Convergence with Kubernetes
Total standardization
I prepared this material for a speech at the conference and asked our technical director what the main thing Kubernetes is for our organization. He replied:
The developers themselves do not understand how much extra work they have done.
Apparently, he was inspired by the recently read book “Factfulness” - it is difficult to notice minor and continuous changes for the better, and we constantly lose sight of our progress.
But the transition to Kubernetes just can not be called insignificant.

Nearly 30 of our teams run all or some of the workloads on the clusters. Approximately 70% of our HTTP traffic is generated in applications on Kubernetes clusters. This is probably the most extensive technology convergence since I joined the company after the Forward group bought the uSwitch in 2010 when we switched from .NET and physical servers to AWS and from a monolithic system to microservices .
And everything happened very quickly. At the end of 2017, all teams used their AWS infrastructure. They set up load balancers, EC2 instances, ECS cluster updates, and so on. It took a little over a year, and everything changed.
We spent a minimum of time on convergence, and as a result, Kubernetes helped us solve pressing problems - our cloud grew, the organization became more complicated, and we hardly entered new people into the teams. We did not change the organization to use Kubernetes. On the contrary - we used Kubernetes to change the organization.
Maybe the developers did not notice the big changes, but the data speak for themselves. More on this later.
Many years ago I was at a Clojure conference and heard a lecture by Michael Nygard on architecture that cannot be brought to a final state . He opened my eyes. A neat and orderly system looks caricature when it compares the TV shops with kitchen goods and large-scale software architecture - the existing system looks like a dull knife, and some kind of porridge comes out instead of even slices. Without a new knife, there’s nothing to think about salad.
This is about how organizations adore three-year projects: the first year is development and preparation, the second year is implementation, the third is return. In the lecture, he says that such projects are usually done continuously and rarely get to the end of the second year (often due to another company's acquisition and changes in direction and strategy), so the usual architecture is
layering of change in some kind of stability.
And uSwitch is a great example.
We switched to AWS for many reasons - our system could not cope with peak loads, and the development of the organization was hampered by a too rigid system and closely related teams that were formed for specific projects and were divided by specialization.
We were not going to drop everything, move all systems and start over. We created new services with proxying through the existing load balancer and gradually choked the old application. We wanted to immediately show a return and in the very first week we conducted A / B testing of the first version of the new service in production. As a result, we took long-term products and began to form teams for them under developers, designers, analysts, etc. And we immediately saw the result. In 2010, it seemed a real revolution.
Year after year we added new commands, services and applications and gradually “choked” the monolithic system. The teams progressed quickly - now they worked independently of each other and consisted of specialists in all the necessary fields. We have minimized the interaction of teams for product release. We have selected a few commands only for the configuration of the load balancer.
The teams themselves chose development methods, tools and languages. We set a task for them, and they themselves found a solution, because they understood the question best of all. With AWS, these changes have become easier.
We intuitively followed the principles of programming - teams that are loosely connected with each other will communicate less often and we will not have to spend precious resources to coordinate their work. All this is great described in the recently published book "Accelerate" .
As a result, as Michael Nigard described, we got a system from many layers of changes - some systems were automated with Puppet, some with Terraform, somewhere we used ECS, somewhere - EC2.
In 2012, we were proud of our architecture, which could be easily changed to experiment , find successful solutions and develop them.
But in 2017, we realized that a lot has changed.
Now AWS infrastructure is much more complicated than in 2010. It offers a lot of options and opportunities - but not without consequences. Today, any team that works with EC2 has to choose VPC, network configuration, and much more.
We experienced it ourselves - the teams began to complain that they were spending more and more time on infrastructure maintenance, for example, updating instances in AWS ECS clusters , EC2 machines, switching from ELB balancers to ALB, etc.
In mid-2017, at a corporate event, I called on everyone to standardize work in order to improve the overall quality of the systems. I used the hackneyed iceberg metaphor to show how we create and maintain software:

I said that most of the teams in our company should be engaged in creating services or products and focus on solving problems, application code, platforms and libraries, etc. In that order. There is a lot of work under water - log integration, increasing observability, secret management, etc.
At that time, each application development team was engaged in almost the entire iceberg and made all the decisions on its own - choosing a language, development environment, library and metrics tool, operating system, instance type, storage.
