How to become datsayntistom if you are over 40 and you are not a programmer
There is an opinion that one can become a dascientist only with a corresponding higher education, and better a degree.
However, the world is changing, technologies are becoming available for mere mortals. I may surprise someone, but today any business analyst is able to master machine learning technologies and achieve results that compete with professional mathematicians, and perhaps even the best.
In order not to be unfounded, I will tell you my story - as an economist I became a data analyst, having obtained the necessary knowledge through online courses and participating in machine learning competitions.
')

Now I am a leading analyst in the big data group at QIWI, but three years ago I was quite far from datasynes and heard about artificial intelligence only from the news. But then everything changed, thanks in part to Coursera and Kaggle.
So, first things first.
I am an economist, a long time worked as a business consultant. My specialization is the development of a budgeting and reporting methodology for subsequent automation. If in a simple way - this is about first building the process normally, so that the result from automation will be.
3 years ago, at the age of 42, when I felt that I was starting to become bronze from consulting success, and began to think about the need for change. About the next career. I already had the experience of how to start a career from scratch (in 30 years I changed the quiet life of an economist for consulting), so the changes did not frighten me.
It does not occur at once, but when you think about it, it becomes obvious that despite the fact that I had already worked for 20 years, there are still about 25 years ahead of retirement (it’s been a long time that it’s necessary to rely on retirement at 70 or even later ). In general, the road ahead is longer than the one that has already passed, and it would be nice to go through it with the current specialty. So, it was worth learning. At that time I was freelance, and for the sake of the future I reduced the number of projects and was able to allocate enough time to study.
While I was thinking where to move further, I discovered the Coursera. The Western approach to education, when you first of all explain the meaning, the general idea, and only then the details, turned out to be close to me. In contrast to the brutal Soviet education system, which assumes that only decent ones will come up, they give a chance to those like me, who have gaps in basic education.
I started with business intelligence courses. It was extremely useful for me as a consultant. These same courses helped me to better understand the role of AI-technologies for business development and, most importantly, to see my role in this. This is the same as with other technologies - it is not at all necessary that those who develop new technologies will be the best in their application. For technology to really help a business, it is important to understand this business. Expertise in business processes is just as important as understanding the very technologies of machine learning, big data processing, and so on.
And I plunged into courses on datasynes, statistics, programming.
With interruptions, I have mastered more than 30 courses on the Coursera in a year and no longer felt like an alien in the world of big data and machine learning.
Some courses have recommended Kaggle as an excellent practice site. Do not repeat my mistakes - I came there only when I already felt that I had accumulated enough knowledge. And it was worth doing it half a year earlier, when the first understanding of what and how appeared. Would be six months steeper. After all, this is not just one of the venues for competitions, it is the best (at present) platform for the development of machine learning in practice, which is useful for both beginners and superguru. And there you grow, as they say, for two days - only courses without practice will not give such an effect.
My first contest was a contest from Santander Bank - predicting customer satisfaction. I was a novice and wanted to check the level of my knowledge in business. I combined my experience as a bank client, skills in analyzing business cases and machine learning technology and made a pretty good model with which I climbed into the top 50 in the public leaderbord. It was much higher than my expectations from the first competition, given that more than 5 thousand people participated in it.
But not everything was so simple. I didn’t earn the happy one then. There is such a common problem among beginners as “retraining a model” that I met in practice. Local validation was poorly organized, I was too focused on public, and as a result - on the closed part of the test, I flew 500+ positions down. Of course, I was upset, but the lesson was good: good validation is the basis of machine learning, and it needs to be taken seriously. Now this component is one of the strengths of my models.
Despite the weak first result, there was confidence that getting into the top is real, you need more practice and additional knowledge.
For those who do not know how good Caggle is - the community is ready to help newcomers with overcoming some gags, discussing ideas, sharing examples of how it works. Well and no less important - at the end of the competition there is an opportunity to study the decisions of the leaders. Learning from one’s experience can make rapid progress. Not necessarily on all the rake itself.
I can not help but recall the OpenDataseSayns (ods.ai) - the Russian-speaking datasientist community. The machine learning trainings that ods organizes are another way to get to know the subject more deeply. Well, as a platform for communication on any issues also helps a lot. If you are thinking about your future in datasynes, and you have not signed up for ods yet, this is a serious mistake.
