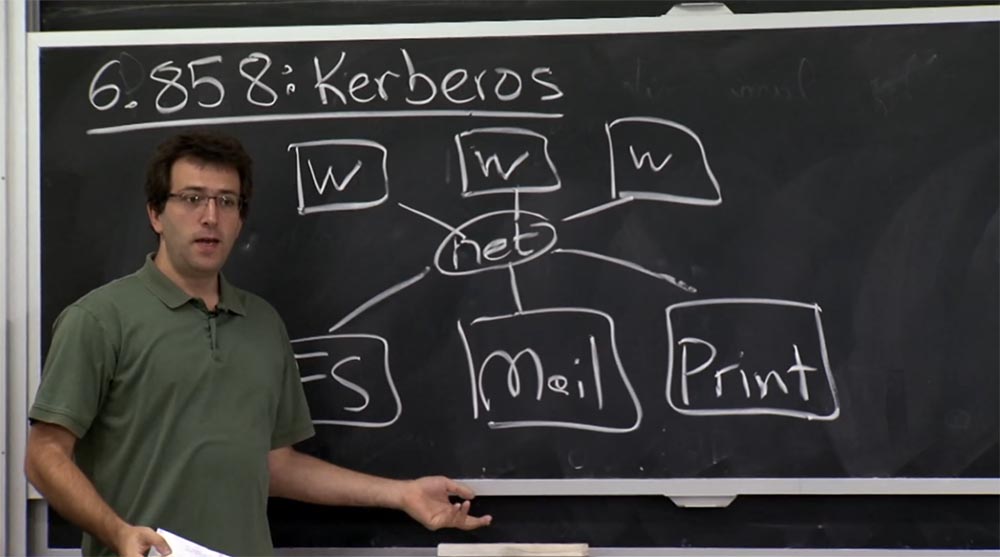
Thus, this meant that on one side you would have these servers, and on the other - a bunch of workstations that users will use themselves and on which applications will run. These workstations will connect to these servers and store user files, receive their mail, and so on.
The problem they wanted to solve was how to authenticate users who use these workstations for all these different computers in the server side, without having to trust the network and verify its correctness. This in all respects was a reasonable design requirement. I have to mention that at that time the alternative to Kerberos was the R login commands, discussed in the last lecture, which seemed like a bad plan, as they simply use their IP addresses to authenticate users.
Kerberos was quite successful, it is actually still used on the MIT network and is the core of Microsoft’s Active Directory server. Almost every Microsoft product based on the kind of Windows Server uses Kerberos in one form or another.
But this protocol was developed 25 or 30 years ago, and since then changes have been needed, because today people understand security much more. Thus, today's version of Kerberos is noticeably different in many respects from the version described in the materials for this lecture. We will consider which assumptions are not good enough today and what was wrong with the first version. This is unavoidable for the first protocol that actually used cryptography to authenticate network participants in a full-scale system.
In any case, the diagram shown on the board is a kind of setup for creating Kerberos. It is interesting to find out what the model of trust is here. Therefore, an additional structure is introduced into our scheme - the Kerberos server located here at the side.
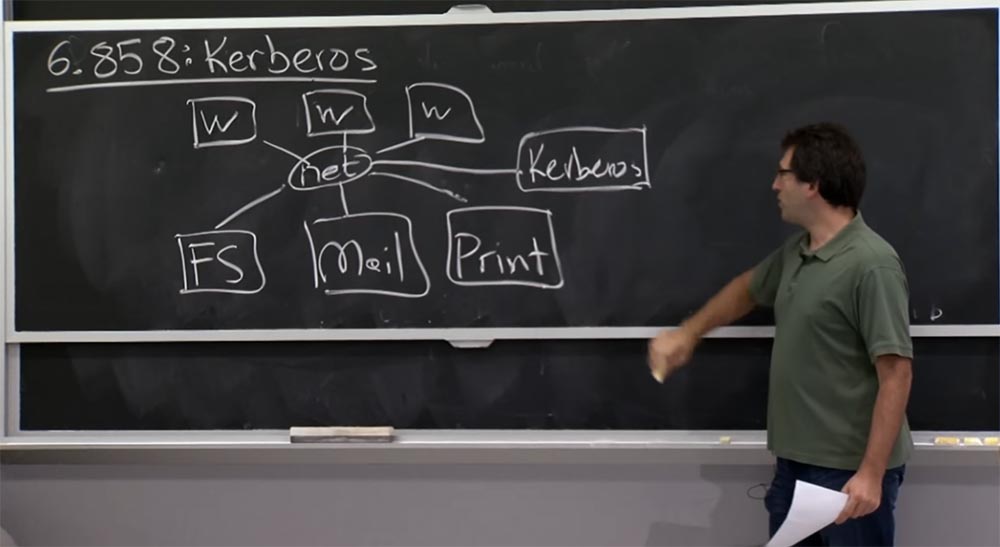
Thus, our third model is in some sense based on the fact that the network is unreliable, as we mentioned in the last lecture. Who should we trust in this Kerberos scheme? Of course, all members of the network must trust the Kerberos server. Thus, the creators of the system at one time assumed that the Kerberos server would be responsible for all checks of network authentication in one form or another. What else do we have on this network, what can we trust?
