Use Node.js to work with large files and raw data sets.

This post is a translation of the original article by Paige Nidrinhaus, full-stack software engineer. Its main specialty is JavaScript, but Paige studies other languages and frameworks. And the experience gained is shared with its readers. By the way, the article will be interesting to novice developers.
Recently, I was faced with a task that interested me - it was necessary to extract certain data from a huge amount of unstructured files of the US Federal Election Commission. I did not work too much with raw data, so I decided to take up the challenge and take on this task. As a tool for solving it, I chose Node.js.
Skillbox recommends: Online course "Profession Frontend Developer" .
')
We remind: for all readers of "Habr" - a discount of 10,000 rubles when recording for any Skillbox course on the promotional code "Habr".
The task was described in four points:
- The program must calculate the total number of lines in the file.
- Every eighth column contains the name of the person. It is necessary to load this data and create an array with all the names contained in the file. The 432nd and 43 243rd names must be displayed.
- Every fifth column contains the date of making donations by volunteers. Calculate how many donations are paid each month, and output the total result.
- Every eighth column contains the name of the person. Create an array, choosing only a name, without a last name. Find out which name is the most common and how many times?
(The original task can be viewed here at this link .)
The file you need to work with is a regular .txt of 2.55 GB. There is also a folder that contains parts of the main file (they can be used to debug the program without analyzing the entire vast array).
Two possible solutions on Node.js
In principle, working with large files JavaScript specialist does not scare. In addition, this is one of the main functions of Node.js. There are several possible solutions for reading from and writing to files.
The usual - fs.readFile (). It allows you to read the entire file, memorizing it, and then use Node.
The alternative is fs.createReadStream (), a function that transmits data in the same way that it is organized in other languages — for example, in Python or Java.
The solution I chose
Since I needed to calculate the total number of rows and parse the data for parsing names and dates, I decided to stop at the second option. Here I could use the rl.on ('line', ...) function to get the necessary data from the lines.
Node.js CreateReadStream () & ReadFile () Code
Below is the code I wrote with Node.js and the fs.createReadStream () function.
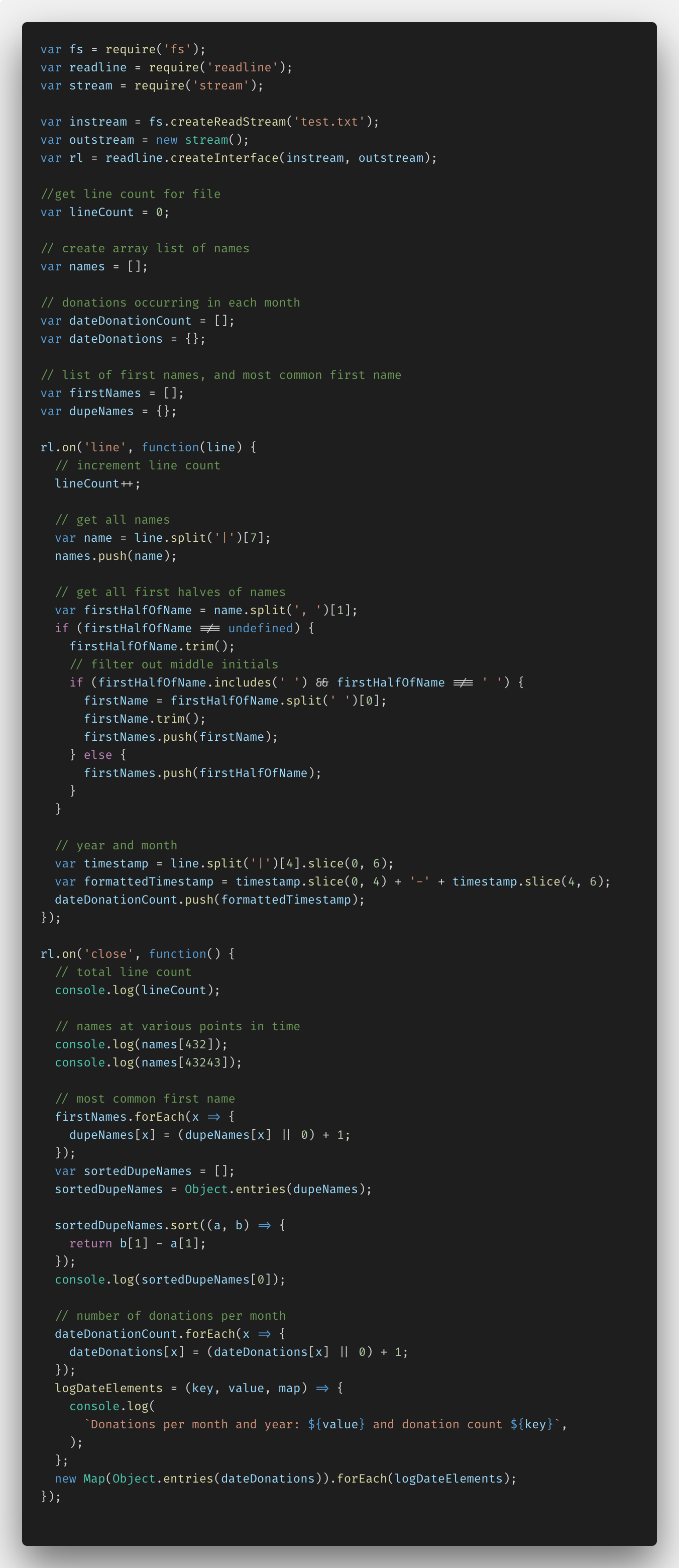
Initially, I needed to configure everything, knowing that data import requires Node.js functions such as fs (file system), readline and stream. Then I was able to create instream and outstream with readLine.createInterface (). The resulting code made it possible to parse the file line by line, taking the necessary data.
