Performance Analysis of WSGI Servers: Part Two
This article is a translation of Kevin Goldberg’s “A Performance Analysis of Python WSGI Servers: Part 2” dzone.com/articles/a-performance-analysis-of-python-wsgi-servers-part with minor additions from the translator.

In the first part of this series, you met WSGI and the six most popular servers in the opinion of the author of WSGI . In this section, you will be shown the result of analyzing the performance of these servers. For this purpose, a special test sandbox was created.
Due to lack of time, the study was limited to six WSGI servers. All code with start-up instructions for this project is posted on GitHub . Perhaps over time, the project will expand and performance analyzes will be presented for other WSGI servers. But while we are talking about six servers:
')
To make the test as objective as possible, a Docker container was created to isolate the server being tested from the rest of the system. Also, the use of the Docker container ensured that each launch starts from a clean slate.
All initial performance indicators were included in the project repository , and a consolidated CSV file was also provided. Also for visualization were created graphics in the environment of Google-doc .
This graph shows the average number of simultaneous requests; The higher the number, the better.
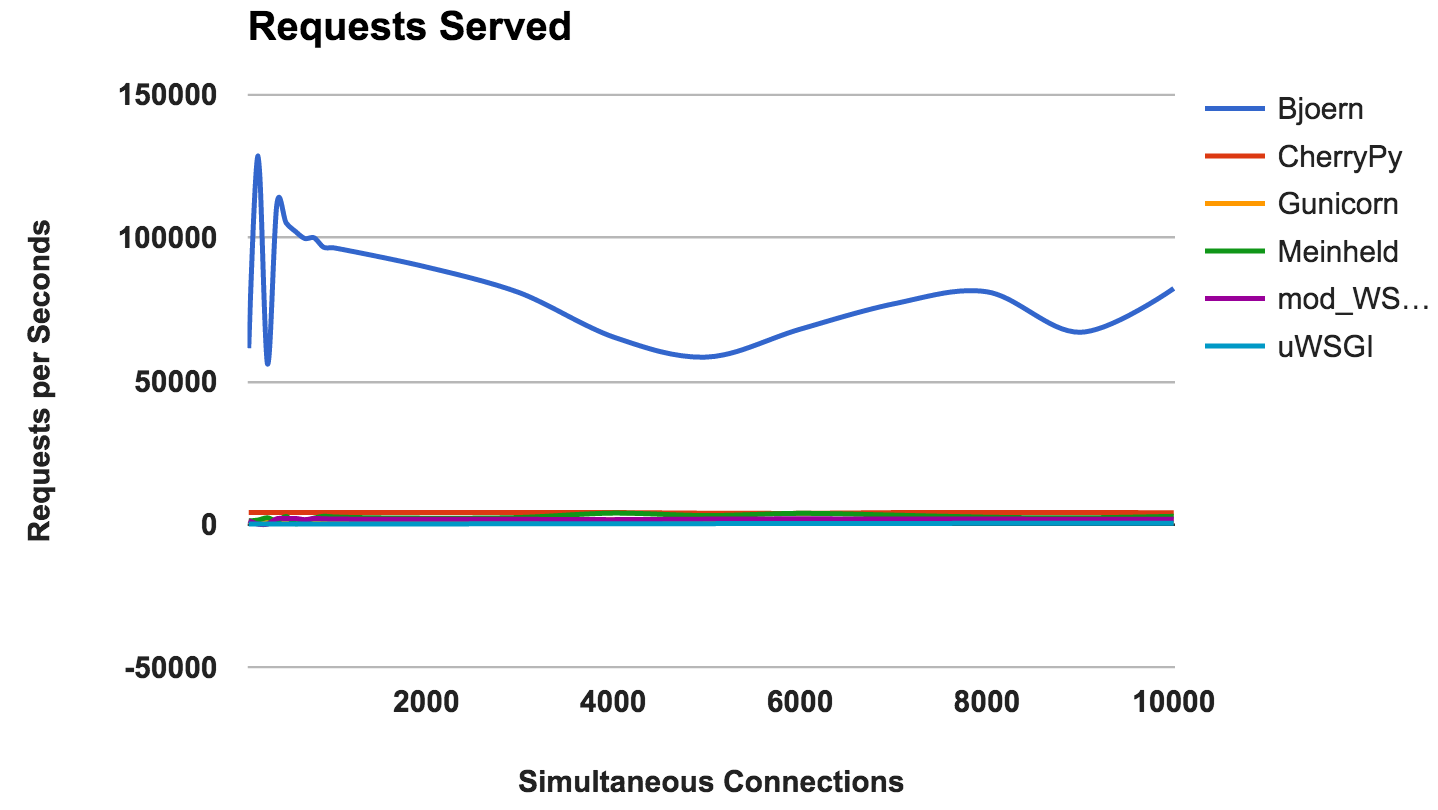
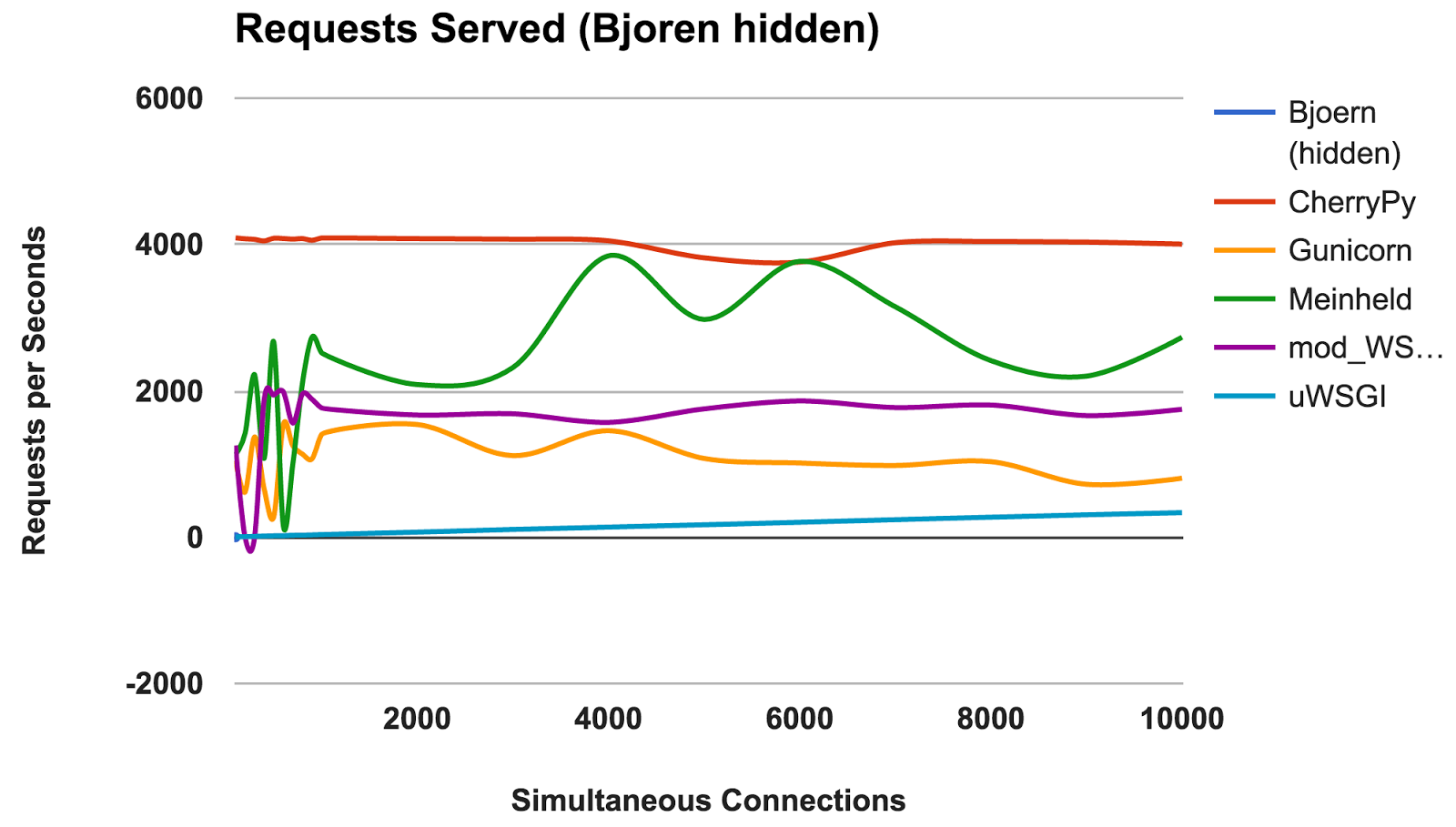
WINNER: Bjoern
By the number of persistent requests, Bjoern is an obvious winner. However, given that the numbers are much higher than those of competitors, we are a bit skeptical. We are not sure that Bjoern is really so stunningly fast. At first we tested the servers alphabetically, and we thought that Bjoern had an unfair advantage. However, even after starting the servers in random order of the server and re-testing the result remained the same.
