How to update the code of smart contracts in Ethereum
How to update the code of smart contracts in Ethereum
The article assumes that the reader has a basic understanding of how Ethereum, EVM (Ethereum Virtual Machine) and smart contracts work at a technical level, as well as an understanding of the basics of the programming language of smart contracts - Solidity.
The material was worked on by the team of the AXIOMA GROUP company, led by Dmitry Abrosimov.
In applications where transparency of operations and user confidence are prioritized, blockchains and smart contracts are often used. The advantage of this architectural solution is that the operations on the blockchain are irreversible and are visible to everyone, that is, everyone can easily check whether the application works honestly.
Smart contracts are special programs that execute code programmed before it is published on the blockchain. Change it after the publication is no longer possible. This is an undoubted advantage for many applications, but it is rather difficult to maintain and maintain the smart contract code. Imagine that after prolonged work a logical error was discovered, allowing fraudsters to divert the broadcast from the smart contract. In such a situation, all that can be done is to observe how the air is transferred to someone else’s wallet. As an example, let us recall an error in one of Parity’s wallet libraries, which led to the freezing of air worth $ 160 million.
Therefore, the ability to update the smart contract code is needed to correct errors. In addition, it makes the development of the application as it grows more convenient. In this article, we will group and classify the well-known methods of updating the code of smart contracts in Ethereum and describe the advantages and disadvantages of various methods.
Basic ways to update code
The article uses code samples from the public open-source repository ZeppelinOS . We have no goal to reinvent the wheel, so we use ready-made and tested solutions. The names of smart contracts may vary.
The most difficult in all ways of updating the code is to save permanent data in the storage of a smart contract. There are different ways to update the code, while allowing to save data, all of them can be divided into two groups:
Breakdown of code that implements logic and data storage for various smart contracts.
Proxy code from one smart contract to another using shared data storage.
Consider each of the groups in more detail.
Breakdown of logic and data storage on different smart contracts
The idea is to break the data storage code and the code to implement the logic into different smart contracts.
Abstract scheme of work looks like this:
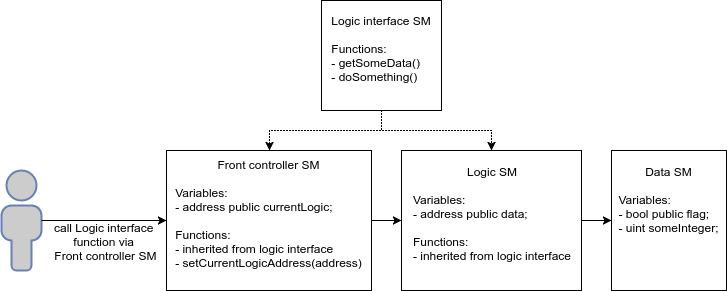
The concept of “smart contract” in the schemes for convenience is reduced to “SM”.
- The front controller in this scheme is necessary for the client to always access a single access point, which automatically sends it to the current version of the smart contract with logic.
- The front controller implements the same methods as the smart contract with logic, through a separate interface common to both smart contracts for integrity.
- The front controller stores the address of the current implementation, which can be changed via the setCurrentLogicAddress () function.
- A smart contract with logic stores the address of a smart data contract (data).
- If the function involves working with data (read or write), then a smart contract is applied to the data (via the data address)
- All business logic, validation and return values are implemented in a smart contract with logic, and the front controller only calls the necessary functions of a smart contract with logic, passing the necessary arguments
The process of updating the code is that instead of the current version of the smart contract with logic, a new version is created and the address of the new version of the code is changed in the front controller.
The problem with this scheme is that a smart data contract has a fixed data scheme. The product in the IT field is changing rapidly and must adapt to the new requirements. This is where the problem arises: the smart data contract is not updated.
This problem can be solved by using the “Perpetual Key-Value Type Storage” data storage template.
Eternal key-value storage (Eternal key-value storage)
The idea is to universalize the data storage scheme in a smart data contract so that it can store any type of data (numbers, strings, addresses, and so on) in unlimited quantities.
This can be achieved by declaring the space of possible values for storage through mappings, as shown in this example .
Thus we get the ability to save almost any type of data.
- Note that the largest size types (32 bytes) are used as mapping values to be as flexible as possible in data storage.