In addition, I added several variables and comments for working with specific data. These are lineCount, dupeNames, and the names, donation, and firstNames arrays.
In the function rl.on ('line', ...) I was able to set the file to be parsed line by line. So, I entered the lineCount variable for each line. I used the split () JavaScript method to parse the names, adding them to my names array. Then I separated only the names, without surnames, at the same time highlighting exceptions, such as the presence of double names, initials in the middle of the name, etc. Next, I separated the year and date from the data column, converting it all into YYYY-MM format and adding the dateDonationCount to the array.
In the function rl.on ('close', ...), I performed all the transformations of the data added to the arrays, with the information received in the console.log.
lineCount and names are needed to determine the 432nd and 43,243rd names; no conversion is required here. But identifying the most common name in the array and determining the number of donations are more complex tasks.
In order to identify the most frequent name, I had to create an object of value pairs for each name (key) and the number of references to Object.entries (). (value), and then convert it all into an array of arrays using the ES6 function. After this, the task of sorting the names and identifying the most repetitive was no longer difficult.
With donations, I did about the same trick: I created an object of value pairs and a function logDateElements (), which allowed me, using the interpolation of ES6, to display the keys and values for each month. Then I created new Map (), converting the dateDonations object to a meta-array, and cycled each array using logDateElements (). (It wasn't as simple as it seemed at the beginning.)
But it worked, I was able to read a relatively small 400 MB file, highlighting the necessary information.
After that I tried fs.createReadStream () - I implemented the task on fs.readFile () in order to see the difference. Here is the code:
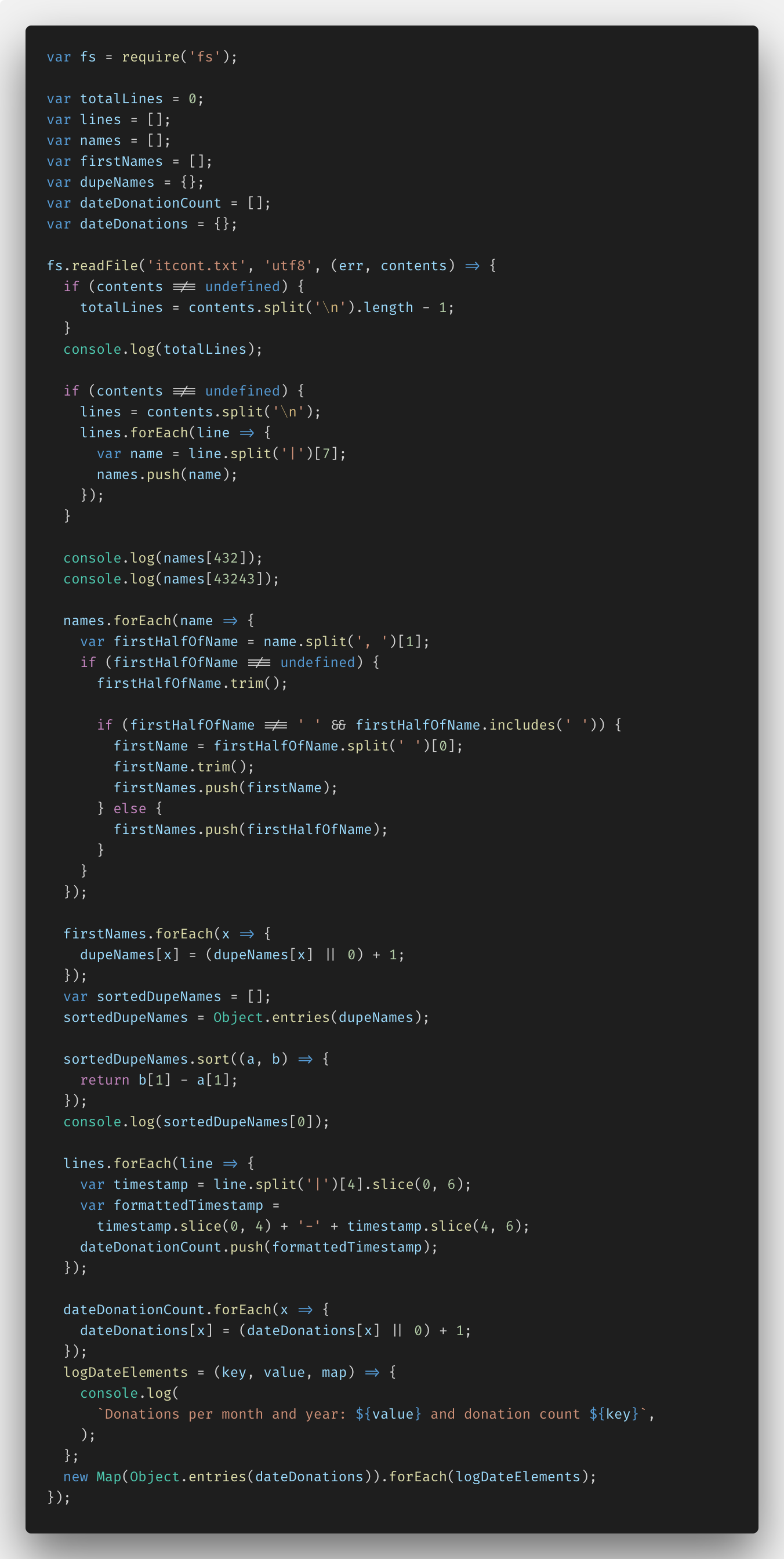
All the solution you can see here .
