OpenStack fine tuning under high load
Hi, my name is Maxim, I am a system administrator. Three years ago, my colleagues and I began to transfer products to microservices, and decided to use Openstack as a platform, and encountered a number of unobvious rakes in automating test circuits. This post is about the nuances of OpenStack settings, which are hardly located on the fifth page of the search engine output (and it is better that they were easily located on the first one).
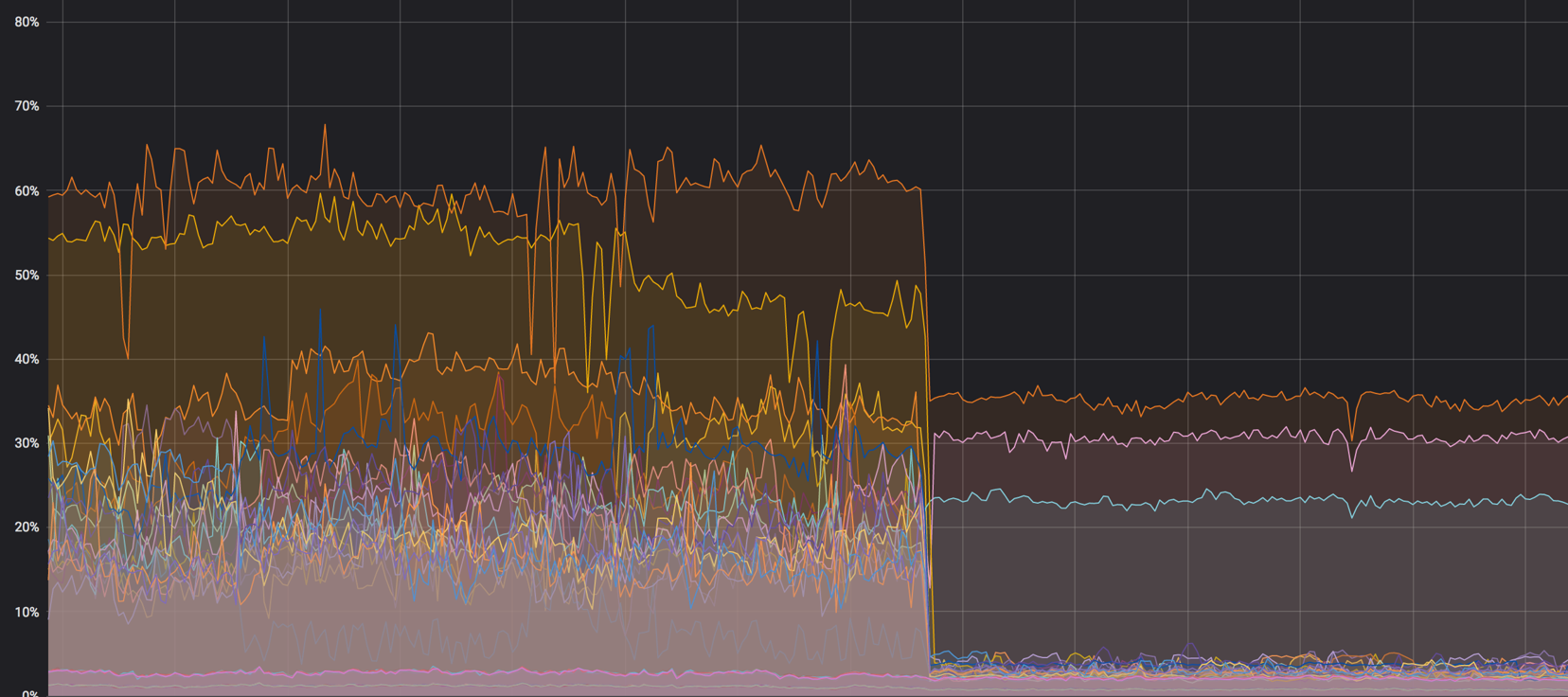
Load on the core: it was - it became
NAT
In some instances we use dualstack. This is when the virtual machine receives two addresses at once - IPv4 and IPv6. At first we made it so that the “floating” v4 address was assigned in the internal network via NAT, and the machine received v6 via BGP, but there are a couple of problems with this.