- The key is the type bytes32, which must contain a hash obtained, for example, via keccak256 ('...'). This choice is due to the fact that:
This allows the use of arbitrary key lengths.
This makes it possible to use composite keys, for example keccak256 (“users”, “user_id_123”).
All data types are declared as internal in order to use less gas to access them. To work with data, for each type you need to write the necessary functions. An example of operations for the uint data type can be viewed by reference .
It is also important to restrict write access and data deletion only for a smart contract with logic (using the get * function check does not make sense because it is a safe operation that does not change the internal state of the smart contract). This can be done in the same way as storing the address of the current version of the smart contract code in the front controller. Only in this case, the current address of the code will be stored in EternalStorage.
An example of using the template “perpetual storage” of a smart contract with logic can be found here .
Underwater rocks
What should be considered when updating the smart contract code in this way:
As a “foolproof” in a smart logic contract, you only need to allow access to functions that change state for the front controller.
The main disadvantages of this approach in general:
- Gas consumption increases due to the fact that working with a single smart contract changes to a chain of three. Also, the cost of publishing such smart contracts in the blockchain will be higher.
- In a smart contract with logic, you can change any internal functions or change the operation of any public function, keeping its signature. If, however, you cannot save the signature for some reason, you will have to update the common interface between the front controller and the smart contract with logic and implement the same changes in the front controller. As can be seen from the description of the approach, it is impossible. It turns out that a single entry point also needs to be updated, using the same approach (for which the same problem, however, will remain relevant).
- The problem can be solved through the low-level call function, which accepts functions with an arbitrary number of arguments as input. If we add to this the use of solidity assembly code, then the common interface between the front controller and the code with logic can be removed, and in the front controller you can leave a single function for processing client requests to redirect directly to the smart contract with logic. We will not consider solving the problem in this way, because a similar scheme is used in proxying, except that the delegatecall function is used there, which does not switch the context.
Cons of the template "perpetual storage of the key-value type":
- Abstraction from the application domain. This complicates the work and perception of data, and can also become an obstacle to the implementation of requirements (for example, there are no structures).
- Gas consumption is more likely to be higher than if the data scheme were designed taking into account the application domain. First, whatever key types are used in mappings, they will occupy 32 bytes (because mapping keys are implemented using keccak256 ). Secondly, it is difficult to optimize the mapping because each mapping value occupies a whole slot (32 bytes) in the storage, regardless of the data type used.
Code proxying using shared storage
To understand this way of updating the code, you need to understand how EVM works at the communication level of two (or more) smart contracts and what possibilities Solidity provides for this.
Outside, smart contract functions can be invoked in two ways:
- Call is a local function call that does not send anything to the blockchain network and does not change the state, that is, it performs the function in read mode.
- Transaction is a function call that changes the state of the blockchain and sends a transaction to the network for processing by the miners.
When using any method, the execution context of the function remains inside the smart contract in which the function is called. This means that the data warehouse and the balance with which the function works are stored and changed only within the current smart contract.
If a smart contract causes a function of another smart contract, then the called function works in the context of its smart contract, which ensures safe and independent work with the storage of one and the second smart contract.
Although the call of a function of another smart contract is similar to the type of call “transaction”, it works somewhat differently in terms of the availability of the result of another function, and the official name of such a call of the function is message call .
Consider an example:
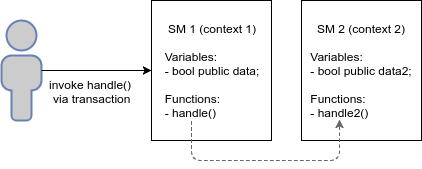
The code of both functions (handle, handle2) can be viewed by reference .
The SM1.handle () function changes the value of the data variable to true, working only in the context of the SM1 smart contract, and the SM2.handle2 () function changes the value of the data2 variable to false, working only in the context of the smart contract SM2. If SM1.handle () tries to change the value of SM2.data2, then EVM will complete this operation with an error.
Low-level Solidity functions for calling another smart contract code
What is shown above uses the function call of another smart contract with the well-known ABI (sm2 variable type - SM2).
There are ways to call the code of another smart contract without an ABI , i.e. in our case, not importing the SM2 smart contract or its interface.
Solidity provides two built-in low-level functions that allow you to call another smart contract code:
- call - a function call of another smart contract with context switching (as in the example above with ABI).
- delegatecall - a function call of another smart contract within the current context.