We were disappointed with the weak uWSGI results. We expected him to be in the lead. During testing, we noticed that the uWSGI logs were typing on the screen, and we initially explained the lack of performance by the extra work that the server was doing. However, even after the “ --disable-logging ” option is added, uWSGI is still the slowest server.
As mentioned in the uWSGI manual, it usually interfaces with a proxy server, such as Nginx. However, we are not sure that this can explain such a big difference.
The delay is the amount of time elapsed between the request and its response. Lower numbers are better.
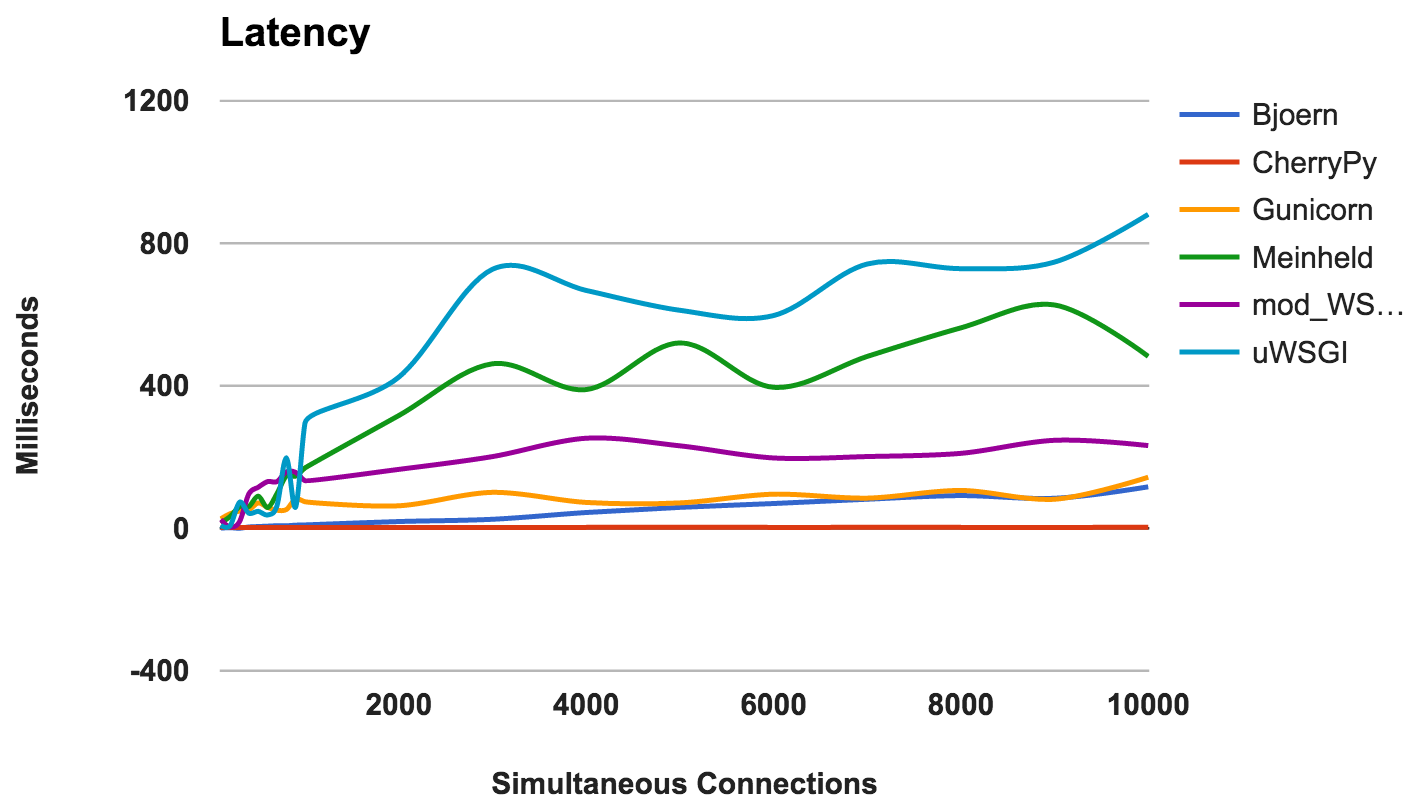
WINNER: CherryPy
This metric shows the memory requirements and the “lightness” of each server. Lower numbers are better.
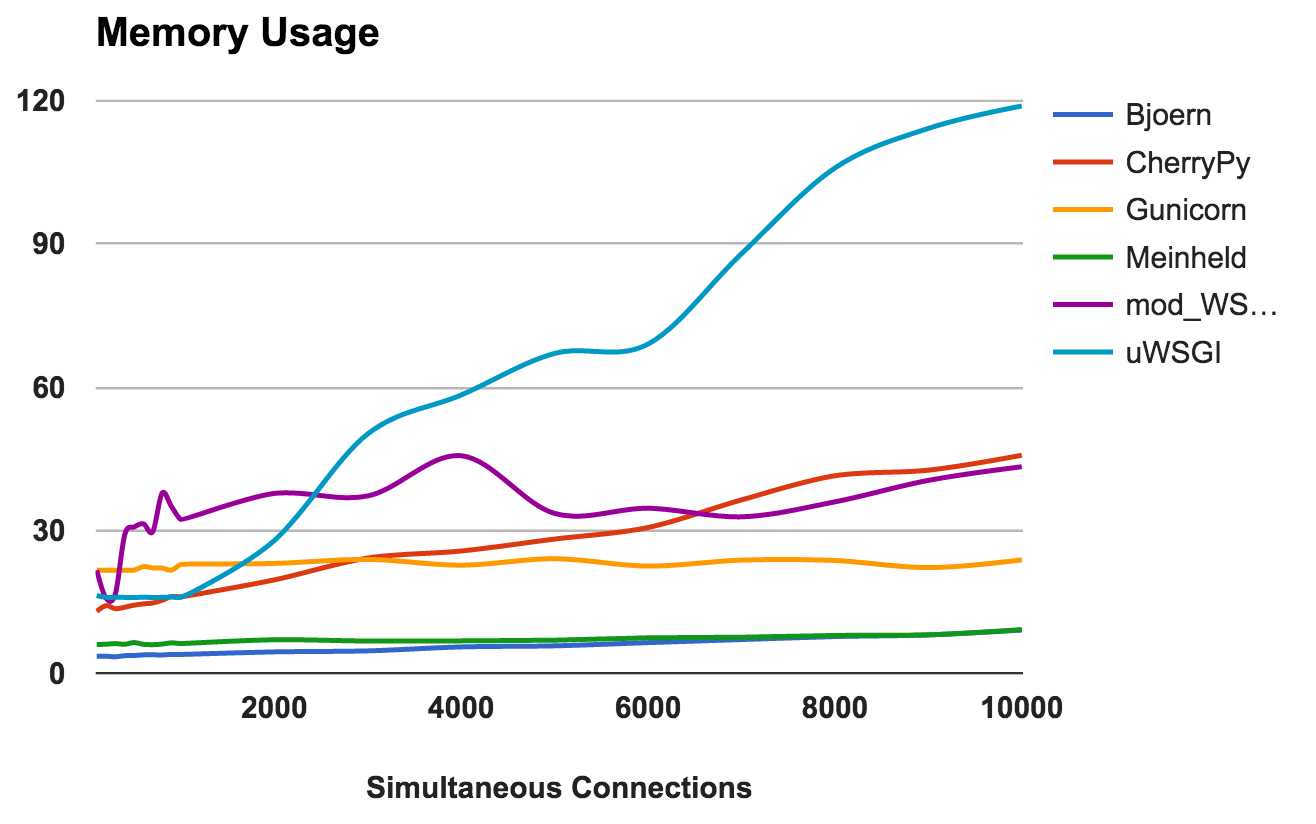
WINNERS: Bjoern and Meinheld
An error occurs when the server crashes, interrupts, or expires. The lower the better.
