How to ensure high availability in Kubernetes
Note trans. : The original article was written by a technical writer from Google, working on documentation for Kubernetes (Andrew Chen), and a director of software engineering at SAP (Dominik Tornow). Its goal is to explain the basics of the organization and implementation of high availability in Kubernetes in an accessible and visual manner. It seems to us that the authors succeeded, so we are happy to share the translation.

Kubernetes is a container orchestration engine designed to run containerized applications on multiple nodes, commonly referred to as a cluster. In these publications, we use a systems modeling approach to improve the understanding of Kubernetes and its underlying concepts. Readers are advised to already have a basic understanding of Kubernetes.
')
Kubernetes is a scalable and reliable container orchestration engine. Scalability here is determined by responsiveness in the presence of a load, and reliability - responsiveness in the presence of failures.
Note that the scalability and reliability of Kubernetes does not mean the scalability and reliability of the application running in it. Kubernetes is a scalable and reliable platform, but each application in K8s has yet to go through certain stages in order to become such and avoid bottlenecks and single points of failure.
For example, if an application is deployed as ReplicaSet or Deployment, Kubernetes (re-) plans and (re-) starts the sweeps affected by the node drops. However, if the application is deployed as file, Kubernetes will not take any action in the event of a node failure. Therefore, although Kubernetes itself remains functional, the responsiveness of your application depends on the chosen architecture solutions and deployment.
The focus of this publication is the reliability of the Kubernetes. She tells how Kubernetes maintains responsiveness in the presence of bounce.

Scheme 1. Master and worker
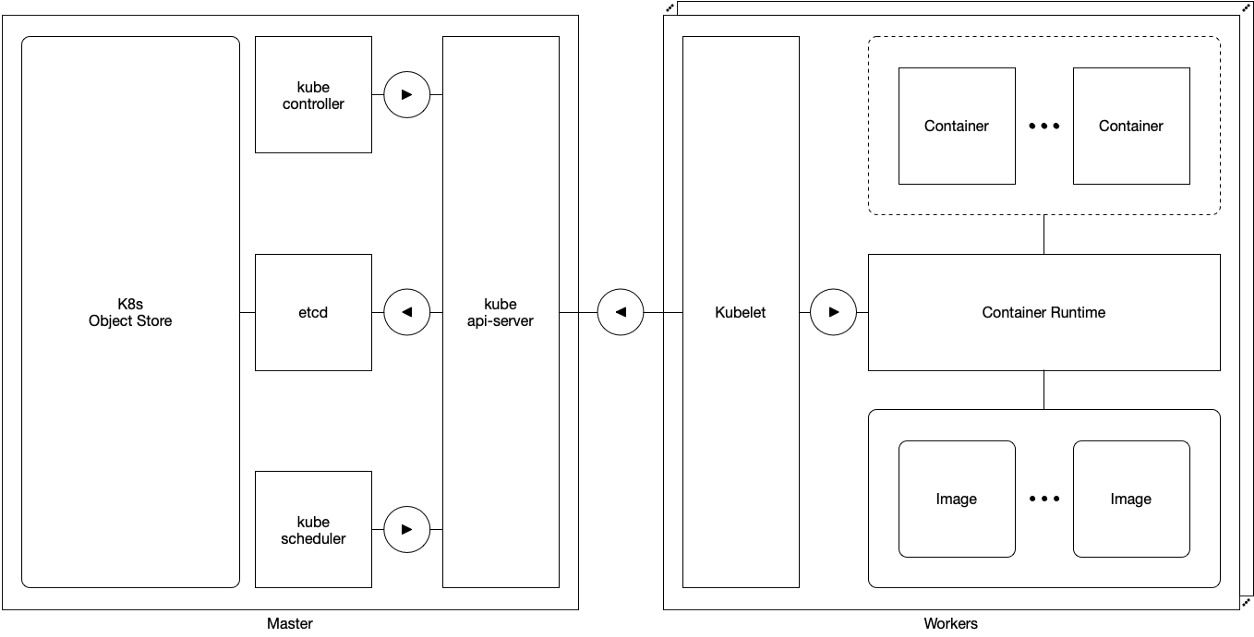
At the conceptual level, the components of Kubernetes are grouped into two distinct classes: the components of the master (Master) and the components of the worker (Worker) .