Since the datascentists' vacancies often mentioned the expectations of high results on Kaggle, I saw a chance for myself - besides the fact that I am gaining experience, it is possible to fill in an empty resume with more or less relevant experience. I began to treat Caggle as a job, where a career start could be a bonus.
As soon as free time appeared, I built models on Kaggle, and with each competition the result became better.
I had something that most of the participants didn’t have - the ability to analyze business cases and my consulting experience, it helped a lot in building models. Six months later, I took the 7th place in the next competition from the bank Santander and earned my first gold medal.
If you persistently strive for a specific goal, you will reach it - in June 2017, after a year or so of my battles on Kaggle, we, together with Agnis Lyukis, a developer from Latvia, won a competition from Sberbank to predict apartment prices in Moscow.

Our strengths were the understanding of the case (this is a complex task, the solution of which was not worth going to the forehead, as most did) and strong local validation. We finished the competition second in public, but our model almost did not suffer from retraining and did not lose much on closed data - in the final we were the first with a giant margin.
This victory threw me into the top 50 of the global Kaggle ranking, which resulted in job offers. Having studied the options, I chose the bank, as a place where there are many tasks on which you can pump skills, and also feel the whole truth of life while developing models - yet in competitions conditions are more greenhouse.
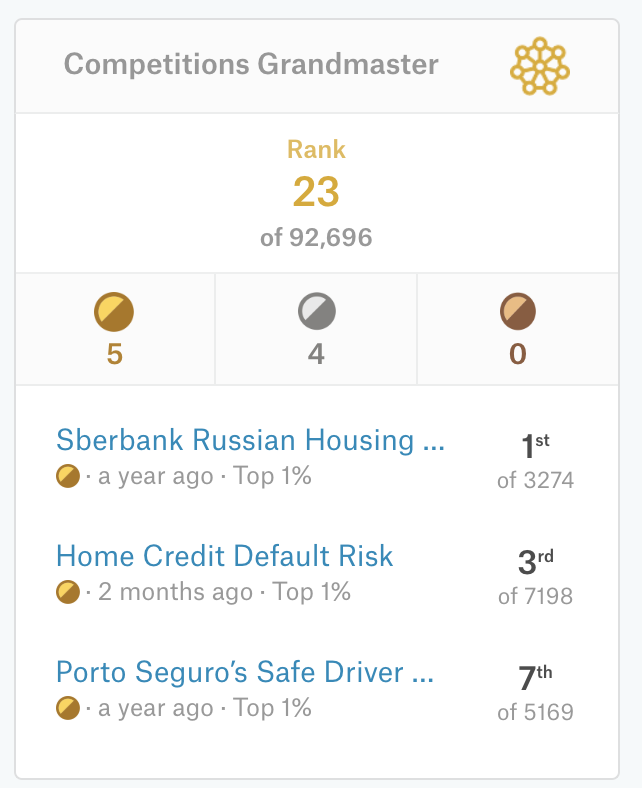
I had ambitious plans for career growth and the option “not to rush to work for several years to grow to the next level” was not considered. It was necessary to plow up and at work, and in the second shift not to forget about Kaggle. Not easy, but who is easy now? And it gave results - 3 more gold medals and I earned epaulets of Grandmaster on Kaggle plus was fixed in the global top (now 23rd).
Like a cherry on a cake - 3 place in bank scoring competitions, what I professionally did last year. And, as you can see, he did well.
Alas, the truth of life in a bank is also a very conservative and slow decision-making process. The introduction of my models moved slowly. There was no plan to restructure the work of the entire bank, so it was easier, albeit with regret, to change jobs.
It turned out to be not difficult at all - thanks to the results on Kaggle, the search did not take much time, and for several months I’ve been digging billions of tables in QIWI. We have a lot of interesting tasks , I am sure that pretty soon we will be able to turn our data into a profit for the company - the background of the economist helps a lot with this. Kagglopyop here also appeared in the cashier for several cases.
The most important part is to understand the task and find all the drivers that can affect the result. The better you understand the case, the greater the chance to speak cool. Anyone can generate hundreds or even thousands of statistical features, but they can come up with those that are designed specifically for this task and explain well the target, which is much more complicated. Invest in it, and quickly find yourself in the top. It is necessary to apply any relevant experience (business, household, etc.) - it helps a lot.
