Data-mining and Twitter
Among social networks, Twitter is more suitable for extracting text data due to the hard limit on the length of the message in which users are forced to put all the most essential.
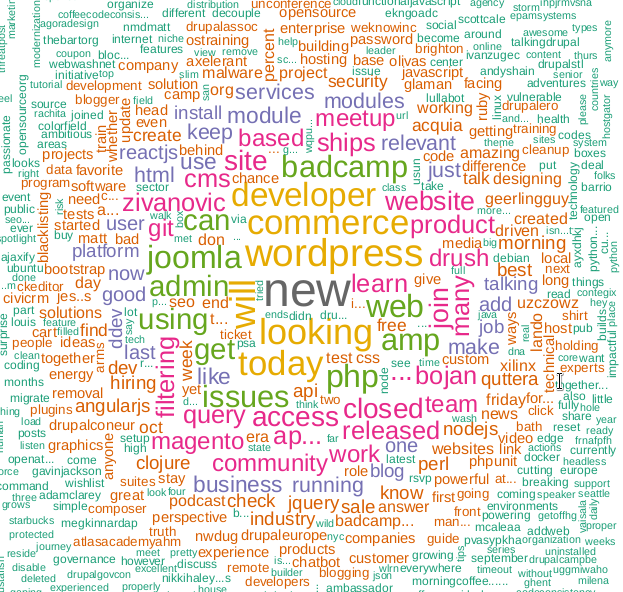
I suggest to guess what technology is framed by this cloud of words?
Using the Twitter API you can extract and analyze a wide variety of information. An article on how to do this using the R programming language.
Writing the code takes not so much time, difficulties may arise due to changes and toughening of the Twitter API, the company seems to be seriously concerned about security issues after dragging out the US Congress following the investigation into the influence of “Russian hackers” on the US elections in 2016.
Accessing API
Why would someone need to commercially extract data from Twitter? Well, for example, it helps to make more accurate predictions about the outcome of sporting events. But I'm sure there are other user scripts.
For a start, it is clear that you need to have a Twitter account with the phone number. It is necessary to create an application, this step gives access to the API.
Go to the developer page and click on the button Create an app . The following is a page where you need to fill out information about the application. At the moment the page consists of the following fields.
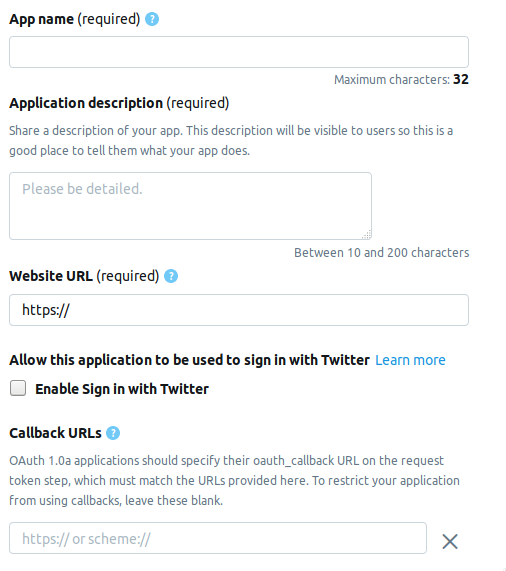
- AppName - the name of the application (required).
- Application description - description of the application (required).
- Website URL - application site page (required), you can enter anything that looks like a URL.
- Enable Sign in with Twitter (check box) - Login from the application page to Twitter, you can skip.
- Callback URLs - Callback application for authentication (required) and necessary , you can leave
http://127.0.0.1:1410.
The following are optional fields: the address of the terms of service page, the name of the organization, and so on.
When creating a developer account, select one of three options.
- Standard - Basic option, you can search for entries to a depth of ≤ 7 days, free.
- Premium - A more advanced option, you can search for records to a depth of ≤ 30 days and since 2006. Free, but they do not give immediately after consideration of the application.
- Enterprise - Business class, paid and reliable rate.
I chose Premium , I had to wait for approval for about a week. I can not say to everyone, whether they are giving it in a row, but it is worth trying in any case, and Standard will not go anywhere.
Connect to Twitter
After you have created an application in the Keys and tokens tab, a set containing the following elements will appear. The names below and the corresponding variables are R.
Consumer API keys
- API key -
api_key - API secret key -
api_secret
Access token & access token secret
- Access token -
access_token - Access token secret -
access_token_secret
Install the necessary packages.
install.packages("rtweet") install.packages("tm") install.packages("wordcloud") This part of the code will look like this.
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) After authentication, R will offer to save OAuth codes to disk for later use.
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No Both options are acceptable, I chose the 1st.
Search and filter results
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600) The include_rts key allows you to control the inclusion of retweets in the search or exclusion from it. At the output we get a table with many fields in which there are details and details of each record. Here are the first 20.
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url" You can make a more complex search string.
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100) Search results can be saved in a text file.
write.table(tweets$text, file="datamine.txt") We merge into the corpus of texts, filter out the official words, punctuation marks, and translate everything into lower case.
There is another search function - searchTwitter , which requires the twitteR library. In some ways, it is more convenient to search_tweets , but in some ways it is inferior to it.
Plus - the presence of a filter in time.
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText()) Minus - the output is not a table, but an object of type status . In order to use it in our example, you need to isolate the text field from the output. This makes sapply in the second line.
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) In the second line, the tm_map function tm_map needed in order to translate any Emodzhi characters into lowercase, otherwise the conversion to lower case using tolower will end with an error.
Build a word cloud
Word clouds first appeared on Flickr photo hosting, as far as I know, and have since gained popularity. For this task we need a wordcloud library.
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2")) The search_string function allows you to set a language as a parameter.
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru") However, since the NLP package for R is poorly Russified, in particular, there is no list of service or stop words, I could not build a word cloud with the search in Russian. I would be glad if you find the best solution in the comments.
Well, actually ...
library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2")) Used materials.
Short links:
- Collecting Twitter Data: Getting Started
- Using R to Mine and Analyze Popular Sentiments
- Using Twitter API to collect data
- Explore Twitter Data Using R
- Introduction to the tm Package, Text Mining in R
Original links:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PS Hint, the cloud keyword on KDPV is not used in the program, it is related to my previous article .
')
Source: https://habr.com/ru/post/426657/
All Articles