NAT is an additional node in the network, where even without it you need to monitor the normal distribution of the load. The emergence of NAT in the network almost always leads to difficulties with debugging - on the host one IP, in the base another, and it becomes difficult to track the request. Mass searches begin, and the solution will still be inside OpenStack.
NAT also does not allow normal access segmentation between projects. All projects have their own subnets, floating IPs are constantly migrating, and with NAT it becomes absolutely impossible to manage. In some installations, they talk about the use of NAT 1 in 1 (the internal address is not different from the external one), but it still leaves unnecessary links in the chain of interaction with external services. We came to the conclusion that the best option for us is the BGP network.
The simpler the better
We tried different automation tools, but stopped at Ansible. This is a good tool, but its standard functionality (even with optional modules) may not be enough in some difficult situations.
For example, through the Ansible-module it is impossible to specify from which subnet to allocate addresses. That is, you can specify a network, but you will not be able to specify a specific address pool. This is where a shell command that creates a floating IP will help:
openstack floating ip create -c floating_ip_address -f value -project \ {{ project name }} —subnet private-v4 CLOUD_NET Another example of missing functionality: due to dualstack, we cannot nominally create a router with two ports for v4 and v6. This bash script comes in handy here:
#! /bin/bash # $1 - router_name # $2 - router_project # $3 - router_network # echo "${@:4}" - private subnet lists FIXED4_SUBNET="subnet-bgp-nexthop-v4" FIXED6_SUBNET="subnet-bgp-nexthop-v6" openstack --os-project-name $2 router show $1 if [ $? -eq 0 ] then echo "router is exist" exit 0 fi openstack --os-project-name $2 router create --project $2 $1 for subnet in "${@:4}"; do openstack --os-project-name $2 router add subnet $1 $subnet done openstack --os-project-name $2 router set $1 --external-gateway $3 --fixed-ip subnet=$FIXED4_SUBNET --fixed-ip subnet=$FIXED6_SUBNET The script creates a router, adds v4 and v6 subnets to it, and assigns an external gateway.
