Transition to Google Cloud Platform (Google Cloud Platform - GCP)
[Part 1 of 2]

Hike blog appeared December 12, 2012, and then there were quite a few readers. By 2016, we reached 100 million registered users and 40 billion messages per month. But such growth marked the problem associated with the scaling of our infrastructure. To eliminate it, we needed a high-performance platform at an affordable price. In 2016 and 2017, we were faced with numerous interruptions in work, with this we had to do something urgently, so we began to consider various options.
We needed a cloud platform that would quickly build, test, and deploy applications in a scalable and reliable cloud environment. At first glance, it may seem that all large cloud platforms are similar in many respects, but they have several fundamental differences.
We will divide this publication into 2 parts:
- Reason for choosing GCP
- Transition to GCP without downtime
Concept confirmation
We started with a proof of concept, within which we considered the compatibility of the existing infrastructure with the services offered by the Google Cloud cloud platform, and also planned elements for future development.
Key areas under the concept confirmation:
⊹ Load Balancer
⊹ Computer
⊹ Networking and firewalls
⊹ Security
⊹ Cloud availability
⊹ Big data
⊹ Charging
Confirmation of the concept included testing and checking the bandwidth of virtual machines / network / load balancer, as well as stability, scalability, security, monitoring, billing, big data and machine learning services. In June 2017, we made an important decision to transfer the entire infrastructure to the cloud platform Google Cloud.
We wanted to choose a cloud platform that can cope with the innumerable problems we faced:
⊹ Load Balancer:
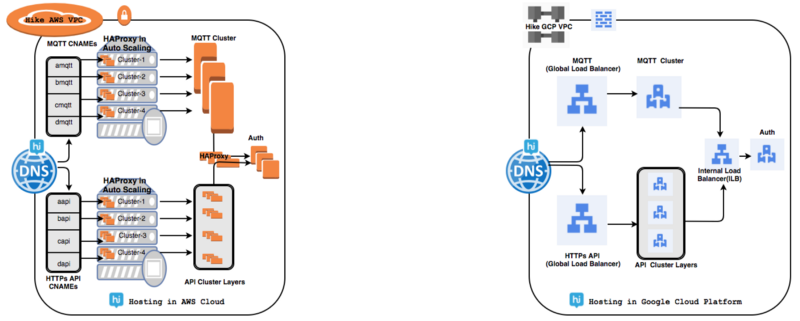
We had a lot of problems related to managing local HAProxy clusters to handle several tens of millions of active users daily connections. The global load balancer (GLB) has solved many of our problems.

Using global GCP load balancing, a single anycast IP address can forward up to 1 million requests per second to various GCP servers, such as Managed Instance Groups (MIG), and this does not require “pre-warming up”. Our overall response time improved 1.7–2 times, because GLB uses a pool implementation that allows traffic to be distributed across multiple sources.
⊹ Computer:
There were no major problems in the computers themselves, but we needed a high-performance platform at an affordable price. The overall throughput of Google virtual machines increased 1.3-1.5 times, which reduced the total number of running virtual machine instances.
Redis tests were conducted with a cluster of 6 copies (8 cores, 30 GB each). Based on the results below, we conclude that GCP provides performance improvements of up to 48% (on average) for most REDIS operations and up to 77% for specific REDIS operations.
redis-benchmark -h -p 6379 -d 2048 -r 15 -q -n 10000000 -c 100

