CICD: Seamless Deploy on Distributed Cluster Systems without Downtime
I am posting the second report from our first meeting , which was held in September. Last time, you could read (and see) about using Consul to scale stateful services from Ivan Bubnov from BIT.GAMES, and today we'll talk about CICD. More precisely, our system administrator Egor Panov, who is responsible for the availability of infrastructure and services in Pixonic, will tell about it. Under the cut - decoding performance.
To begin with, the game industry is more risky - you never know what exactly will sink into the heart of the player. And so we create many prototypes. Of course, we create prototypes on a knee of sticks, strings and other improvised materials.
It would seem that with such an approach it is impossible to support anything at all later. But even at this stage we hold. Hold on three pillars:
')
Accordingly, if we do not build our processes, for example, deploy or CI (continuous integration) - sooner or later we will come to the conclusion that the testing time will increase and increase all the time. And we will either slowly do everything and lose the market, or simply explode at every delay.
But the CICD process is not so easy to build. Some will say, well, yes, I will put Jenkins, I will quickly call up something, so I have a ready-made CICD. No, it is not only a tool, it is also a practice. Let's start in order.

The first. In many articles they write that everything needs to be kept in one repository: the code, and tests, and warmup, and even the database schema, and IDE settings that are common to all. We went our way.
We have identified different repositories: deploy in our one repository, tests - in another. It works faster. Maybe you will not fit, but for us it is much more convenient. Because there is one important point in this paragraph - you need to build a simple and transparent gitflow. Of course, you can download it somewhere somewhere, but in any case, you need to customize it, improve it. For us, for example, warmth lives with its own githflo, which is more like GitHub-flow, and server-side development lives along its own githflow.
The next item. You need to configure a fully automatic build. It is clear that at the first stage, the developer himself personally assembles the project, then he personally deploit it with the help of SCP, he starts it himself, sends it himself to whom he needs. This option did not last long, a bash script appeared. Well, since the development environment is changing all the time, a dedicated dedicated build server has appeared. He lived for a very long time, during which time we managed to increase in servers to 500, configure server configuration on Puppet, save up Legacy on Puppet, refuse Puppet, switch to Ansible, and this build server continued to live.
We decided to change everything after two calls, the third did not wait. The story is clear: the build server is a single point of failure and, of course, when we needed to fix something, the data center fell completely together with our build server. And the second call: we needed to update the Java version - we updated it on the buildserver, put it on the stage, everything is cool, everything is fine and right there needed some small bugfix to run on the prod. Of course, we forgot to roll back and everything just fell apart.
After that, we rewrote everything in such a way that the entire build could happen on absolutely any TeamCity agent and rewrote it to Ansible, because configuring to Ansible, why not use the same tool for deployment.
The following rule: the more often you commit, the better. And why? Because there is a fourth: every commit is going to. And in fact, even more than every commit. I have already said that we have TeamCity, and it allows you to start a commit from your favorite IDE (you guess what I mean). Actually, fast feedback, everything is great.
A broken build is fixed immediately. As soon as you set up automatic deployment, you need to set up automatic notification in Slack. We all know perfectly well that a developer knows how his code works, only at the moment when he writes it. Therefore: a person found out - immediately fixed it.
We test on the environment repeating the prod. Everything is simple, we chose Ansible and AWX. Someone might ask, what about Docker, Kubernetes, OpenShift, where all the problems out of the box have long been solved? I forgot to say, we have both Linux and Windows components. And, for example, the Photon server, which on Windows, we just recently were able to pack more or less normally in a 10 GB docker container. Accordingly, we have an application on Windows, which is poorly packaged in a container; There is an application on Linux (which is in Java) that packs perfectly, but there’s no need to, it works great wherever you run it. This is Java.
Then we chose between Ansible and Chef. They both work fine with Windows, but Ansible was much easier for us. When we installed AWX - in general, all the fire has become. In AWX there are secrets, there are graphics, history. It is possible to show a person who is far from all this, he will immediately see everything and everything will become clear.
And you always need to keep the build fast. I don’t know why, but always, when you launch a new project, then you’ll forget about the build server, the agents, and select a computer that was lying next to you - this is our build server. This error is undesirable to repeat, because everything I’m talking about (fast feedback, advantages) - it will all be not so relevant if the build on your own laptop runs much faster than on any build server farm.

7 points - and we have already built some kind of CI process. Wonderful. The following diagram is not visible, but there is a Graylog on the side. Who reads our articles on Habré, he already saw how we chose Graylog and how we installed it . In any case, it helps to otdebazhit if some problem still happened.