Node.js results
The solution turned out to be working. I added the path to the readFileStream.js file and ... watched as the Node server crashed with a javascript error heap out of memory.

It turned out that, although everything worked, but this solution tried to transfer the entire contents of the file to memory, which was impossible with a volume of 2.55 GB. Node can simultaneously work with 1.5 GB in memory, not more.
Therefore, none of my decisions came up. It took a new one that could work even with such large files.
New solution
As it turned out, it was necessary to use the popular NPM module EventStream.
Having studied the documentation, I was able to understand what needs to be done. Here is the third version of the program code.

The documentation for the module indicated that the data stream should be split into individual elements using the \ n symbol at the end of each line of the txt file.
Basically, the only thing I had to change was the answer names. I did not manage to place 130 million names in the array - again a memory shortage error occurred. I solved the problem by calculating the 432nd and 43243rd names and putting them into my own array. A little is not what was asked in the conditions, but who said that you can not be creative?
Round 2. We try the program in work
Yes, it's the same 2.55 GB file, we cross our fingers and watch the result.
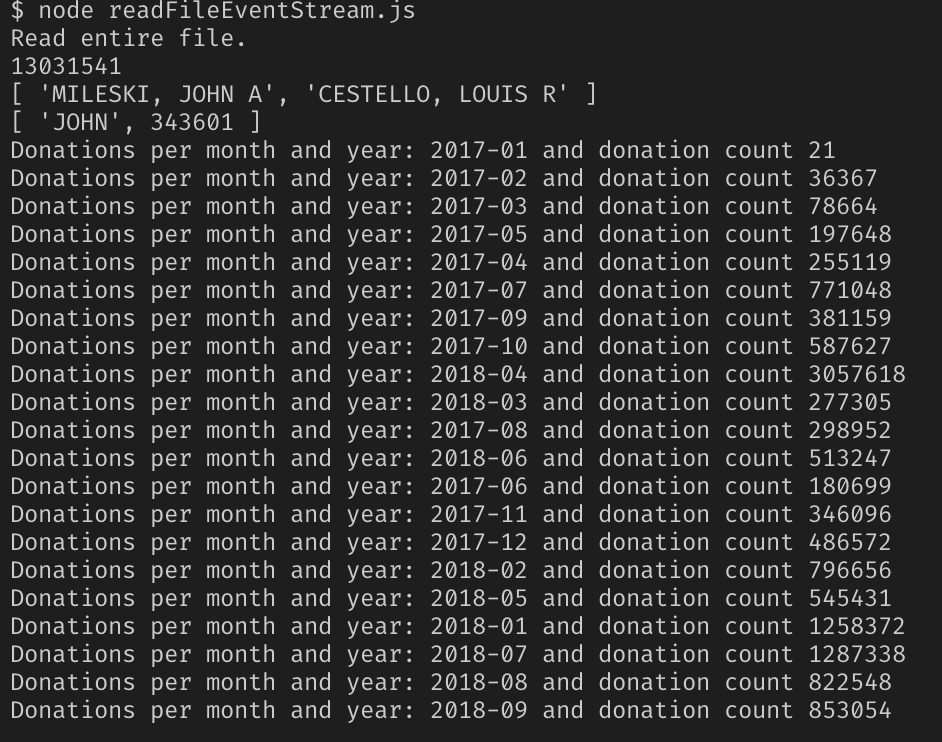
Success!
As it turned out, simply Node.js is not suitable for solving such problems, its capabilities are somewhat limited. But expanding them with modules, you can work with such large files.
Skillbox recommends:
- Practical course "Profession web developer" .
- Practical course "Mobile Developer PRO" .
- Practical annual course "PHP-developer from scratch to PRO" .
Source: https://habr.com/ru/post/427415/
All Articles