The masters are responsible for managing everything except the performance of the pods. Wizard components include:
Workers are responsible for managing the execution of the pods. They have one component:
Workers are trivially reliable: a temporary or permanent failure of any worker in the cluster does not affect the master or other workers in the cluster. If the application is deployed accordingly, Kubernetes (re-) plans and (re-) launches any one affected by the worker’s failure.
Scheme 2. Configuration with a single master
In a single master configuration, the Kubernetes cluster consists of one master and many workers. The latter are directly connected to the kube-apiserver wizard and interact with it.
In this configuration, the responsiveness of Kubernetes depends on:
Since the only master is a single point of failure, this configuration is not in the high availability category.

Scheme 3. Configuration with multiple wizards
In a configuration with many wizards, the Kubernetes cluster consists of many wizards and many workers. Workers connect to any master's kube-apiserver and interact with it through a highly available load balancer.
In this configuration, Kubernetes does not depend on:
Since there is no single point of failure in such a configuration, it is considered highly available.
In the configuration with many wizards, numerous kube-controller-managers and kube-schedulers are involved. If two components modify the same objects, conflicts may arise.
To avoid potential conflicts, a leader / follower pattern has been implemented for kube-controller-manager and kube-scheduler in Kubernetes. Each group selects one lead (or leader) , and the rest of the group takes the role of the slave. At any one time only one master is active, and the followers are passive.

Scheme 4. Redundant Deployment wizard components in detail
This illustration shows a detailed example in which kube-controller-1 and kube-scheduler-2 are leading among kube-controller-managers and kube-schedulers. Since each group chooses its leader, they do not have to be on the same master at all.
A new leader is chosen by the members of the group at the time of launch or in the event of a lead falling. Lead - a member who has the so-called leader lease ("rented" at the moment the status of the leader).
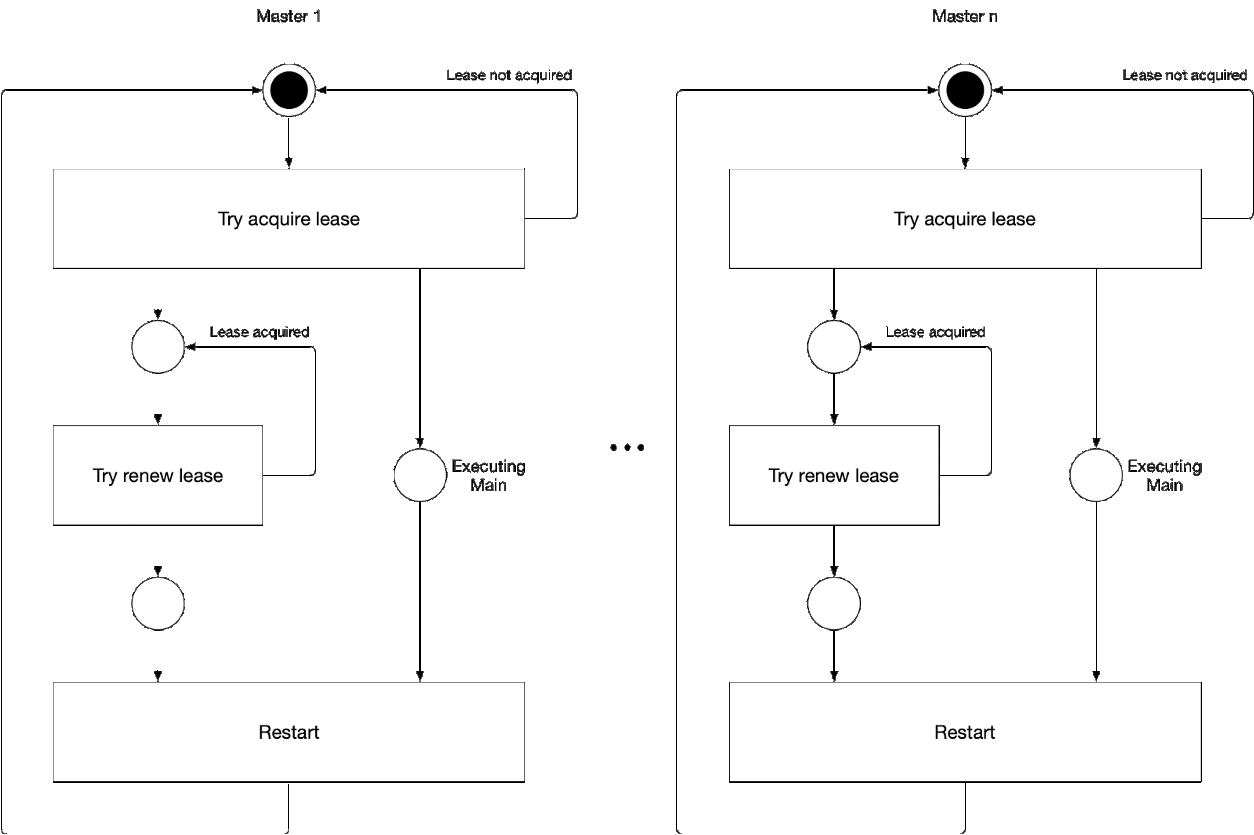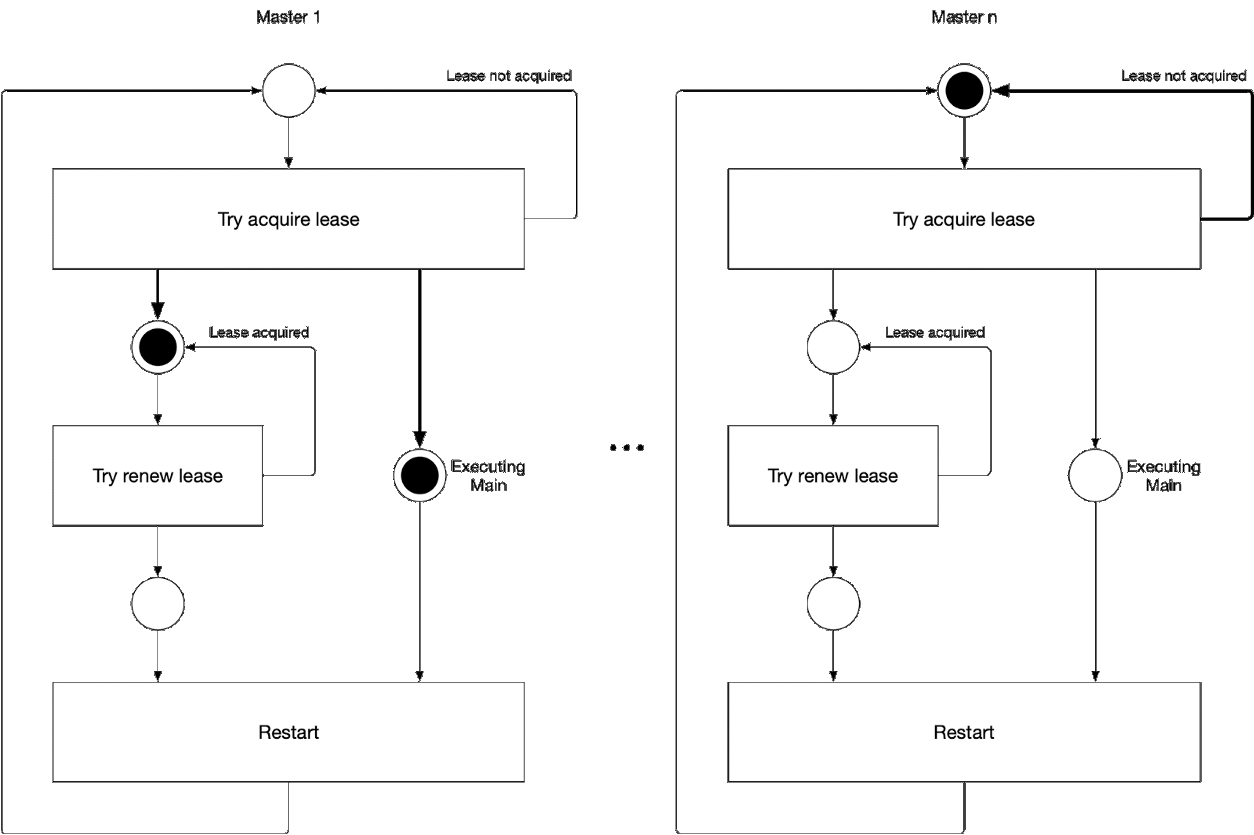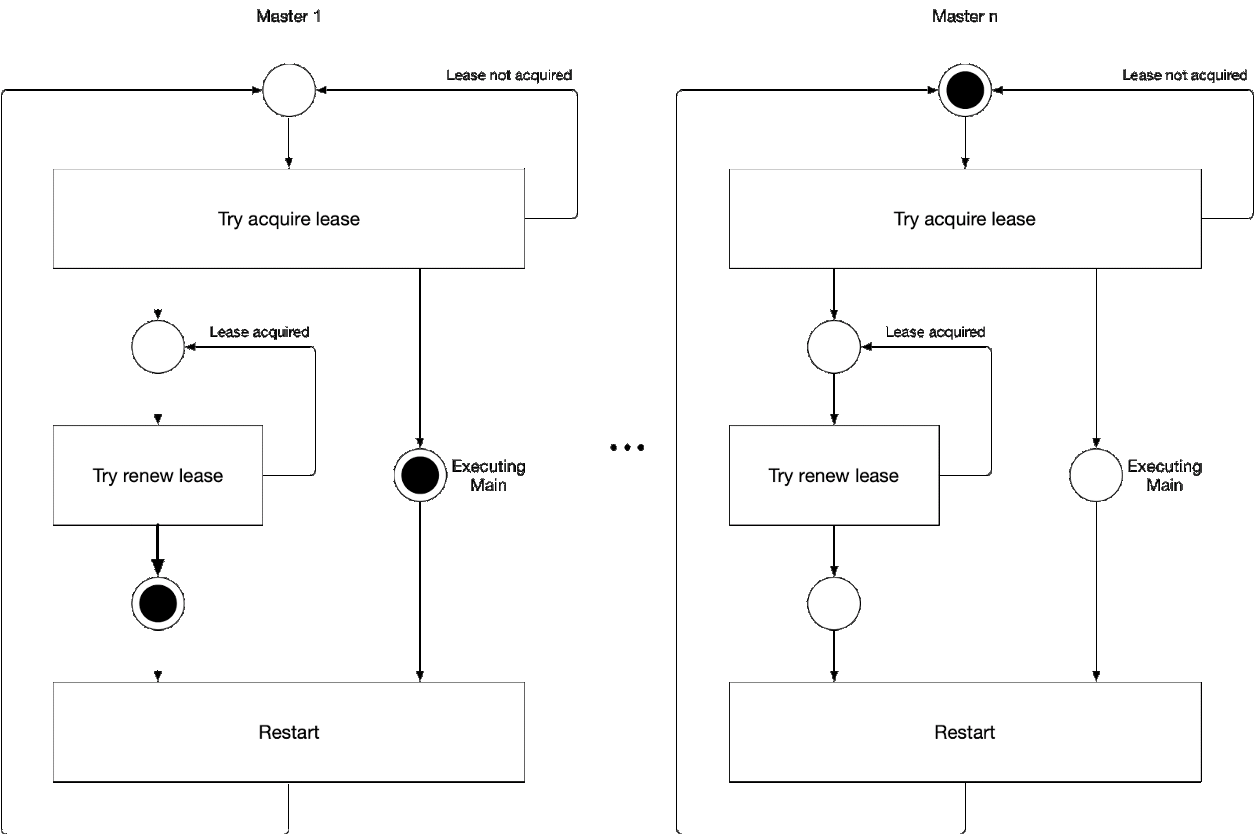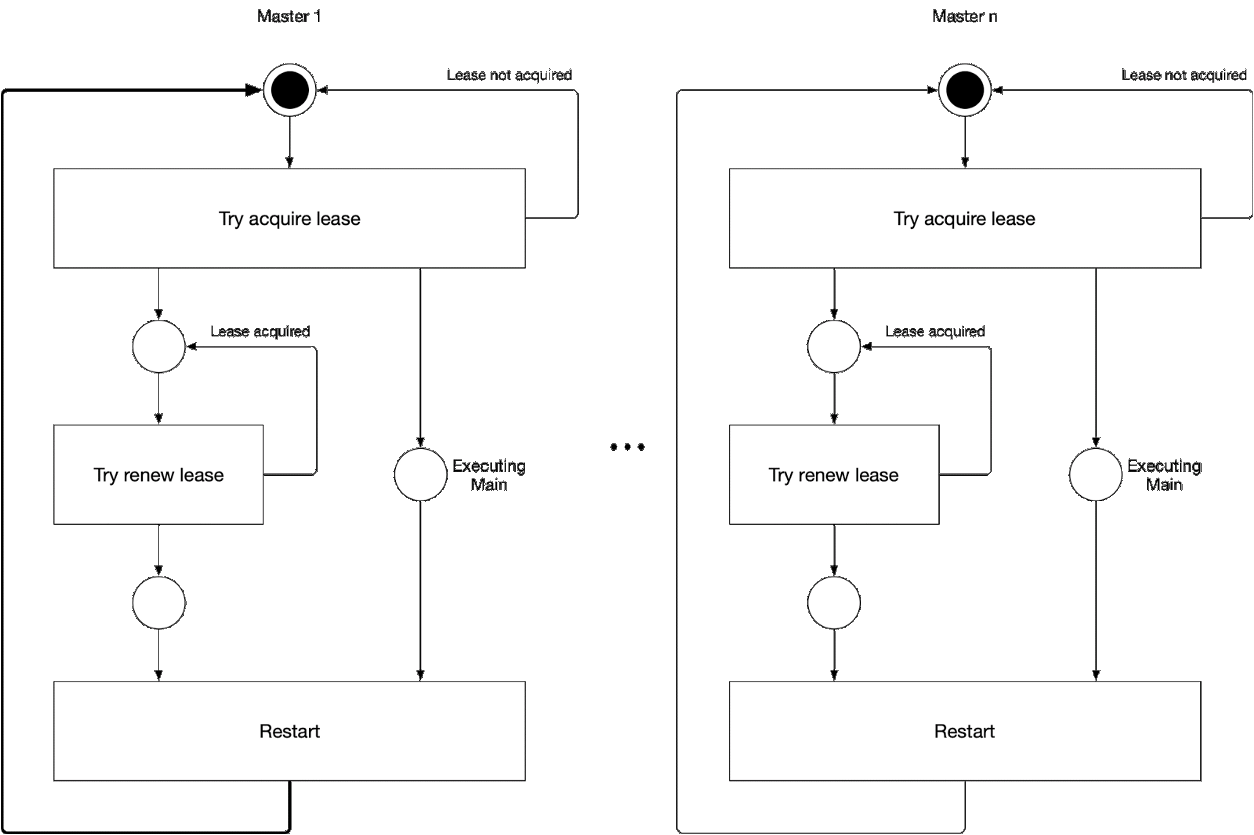
Scheme 5. The process of selecting the master master component
This illustration demonstrates the process of selecting a leader for kube-controller-manager and kube-scheduler. The logic of this process is as follows:
The current leader statuses for kube-controller-manager and kube-scheduler are permanently stored in the Kubernetes object storage as endpoints objects in the
Demonstration using the
Endpoint 's kube-scheduler and kube-controller-manager store information about the leader in the annotation
Although Kubernetes guarantees that there will be one master at a time, Kubernetes does not guarantee that two or more components of the master will not mistakenly assume that they are leading at this moment — this state is known as split brain .