At the base of the pyramid, we had Amazon Web Services infrastructure. But not all AWS services are the same. They have Backend-as-a-Service (BaaS) , for example, for authentication and data storage. And there are other, relatively low-level services, such as EC2. I wanted to study the data and understand that the teams have reason to complain and they really spend more time working with low-level services and make many less important decisions.
I divided the services into categories, collected all the available statistics using CloudTrail , and then used BigQuery , Athena and ggplot2 to see how the situation has changed for developers lately. Growth for services such as RDS, Redshift, etc., we consider desirable (and expected), and growth for EC2, CloudFormation, etc., on the contrary.

Each dot in the diagram shows the 90th (red), 80th (green) and 50th (blue) percentiles for the number of low-level services that our people used every week for a certain period. I added smoothing lines to show the trend.
And although we were striving for high-level abstractions when deploying software, for example, using containers and Amazon ECS , our developers regularly used more and more AWS services and didn’t abstract from the complexities of system management. In two years, the number of services doubled for 50% of employees and almost tripled for 20%.
This limited the growth of our company. Teams sought autonomy, but how could they hire new people? We needed strong application and product developers and knowledge of AWS’s increasingly complex system.
We wanted to expand the team and at the same time preserve the principles with which success was achieved: autonomy, minimal coordination and self-sustained infrastructure.
With Kubernetes, we achieved this goal through abstractions with a focus on applications and the ability to maintain and tune clusters for minimal command coordination.
Abstractions with a focus on applications
Kubernetes concepts can be easily compared with the language used by the application developer. Suppose you manage application versions as a deployment . You can run multiple replicas for the service and map them to HTTP via Ingress . And through user resources, you can expand and specialize this language, depending on what you need.
Teams work more productively with these abstractions. In principle, this example has everything you need to deploy and run a web application. The rest is handled by Kubernetes.
In the picture with the iceberg, these concepts are at the water level and connect the developer’s tasks from above to the platform below. The cluster management team can make low-level and insignificant decisions (on managing metrics, logging, etc.) and at the same time speak the same language with the developers above water.
In 2010, uSwitch had traditional teams to maintain a monolithic system, and most recently we had an IT department that partially managed our AWS account. It seems to me that the lack of common concepts seriously interfered with the work of this team.
Try saying something useful if you have only EC2 copies, load balancers and subnets in your vocabulary. Describing the essence of the application was difficult or even impossible. This could be a Debian package, deployment via Capistrano, and so on. We could not describe the application in a common language for all.
In the early 2000s, I worked in London ThoughtWorks. At the interview, I was advised to read Eric Evans ' Problem-Oriented Design . I bought a book on the way home and started reading more on the train. Since then, I remember about it in almost every project and system.
One of the main concepts of the book is a single language in which different teams communicate. Kubernetes provides such a common language for developers and infrastructure maintenance teams, and this is one of its main advantages. Plus, it can be expanded and supplemented with other subject areas and business areas.
In a common language, communication is more productive, but we still need to limit the interaction between the teams as much as possible.
Necessary minimum of interaction
The authors of the book “Accelerate” highlight the characteristics of a loosely coupled architecture with which IT teams work more efficiently:
In 2017, the success of continuous delivery depended on whether the team:
Seriously change the structure of its system without the permission of the leadership.
Seriously change the structure of your system, not waiting for other teams to change their own, and not creating a lot of extra work for other teams.
Perform their tasks without communicating and coordinating their work with other teams.
Deploy and release a product or service on demand, regardless of other services associated with it.
Make most of the tests on demand, without an integrated test environment.
We needed centralized software multi-tenant clusters for all teams, but at the same time we wanted to preserve these characteristics. We have not yet reached the ideal, but we try our best:
- We have several working clusters, and the teams themselves choose where to run the application. We do not use federation yet (we are waiting for AWS support), but we have Envoy for load balancing on Ingress balancers in different clusters. We automate most of these tasks using a continuous delivery pipeline (we have a Drone ) and other AWS services.
- All clusters have the same namespace . About one for each team.
- Access to namespaces is controlled through RBAC (role-based access control). For authentication and authorization, we use a corporate identity in Active Directory.
- Clusters are scaled automatically , and we are doing everything possible to optimize the node startup time. It still takes a couple of minutes, but, in general, even with large workloads, we do without coordination.
- Applications are scaled automatically based on application-level metrics from Prometheus. The development teams control the automatic scaling of their application by query metrics per second, operations per second, etc. Thanks to the cluster autoscaling, the system prepares nodes when demand exceeds the capabilities of the current cluster.