There is a third low-level function - callcode, but it is not recommended to be used and it will be removed in future versions of Solidity.
Call works according to the scenario already familiar to us, but delegatecall introduces something new - when executing a function from another smart contract, the context does not switch. Here we first come across the concept of “shared storage”. The called function is able to change the value of variables in the calling smart contract — it delegates the execution of the function code from another smart contract, but within its own context.
If you go back to the example code above and replace call with delegatecall, then SM2.handle2 (), setting the data2 variable as the value false, will actually change the value of the variable SM1.data, and SM2.data2 will remain unchanged because the function SM2. handle2 () worked in the context of the SM1 smart contract.
To explain this behavior, you need to refer to the organization of state variables in the persistent store . The Solidity compiler places each state variable of a fixed value in a separate slot of 32 bytes (EVM uses a 32-byte machine word) in the persistent storage, starting from the zero position in the variable declaration order. Position is calculated as follows:
keccak256(variablePosition) // variablePosition 0 The state variables of the dynamic quantity are placed somewhat differently. For example, the position of the mapping elements is calculated as follows:
keccak256(elementKey . mappingPosition) If the total value of the values of several state variables is less than 32 bytes, then the compiler tries to pack them into one storage slot. When describing the data scheme, you need to keep this in mind, but later we will omit this point in order not to complicate the examples.
If we return to the code of two contracts SM1 and SM2, then the storage slots can be expressed as a table:

As the table shows, SM2.data2 and SM1.data occupy the same slot in the storage, so when using delegatecall to execute the function SM2.handle2, which changes the value of the variable data2, the value of the data variable of the smart contract SM1 changes inside the EVM.
The call and delegatecall functions are useful if you need to call a function of another smart contract whose ABI is not known and only its address is present.
Disadvantages of these functions:
- They do not return the result of the execution of the called function, but only the “success” or “failure” of the function (true / false).
- They do not cause exceptions in case of errors on the side of the called function, therefore, as a consequence of the first drawback, the function call must be framed in the require () statement:
require (sm2.call ("handle2"));
Solidity provides the ability to return the result of a function execution via call / delegatecall using the Solidity Assembly, a low-level programming language.
Solidity assembly
Solidity assembly is a low-level programming language that can be used without Solidity itself. We will look at the inline assembly - this is the assembly code, which is embedded directly into the code of the smart contracts Solidity.
Solidity assembly must be used with caution and knowledge of the matter, because using it, communication with EVM occurs at a low level, which can cause unsafe code to be written.
Consider an example of calling the SM2.handle2 function from SM1 using delegatecall at the assembly level. Rewrite code SM1 and SM2 as follows and understand it:
- Implemented the so-called fallback function (without a name and arguments) in SM1, which is triggered when a function call of a smart contract occurs that is not present in the smart contract.
- In order for the smart contract to be able to receive air, the fallback function is indicated by the keyword payable.
- Inside the fallback function, an inline assembly code is declared which, using assembly expressions, calls the function of another smart contract via delegatecall.
- The SM2 code is rewritten so that the state variables are declared in the same order and with the same types as in the SM1 smart contract. For data consistency, we write our own SM2 address in sm2.
Let us consider in more detail the fallback code of the function in order.
- We declare a local variable addr, which takes the value _sm2, outside the assembly code block, because inside the assembly block, the reference to external variables (state variables) does not happen as usual :
address addr = _sm2;
- We are starting to embed the assembly code in the function code of a smart contract:
assembly {
- Create a pointer to the address 0x40 (in the range of 0x40 - 0x5f there is a “free memory” area) using the mload operation:
let ptr: = mload (0x40)
- Copy the entire calldata (the data that was passed when the function was called) to the beginning of the pointer that we created earlier.
calldatacopy (ptr, 0, calldatasize)
Below, the function of another smart contract is called using delegatecall, the result of which (true / false) is stored in the variable success. Call arguments mean the following:
gas - the remainder of the gas available for work
addr - the address of another smart contract
ptr - we specify the position of the beginning of the calldata memory area, which we pass to the called function
calldatasize - we specify the position of the end of the calldata memory area, which we pass to the called function
the last two arguments (0, 0) - indicate the position of the beginning and end of the memory area of the returned data of the called function. At the time of the function call, the size of the returned data is unknown, therefore both arguments are indicated by zeros, and below is the actual calculation of the size of the returned data.
let success: = delegatecall (gas, addr, ptr, calldatasize, 0, 0)
- Write the size of the data that the called function (returndata) returned to the size variable:
let size: = returndatasize
- Copy all the data that the called function (returndata) returned to the beginning of the pointer that we created earlier:
returndatacopy (ptr, 0, size)
- We check the success of the function call:
If success = 0, then cancel all state changes and return returndata (32 bytes long).