Then - local validation. Your main enemy is retraining, especially if you use such a powerful technology as gradient boosting. I know how psychologically difficult it is to stop focusing on a public leaderboard, but if you don’t want disappointment, the correct answer is to use cross-validation, say “No” to the delayed sample. Of course, there are exceptions, but even in tasks with time series, you can fasten cross-validation, greatly increasing the reliability of the model. Not always the local validation scheme will be simple, but it is worth spending time on it - both in competitions and in real life. The reward will be stable models.
Of course, you need to study the basic tools well. Knowing the principles of different technologies, you can adequately choose the best tool for solving a specific problem. For tabular data, the current leader is gradient boosting, and specifically Lightgbm. But it is important to be able to use other methods, from logging to neural networks - in life and in competitions will not be superfluous.
By the way, the best way to understand what technologies rule now, when everything is changing rapidly - to see which libraries are used by competition leaders. In recent years, many worthwhile technologies have broken through the Caggle world.
Hyperparameters. It is important to know the key hyperparameters of the tools used. Usually not many parameters need to be changed. My belief is that you should not spend a lot of time on the selection of hyperparameters. Of course, it is necessary to find good hyperparameters, but you should not dwell on it.
Usually, when the model is outlined, I select a more or less stable set of parameters and return to their tuning only towards the end, when other ideas have run out. Common sense dictates that the time spent on creating and testing new variables, libraries, non-standard ideas, can give a much greater increase in the model than the improvement from the transition from a good set of hyper-parameters to the ideal.
If you make a bet on Kaggle as a feature that will pump your resume - consider this as a job, you will not regret. It helped me, will help you.
Well, again about the competition. It is very high here, so it’s very difficult to win alone. Teamwork is very useful, the synergy of ideas allows you to jump above your head. Feel free to use it.
Well, a little motivation in the end. First of all, I proved to myself that I can become a dancinetist at 44 years old. The recipe turned out to be surprisingly simple - online education, business-oriented thinking, efficiency and purposefulness.
Now in every possible way I incite my friends to do the same way. A new digital economy needs (and will need) highly qualified specialists. Coursera + Kaggle - this is just an excellent opportunity to start.
Once, after all, Excel was a new and incomprehensible tool (I even remember how difficult the first battles with the traditional calculator were). And now, after all, no one has any doubt that a specialist who is knowledgeable in his business can squeeze out of Excel much more real benefits than the Excel developers themselves.
It will take a little time, and ownership of machine learning tools will become as mandatory as owning Excel, so why not prepare for this in advance and win the competition in the labor market right now?
Moreover, the competition should not be afraid. The more people from the business will come to datasens - the more money. The introduction of new technologies in traditional sectors of the economy can accelerate business, and for this, business must begin to understand the opportunities that new technologies are opening today. In fact, any business analyst, having mastered several courses, may be at the forefront of progress and help his company outrun conservative competitors.
I hope my experience will help someone make an important decision.
If you have any questions about Kaggle, please write, I’ll be happy to answer in the comments.
However, the world is changing, technologies are becoming available for mere mortals. I may surprise someone, but today any business analyst is able to master machine learning technologies and achieve results that compete with professional mathematicians, and perhaps even the best.
In order not to be unfounded, I will tell you my story - as an economist I became a data analyst, having obtained the necessary knowledge through online courses and participating in machine learning competitions.
')
Now I am a leading analyst in the big data group at QIWI, but three years ago I was quite far from datasynes and heard about artificial intelligence only from the news. But then everything changed, thanks in part to Coursera and Kaggle.
So, first things first.
About myself
I am an economist, a long time worked as a business consultant. My specialization is the development of a budgeting and reporting methodology for subsequent automation. If in a simple way - this is about first building the process normally, so that the result from automation will be.
3 years ago, at the age of 42, when I felt that I was starting to become bronze from consulting success, and began to think about the need for change. About the next career. I already had the experience of how to start a career from scratch (in 30 years I changed the quiet life of an economist for consulting), so the changes did not frighten me.
It does not occur at once, but when you think about it, it becomes obvious that despite the fact that I had already worked for 20 years, there are still about 25 years ahead of retirement (it’s been a long time that it’s necessary to rely on retirement at 70 or even later ). In general, the road ahead is longer than the one that has already passed, and it would be nice to go through it with the current specialty. So, it was worth learning. At that time I was freelance, and for the sake of the future I reduced the number of projects and was able to allocate enough time to study.