An instructive discussion of the topic of split brain and possible ways to eliminate it can be found in the article “ How to do distributed locking ” by Martin Kleppmann.
Kubernetes does not use any split brain countermeasures. Instead, he relies on his ability to strive for the desired state over a period of time, which mitigates the consequences of conflicting decisions.
In a configuration with many masters, Kubernetes is a scalable and reliable container orchestration engine. In this configuration, Kubernetes provides reliability using many wizards and many workers. Many masters work on the master / slave pattern, and the workers work in parallel. Kubernetes has its own lead selection process in which information about the lead is stored as endpoints objects .
Information on how to prepare for the Kubernetes cluster of high availability can be obtained in the official documentation .
This post is part of the joint initiative of CNCF, Google and SAP, aimed at improving the understanding of Kubernetes and its underlying concepts.
Read also in our blog:
Kubernetes is a container orchestration engine designed to run containerized applications on multiple nodes, commonly referred to as a cluster. In these publications, we use a systems modeling approach to improve the understanding of Kubernetes and its underlying concepts. Readers are advised to already have a basic understanding of Kubernetes.
')
Kubernetes is a scalable and reliable container orchestration engine. Scalability here is determined by responsiveness in the presence of a load, and reliability - responsiveness in the presence of failures.
Note that the scalability and reliability of Kubernetes does not mean the scalability and reliability of the application running in it. Kubernetes is a scalable and reliable platform, but each application in K8s has yet to go through certain stages in order to become such and avoid bottlenecks and single points of failure.
For example, if an application is deployed as ReplicaSet or Deployment, Kubernetes (re-) plans and (re-) starts the sweeps affected by the node drops. However, if the application is deployed as file, Kubernetes will not take any action in the event of a node failure. Therefore, although Kubernetes itself remains functional, the responsiveness of your application depends on the chosen architecture solutions and deployment.
The focus of this publication is the reliability of the Kubernetes. She tells how Kubernetes maintains responsiveness in the presence of bounce.
Kubernetes architecture
Scheme 1. Master and worker
At the conceptual level, the components of Kubernetes are grouped into two distinct classes: the components of the master (Master) and the components of the worker (Worker) .
The masters are responsible for managing everything except the performance of the pods. Wizard components include:
Workers are responsible for managing the execution of the pods. They have one component:
Workers are trivially reliable: a temporary or permanent failure of any worker in the cluster does not affect the master or other workers in the cluster. If the application is deployed accordingly, Kubernetes (re-) plans and (re-) launches any one affected by the worker’s failure.
Single Master Configuration
Scheme 2. Configuration with a single master
In a single master configuration, the Kubernetes cluster consists of one master and many workers. The latter are directly connected to the kube-apiserver wizard and interact with it.
In this configuration, the responsiveness of Kubernetes depends on:
- the only master
- Connecting workers to a single master.
Since the only master is a single point of failure, this configuration is not in the high availability category.
Multi Wizard Configuration
Scheme 3. Configuration with multiple wizards
In a configuration with many wizards, the Kubernetes cluster consists of many wizards and many workers. Workers connect to any master's kube-apiserver and interact with it through a highly available load balancer.
In this configuration, Kubernetes does not depend on:
- the only master
- Connecting workers to a single master.