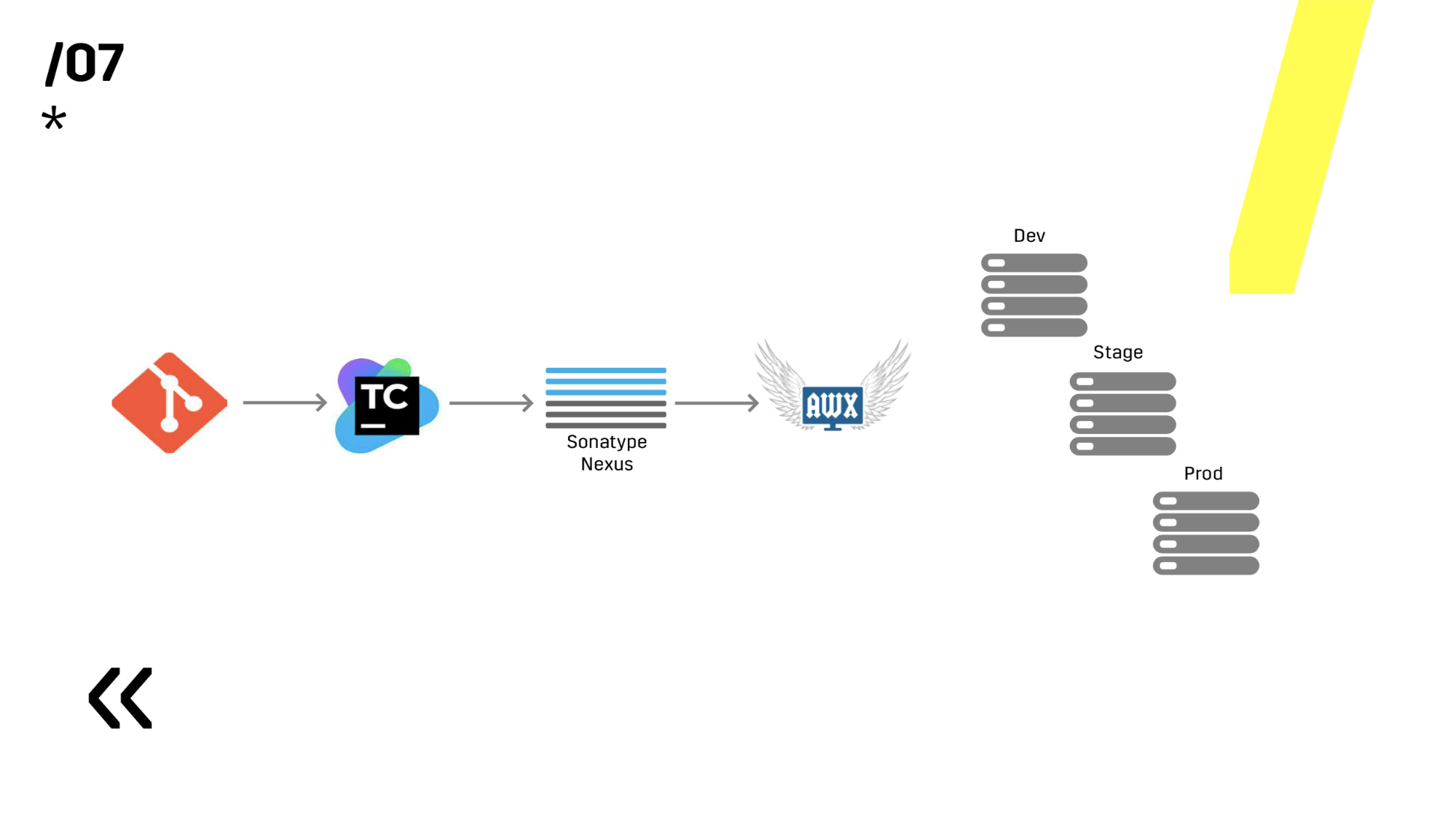
Here on this base it is already possible to go to the deployment.

But I already told you about the deployment in the second paragraph, so I will not dwell on it much. I’ll say one thing: if you're using Ansible, be sure to add this serial on the slide. More than once it happened that you launch something, and then you realize, but I didn’t either start up, or not there, or not, and not there, and then you see that this is just one server. And we can easily lose one server and you just reload it, no one noticed.
Plus they installed the artifacts storage on Nexus - it is a single entry point for absolutely everyone, not just CI.
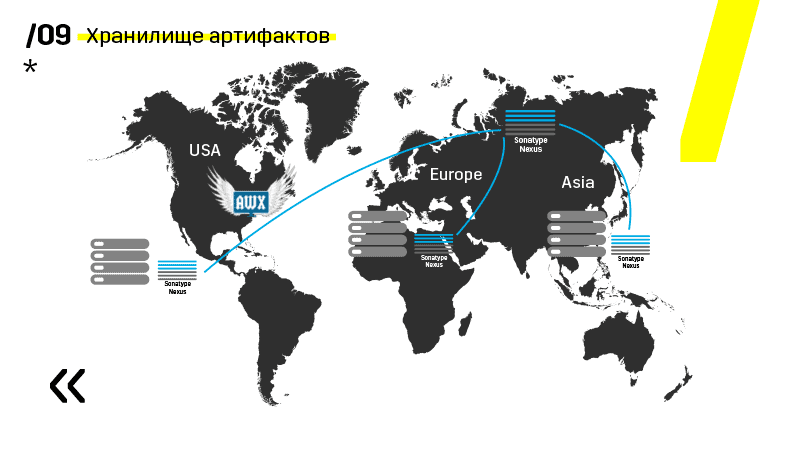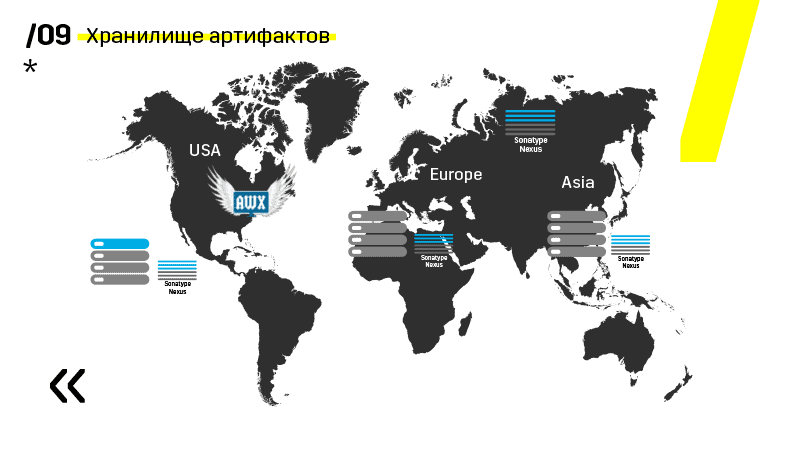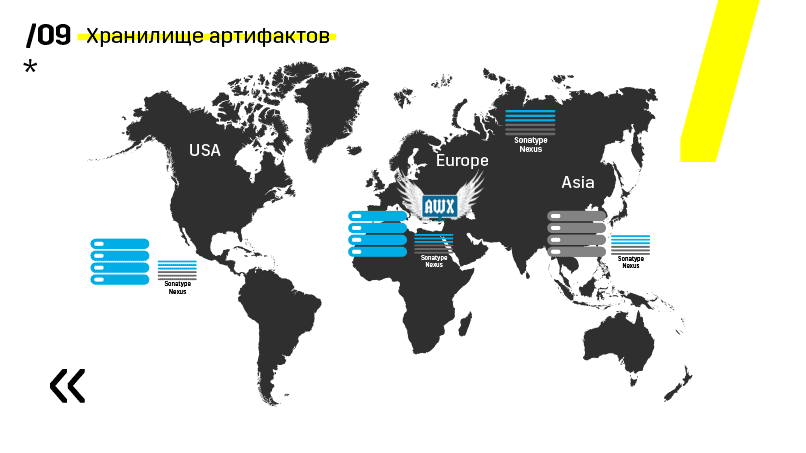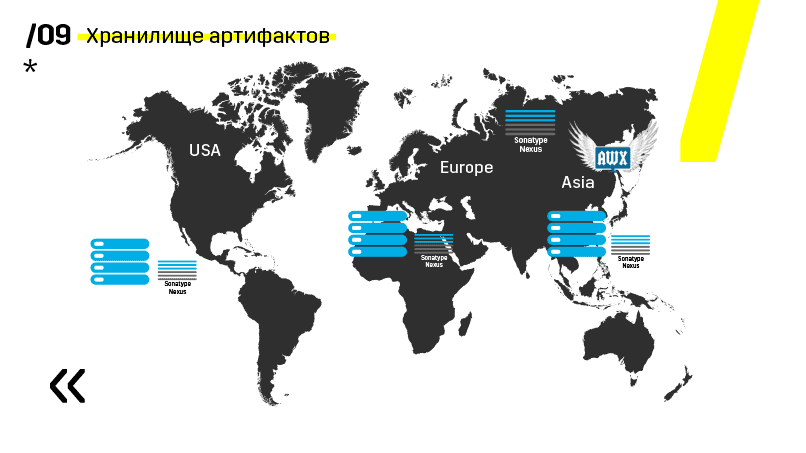
