7 best practices for the operation of containers according to Google
Note trans. : The author of the original article is Théo Chamley, architect of cloud solutions for Google. In this publication for the Google Cloud blog, he presented a brief extract from a more detailed guide to his company, entitled “ Best Practices for Operating Containers ”. In it, Google experts gathered best practices for the operation of containers in the context of using Google Kubernetes Engine and more, covering a wide range of topics: from security to monitoring and logging. So, what are the most important practices for working with containers in Google’s opinion?

Kubernetes Engine (based on Kubernetes service for running containerized applications on Google Cloud - approx. Transl. ) - one of the best ways to run workloads that need scaling. Kubernetes will provide trouble-free operation for most applications if they are containerized. But if you want the application to be easy to manage, and you want to take full advantage of Kubernetes, you need to follow the best practices. They will simplify the operation of the application, its monitoring and debugging, as well as increase security.
')
In this article we will go through the list of what it is worth knowing and doing for the effective functioning of containers in Kubernetes. Those wishing to delve into the details should read the material Best Practices for Operating Containers , as well as pay attention to our earlier post about the assembly of containers.
If the application is running in the Kubernetes cluster, not much is needed for logs. A centralized logging system is probably already built into the cluster in use. In the case of Kubernetes Engine, Stackdriver Logging is responsible for this. ( Note : when using your own Kubernetes installation, we recommend you take a closer look at our Open Source solution - loghouse .) Make it easy for yourself and use native container journaling mechanisms. Write logs to stdout and stderr - they will be automatically received, saved and indexed.
If you wish, you can also write logs in JSON format . This approach makes it easy to add metadata to them. And along with them in Stackdriver Logging, it will be possible to search logs using this metadata.
For the containers to function correctly in a Kubernetes cluster, they must be stateless and immutable. When these conditions are met, Kubernetes will be able to do its job, creating and destroying the essence of the application, when and where it is needed.
Stateless means that any state (persistent data of any kind) is stored outside the container. For this, depending on the needs, different types of external storage can be used: Cloud Storage , Persistent Disks , Redis , Cloud SQL or other managed databases. ( Note : read more about this also in our article “ Operators for Kubernetes: How to run stateful applications .”)
Immutable means that the container will not be modified during its lifetime: no updates, patches, changes in configuration. If you need to update the application code or apply a patch, create a new image and back it up. It is recommended to take out the container configuration (port for listening, options for the executable environment, etc.) outside - in Secrets and ConfigMaps . They can be updated without having to build a new container image. For simple creation of pipelines with image assembly, you can use Cloud Build . ( Note : For this purpose, we use the open source tool dapp .)
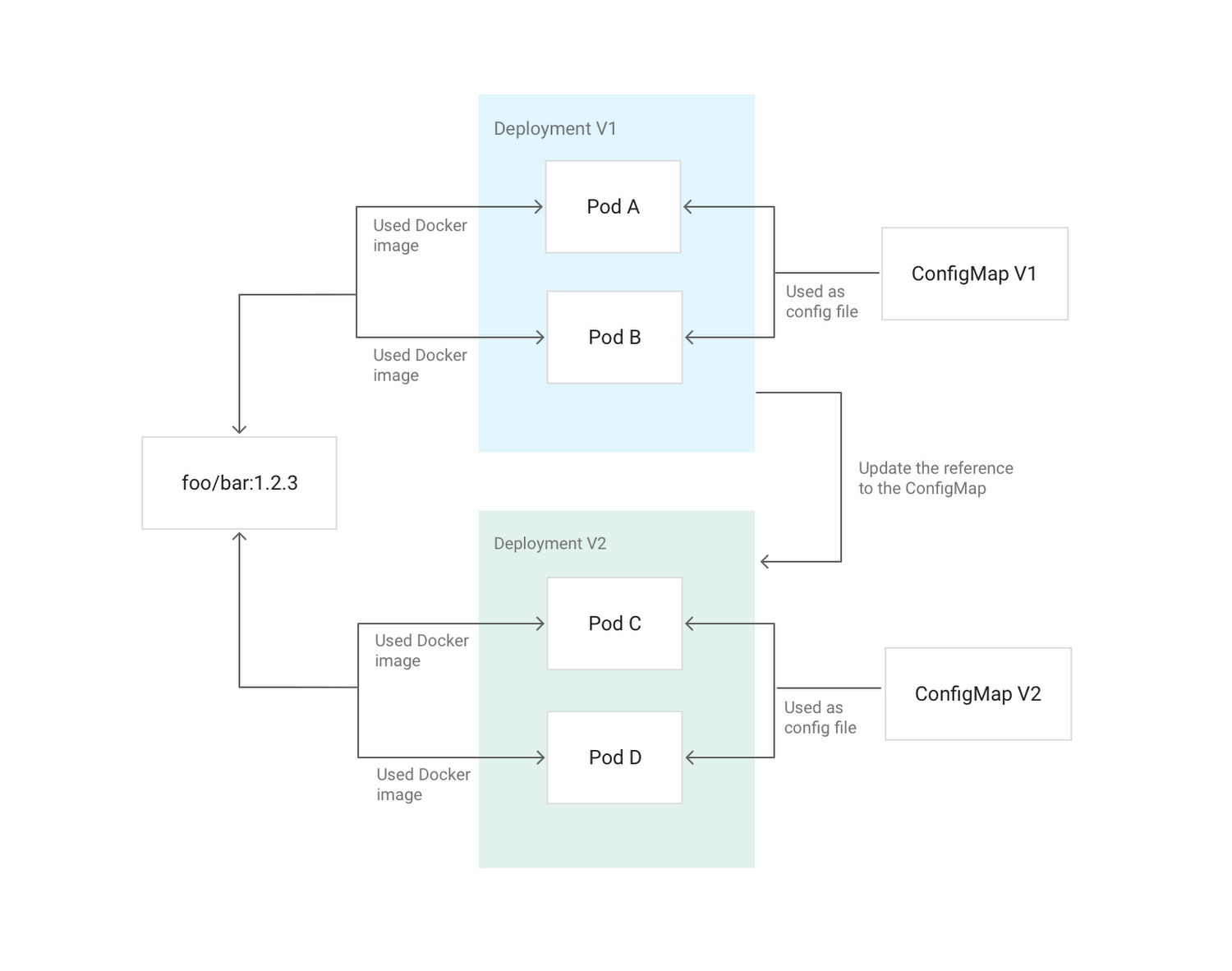
An example of updating the Deployment configuration in Kubernetes using a ConfigMap mounted in the hearth as a config