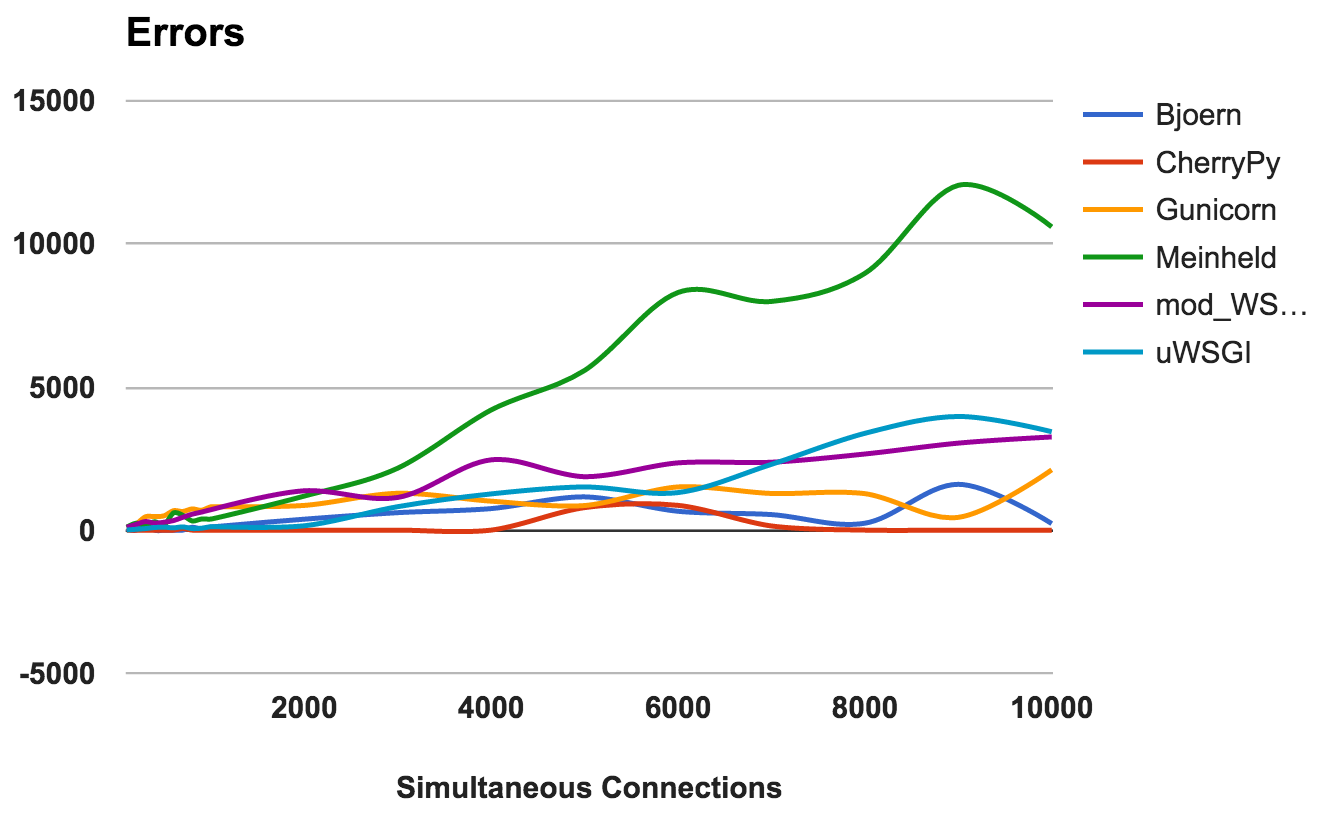
For each server, we calculated the ratio of the total ratio of requests to errors:
WINNER: CherryPy
High CPU utilization is not good or bad if the server is working well. However, this gives some interesting information about the server. Since two CPU cores were used, the maximum possible use is 200 percent.