Retry
In any strange situation - restart. Try again, create an instance, router or DNS record, because you do not always understand quickly what your problem is. Retry can delay the degradation of the service, but at this time you can safely and without nerves solve the problem.
All the tips above, in fact, work great with Terraform, Puppet and anything else.
Everything has its place
Any large service (OpenStack is no exception) combines many smaller services that can interfere with each other’s work. Here is an example.
The network agent Neutron-L2-agent is responsible for network connectivity in OpenStack. If all the other agents are partially on the controllers, then L2, by virtue of the specifics, is present everywhere.
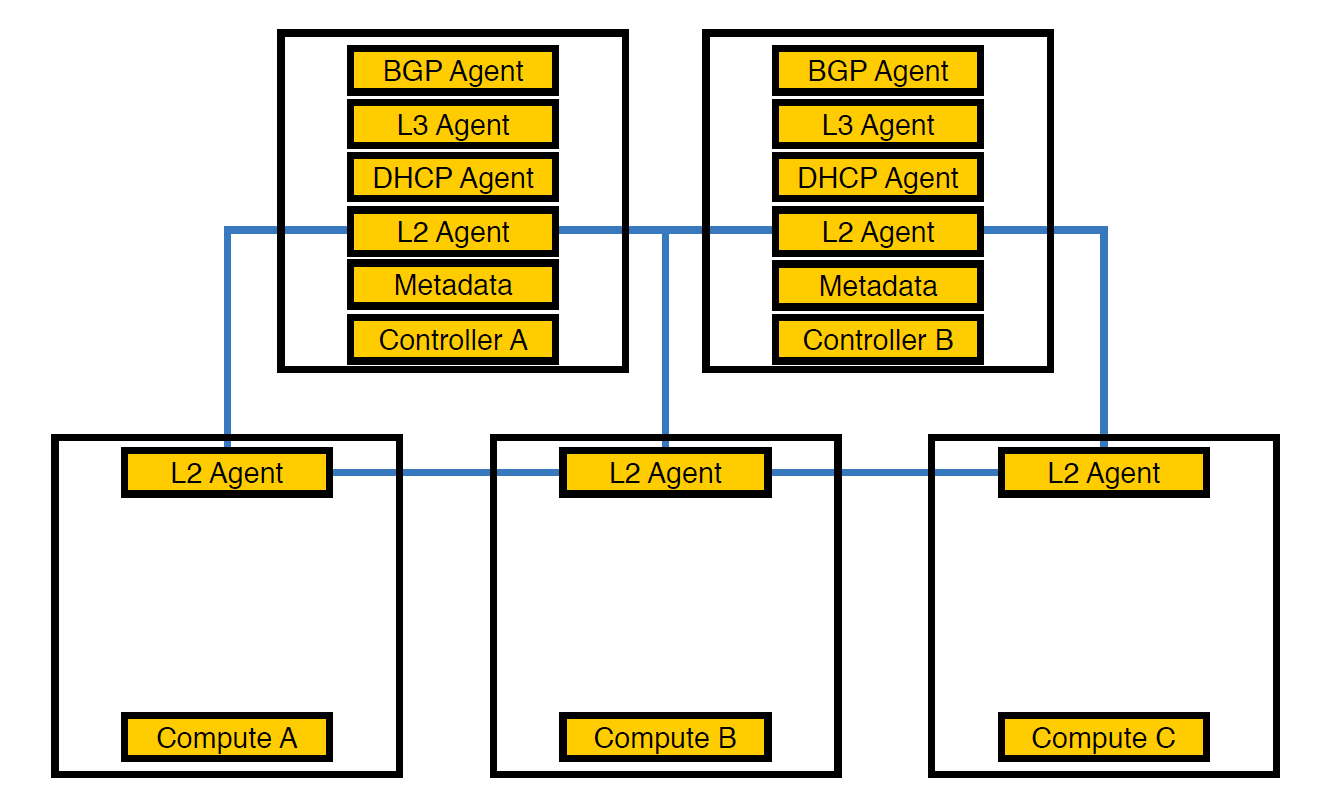
That was how our infrastructure looked at the very beginning, until the number of circuits exceeded 50
At this point, we realized that because of this arrangement of agents, the controllers could not cope with the load, and transferred the agents to compute nodes. They are more powerful than controllers, and besides, the controller does not have to be engaged in processing everything - it must issue a task to the executing node, and the node will execute it.

Transfer agents to compute nodes
However, this was not enough, because this arrangement had a bad effect on the performance of virtual machines. With a density of 14 virtual cores per physical one, if one network agent started loading a stream, it could hit several virtual machines at once.
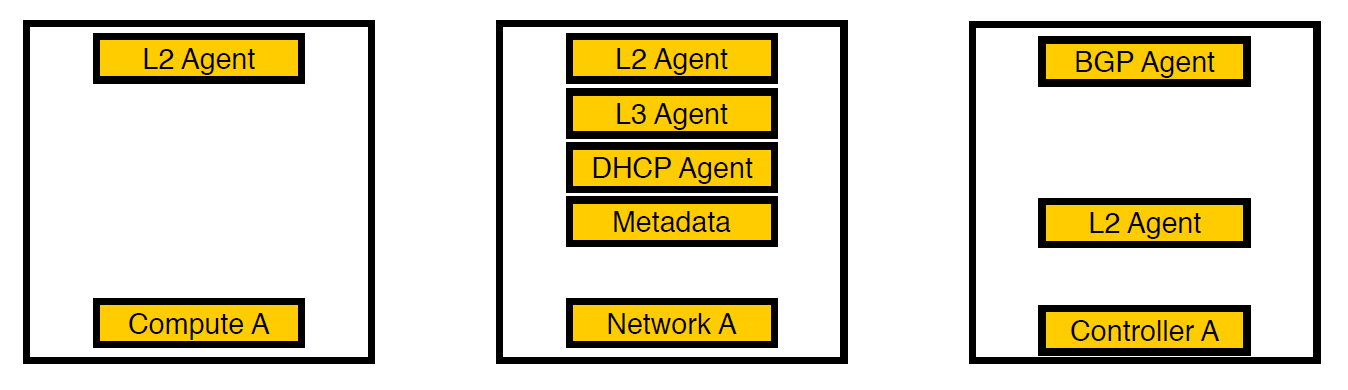
Third iteration. There are selected nodes
We thought and carried the agents to separate network nodes. Now, only virtual services remain on compute nodes, all agents work on network nodes, and only bgp agents that are involved in the v6 network remain on controllers (since one bgp agent can serve only one type of network). L2 remained everywhere, because without it, as we wrote above, there will be no connectivity on the network.