In the opposite case (success = 1), simply return returndata (32 bytes long).
switch success case 0 { revert(ptr, 32) } default { return(ptr, 32) } At this fallback function completes its work. Thus, when calling the function SM1.handle () (which is actually not in SM1), the function SM2.handle () is called, which will change the value of the state variable SM1.data.
The approach described above, using the inline assembly and delegatecall, is the basis for the way to update the smart contract code - “code proxying using shared storage”. All the options that will be described below differ only in terms of organizing the data scheme.
Consider the well-known code proxying options: inherited storage (inherited storage), eternal storage (eternal storage), and unstructured storage (unstructured storage).
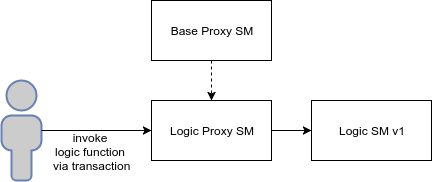
Option 1: Inherited Storage
In fact, everything described above uses storage of an inherited type. We will bring the code described above into a more general form that can be reused in the following sections.
Schematically, proxying with the inherited storage looks like this:
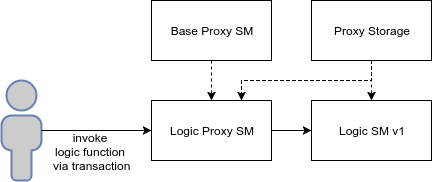
- Proxy Storage is a smart contract that stores the necessary variables for a proxying smart contract to work correctly (it stores the address of the current version of the smart contract with logic).
- Base Proxy SM is a basic smart contract containing code for proxying, which can be inherited by other smart contracts (in our case, Logic Proxy SM inherits Base Proxy SM).
- Logic Proxy SM is the entry point for function calls that delegates their execution to a specific version of a smart contract with logic (in our case, Logic SM v1). Logic Proxy SM inherits Proxy Storage to store the address of the current version of the smart logic contract.
- Logic SM v1 is an implementation of a specific version of a smart contract with logic that inherits Proxy Storage in order to reconcile common state variables with a proxying smart contract. A smart contract with logic may represent new state variables.
Updating a smart contract with logic happens like this:
- A new smart contract with logic is created - Logic SM v2 (v3, v4, v5, ...).
- Important: since proxying is based on the use of shared storage, all new versions of smart contracts with logic must be inherited from the previous version in order for the order and type of state variables to be preserved.
- Logic Proxy SM updates the address of the new version of the code.
Thus, in a smart contract with logic, you can add new functions, as well as new state variables.
The BaseProxy code contains a fallback function for proxying and an implementation interface function that gives the address of the current version of the smart contract with logic.
The ProxyStorage code contains state variables necessary for the operation of code proxying (in our example, the presence of the registry variable can be excluded), and also implements the implementation function.
LogicProxy only inherits BaseProxy, and also contains a function for updating the address of the current version of the smart contract with logic.
The smart contract with logic itself (Logic SM v1) implements the application logic and contains its own state variables:
contract LogicV1 is ProxyStorage {</p> <source>bool public data1; address public data2; // other state variables function handleSomething() { // ... } }
A new version of the smart contract with logic is created based on the previous version:
contract LogicV2 is LogicV1 {</p> <p>bool public data3; // ... other code</p> <p>} The main disadvantages of this option is that for new versions of a smart contract with logic, you must pull the code of all previous versions and you cannot exclude any state variable from the previous version.
Option 2: Perpetual Storage (eternal storage)
The essence of code proxying using perpetual storage is to get rid of the need to inherit the storage variable scheme from previous versions of a smart contract with logic, and in principle makes it possible not to inherit previous versions.
The idea is to connect the same storage option, which is described in the “method of breaking logic and storing data into different smart contracts” using perpetual key-value storage.