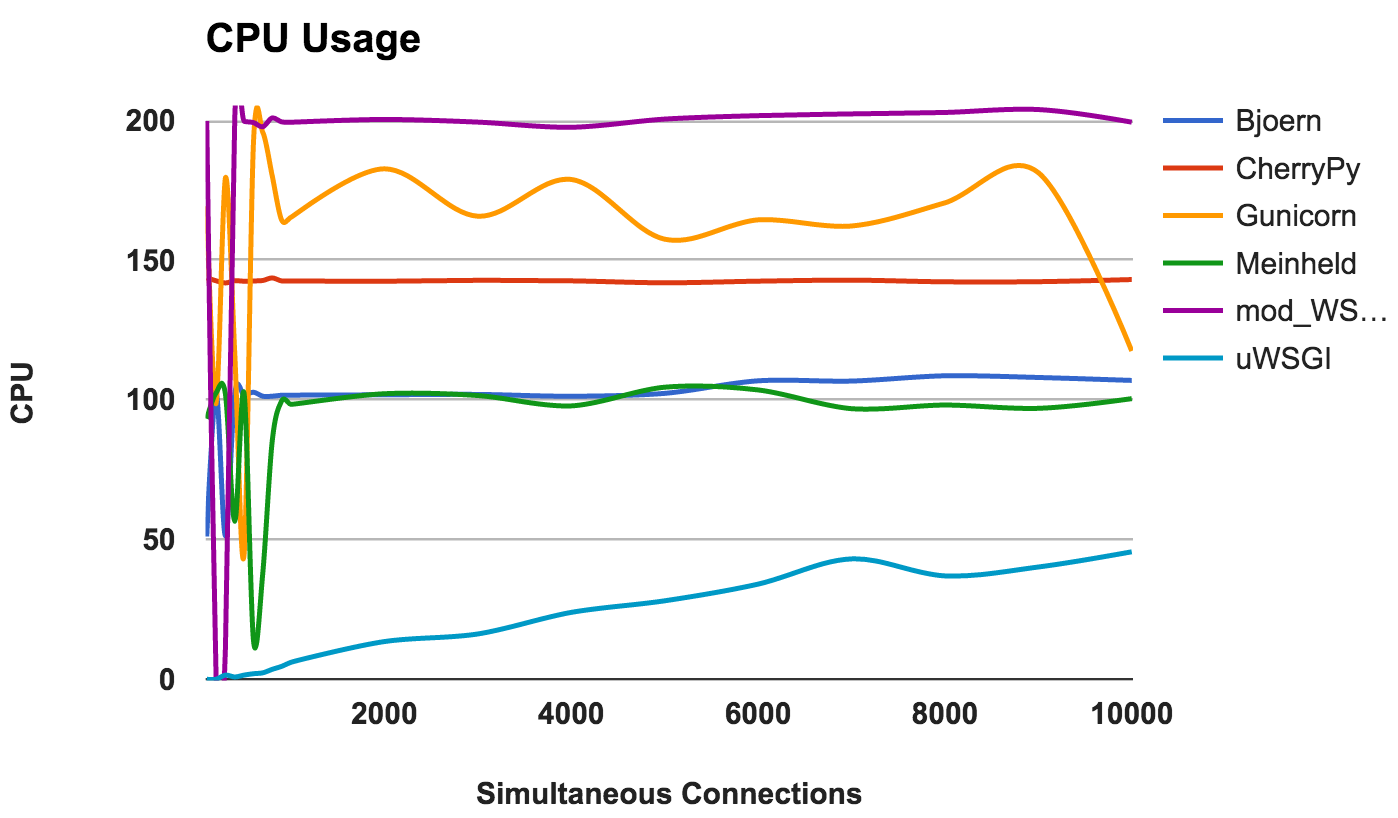
WINNER: No, because this is more likely an observation of behavior than a comparison of performance.