And it helps us to ensure repeatability. Well, since Nexus can work as proxy services in different regions, they speed up deployment, the installation of rpm packages, docker images, whatever.
When you start a new project, it is advisable to choose components that are easily automated. For example, with the Photon server, we failed. In any case, it was the best solution for other parameters. But Cassandra, for example, is very conveniently updated and automated.
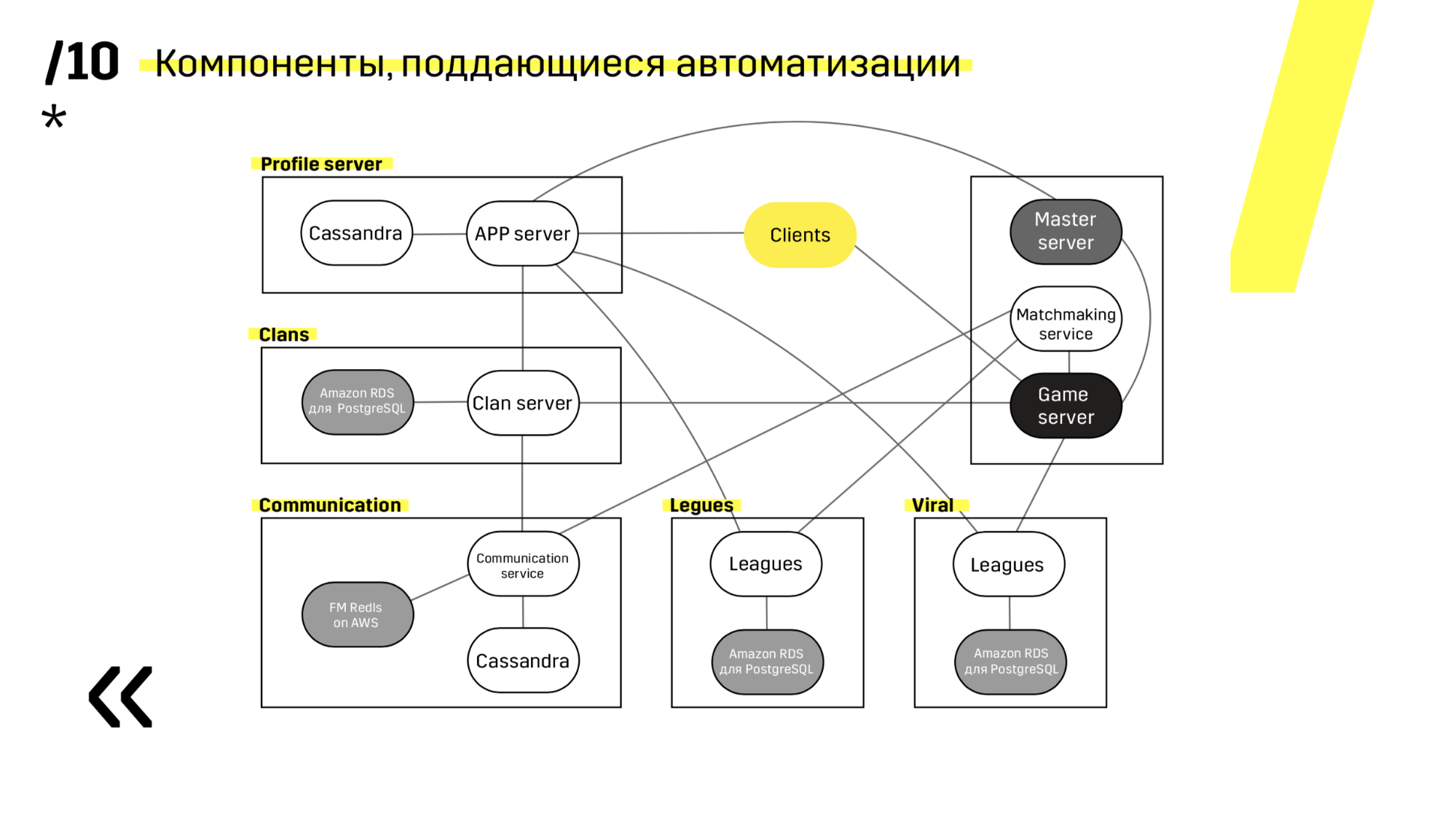
Here is an example of one of our projects. The client comes to the APP server, where he has a profile in the Cassandra database, and then goes to the master server, which, with the help of matchmaking, gives him a game server with some room. All other services are made in the form of “application - DB” and are updated in the same way.