Student: users can trust their own machines.
Professor: yes, this is a good argument. There are users I didn't draw here. But these guys use some kind of workstation, and in fact, in Kerberos it’s very important that the user trusts his workstation. What happens if you do not trust your workstation? Because if the user does not trust the workstation, then there you can simply "smell out" your password and act on your behalf.
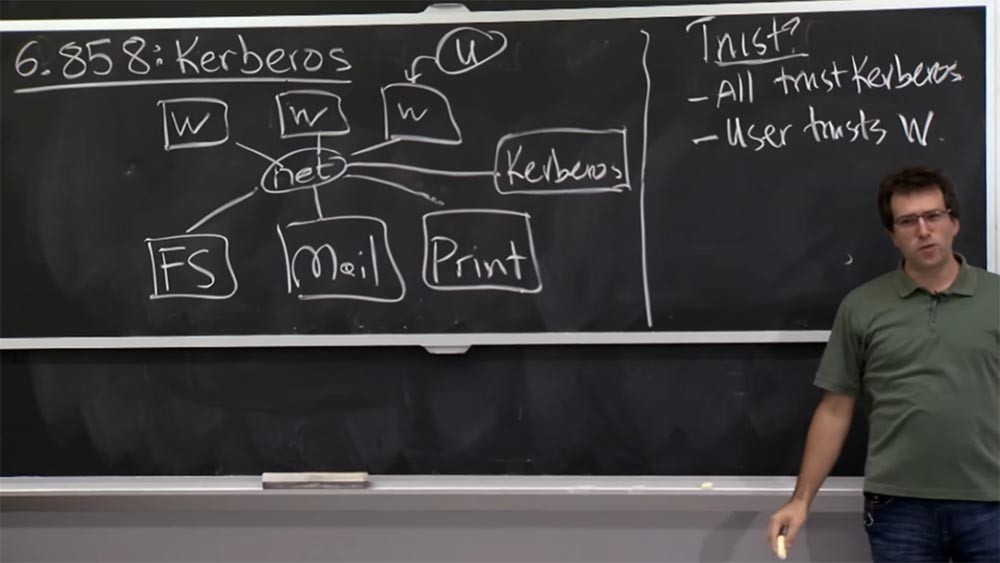
Student: An attacker can do much more, for example, by finding out your ticket to the Kerberos server.
Professor: yes, exactly. When you log in, you enter your password, which is even worse than a ticket. So actually, here there is a small problem with Kerberos, if you do not trust the workstation. If you use your own laptop, it is not so bad, but the security of a public computer is in doubt. We will look at what exactly might go wrong in this case.
Student: you must trust server administrators and be sure that they can have privileged access to each other’s servers.
Professor: I think that the machines themselves do not have to trust each other, for example, the mail server does not have to trust the print server or the file server.
Student: not to trust, but to be able to access a server that is not supported access through another server.
Professor: yes, that's true. If you establish a trust relationship between the mail server and the print server, but at the same time simply for convenience, give the mail server access to your files on the file server, then this can be misused. So you should be careful about introducing additional levels of trust or redundant trusting relationships here.
What else matters here? Should servers somehow trust users or workstations? I guess not. The global goal of Kerberos was that a server should not, a priori, know all these users or workstations, or know how to authenticate them, until these users can cryptographically prove that they are legitimate users and should have access to their data or something. more than the server manages.