Summarize! Here are some general ideas that can be gleaned from the results of each server:
Introduction
In the first part of this series, you met WSGI and the six most popular servers in the opinion of the author of WSGI . In this section, you will be shown the result of analyzing the performance of these servers. For this purpose, a special test sandbox was created.
Contestants
Due to lack of time, the study was limited to six WSGI servers. All code with start-up instructions for this project is posted on GitHub . Perhaps over time, the project will expand and performance analyzes will be presented for other WSGI servers. But while we are talking about six servers:
')
- Bjoern describes itself as a “super fast WSGI server” and boasts that it is “the fastest, smallest and easiest WSGI server”. We have created a small application that uses most of the library's default settings.
- CherryPy is an extremely popular and stable framework and WSGI server. This small script was used to serve our sample application via CherryPy .
- Gunicorn was inspired by Ruby's Unicorn server (hence the name). He modestly asserts that he is "just implemented, easy to use and quite fast." Unlike Bjoern and CherryPy , Gunicorn is a standalone server. We created it using this command . The WORKER_COUNT parameter was set to twice the number of available processor cores, plus one. This was done based on recommendations from the Gunicorn documentation .
- Meinheld is a high-performance WSGI-compatible web server that claims to be lightweight. Based on the example specified on the server site, we created our application .
- mod_wsgi is created by the same creator as mod_python . Like mod_python , it is available only for Apache. However, it includes a tool called mod_wsgi express , which creates the smallest possible Apache instance. We configured and used mod_wsgi express with this command . To comply with Gunicorn , we configured mod_wsgi so that we can create workers twice as large as the processor cores.
- uWSGI is a full-featured application server. As a rule, uWSGI interfaces with a proxy server (for example: Nginx). However, in order to better evaluate the performance of each server, we tried to use only bare servers and created two workers for each available processor core.
Benchmark
To make the test as objective as possible, a Docker container was created to isolate the server being tested from the rest of the system. Also, the use of the Docker container ensured that each launch starts from a clean slate.
Server:
- Isolated in a Docker container.
- 2 processor cores are allocated.
- Container RAM was limited to 512 MB.
Testing:
- wrk , a modern HTTP benchmarking tool, ran tests.
- Servers were tested in random order with an increase in the number of simultaneous connections in the range from 100 to 10,000.
- wrk was limited to two CPU cores not used by Docker.
- Each test lasted 30 seconds and was repeated 4 times.
Metrics:
- The average number of persistent requests, errors, and delays was provided by wrk .
- Docker’s built-in monitoring showed levels of CPU and RAM usage.
- The highest and lowest readings were discarded, and the remaining values were averaged.
- For the curious, we sent the full script to GitHub .
results
All initial performance indicators were included in the project repository , and a consolidated CSV file was also provided. Also for visualization were created graphics in the environment of Google-doc .
RPS dependence on the number of simultaneous connections
This graph shows the average number of simultaneous requests; The higher the number, the better.
- Bjoern: The clear winner.
- CherryPy: Despite being written in pure Python, he was the best performer.
- Meinheld: Excellent performance, given the scarce container resources.
- mod_wsgi: Not the fastest, but the performance was consistent and adequate.
- Gunicorn: Good performance at lower loads, but there is a struggle with a large number of connections.
