Can artificial intelligence leave bookmakers out of work?
"The victory of artificial intelligence over football experts" - this could be the title of this article about the results of a football competition. Could, but, alas, did not.
During the World Cup we held a competition in NORBIT for the best prediction of football matches. I am too superficially versed in football to qualify for something, but the desire to take part in the competition still won my laziness. Under the cut - the story of how, thanks to machine learning, I was able to achieve good results among connoisseurs of football teams. True, I did not manage to break the bank, but I discovered a new fascinating world of Data Science.

I began with the hypothesis that in addition to the individual skill of national team players, there are still immeasurable but important factors - team spirit + teamwork (for example, a team in a game with a stronger opponent, but in a test match and in his field wins more often). The task is not so simple for a person, but quite understandable for machine learning.
')
I once had a little experience with ML (with the BrainJS library), but this time I decided to check the statement that Python is much better suited for such tasks.
I began acquaintance with Python with an excellent course on Coursera , and I learned the basics of machine learning from a series of articles from Open Data Science on Habré .
I quickly found an excellent Dataset with a history of all games of international teams from the beginning of the 20th century. After importing into Pandas dataframe:

In total, the database contains information about 39 thousand games of international teams.
Pandas makes it very convenient to analyze data, for example, the most productive match was between Australia and American Samoa in 2001, which ended with a score of 31: 0 .

Now we need to add an objective assessment of the level of the team in the year of the match. Such assessments involved in FIFA.

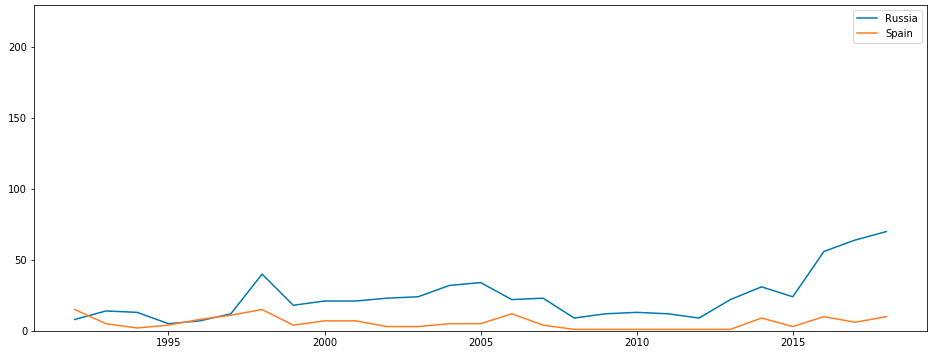
But, unfortunately, the FIFA rating has been conducted only since 1992. And, judging by the schedule, the teams' ratings are highly susceptible to change, and I really would not want to average the positions of the teams in the world rankings until this year.
UEFA has been keeping its statistics since more ancient times, but I could not find a ready-made dataset, so this site came to the rescue. Under Node.js, there is a powerful and convenient Cheerio for such tasks, but under Python everything turned out to be just as simple (yes, the administrator of this site will forgive me).
Rating fluctuations after adding the UEFA rating (and a small edit of country names on the basis of geopolitical casting):

But even here it was not without a barrel of tar - UEFA maintains a rating of only European teams (sometimes it is worth thinking about what is hidden under common abbreviations before using them). Fortunately, the playoffs were almost "European".
It remains a little more comfortable to divide the results into separate games and add ratings to the table.
The most interesting part is model training. Google immediately suggested the easiest and fastest option - this is the MLPClassifier classifier from the Python library - Sklearn. Let's try to teach the model on the example of Sweden.
Accuracy: 0.62
Not much more accurate than throwing a coin, but probably already better than my potential “expert” predictions. Here it would be wise to try to enrich the data, play with hyper parameters, but I decided to go the other way and try the gradient boosting library Catboost from Yandex. On the one hand, this is more patriotic, on the other - they promise high-quality work with categorical features, as confirmed by numerous comparisons .
Took the settings from the example :
Accuracy: 0.73
Already better, we try in business.