The second point - you need to provide a simple, loosely coupled architecture for deployment. We succeeded.
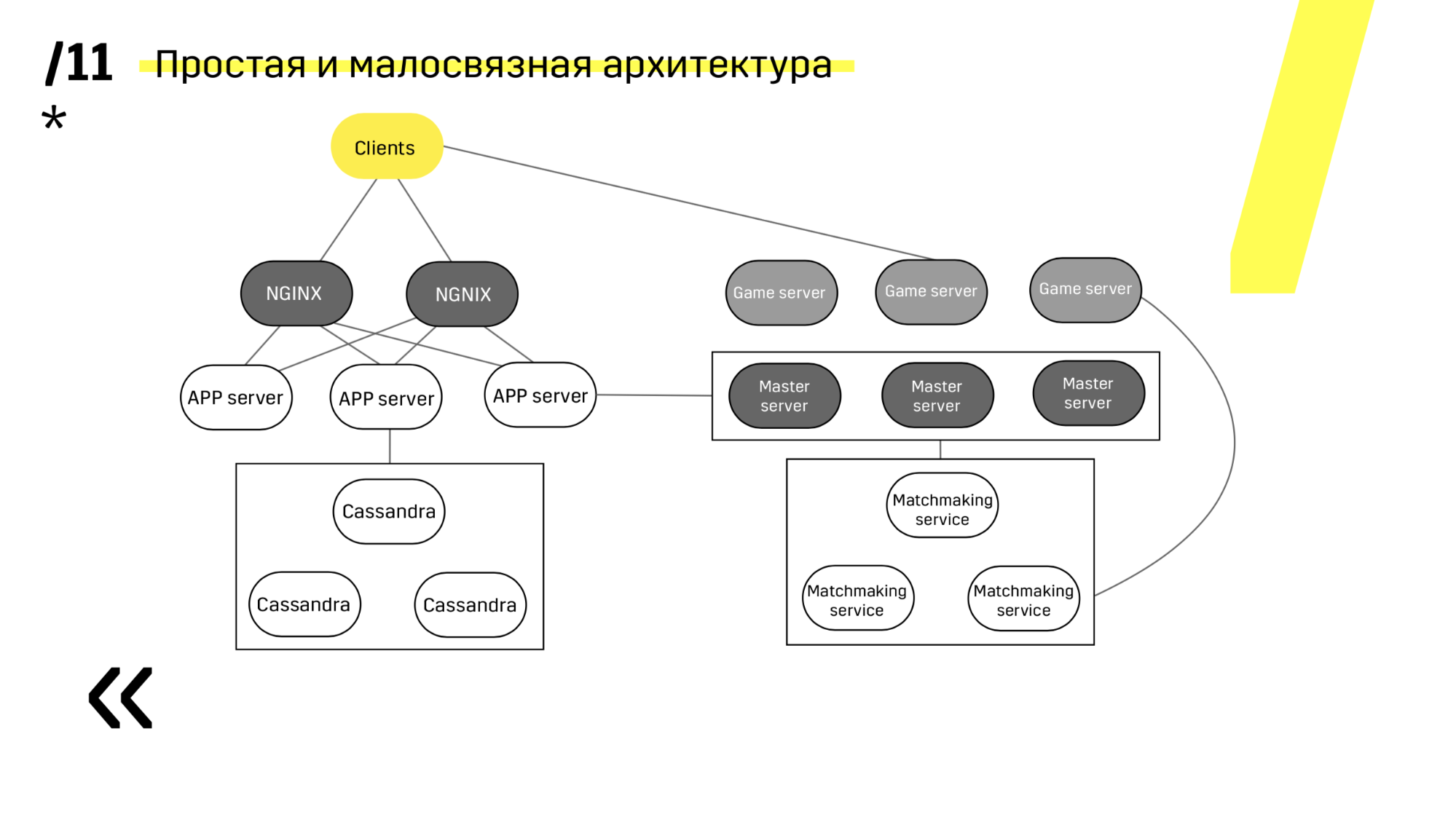
See, update for example the app server. We have dedicated discovery services that reconfigure the balancer, so we just go to the app server, extinguish it, it flies out of balance, we update and that's it. And so with each separately.
Master servers are updated almost identically. The client pings each master server in the region and goes to the one on which ping is better. Accordingly, if we update the master server, then maybe the game will go a little slower, but this is updated easily and simply.
Game servers are updated a little differently, because there is still a game. We go to matchmaking, ask him to throw out a certain server from balancing, we come to the game server, wait until the games become exactly zero, and update. Then we return back to balancing.