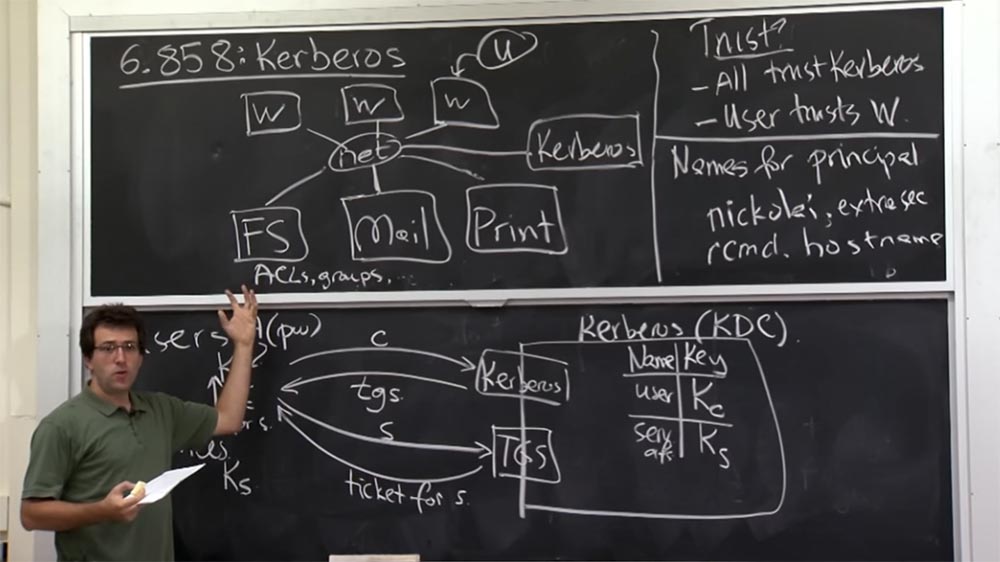
Let's take a look at how Kerberos works and what its overall architecture is. Let's draw the Kerberos server on a larger scale. Nowadays, it is called the KDC - Key Distribution Center, or Key Grant Center. Somewhere here are located users and services to which you can connect. The plan is that the Kerberos server will be responsible for storing a shared key for communication between the Kerberos server and each computer entity in the world around it. Thus, if the user has some client key Kc, then the Kerberos server remembers this key and stores it somewhere inside of it. In the same way, the Ks key for the service will be known only to this service itself, the Kerberos server, and no one else. So you can think of it as a general use of passwords, when you know the password and Kerberos knows it, but nobody else knows it.

So you're going to prove to each other that "I am the very same guy." Of course, the Kerberos server will have to track who owns this key, so it must have a table in which user names and services will be stored, for example, serv afs (this is a file server), and the corresponding keys.
In this case, the KDC is responsible for storing a giant table, not very large in terms of the number of bytes, but very voluminous in terms of the number of records, because it takes into account any computer entity that lives in the MIT network, which the Kerberos server should know about. Thus, we have two kinds of interface.

In the materials of the lecture this is not clearly stated, that is, the existence of these 2 interfaces is simply implied. In fact, there are actually two interfaces for one machine. One of them is called Kerberos, and the second is TGS, Ticket Granting Service, or Ticket Service.
In fact, in the end, these are just two ways to talk about the same thing, and the protocol is only slightly different for these two things. Therefore, initially, when a user logs in, he “speaks” with the upper interface, Kerberos and sends him his client name C, this can be your username on the Athena university network.
The server responds to this request with a tgs ticket or ticket information; we will look at the details of this information a little later. Then, when you want to talk to some service, you will first have to contact the TGS interface and tell him: “I have already logged into the system through the Kerberos interface and now I want to talk to the S server, which will provide me with a certain service.”
So you tell the TGS about the server you want to talk with, after which it will return you something like a ticket to talk to server S. Then you can finally talk to the server you need, using the received ticket for server S.
This is a kind of high level plan. So why is it using 2 interfaces? Many questions can be asked about this. In the case of the Ks server, this service is likely to be stored on disk. And what happens to this Kc on the user's side? Where does this Ks come from in Kerberos?

Student: this Kc must be in the database, in the table of the KDS server.
Professor: Yes, well, the C key is here in the table, in this gigantic database. But it must also be known to the user, because the user must prove that he is a user.
Student: is it a one-way function that then requires a password?
Professor: yes, they actually have such a smart plan, where Kc is obtained by hashing a user password or some kind of key generation function, for this there are several different techniques. But basically we take the password, convert it in some way, and get this key Kc. So it seems like a good way.
But why do we need two protocols? After all, you can imagine that you simply request a ticket directly from the first Kerberos interface, telling him: “Hey, I want a ticket for this particular name!”, He will send you the ticket back, and you can decrypt it using Kc.
Student: maybe they don’t want the user to re-enter their password every time they want to access another service?