Forecast results for the final “Crotia team will lose to France with a probability of 93.7%”
Although this time I did not win the competition " NORBIT ", but I very much hope that this article for someone will reduce the level of magic in the practical use of machine learning, and maybe even motivate me to my own experiments.
During the World Cup we held a competition in NORBIT for the best prediction of football matches. I am too superficially versed in football to qualify for something, but the desire to take part in the competition still won my laziness. Under the cut - the story of how, thanks to machine learning, I was able to achieve good results among connoisseurs of football teams. True, I did not manage to break the bank, but I discovered a new fascinating world of Data Science.
I began with the hypothesis that in addition to the individual skill of national team players, there are still immeasurable but important factors - team spirit + teamwork (for example, a team in a game with a stronger opponent, but in a test match and in his field wins more often). The task is not so simple for a person, but quite understandable for machine learning.
')
I once had a little experience with ML (with the BrainJS library), but this time I decided to check the statement that Python is much better suited for such tasks.
I began acquaintance with Python with an excellent course on Coursera , and I learned the basics of machine learning from a series of articles from Open Data Science on Habré .
I quickly found an excellent Dataset with a history of all games of international teams from the beginning of the 20th century. After importing into Pandas dataframe:
In total, the database contains information about 39 thousand games of international teams.
Pandas makes it very convenient to analyze data, for example, the most productive match was between Australia and American Samoa in 2001, which ended with a score of 31: 0 .
Now we need to add an objective assessment of the level of the team in the year of the match. Such assessments involved in FIFA.
But, unfortunately, the FIFA rating has been conducted only since 1992. And, judging by the schedule, the teams' ratings are highly susceptible to change, and I really would not want to average the positions of the teams in the world rankings until this year.
UEFA has been keeping its statistics since more ancient times, but I could not find a ready-made dataset, so this site came to the rescue. Under Node.js, there is a powerful and convenient Cheerio for such tasks, but under Python everything turned out to be just as simple (yes, the administrator of this site will forgive me).
Web scraping ranking
from requests import get from requests.exceptions import RequestException from contextlib import closing from bs4 import BeautifulSoup def query_url(url): try: with closing(get(url, stream=True)) as resp: if is_good_response(resp): return resp.content else: return None except RequestException as e: log_error('Error during requests to {0} : {1}'.format(url, str(e))) return None def is_good_response(resp): content_type = resp.headers['Content-Type'].lower() return (resp.status_code == 200 and content_type is not None and content_type.find('html') > -1) def log_error(e): print(e) def parse_ranks(raw_html, year): html = BeautifulSoup(raw_html, 'html.parser') ranks = [] for tr in html.select('tr'): tds = tr.select("td") if len(tds) == 10: rank = (year, tds[2].text, tds[7].text) ranks.append(rank) return ranks def get_url(year): if year in range(1960, 1999): method = 1 if year in range(1999, 2004): method = 2 if year in range(2004, 2009): method = 3 if year in range(2009, 2018): method = 4 if year in range(2018, 2019): method = 5 return f"https://kassiesa.home.xs4all.nl/bert/uefa/data/method{method}/crank{year}.html" ranks = [] for year in range(1960, 2019): url = get_url(year) print(url) raw_html = query_url(url) rank = parse_ranks(raw_html, year) ranks += rank with open('team_ranks.csv', 'w') as f: writer = csv.writer(f , lineterminator='\n') writer.writerow(['year', 'country', 'rank']) for rank in ranks: writer.writerow(rank) Rating fluctuations after adding the UEFA rating (and a small edit of country names on the basis of geopolitical casting):
But even here it was not without a barrel of tar - UEFA maintains a rating of only European teams (sometimes it is worth thinking about what is hidden under common abbreviations before using them). Fortunately, the playoffs were almost "European".
It remains a little more comfortable to divide the results into separate games and add ratings to the table.
The most interesting part is model training. Google immediately suggested the easiest and fastest option - this is the MLPClassifier classifier from the Python library - Sklearn. Let's try to teach the model on the example of Sweden.
from sklearn.neural_network import MLPClassifier games = pd.read_csv('games.csv') # SwedenGames = games[(games.teamTitle == 'Sweden')] # y = SwedenGames['score'] y = y.astype('int') # X = SwedenGames.drop(['score', 'teamTitle', 'againstTitle'], axis=1) # X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25) mlp = MLPClassifier() mlp.fit(X_train, y_train); predictions = mlp.predict(X_test) print('Accuracy: {:.2}'.format( accuracy_score(y_test, mlp.predict(X_test)) )) Accuracy: 0.62
Not much more accurate than throwing a coin, but probably already better than my potential “expert” predictions. Here it would be wise to try to enrich the data, play with hyper parameters, but I decided to go the other way and try the gradient boosting library Catboost from Yandex. On the one hand, this is more patriotic, on the other - they promise high-quality work with categorical features, as confirmed by numerous comparisons .
Took the settings from the example :
# categorical_features_indices = [1, 2, 4] train_pool = Pool(X_train, y_train, cat_features=categorical_features_indices) validate_pool = Pool(X_test, y_test, cat_features=categorical_features_indices) # , GridSearchCV. best_params = { 'iterations': 500, 'depth': 10, 'learning_rate': 0.1, 'l2_leaf_reg': 1, 'eval_metric': 'Accuracy', 'random_seed': 42, 'logging_level': 'Silent', 'use_best_model': True } cb_model = CatBoostClassifier(**best_params) cb_model.fit(train_pool, eval_set=validate_pool) print('Accuracy: {:.2}'.format( accuracy_score(y_test, cb_model.predict(X_test)) )) Accuracy: 0.73
Already better, we try in business.
def get_prediction(country, against): y = SwdenGames['score'] y = y.astype('int') X = SwdenGames.drop(['score', 'againstTitle'], axis=1) train_pool = Pool(X, y, cat_features=[1, 2, 4]) query = [ get_team_rank(country, 2018), 0, 1 if country == 'Russia' else 0, get_team_rank(against, 2018), against] return cb_model.predict_proba([query])[0] team_1 = 'Belgium' team_2 = 'France' result = get_prediction(team_1, team_2) if result[0] > result[1]: print(f" {team_1} {team_2} {result[0]*100:.1f}%") else: print(f" {team_1} {team_2} {result[1]*100:.1f}%") Forecast results for the final “Crotia team will lose to France with a probability of 93.7%”
Although this time I did not win the competition " NORBIT ", but I very much hope that this article for someone will reduce the level of magic in the practical use of machine learning, and maybe even motivate me to my own experiments.
Source: https://habr.com/ru/post/427273/
All Articles