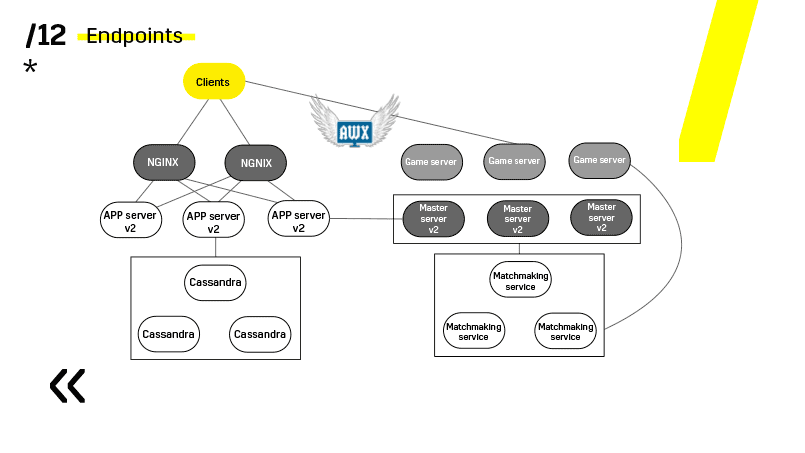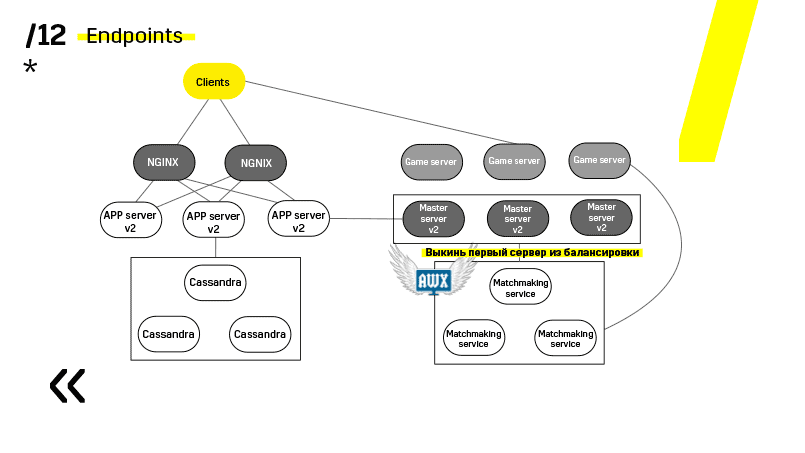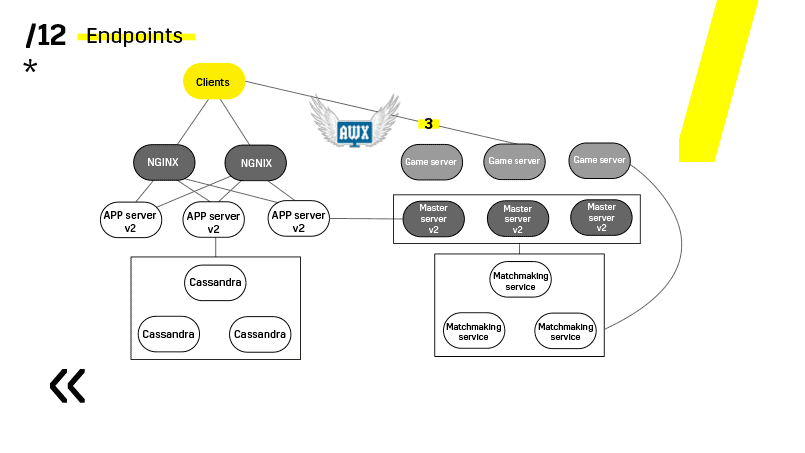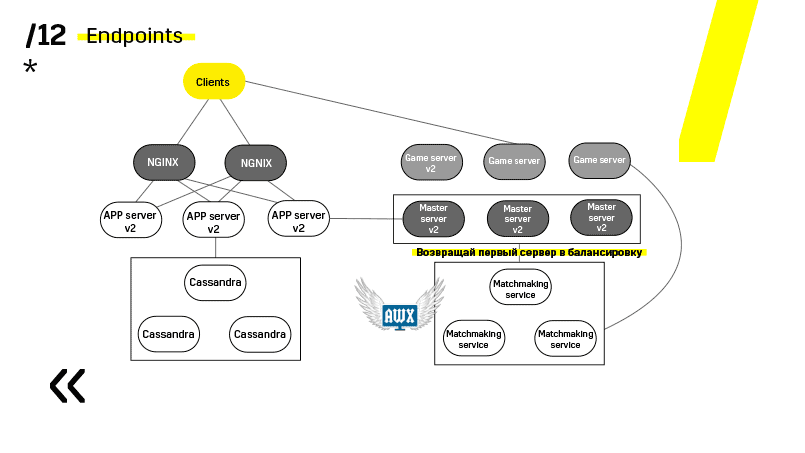
The key point here is the endpoints that each component has, and with which it is easy and simple to communicate. If you need an example, that is Elasticsearch-cluster. Using ordinary http requests in JSON, you can easily communicate with it. And he immediately in the same JSON gives all sorts of different metrics and high-level information about the cluster: green, yellow, red.
Having done these 12 steps, we increased the number of environments, began to test more, deployed us accelerated, people began to receive fast feedback.

What is very important, we got the simplicity and speed of experiments. And this is very important, because when there are a lot of experiments, we can easily weed out the erroneous ideas and stop at the right ones. And not on the basis of some subjective assessments, but on the basis of objective indicators.
In fact, I don’t even watch when we have a deployment there, when a release occurs. There is no feeling of “oh, release!”, Everything is goosebumps. Now it is such a routine operation, I occasionally see in the chatika that something is breaking, well, okay. This is really cool. Your sysadmin will roar with joy when you do that.
But the world does not stand still, he sometimes jumps. We have something to improve. For example, build logs would also like to be thrown into Graylog. This will require further refinement of the logging so that there is not a separate story, but clearly: this is how the build was going, how it was tested, how it was deployed, and so it behaves on the prod. And continuous monitoring - with this history is more complicated.

We use Zabbix, but he is not ready for such approaches at all. Soon the 4th version will be released, we will find out what is there and if everything is bad, then we will come up with another solution. How we can do it - I will tell you on the next mitap.
And what happens when you pick up some garbage in production? For example, you didn’t calculate something for performance and everything is ok on integration, but in production you’ll see that your servers are starting to fall. How do you roll back? Is there some sort of “save me” button?
We tried to automate the back haul. You can then on the reports to tell how it works cool, how wonderful it all is. But first, we design so that the versions are backward compatible and test it. And when we did this fully automatic thing that checks something there and rolls it back, and then started living with it, we realized that we are investing much more into it than if we just use the same pedal to run the old versions. .
Regarding the automatic update of deploy: why do you make changes to the current server, and do not add a new one and just add it to the targetgroup or the balancer?
So faster.
For example, if you need to update the Java version, you change the state instate on Amazon, update the Java version or something else, how do you roll back in this case? Are you making changes on your production server?
Yes, each component works fine with the new version and the old one. Yes, you may have to perezalit server.
There are changes of states when big problems are possible ...
Then we explode.