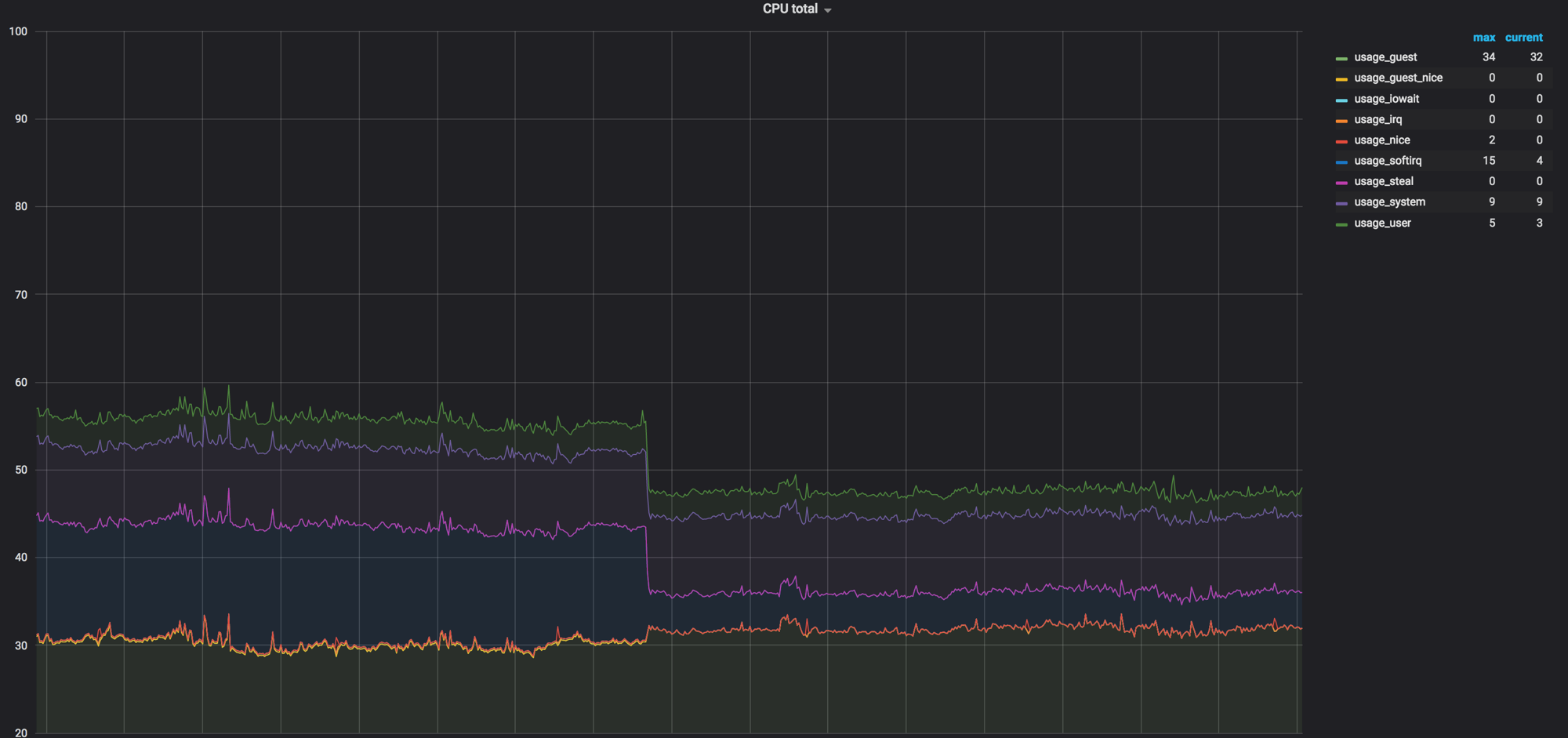
The load schedule of the compute node before everything is mixed. It was about 60%, but the load dropped insignificantly

The load on softirq, before the network agents were removed from the compute node. 3 cores are loaded. At that time, we thought it was normal.