- We wrote a command line tool in Go called u , which standardizes command authentication in Kubernetes, use of Vault , requests for AWS temporary credentials, and so on.
I'm not sure that we have more autonomy with Kubernetes, but it definitely remained at a high level, and at the same time we got rid of some problems.
The transition to Kubernetes was quick. The diagram shows the total number of namespaces (roughly equal to the number of teams) in our work clusters. The first appeared in February 2017.
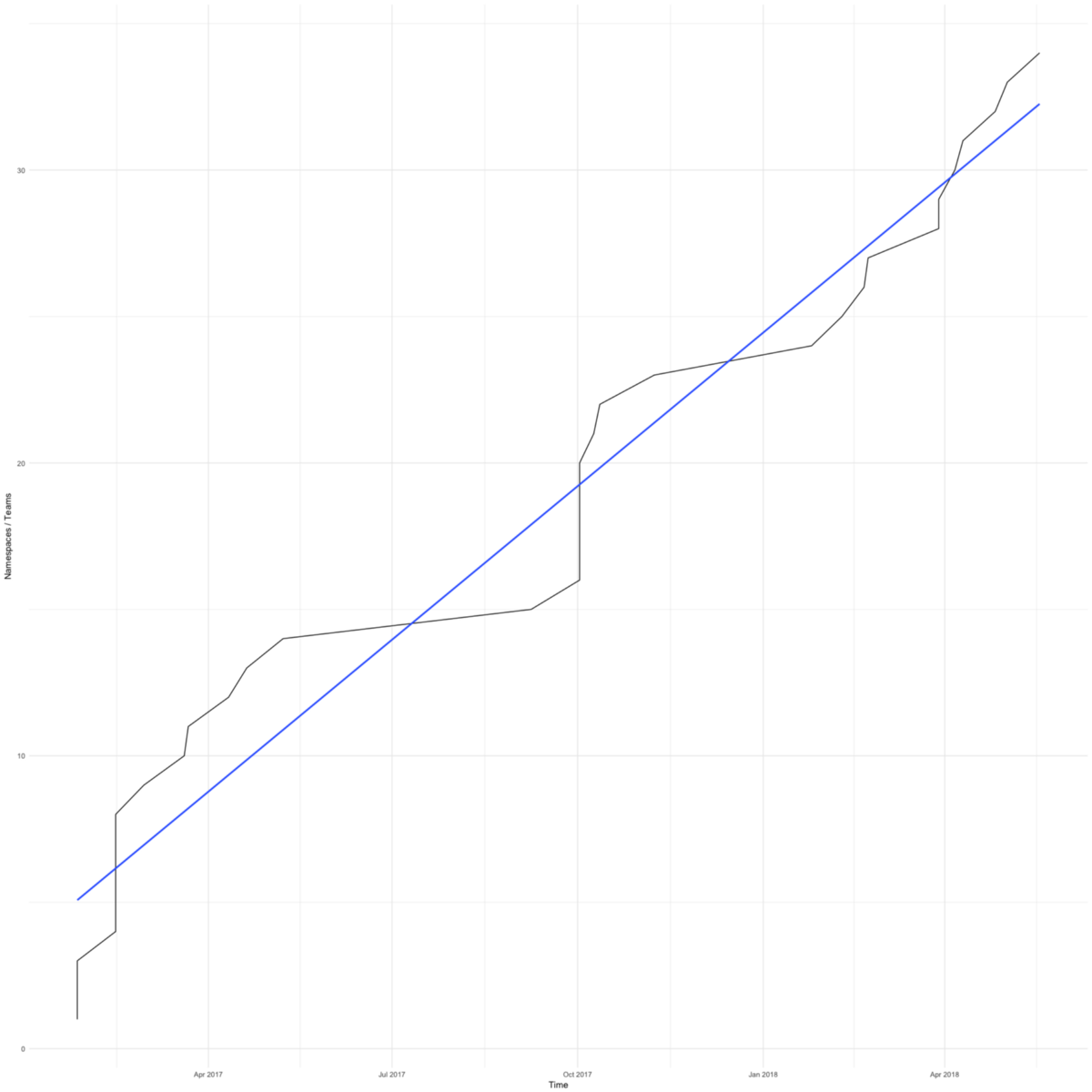
We had reasons to rush - we wanted to save small teams focused on their product from worries about the infrastructure.