- uWSGI: Disappointed with poor results.
WINNER: Bjoern
Bjoern
By the number of persistent requests, Bjoern is an obvious winner. However, given that the numbers are much higher than those of competitors, we are a bit skeptical. We are not sure that Bjoern is really so stunningly fast. At first we tested the servers alphabetically, and we thought that Bjoern had an unfair advantage. However, even after starting the servers in random order of the server and re-testing the result remained the same.
uWSGI
We were disappointed with the weak uWSGI results. We expected him to be in the lead. During testing, we noticed that the uWSGI logs were typing on the screen, and we initially explained the lack of performance by the extra work that the server was doing. However, even after the “ --disable-logging ” option is added, uWSGI is still the slowest server.
As mentioned in the uWSGI manual, it usually interfaces with a proxy server, such as Nginx. However, we are not sure that this can explain such a big difference.
Delay
The delay is the amount of time elapsed between the request and its response. Lower numbers are better.
- CherryPy: Well coped with the load.
- Bjoern: In general, low latency, but works better with fewer simultaneous connections.
- Gunicorn: good and consistent.
- mod_wsgi: Average performance, even with a large number of simultaneous connections.
- Meinheld: Overall, acceptable performance.
- uWSGI: uWSGI again in last place.
WINNER: CherryPy
RAM usage
This metric shows the memory requirements and the “lightness” of each server. Lower numbers are better.
- Bjoern: Extremely light. Uses only 9 MB of RAM to handle 10,000 simultaneous requests.
- Meinheld: Same as Bjoern .
- Gunicorn: Skillfully copes with high loads with barely noticeable memory consumption.
- CherryPy: Initially, I needed a small amount of RAM, but its use rapidly increased with increasing load.
- mod_wsgi: At lower levels, it was one of the most intense in memory, but remained fairly consistent.
- uWSGI: Obviously, the version of the problem we are testing is with the amount of memory consumed.
WINNERS: Bjoern and Meinheld
Number of mistakes
An error occurs when the server crashes, interrupts, or expires. The lower the better.
For each server, we calculated the ratio of the total ratio of requests to errors:
- CherryPy: error rate around 0, even with a high number of connections.
- Bjoern: Errors were encountered, but this was offset by the number of requests processed.
- mod_wsgi: Works well with an acceptable error rate of 6%.
- Gunicorn: Works with a 9 percent error rate.
- uWSGI: Given the low number of requests that he served, he ended up with a 34 percent error rate.
- Meinheld: Fell at higher loads, throwing out over 10,000 errors during the most demanding test.
WINNER: CherryPy
CPU use
High CPU utilization is not good or bad if the server is working well. However, this gives some interesting information about the server. Since two CPU cores were used, the maximum possible use is 200 percent.
- Bjoern: single-threaded server, as evidenced by its consistent use on a 100% CPU.
- CherryPy: multi-threaded, but stuck at 150 percent. This may be due to GIL Python .
- Gunicorn: uses multiple processes with full utilization of CPU resources at lower levels.
- Meinheld: single-threaded server using CPU resources like Bjoern.
- mod_wsgi: Multithreaded server using all CPU cores for all measurements
- uWSGI: very low CPU utilization. Consumption of resources of the CPU does not exceed 50 percent. This is one of the proofs that uWSGI is not configured correctly.
WINNER: No, because this is more likely an observation of behavior than a comparison of performance.
Conclusion
Summarize! Here are some general ideas that can be gleaned from the results of each server:
- Bjoern: It justifies itself as a “super-fast, ultra-lightweight WSGI server.”
- CherryPy: High performance, low memory consumption and a small number of errors. Not bad for pure python.
- Gunicorn: Good server for average loads.
- Meinheld: Works well and requires minimal resources. However, struggling with higher loads.
- mod_wsgi: Integrates into Apache and works great.
- uWSGI: Very disappointed. Either we have incorrectly configured uWSGI , or the version we installed has basic errors.
Source: https://habr.com/ru/post/427217/
All Articles