The Google Compute Engine (GCE) cloud computing service has provided additional benefits in managing our infrastructure by using the following:
● Managed Instance Group (MIG): MIG helps us maintain application services in a reliable environment with multi-zone functions instead of allocating resources for each zone. MIG automatically identifies and corrects inoperable instances in a group to ensure optimal performance of all instances.
● Live migration: Live migration helps keep virtual machine instances running even when the host system crashes, for example, when updating software or hardware. Working with our previous cloud partner, we received a notification about a planned maintenance event and had to stop and start the virtual machine in order to switch to a workable virtual machine.
● Custom Virtual Machines: Within the GCP framework, we can create our own virtual machines with the necessary processing power and memory for specific workloads.
⊹ Networking and firewalls:
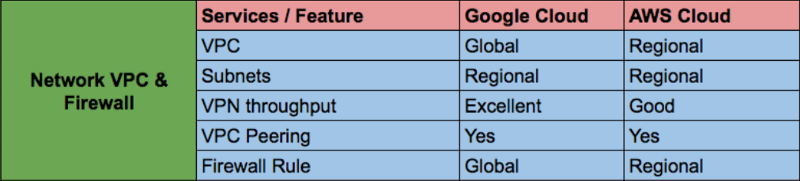
Managing multiple firewall networks and rules is not easy and can lead to risk. The default network VPC GCP is global and provides inter-regional communication without additional configuration and without changes in network bandwidth. Firewall rules provide flexibility within the VPC for projects that use the name of a tag rule.
For a network with low latency and higher bandwidth, we were forced to select costly instances with a bandwidth of 10 Gbit / s and activated the extended networks on these instances.
⊹ Security:
Security is the most important aspect for any cloud service provider. In the past, security was either not available for most services, or was just an additional option.
Google cloud services are encrypted by default. To protect data, GCP uses several levels of encryption. Using multiple levels of encryption protects the backed up data and allows you to choose the best approach based on the requirements of the application, for example, using the Identity-Aware Proxy service and encrypting inactive data by default.
In addition, GCP closes recent catastrophic vulnerabilities based on speculative execution in the vast majority of modern processors (Meltdown, Specter). Google has developed a new binary modification method called Retpoline , which allows you to work around this problem and transparently make changes to the entire running infrastructure seamlessly visible to users.
⊹ Cloud availability:
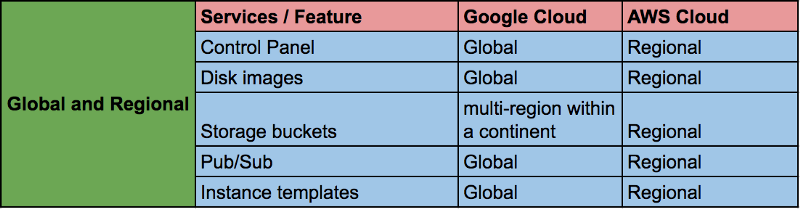
The availability of GCP resources is different from that of other cloud solution providers, since the majority of GCP resources, including the control panel, are either zonal or regional. We had to manage several VPCs for individual projects from individual accounts that needed a VPC peering or a VPN connection for a private connection. We also had to keep a copy of the image in a separate account.
In the Google Cloud, most resources are either global or regional. Such resources include the control panel (where we can see all the virtual machines of our project on one screen), disk images, data storage containers (several regions within the continent), VPC (but separate subnets are regional), global load balancing, publishing and subscription, etc.
⊹ Big data:
We have moved from a monolithic, hard-to-manage analytical configuration to a fully manageable BQ system, which resulted in improvements in three areas:
● Increase query processing speed up to 50 times.
● Fully managed data processing systems with automatic scaling.
● Data processing time was reduced from hours to 15 minutes.
⊹ Charging:
It was difficult to compare different cloud providers because many services were not similar or comparable, differed for different usage scenarios, and depended on unique usage scenarios.
Advantages of GCP:
● Discounts for long-term use: Apply when virtual machines are increasing in use when certain thresholds are reached. We can automatically receive a discount of up to 30% on workloads that are performed during most of the reference month.
● Per-minute billing: When allocating a virtual machine, GCE will be charged for a minimum period of 10 minutes, after which per-minute billing begins for the actual use of the virtual machine. This provides a significant reduction in costs, because we do not have to pay for a full hour, even if the copy of the machine is running for less than an hour.
● Superior hardware, fewer instances: We found that for almost all levels and applications, using GCP, you can perform the same workload with the same performance but fewer instances.
● Commitment, not reservation: Another factor is the GCP approach to the price of virtual machine instances. In AWS, the primary way to reduce the cost of a virtual machine copy is to purchase reserved copies for a period of 1-3 years. If the workload required a virtual machine configuration change, or we did not need this instance, we had to sell it on the market for reserved instances at a lower price. The GCP has a “Discount for Obligation to Use”, which is valid when reserving processor and memory resources, and it does not matter which virtual machine instances we use.
Conclusion:
Based on this detailed analysis, we decided to switch to GCP and began working on the transition map and checklists. In the next article we will talk about what we learned during the implementation of this project.
')
Source: https://habr.com/ru/post/427347/
All Articles