While I was thinking where to move further, I discovered the Coursera. The Western approach to education, when you first of all explain the meaning, the general idea, and only then the details, turned out to be close to me. In contrast to the brutal Soviet education system, which assumes that only decent ones will come up, they give a chance to those like me, who have gaps in basic education.
I started with business intelligence courses. It was extremely useful for me as a consultant. These same courses helped me to better understand the role of AI-technologies for business development and, most importantly, to see my role in this. This is the same as with other technologies - it is not at all necessary that those who develop new technologies will be the best in their application. For technology to really help a business, it is important to understand this business. Expertise in business processes is just as important as understanding the very technologies of machine learning, big data processing, and so on.
And I plunged into courses on datasynes, statistics, programming.
With interruptions, I have mastered more than 30 courses on the Coursera in a year and no longer felt like an alien in the world of big data and machine learning.
Kaggle
Some courses have recommended Kaggle as an excellent practice site. Do not repeat my mistakes - I came there only when I already felt that I had accumulated enough knowledge. And it was worth doing it half a year earlier, when the first understanding of what and how appeared. Would be six months steeper. After all, this is not just one of the venues for competitions, it is the best (at present) platform for the development of machine learning in practice, which is useful for both beginners and superguru. And there you grow, as they say, for two days - only courses without practice will not give such an effect.
My first contest was a contest from Santander Bank - predicting customer satisfaction. I was a novice and wanted to check the level of my knowledge in business. I combined my experience as a bank client, skills in analyzing business cases and machine learning technology and made a pretty good model with which I climbed into the top 50 in the public leaderbord. It was much higher than my expectations from the first competition, given that more than 5 thousand people participated in it.
But not everything was so simple. I didn’t earn the happy one then. There is such a common problem among beginners as “retraining a model” that I met in practice. Local validation was poorly organized, I was too focused on public, and as a result - on the closed part of the test, I flew 500+ positions down. Of course, I was upset, but the lesson was good: good validation is the basis of machine learning, and it needs to be taken seriously. Now this component is one of the strengths of my models.
Despite the weak first result, there was confidence that getting into the top is real, you need more practice and additional knowledge.
For those who do not know how good Caggle is - the community is ready to help newcomers with overcoming some gags, discussing ideas, sharing examples of how it works. Well and no less important - at the end of the competition there is an opportunity to study the decisions of the leaders. Learning from one’s experience can make rapid progress. Not necessarily on all the rake itself.
I can not help but recall the OpenDataseSayns (ods.ai) - the Russian-speaking datasientist community. The machine learning trainings that ods organizes are another way to get to know the subject more deeply. Well, as a platform for communication on any issues also helps a lot. If you are thinking about your future in datasynes, and you have not signed up for ods yet, this is a serious mistake.
Since the datascentists' vacancies often mentioned the expectations of high results on Kaggle, I saw a chance for myself - besides the fact that I am gaining experience, it is possible to fill in an empty resume with more or less relevant experience. I began to treat Caggle as a job, where a career start could be a bonus.
As soon as free time appeared, I built models on Kaggle, and with each competition the result became better.
I had something that most of the participants didn’t have - the ability to analyze business cases and my consulting experience, it helped a lot in building models. Six months later, I took the 7th place in the next competition from the bank Santander and earned my first gold medal.
If you persistently strive for a specific goal, you will reach it - in June 2017, after a year or so of my battles on Kaggle, we, together with Agnis Lyukis, a developer from Latvia, won a competition from Sberbank to predict apartment prices in Moscow.
Our strengths were the understanding of the case (this is a complex task, the solution of which was not worth going to the forehead, as most did) and strong local validation. We finished the competition second in public, but our model almost did not suffer from retraining and did not lose much on closed data - in the final we were the first with a giant margin.
This victory threw me into the top 50 of the global Kaggle ranking, which resulted in job offers. Having studied the options, I chose the bank, as a place where there are many tasks on which you can pump skills, and also feel the whole truth of life while developing models - yet in competitions conditions are more greenhouse.