Professor: right, the reason for the difference between these two interfaces is that from the first interface all the answers are returned encrypted with your Kc key, and the creators of Kerberos were worried about the possibility of saving this Kc for a long time. Because either you have to ask the user to enter the password every time, which is just annoying, or he constantly “sits” in the memory. This is basically as good as a user’s password, because someone with access to Kc can save access to the user's files as long as the user may not change their password, or even longer. Later we will take a closer look at this issue.
So leaking this Kc key is a very dangerous thing. Thus, the whole point of using the first and then the second interface first for all subsequent requests is that you can actually forget Kc as soon as you decrypt the response from the TGS interface of the Kerberos server. From now on, even in the event of a key leak, the functionality will depend on the ticket received. So in the worst case, someone will get access to your account for a couple of hours, and not for an unlimited amount of time. This is what explains this scheme with two ways of accessing the same resources.
So, before we delve into the mechanics of how these protocols actually look online, let's talk a little about the aspect of names in Kerberos. In a sense, Kerberos can be considered a registry of names. He is responsible for displaying these cryptographic keys as string names. This is a fundamental type of operation that Kerberos performs. You will see in the next lecture why we need this function. It can be implemented differently than in Kerberos, but it is fundamentally very important to have such a thing in almost any distributed security system. So let's see how Kerberos acts with names.
In Kerberos, there is something like system calls for each computer entity in the database of network participants, and the main type of this data is just a string. So you can have some basic names like nickolai. This is the name string.

It is the main parameter in some Kerberos realm, in fact, this thing is in the left column of the KDC table. And there are also some additional parameters that the protocol supports. I could, for example, enter another name like nickolai.extra sec, which would be used in addition to the name nickolai to access resources that need additional security. So maybe I will have one password for really safe things and another password for my regular account.
This aspect is mentioned in the Kerberos work. Therefore, one may wonder - where does the impact come from? The Kerberos service matches names for certain keys for you, but how do you know what name you need to ask or what name to expect in response when you communicate with some computer? That is, I ask, what are the names that appear outside the Kerberos server, or where exactly do these user names appear? Do you have any ideas?
Student: Presumably, you can ask for usernames from the MIT server.
Professor: yes, of course. This is how you can list these things. In addition, users simply enter them when they log into the system, this is where they initially come from. Do usernames appear anywhere else? Should they appear anywhere else?
Student: perhaps, user access is indicated in the lists in various services.
Professor: yes, this is a really important point, right? The purpose of Kerberos is simply to associate keys with names. But that does not tell you what this name should have access to.
In fact, the way applications typically use Kerberos is that one of these servers uses Kerberos to figure out which line name it is talking to. When the mail server receives a connection from some workstation, it receives a Kerberos ticket, which proves that this user is called Nikolay. After that, the internal mail server finds out what this user has access to. Similarly comes the file server.
Thus, within all of these servers there are access control lists, possibly lists of groups or other things that authorize. So Kerberos provides authentication that shows you who this person you are talking to is. The service itself is responsible for implementing the part of the authorization that decides what level of access you should have based on your username. So we figured out where the usernames appear. There are other main names that Kerberos supports to interact with services.
According to the materials of the lecture, the services look like this: rcmd.hostname. The reason why you need a name for one of these services is that you want, for example, when connecting to a file server, to perform mutual authentication. This means that in this procedure, not only the final server will find out who I am, but I, the user or the workstation, will be convinced that I am talking with the correct file server, and not with some kind of fake file server that has forged my files. Because, perhaps, I want to see the file with my ratings and send it to the registrar. Therefore, it would be too bad if some other file server could play the role of the correct server and give me the wrong rating file.
Therefore, services also need their own name, and workstations need to figure out which name I expect to see when I connect to the service.
As a rule, at some level it comes from the user. So, for example, if I type ssh.foo, it means that I should expect the appearance of the Kerberos main name of type rcmd.foo at the other end of this connection. And if someone else is there, then the SSH client should break the connection and not allow me to connect, because then I will be misled and talk to some other machine.
This raises an interesting question. When can we reuse names in Kerberos? For example, all of you have accounts in the Athena institute system. When you graduate, can MIT delete your record in the database and allow someone else to register the same username? Would that be a good idea?
Student: but, after all, not only the Kerberos database, but also the services have a list of user names?
Professor: yes, because these names are actually just represented by string entries somewhere in the ACL on a file or mail server. If we erase your entry in the Kerberos server database, this does not mean that your entry has disappeared altogether. These entries are version independent.
For example, the record says that Alice has access to some Athens locker. Then Alice finishes the institute, and her record is deleted, but some new Alice enters the institute and is going through the registration process in the Kerberos database. At the same time, she gets the main name, completely identical to the name of the old Alice, so the file server can give the new Alice access to the files of the old Alice.