The first team agreed to switch to Kubernetes when the place on their application server ran out due to incorrect logrotate settings. The transition took only a few days, and they took up the business again.
Recently, teams are switching to Kubetnetes for the sake of improved tools. Kubernetes clusters make it easy to integrate with our secret management system ( Hashicorp Vault ), distributed tracing ( Google Cloud Trace ) and similar tools. All our teams get even more efficient features.
I have already shown a chart with percentiles of the number of services that our employees used every week from the end of 2014 to 2017. But the continuation of this chart to date.
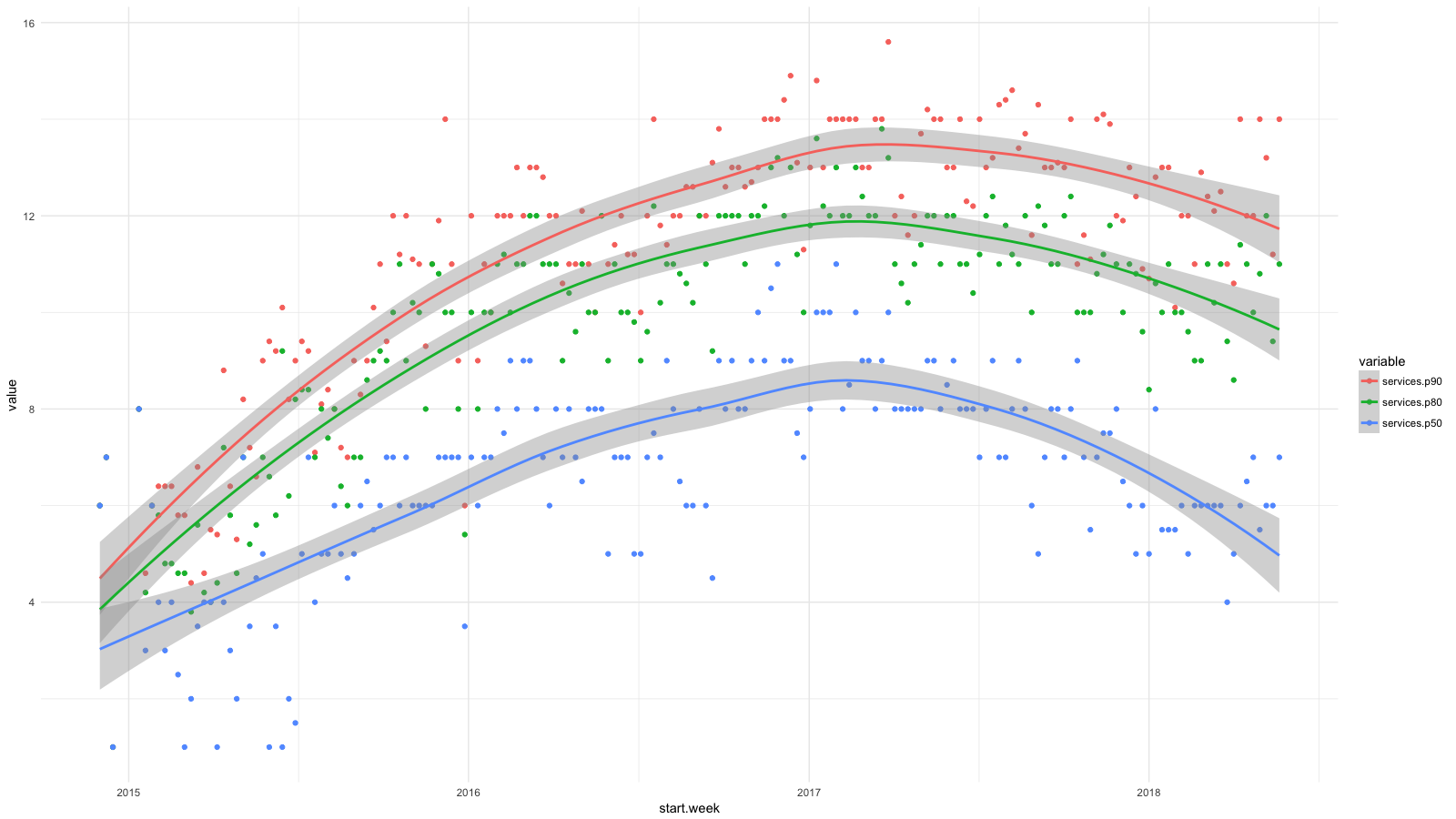
We have made progress in managing the complex structure of AWS. I am glad that now half of the employees are doing the same as in early 2015. In a cloud computing team, we have 4–6 employees, about 10% of the total number — it’s not surprising that the 90th percentile almost did not budge. But I hope for progress here.