It just seems to me to add a new server and simply place it at the balancer in the targetgroup — a small task and a fairly good practice.
We are hosted on hardware, not in the clouds. We add a server - it is possible, but a little longer than just click in the cloud. Therefore, we take our current server (we do not have such a load so that we could not bring out some of the machines) - we output some of the machines, update them, send sales traffic there, see how it works, if everything is okay, then we go further other cars.
You say if every commit is going and if everything is bad, the developer rules everything right away. How do you understand that everything is bad? What procedures are done with a commit?
Naturally, the first time is some kind of manual testing, the feedback is slow. Later, by some autotests on Appium, all this is covered, it works and gives some kind of feedback on whether tests have fallen or not.
Those. At first each commit rolls out and testers watch it?
Well, not everyone is a practice. We have done one practice of these 12 points - accelerated. In fact, it is a long and hard work, maybe for a year. But ideally, then you come to this and everything works. Yes, we need some kind of autotest, at least a minimal set, about the fact that it all works for you.
And the question is smaller: there is an App-server in the picture and so on, so what is interesting to me there? You said that you do not have the Docker, what is a server? Naked java or what?
Somewhere is Photon on Windows (game server), the App server is a Java application on Tomkat.
Those. any virtualok, any containers, anything?
Well, Java is a container.
And Ansiblom all this roll?
Yes. Those. at a certain point we simply did not invest in orchestration, because why? If in any case the Windows need to be managed separately in the same way, and here everything is covered with one tool.
And a database as? Dependency on component or service?
In the service itself there is a scheme that will fix it when it appeared and need to be designed so that nothing is deleted, but just something is added and it is backward compatible.
Do you also have an iron base or a base somewhere in the cloud in Amazon?
The largest base is iron, but there are others. There are small, RDS - this is not iron, virtual. Those small services that I showed: chat rooms, leagues, communication with facebook, clans, some of this - RDS.
Master server - what is it like?
This is, in fact, the same game server, only with a sign of a master and he is a balancer. Those. the client pings all the masters, then he gets the one to which the ping is smaller, and already the master server, using matchmaking, collects the rooms on the game servers and sends the player.
I understand correctly that you write (if any features appear) migration to update data for each rollout? You said that you take old artifacts and fill it up - and what happens to this data? Are you writing a migration to roll back the database?
This is a very rare rollback operation. Yes, you write migration handles, and what to do.
How does server update sync with client updates? Those. you need to release a new version of the game - you first upgrade all the servers, then the clients will be updated? Does the server support both the old and the new version?
Yes, we develop feature toggling and feature dimming. Those. This is a special handle, a lever that allows you to turn on some feature later. You can absolutely safely upgrade, see that everything works for you, but do not include this feature. And when you have already dispersed the client, then you can tweak up 10% with fichidimming, see that everything is OK, and then to the full.
You say that you separately store parts of the project in different repositories, i.e. Do you have any process to develop? If you change the project itself, then your tests should fall because you changed the project. So the tests that are separately necessary, as soon as possible to fix.
I told you about the whale "tight interaction with testers." This scheme with different repositories works very well only if there is some very tight communication. This is not a problem for us, everyone communicates with each other easily, there is good communication.
Those. do testers support your repository with tests? And autotests separately lie?
Yes. You made some kind of feature and you can from the repository of testers type those autotests that you need, but do not check everything else.
Such an approach, when everything is rolling fast - you can afford to go to the prod right after each commit. Do you adhere to such tactics or do you put together some releases? Those. once a week, not on Fridays, not on weekends, are there any release tactics you have or is the feature ready, can you release it? Because if you make a small release of small features, then you are less likely that everything will break, and if something breaks, then you know for sure.
To force client users every five minutes or to download a new version every day is not an ice idea. In any case, you will be tied to the client. It's great when you have a web-project in which you can even be updated every day and do not need to do anything. With the client, the story is more complicated, we have some kind of release tactics and we follow it.
You told about the automation of rolling out on grocery servers, and (as I understand it) there is also automation of rolling out for a test - and what about dev-environments? Is there any automation being deployed by developers?
Almost the same. The only thing is that they are no longer iron servers, but in a virtual machine, but the essence is about the same. In this case, on the same Ansible, we wrote (we have Ovirt) the creation of this virtual machine and the knurling on it.
Do you have the whole story stored in one project together with Ansible sales and test configs or does it live and develop separately?
We can say that these are separate projects. Dev (devbox we call it) - this is the story, when everything is in one pack, and on the prode - this is a distributed story.
To begin with, the game industry is more risky - you never know what exactly will sink into the heart of the player. And so we create many prototypes. Of course, we create prototypes on a knee of sticks, strings and other improvised materials.
It would seem that with such an approach it is impossible to support anything at all later. But even at this stage we hold. Hold on three pillars:
')
- excellent expertise testers;
- interaction with them;
- the time we give out for testing.
Accordingly, if we do not build our processes, for example, deploy or CI (continuous integration) - sooner or later we will come to the conclusion that the testing time will increase and increase all the time. And we will either slowly do everything and lose the market, or simply explode at every delay.
But the CICD process is not so easy to build. Some will say, well, yes, I will put Jenkins, I will quickly call up something, so I have a ready-made CICD. No, it is not only a tool, it is also a practice. Let's start in order.
The first. In many articles they write that everything needs to be kept in one repository: the code, and tests, and warmup, and even the database schema, and IDE settings that are common to all. We went our way.
We have identified different repositories: deploy in our one repository, tests - in another. It works faster. Maybe you will not fit, but for us it is much more convenient. Because there is one important point in this paragraph - you need to build a simple and transparent gitflow. Of course, you can download it somewhere somewhere, but in any case, you need to customize it, improve it. For us, for example, warmth lives with its own githflo, which is more like GitHub-flow, and server-side development lives along its own githflow.