I had ambitious plans for career growth and the option “not to rush to work for several years to grow to the next level” was not considered. It was necessary to plow up and at work, and in the second shift not to forget about Kaggle. Not easy, but who is easy now? And it gave results - 3 more gold medals and I earned epaulets of Grandmaster on Kaggle plus was fixed in the global top (now 23rd).
Like a cherry on a cake - 3 place in bank scoring competitions, what I professionally did last year. And, as you can see, he did well.
Alas, the truth of life in a bank is also a very conservative and slow decision-making process. The introduction of my models moved slowly. There was no plan to restructure the work of the entire bank, so it was easier, albeit with regret, to change jobs.
It turned out to be not difficult at all - thanks to the results on Kaggle, the search did not take much time, and for several months I’ve been digging billions of tables in QIWI. We have a lot of interesting tasks , I am sure that pretty soon we will be able to turn our data into a profit for the company - the background of the economist helps a lot with this. Kagglopyop here also appeared in the cashier for several cases.
And now how to achieve success in competitions
The most important part is to understand the task and find all the drivers that can affect the result. The better you understand the case, the greater the chance to speak cool. Anyone can generate hundreds or even thousands of statistical features, but they can come up with those that are designed specifically for this task and explain well the target, which is much more complicated. Invest in it, and quickly find yourself in the top. It is necessary to apply any relevant experience (business, household, etc.) - it helps a lot.
Then - local validation. Your main enemy is retraining, especially if you use such a powerful technology as gradient boosting. I know how psychologically difficult it is to stop focusing on a public leaderboard, but if you don’t want disappointment, the correct answer is to use cross-validation, say “No” to the delayed sample. Of course, there are exceptions, but even in tasks with time series, you can fasten cross-validation, greatly increasing the reliability of the model. Not always the local validation scheme will be simple, but it is worth spending time on it - both in competitions and in real life. The reward will be stable models.
Of course, you need to study the basic tools well. Knowing the principles of different technologies, you can adequately choose the best tool for solving a specific problem. For tabular data, the current leader is gradient boosting, and specifically Lightgbm. But it is important to be able to use other methods, from logging to neural networks - in life and in competitions will not be superfluous.
By the way, the best way to understand what technologies rule now, when everything is changing rapidly - to see which libraries are used by competition leaders. In recent years, many worthwhile technologies have broken through the Caggle world.
Hyperparameters. It is important to know the key hyperparameters of the tools used. Usually not many parameters need to be changed. My belief is that you should not spend a lot of time on the selection of hyperparameters. Of course, it is necessary to find good hyperparameters, but you should not dwell on it.
Usually, when the model is outlined, I select a more or less stable set of parameters and return to their tuning only towards the end, when other ideas have run out. Common sense dictates that the time spent on creating and testing new variables, libraries, non-standard ideas, can give a much greater increase in the model than the improvement from the transition from a good set of hyper-parameters to the ideal.
If you make a bet on Kaggle as a feature that will pump your resume - consider this as a job, you will not regret. It helped me, will help you.
Well, again about the competition. It is very high here, so it’s very difficult to win alone. Teamwork is very useful, the synergy of ideas allows you to jump above your head. Feel free to use it.
Total
Well, a little motivation in the end. First of all, I proved to myself that I can become a dancinetist at 44 years old. The recipe turned out to be surprisingly simple - online education, business-oriented thinking, efficiency and purposefulness.
Now in every possible way I incite my friends to do the same way. A new digital economy needs (and will need) highly qualified specialists. Coursera + Kaggle - this is just an excellent opportunity to start.
Once, after all, Excel was a new and incomprehensible tool (I even remember how difficult the first battles with the traditional calculator were). And now, after all, no one has any doubt that a specialist who is knowledgeable in his business can squeeze out of Excel much more real benefits than the Excel developers themselves.
It will take a little time, and ownership of machine learning tools will become as mandatory as owning Excel, so why not prepare for this in advance and win the competition in the labor market right now?
Moreover, the competition should not be afraid. The more people from the business will come to datasens - the more money. The introduction of new technologies in traditional sectors of the economy can accelerate business, and for this, business must begin to understand the opportunities that new technologies are opening today. In fact, any business analyst, having mastered several courses, may be at the forefront of progress and help his company outrun conservative competitors.
I hope my experience will help someone make an important decision.
If you have any questions about Kaggle, please write, I’ll be happy to answer in the comments.
Source: https://habr.com/ru/post/427311/
All Articles