, Kerberos , Kerberos . , , , .
. , , , , , . , , , - . , . , , .
, . , , , TGS.

, , Kerberos, «». : s , IP – addr, time stump, life, , , Kc,s, . .

.
, Kerberos «». Ac , IP- , , . , . K,s, , Kerberos Ks. , .
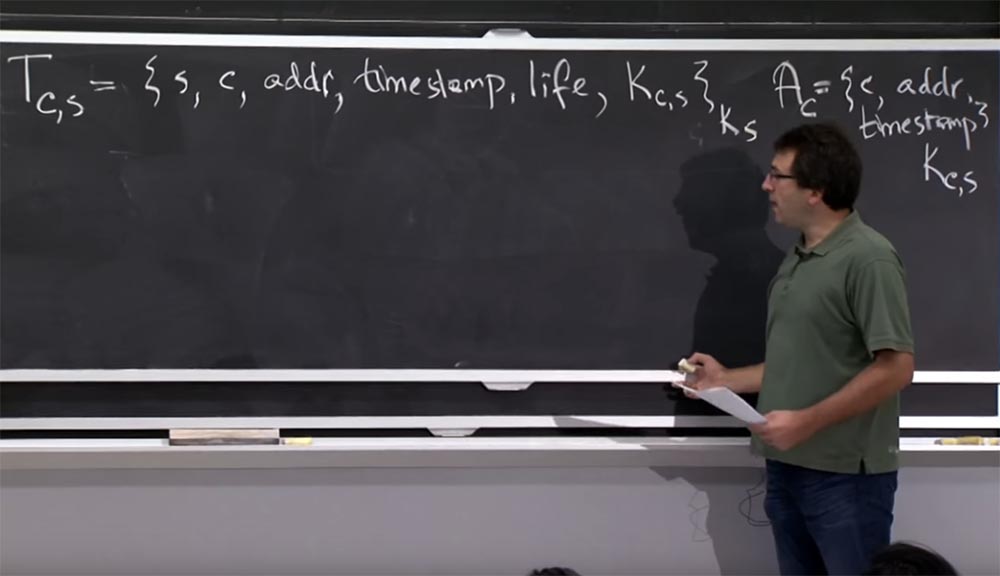
, , Kerberos TGS. , , Kerberos, , . : C, , S, TGS. .
Tc,s, Ks, , Ks, , Kc. .
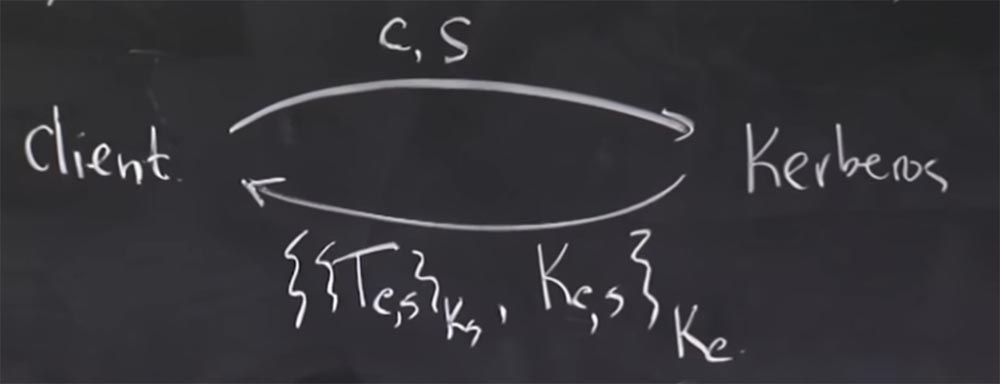
. , Kerberos ? , ?
: , , , Kc.
: , , Kerberos , . : «, , . , , , Kc». , .
, , , Kerberos, Kerberos , . , , - Kerberos, , .
: …
: , , Kerberos, ? , ? , , , , , , , , , .

«», , , , , . , , . . Kerberos, , . , , .
: ? , …
: , . , Kerberos , . , , - , , , . 30 , .
Kerberos 5 : , — . , , , , .
Kerberos 4 , , , . , . , , .
, , , . , . — K,s - ? K,s T,s. K,s?
27:10
MIT course "Computer Systems Security". 13: « », 2
Full version of the course is available here .
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps until December for free if you pay for a period of six months, you can order here .
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
Source: https://habr.com/ru/post/427763/
All Articles