The next item. You need to configure a fully automatic build. It is clear that at the first stage, the developer himself personally assembles the project, then he personally deploit it with the help of SCP, he starts it himself, sends it himself to whom he needs. This option did not last long, a bash script appeared. Well, since the development environment is changing all the time, a dedicated dedicated build server has appeared. He lived for a very long time, during which time we managed to increase in servers to 500, configure server configuration on Puppet, save up Legacy on Puppet, refuse Puppet, switch to Ansible, and this build server continued to live.
We decided to change everything after two calls, the third did not wait. The story is clear: the build server is a single point of failure and, of course, when we needed to fix something, the data center fell completely together with our build server. And the second call: we needed to update the Java version - we updated it on the buildserver, put it on the stage, everything is cool, everything is fine and right there needed some small bugfix to run on the prod. Of course, we forgot to roll back and everything just fell apart.
After that, we rewrote everything in such a way that the entire build could happen on absolutely any TeamCity agent and rewrote it to Ansible, because configuring to Ansible, why not use the same tool for deployment.
The following rule: the more often you commit, the better. And why? Because there is a fourth: every commit is going to. And in fact, even more than every commit. I have already said that we have TeamCity, and it allows you to start a commit from your favorite IDE (you guess what I mean). Actually, fast feedback, everything is great.
A broken build is fixed immediately. As soon as you set up automatic deployment, you need to set up automatic notification in Slack. We all know perfectly well that a developer knows how his code works, only at the moment when he writes it. Therefore: a person found out - immediately fixed it.
We test on the environment repeating the prod. Everything is simple, we chose Ansible and AWX. Someone might ask, what about Docker, Kubernetes, OpenShift, where all the problems out of the box have long been solved? I forgot to say, we have both Linux and Windows components. And, for example, the Photon server, which on Windows, we just recently were able to pack more or less normally in a 10 GB docker container. Accordingly, we have an application on Windows, which is poorly packaged in a container; There is an application on Linux (which is in Java) that packs perfectly, but there’s no need to, it works great wherever you run it. This is Java.
Then we chose between Ansible and Chef. They both work fine with Windows, but Ansible was much easier for us. When we installed AWX - in general, all the fire has become. In AWX there are secrets, there are graphics, history. It is possible to show a person who is far from all this, he will immediately see everything and everything will become clear.
And you always need to keep the build fast. I don’t know why, but always, when you launch a new project, then you’ll forget about the build server, the agents, and select a computer that was lying next to you - this is our build server. This error is undesirable to repeat, because everything I’m talking about (fast feedback, advantages) - it will all be not so relevant if the build on your own laptop runs much faster than on any build server farm.
7 points - and we have already built some kind of CI process. Wonderful. The following diagram is not visible, but there is a Graylog on the side. Who reads our articles on Habré, he already saw how we chose Graylog and how we installed it . In any case, it helps to otdebazhit if some problem still happened.
Here on this base it is already possible to go to the deployment.
But I already told you about the deployment in the second paragraph, so I will not dwell on it much. I’ll say one thing: if you're using Ansible, be sure to add this serial on the slide. More than once it happened that you launch something, and then you realize, but I didn’t either start up, or not there, or not, and not there, and then you see that this is just one server. And we can easily lose one server and you just reload it, no one noticed.
Plus they installed the artifacts storage on Nexus - it is a single entry point for absolutely everyone, not just CI.
And it helps us to ensure repeatability. Well, since Nexus can work as proxy services in different regions, they speed up deployment, the installation of rpm packages, docker images, whatever.
When you start a new project, it is advisable to choose components that are easily automated. For example, with the Photon server, we failed. In any case, it was the best solution for other parameters. But Cassandra, for example, is very conveniently updated and automated.
Here is an example of one of our projects. The client comes to the APP server, where he has a profile in the Cassandra database, and then goes to the master server, which, with the help of matchmaking, gives him a game server with some room. All other services are made in the form of “application - DB” and are updated in the same way.
The second point - you need to provide a simple, loosely coupled architecture for deployment. We succeeded.
See, update for example the app server. We have dedicated discovery services that reconfigure the balancer, so we just go to the app server, extinguish it, it flies out of balance, we update and that's it. And so with each separately.
Master servers are updated almost identically. The client pings each master server in the region and goes to the one on which ping is better. Accordingly, if we update the master server, then maybe the game will go a little slower, but this is updated easily and simply.
Game servers are updated a little differently, because there is still a game. We go to matchmaking, ask him to throw out a certain server from balancing, we come to the game server, wait until the games become exactly zero, and update. Then we return back to balancing.
The key point here is the endpoints that each component has, and with which it is easy and simple to communicate. If you need an example, that is Elasticsearch-cluster. Using ordinary http requests in JSON, you can easily communicate with it. And he immediately in the same JSON gives all sorts of different metrics and high-level information about the cluster: green, yellow, red.
Having done these 12 steps, we increased the number of environments, began to test more, deployed us accelerated, people began to receive fast feedback.
What is very important, we got the simplicity and speed of experiments. And this is very important, because when there are a lot of experiments, we can easily weed out the erroneous ideas and stop at the right ones. And not on the basis of some subjective assessments, but on the basis of objective indicators.
In fact, I don’t even watch when we have a deployment there, when a release occurs. There is no feeling of “oh, release!”, Everything is goosebumps. Now it is such a routine operation, I occasionally see in the chatika that something is breaking, well, okay. This is really cool. Your sysadmin will roar with joy when you do that.
But the world does not stand still, he sometimes jumps. We have something to improve. For example, build logs would also like to be thrown into Graylog. This will require further refinement of the logging so that there is not a separate story, but clearly: this is how the build was going, how it was tested, how it was deployed, and so it behaves on the prod. And continuous monitoring - with this history is more complicated.
We use Zabbix, but he is not ready for such approaches at all. Soon the 4th version will be released, we will find out what is there and if everything is bad, then we will come up with another solution. How we can do it - I will tell you on the next mitap.
Questions from the audience
And what happens when you pick up some garbage in production? For example, you didn’t calculate something for performance and everything is ok on integration, but in production you’ll see that your servers are starting to fall. How do you roll back? Is there some sort of “save me” button?