Schematically, the method looks like this:
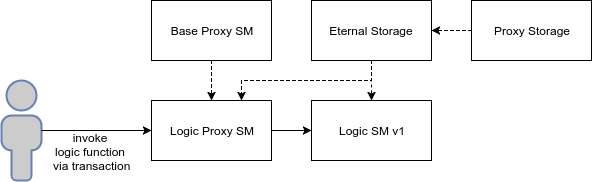
Differences from inherited storage:
- A new smart contract is being introduced - EternalStorage, mentioned in the “method of breaking down logic and storing data into different smart contracts”. Since the proxy method uses shared storage, in EternalStorage there is no need to implement data manipulation functions (setUint, getUint, deleteUint, ...) - all mappings will be available directly in a smart contract with logic.
- EternalStorage inherits ProxyStorage so that the data required for the proxying functionality is consistent.
- LogicProxy and LogicV1 inherit from both EternalStorage - thus, the data scheme is consistent between the smart contracts.
The process of updating a smart contract with logic:
- A new smart contract with logic is created - Logic SM v2 (v3, v4, v5, ...).
- Important: new versions of smart contracts with logic must inherit EternalStorage and not introduce new state variables.
- Logic Proxy SM updates the address of the new version of the code.
Thus, the new versions of smart contracts with logic can make any changes with functions (up to the removal of functions that were present in the old versions) and are not required to pull the old versions.
The main disadvantages of this option are that you have to work with too abstract data and there are problems with the optimization of storage and an increase in gas consumption.
Option 3: Unstructured storage (unstructured storage)
This option is similar to inherited storage (inherited storage), but smart contracts with logic should not inherit ProxyStorage, which contained the necessary state variables for proxying. And ProxyStorage itself is not in this version as a separate smart contract. State variables with the address of the current version of the smart contract with logic are transferred directly to LogicProxy.
Schematically it looks like this:
- LogicV1 contains nothing more related to state variables from ProxyStorage.
- LogicProxy stores directly in its own smart contract the address of the current version of LogicV1.
- BaseProxy still provides the standard proxy function.
- The address of the current version of the smart contract with logic now handles differently. LogicProxy needs to be rewritten as shown in this example .
As you can see, the state variable for storing the address of the current version of a smart contract with logic does not exist at all. Instead, the following is done:
- A private implementationPosition constant is declared, which takes as its value the result of the keccak256 hash function, which hashes an arbitrary unique string (unique within your smart contracts).
- The current version of a smart contract is updated with logic using the inline assembly code: the setImplementation function sets the smart contract address to the position specified in the implementationPosition constant.
- Getting the current version of a smart contract with logic is similarly done using the inline assembly: the implementation function loads data stored in the implementationPosition from the storage (the data obtained will be the address of the current code version).
At first glance, this scheme looks confusing, but if you remember how Solidity distributes variables in the repository, then everything becomes clear. For the distribution of variables, the same hash function is used - keccak256, which accepts the variable position number (starting with 0) as input. The implementationPosition constant explicitly states the address of the variable value to store the address of the current version of the smart contract with logic.
According to the documentation , the constants are not distributed in the repository, so the only risk of this approach is that there is a small probability of collision with those variables that Solidity automatically distributes. In order to avoid this, you need to specify a value unique within your smart contracts as the value of keccak256 in the implementationPosition.
Updating a smart contract with logic is the same as in the case of updating using inherited storage.
Thus, in a smart contract with logic, you can add new functions, as well as new state variables, and there is no need to include in the code the variables necessary for the proxying operation.
Initialization of smart contracts with logic
Versions of smart contracts with logic are published in two stages:
- the publication of the smart contract with logic,
- address update in a proxy smart contract.
There is one problem with smart contracts with logic, which are updated using the proxying method. At the second stage, the proxying smart contract does not see what is happening in the smart contract designer with the logic in the first step. And if the initial values of state variables are set in the constructor, then when the smart contract with logic through the proxying smart contract is accessed, the values of these same variables will have different values, because the initialization of the variables occurred in the context of the smart contract with logic.
To avoid this problem, in smart contracts with logic, you need to take the initialization of state variables into a separate function (for example, initialize), and add the upgradeToAndCall function to the LogicProxy code, as was done in this example .