Since there is no single point of failure in such a configuration, it is considered highly available.
Leader (leader) and slave (follower) in Kubernetes
In the configuration with many wizards, numerous kube-controller-managers and kube-schedulers are involved. If two components modify the same objects, conflicts may arise.
To avoid potential conflicts, a leader / follower pattern has been implemented for kube-controller-manager and kube-scheduler in Kubernetes. Each group selects one lead (or leader) , and the rest of the group takes the role of the slave. At any one time only one master is active, and the followers are passive.
Scheme 4. Redundant Deployment wizard components in detail
This illustration shows a detailed example in which kube-controller-1 and kube-scheduler-2 are leading among kube-controller-managers and kube-schedulers. Since each group chooses its leader, they do not have to be on the same master at all.
Lead selection
A new leader is chosen by the members of the group at the time of launch or in the event of a lead falling. Lead - a member who has the so-called leader lease ("rented" at the moment the status of the leader).
Scheme 5. The process of selecting the master master component
This illustration demonstrates the process of selecting a leader for kube-controller-manager and kube-scheduler. The logic of this process is as follows:
' ' , :
-
-
' ' , :
- leader lease
-
- holderIdentity 'self'Tracking leading
The current leader statuses for kube-controller-manager and kube-scheduler are permanently stored in the Kubernetes object storage as endpoints objects in the
kube-system namespace. Since two Kubernetes cannot have the same name at the same time, type (kind) and namespace, there can be only one endpoint for kube-scheduler and for kube-controller-manager.Demonstration using the
kubectl console utility: $ kubectl get endpoints -n kube-system NAME ENDPOINTS AGE kube-scheduler <none> 30m kube-controller-manager <none> 30m Endpoint 's kube-scheduler and kube-controller-manager store information about the leader in the annotation
control-plane.alpha.kubernetes.io/leader : $ kubectl describe endpoints kube-scheduler -n kube-system Name: kube-scheduler Annotations: control-plane.alpha.kubernetes.io/leader= { "holderIdentity": "scheduler-2", "leaseDurationSeconds": 15, "acquireTime": "2018-01-01T08:00:00Z" "renewTime": "2018-01-01T08:00:30Z" } Although Kubernetes guarantees that there will be one master at a time, Kubernetes does not guarantee that two or more components of the master will not mistakenly assume that they are leading at this moment — this state is known as split brain .
An instructive discussion of the topic of split brain and possible ways to eliminate it can be found in the article “ How to do distributed locking ” by Martin Kleppmann.
Kubernetes does not use any split brain countermeasures. Instead, he relies on his ability to strive for the desired state over a period of time, which mitigates the consequences of conflicting decisions.
Conclusion
In a configuration with many masters, Kubernetes is a scalable and reliable container orchestration engine. In this configuration, Kubernetes provides reliability using many wizards and many workers. Many masters work on the master / slave pattern, and the workers work in parallel. Kubernetes has its own lead selection process in which information about the lead is stored as endpoints objects .
Information on how to prepare for the Kubernetes cluster of high availability can be obtained in the official documentation .
About publication
This post is part of the joint initiative of CNCF, Google and SAP, aimed at improving the understanding of Kubernetes and its underlying concepts.
PS from translator
Read also in our blog:
- “ Experiments with kube-proxy and unavailability of a node in Kubernetes ”;
- " Improving the reliability of Kubernetes: how to quickly notice that the node has fallen ";
- “We understand the Container Storage Interface (in Kubernetes and not only) ”;
- “ Understand RBAC in Kubernetes ”;
- “ What happens in Kubernetes when starting the kubectl run? Part 1 ";
- “ How does the Kubernetes scheduler actually work? ";
- " Behind the scenes of the network in Kubernetes ";
- " Our experience with Kubernetes in small projects " (video of the report, which includes an introduction to the technical device Kubernetes) .
Source: https://habr.com/ru/post/427283/
All Articles