Finally, I will talk about how our development cycle has changed, and again recall the recently read Accelerate book.
The book mentions two indicators of lean development: lead time and package size. The lead time is calculated from the request to the delivery of the finished solution. Package size is the amount of work. The smaller the package size, the more efficient the work:
The smaller the package, the shorter the production cycle, the less variability of processes, less risks, costs and costs, we get feedback faster, work more efficiently, we have more motivation, we try to finish faster and less often we postpone the change.
The book proposes to measure the size of packages by the frequency of deployment - the more often the deployment, the smaller the packages.
We have data for some deployments. The data is not entirely accurate - some teams send releases directly to the main branch of the repository, some use other mechanisms. This does not include all applications, but data for 12 months can be considered indicative.
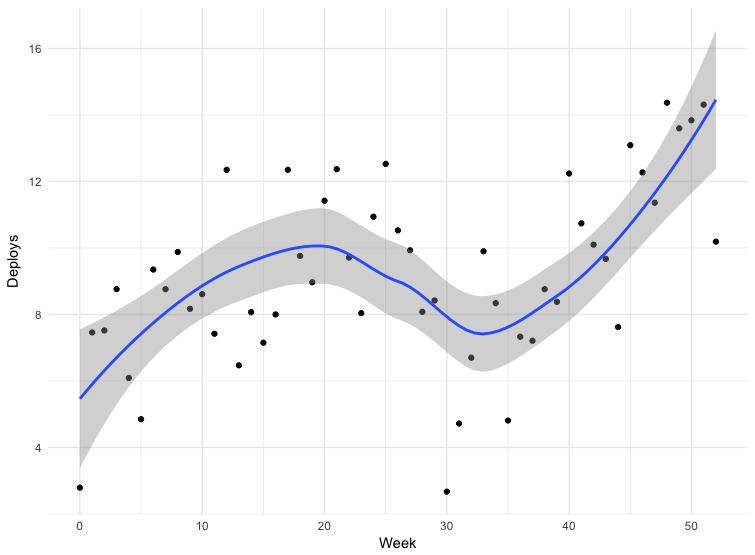
The failure of the thirtieth week is Christmas. For the rest, we see that the deployment frequency increases, which means the packet size decreases. From March to May 2018, the frequency of issues has almost doubled, and lately, we sometimes do more than a hundred issues a day.
Going to Kubernetes is only part of our strategy for standardizing, automating, and improving tools. Most likely, all these factors influenced the frequency of issues.
Back in Accelerate, there is a link between the frequency of deployments and the number of employees and how fast a company can work if the staff is increased. The authors emphasize the limitations of the associated architecture and commands:
Traditionally it is believed that expanding a team increases overall productivity, but decreases individual developer productivity.
If we take the same data on the frequency of deployments and make a diagram of the dependence on the number of users, it is clear that we can increase the frequency of releases, even if we have more people.

At the beginning of the article, I mentioned the book "Factfulness" (which inspired our technical director). The transition to Kubernetes has become for our developers the most significant and rapid convergence of technology. We are moving in small steps, and it's easy not to notice how things have changed for the better. It is good that we have data, and they show that we have achieved the desired - our people are engaged in their product and make important decisions in their own field.
Previously, we have been so good. We had microservices, AWS, well-established product teams, developers responsible for their production services, loosely coupled teams and architecture. I talked about this in the report "Our Age of Enlightenment" ("Our Age of Enlightenment") at a conference in 2012. But there is no limit to perfection.
At the end I want to quote another book - Scale . I started it recently, and there is an interesting fragment about energy consumption in complex systems:
To maintain order and structure in a developing system, a constant flow of energy is needed, and it creates confusion. Therefore, to maintain life, we must eat all the time to defeat the inevitable entropy.
We are fighting entropy, supplying more energy for growth, innovation, maintenance and repair, which is becoming more difficult as the system ages, and this battle lies at the heart of any serious discussion about aging, mortality, sustainability and self-sufficiency of any systems, whether it is a living organism. , company or society.
I think you can add IT systems here. I hope our last efforts will keep entropy for a little while.
')
Source: https://habr.com/ru/post/427441/
All Articles