We tried to automate the back haul. You can then on the reports to tell how it works cool, how wonderful it all is. But first, we design so that the versions are backward compatible and test it. And when we did this fully automatic thing that checks something there and rolls it back, and then started living with it, we realized that we are investing much more into it than if we just use the same pedal to run the old versions. .
Regarding the automatic update of deploy: why do you make changes to the current server, and do not add a new one and just add it to the targetgroup or the balancer?
So faster.
For example, if you need to update the Java version, you change the state instate on Amazon, update the Java version or something else, how do you roll back in this case? Are you making changes on your production server?
Yes, each component works fine with the new version and the old one. Yes, you may have to perezalit server.
There are changes of states when big problems are possible ...
Then we explode.
It just seems to me to add a new server and simply place it at the balancer in the targetgroup — a small task and a fairly good practice.
We are hosted on hardware, not in the clouds. We add a server - it is possible, but a little longer than just click in the cloud. Therefore, we take our current server (we do not have such a load so that we could not bring out some of the machines) - we output some of the machines, update them, send sales traffic there, see how it works, if everything is okay, then we go further other cars.
You say if every commit is going and if everything is bad, the developer rules everything right away. How do you understand that everything is bad? What procedures are done with a commit?
Naturally, the first time is some kind of manual testing, the feedback is slow. Later, by some autotests on Appium, all this is covered, it works and gives some kind of feedback on whether tests have fallen or not.
Those. At first each commit rolls out and testers watch it?
Well, not everyone is a practice. We have done one practice of these 12 points - accelerated. In fact, it is a long and hard work, maybe for a year. But ideally, then you come to this and everything works. Yes, we need some kind of autotest, at least a minimal set, about the fact that it all works for you.
And the question is smaller: there is an App-server in the picture and so on, so what is interesting to me there? You said that you do not have the Docker, what is a server? Naked java or what?
Somewhere is Photon on Windows (game server), the App server is a Java application on Tomkat.
Those. any virtualok, any containers, anything?
Well, Java is a container.
And Ansiblom all this roll?
Yes. Those. at a certain point we simply did not invest in orchestration, because why? If in any case the Windows need to be managed separately in the same way, and here everything is covered with one tool.
And a database as? Dependency on component or service?
In the service itself there is a scheme that will fix it when it appeared and need to be designed so that nothing is deleted, but just something is added and it is backward compatible.
Do you also have an iron base or a base somewhere in the cloud in Amazon?
The largest base is iron, but there are others. There are small, RDS - this is not iron, virtual. Those small services that I showed: chat rooms, leagues, communication with facebook, clans, some of this - RDS.
Master server - what is it like?
This is, in fact, the same game server, only with a sign of a master and he is a balancer. Those. the client pings all the masters, then he gets the one to which the ping is smaller, and already the master server, using matchmaking, collects the rooms on the game servers and sends the player.
I understand correctly that you write (if any features appear) migration to update data for each rollout? You said that you take old artifacts and fill it up - and what happens to this data? Are you writing a migration to roll back the database?
This is a very rare rollback operation. Yes, you write migration handles, and what to do.
How does server update sync with client updates? Those. you need to release a new version of the game - you first upgrade all the servers, then the clients will be updated? Does the server support both the old and the new version?
Yes, we develop feature toggling and feature dimming. Those. This is a special handle, a lever that allows you to turn on some feature later. You can absolutely safely upgrade, see that everything works for you, but do not include this feature. And when you have already dispersed the client, then you can tweak up 10% with fichidimming, see that everything is OK, and then to the full.
You say that you separately store parts of the project in different repositories, i.e. Do you have any process to develop? If you change the project itself, then your tests should fall because you changed the project. So the tests that are separately necessary, as soon as possible to fix.
I told you about the whale "tight interaction with testers." This scheme with different repositories works very well only if there is some very tight communication. This is not a problem for us, everyone communicates with each other easily, there is good communication.
Those. do testers support your repository with tests? And autotests separately lie?
Yes. You made some kind of feature and you can from the repository of testers type those autotests that you need, but do not check everything else.
Such an approach, when everything is rolling fast - you can afford to go to the prod right after each commit. Do you adhere to such tactics or do you put together some releases? Those. once a week, not on Fridays, not on weekends, are there any release tactics you have or is the feature ready, can you release it? Because if you make a small release of small features, then you are less likely that everything will break, and if something breaks, then you know for sure.
To force client users every five minutes or to download a new version every day is not an ice idea. In any case, you will be tied to the client. It's great when you have a web-project in which you can even be updated every day and do not need to do anything. With the client, the story is more complicated, we have some kind of release tactics and we follow it.
You told about the automation of rolling out on grocery servers, and (as I understand it) there is also automation of rolling out for a test - and what about dev-environments? Is there any automation being deployed by developers?
Almost the same. The only thing is that they are no longer iron servers, but in a virtual machine, but the essence is about the same. In this case, on the same Ansible, we wrote (we have Ovirt) the creation of this virtual machine and the knurling on it.
Do you have the whole story stored in one project together with Ansible sales and test configs or does it live and develop separately?
We can say that these are separate projects. Dev (devbox we call it) - this is the story, when everything is in one pack, and on the prode - this is a distributed story.
More reports from Pixonic DevGAMM Talks
- Using Consul to scale stateful services (Ivan Bubnov, DevOps at BIT.GAMES);
- Practice using the model of actors in the back-platform platform of the Quake Champions game (Roman Rogozin, backend developer of Saber Interactive);
- The architecture of the meta-server mobile online shooter Tacticool (Pavel Platto, Lead Software Engineer in PanzerDog);
- How ECS, C # Job System and SRP change the approach to architecture (Valentin Simonov, Field Engineer in Unity);
- KISS principle in development (Konstantin Gladyshev, Lead Game Programmer at 1C Game Studios);
- General game logic on the client and server (Anton Grigoriev, Deputy Technical Officer in Pixonic).
- Cucumber in the cloud: using BDD scripts for load testing a product (Anton Kosyakin, Technical Product Manager in ALICE Platform).
Source: https://habr.com/ru/post/425813/
All Articles