Code as Documentation
Sometimes it happens that the code is the documentation, especially in such large services as OpenStack. With a release cycle of six months, developers forget or simply do not have time to document some things, and it turns out as in the example below.
About timeouts
Once we saw that Neutron calls to Open vSwitch do not fit into five seconds and fall on timeout.
127.0.0.1:29696: no response to inactivity probe after 10 seconds, disconnecting neutron.agent.ovsdb.native.commands TimeoutException: Commands [DbSetCommand(table=Port, col_values=(('tag', 11),), record=qtoq69a81c6-e2)] exceeded timeout 5 seconds Of course, we assumed that somewhere in the settings this is fixed. We looked in the configs, documentation and deb-package, but at first did not find anything. As a result, the description of the desired setting was found on the fifth page of the search results - we looked at the code again and found the right place. The setting is as follows:
ovs_vsctl_timeout = 30 We set it for 30 seconds (it was 5), and everything began to work a little better.
Here's another not obvious - when rebooting network components, some settings of Open vSwitch can be reset. So, for example, happens with ovs-vsctl inactivity_probe. This is also a timeout, but it affects the access of the ovs-vsctl itself to its database. We added it to systemd init, which allowed us to start all the switches with the parameters we need at startup.
ovs-vsctl set Controller "br-int" inactivity_probe=30000 About network stack settings
We also had to slightly deviate from the generally accepted settings in the network stack that we use on our other servers.
Here is the setting of how long ARP records need to be stored in the table:
net.ipv4.neigh.default.base_reachable_time = 60 net.ipv4.neigh.default.gc_stale_time=60 The default is 1 day. In general, one scheme can live for a couple of weeks, but the schemes can be recreated 4-6 times a day, while the MAC-address and IP-address are constantly changing. To not garbage, we set the time in one minute.
net.ipv4.conf.default.arp_notify = 1 net.nf_conntrack_max = 1000000 (default 262144) net.netfilter.nf_conntrack_max = 1000000 (default 262144) In addition, we forcedly sent ARP notifications when the network interface was raised. We also increased the conntrack table, because when using NAT and floating ip, we didn’t have a default value. Increased to a million (with a default of 262,144), things got even better.
The size of the MAC table of the Open vSwitch itself is correct:
ovs-vsctl set bridge bt-int other-config:mac-table-size=50000 (default 2048) 
After all the settings, 40% of the load turned almost to zero
rx-flow-hash
To distribute the processing of udp traffic across all queues and processor threads, we included rx-flow-hash. On Intel network cards, namely in the i40e driver, this option is disabled by default. We have hypervisors with 72 cores in our infrastructure, and if only one is busy, then this is not very optimal.
This is done like this:
ethtool -N eno50 rx-flow-hash udp4 sdfn 
An important conclusion: you can customize everything. The default configuration will fit to some point (as was ours), but the problem with timeouts led to the need to search. And that's fine.
Safety regulations
According to the requirements of the security service, all projects within the company have personal and global rules - there are quite a lot of them. When we passed over 300 virtual machines to one hypervisor, it all drained 80 thousand rules for iptables. For iptables itself, this is not a problem, but Neutron loads these rules from RabbitMQ into one stream (because it is written in Python, and everything is sad with multithreading). Neutron-agent freezes, loss of communication with RabbitMQ and chain reaction from timeouts occur, and after restoring Neutron again requests all the rules, starts synchronization, and everything starts all over again.
At the same time, the time for creating stands increased from 20-40 minutes to, at best, an hour.
At first, we simply wrapped everything up with retrays (already at this stage we realized that the problem could not be solved so quickly), and then we started using FWaaS . With it, we made the security rules with a compute node to the individual network nodes where the router itself is located.

Source - docs.openstack.org
Thus, within the project there is full access to everything that is needed, and for external connections security rules apply. So we reduced the load on Neutron and returned to 20-30 minutes to create a test environment.
Total
OpenStack is a cool thing in which you can dispose of iron, create an internal cloud and create something else on its base. In addition to this, there is a large community and an active group in Telegram , where we were told about timeouts.
That's all. Ask questions, my colleagues and I are ready to answer and share experiences.
')
Source: https://habr.com/ru/post/427569/
All Articles