The upgradeToAndCall function does the same thing as updateCurrentVersionAddress, and in addition to this, it makes a low-level call to a new version of the smart contract with logic, passing all the necessary parameters for initialization. The call function can receive the signature of the called function with parameter passing . Accordingly, if a new version of a smart contract with logic requires initialization of any state variables, instead of calling updateCurrentVersionAddress, you need to call upgradeToAndCall, passing the signature to the initialize function and arguments for it.
Underwater rocks
Code proxying is undoubtedly a more flexible way than splitting logic and storing data into different smart contracts, but you should treat it with care. What you should pay attention to:
- The proxying method uses low-level constructions using inline assembly, which is the closest way to access EVM, so you need to understand well how the Solidity Assembly works.
- It is necessary to strictly follow the data scheme between all associated smart contracts, so as not to disturb the organization of variables in the repository.
- You need to pay great attention to the security of your code using assembly code or other low-level constructs (call, delegatecall). As an example, you can pay attention to the case of detection of code vulnerabilities in The DAO , which also has the use of low-level functions, and which allowed to “steal” the broadcast worth $ 150 million.
The way to create short-term autonomous smart contracts
Sometimes there is a need for a “factory” creation of separate independent smart contracts of a general type that live for a short time. For example, in a project that is based on any transactions, each transaction may be represented as a separate smart contract, with a common code, but belonging to different users.
Let us tell you how we implemented this work in one of the projects.
The project works in the field of betting and in the heart of the system lies the essence - “event”, which is a separate smart contract that allows you to bet on this event. For example, the events of “World Cup 2018” and “Presidential Election 2024” are each expressed as a separate smart contract in the blockchain. There can be an infinite number of events, and the new smart contract will be posted on the blockchain as many times.
An event smart contract contains a fairly large amount of code (event outcomes, rates, determining the correct outcome of an event, winning, and so on), which also consumes a lot of gas during the publication of a smart contract.
To significantly save on gas consumption when publishing a smart contract event, we applied the following approach based on the same mechanism as code proxying.
Some requirements for smart event contracts are:
- Must be able to update business logic.
- At the same time, when updating the code, the previously created smart contracts should not be affected in any way.
Schematically, creating a new event looks like this:

- BaseEvent - is a “prototype” of the event, which contains all the necessary code to implement the logic of the most events (Event). BaseEvent is published once, until you need to update it - in this case, its new version is published.
- An event is directly a smart contract of a specific event - it is created by an EventFactory.
- An EventFactory is a factory that a user accesses to create a new event (Event). The factory stores the address of the current version of BaseEvent and allows you to update it to new versions.
The solution to the requirements is that:
The smart contract of an event contains nothing but the delegation of a call to a function to an EventBase smart contract (that is, it runs in its own context with a shared storage).
Factory at event creation:
- Creates a new smart contract Event, specifying in its constructor the prototype address - EventBase (so that Event delegates the execution to EventBase).
- “Wraps” a newly created Event in EventBase to initialize a new event with multiple parameters (in our case, through an array of bytes with a single argument) to the EventBase.init function.
The smart contract code Event contains one state variable — the address of the event prototype, EventBase. When creating a new event, its address must be passed to the constructor. This is how the second requirement is implemented - the previously created event smart contracts are not affected in any way when the EventBase prototype is updated.
The factory function for creating an event looks like this . The factory also stores the address of the event prototype EventBase, and allows it to be updated , implementing the first requirement — the ability to update.
The creation itself is covered in the line:
EventBase _lastEvent = EventBase(address(new Event(address(eventBase))));
, EventBase :
EventBase public base
EventBase , - .
, , , -.
- — , , , .
, , :
- : - , - ( ). - ( - “ ” , ).
- (emit event), , .
, .
- . , — - , -.
, : . - . - ( - - “ ”). .
, : , - . , ERC223 , , .
-
, , , -:

AXIOMA GROUP , .
, !
https://solidity.readthedocs.io
https://github.com/comaeio/porosity/wiki/Ethereum-Internals
https://blog.zeppelinos.org/proxy-patterns/
https://blog.zeppelinos.org/smart-contract-upgradeability-using-eternal-storage/
https://blog.zeppelinos.org/upgradeability-using-unstructured-storage/
https://medium.com/@novablitz/storing-structs-is-costing-you-gas-774da988895e
https://blog.gnosis.pm/solidity-delegateproxy-contracts-e09957d0f201
https://github.com/zeppelinos/labs
')
Source: https://habr.com/ru/post/426631/
All Articles