You do not run applications as root on your servers, right? If the attacker penetrates the application, he will gain root access. The same considerations are valid in order not to run privileged containers. If you need to change the settings on the host, you can provide specific capabilities to the container using the Kubernetes
If you administer a cluster, you can use the Pod Security Policy to limit the use of privileged containers.
Privileged containers have already been mentioned, but it will be even better if, in addition to this, you do not run applications as root under the container. If an attacker finds a remote vulnerability with the ability to execute code in an application with root privileges, after which he can exit the container through an as-yet unknown vulnerability, he will receive root on the host.
The best way to avoid this is first of all not to run anything as root. To do this, you can use the
Like logging, monitoring is an integral part of application management. A popular monitoring solution in the Kubernetes community is Prometheus , a system that automatically detects scams and services that require monitoring. ( Note : See also our detailed report on monitoring with Prometheus and Kubernetes.) Stackdriver is able to monitor Kubernetes clusters and includes its own version of Prometheus for monitoring applications.
Kubernetes Dashboard in Stackdriver
Prometheus expects the application to forward metrics to the HTTP endpoint. Prometheus client libraries are available for this. The same format is used by other tools like OpenCensus and Istio .
Managing an application in production helps its ability to report its state to the entire system. Is the application running? Is it ok? Is it ready to accept traffic? How does it behave? The most common way to solve this problem is to implement health checks . Kubernetes have two types of them: liveness and readiness probes .
For liveness probe (viability testing), the application must have an HTTP endpoint that returns the “200 OK” response if it is functioning and its basic dependencies are satisfied. For readiness probe (check for readiness for service), the application must have another HTTP endpoint returning the answer “200 OK” if the application is in a healthy state, the initialization steps are completed and any correct request does not lead to an error. Kubernetes will only send traffic to the container if the application is ready according to these checks. Two endpoints can be combined if there is no difference between the states of vitality (liveness) and readiness (readiness).
You can read more about this in the corresponding article from Sandeep Dinesh, the Developer Advocate from Google: " Kubernetes best practices: Setting up health checks ."
Most public and private images use a tagging system similar to that described in Best Practices for Building Containers . If an image uses a system close to semantic versioning , it is necessary to take into account the specifics of tagging. For example, the
You can use the
Read also in our blog:
Kubernetes Engine (based on Kubernetes service for running containerized applications on Google Cloud - approx. Transl. ) - one of the best ways to run workloads that need scaling. Kubernetes will provide trouble-free operation for most applications if they are containerized. But if you want the application to be easy to manage, and you want to take full advantage of Kubernetes, you need to follow the best practices. They will simplify the operation of the application, its monitoring and debugging, as well as increase security.
')
In this article we will go through the list of what it is worth knowing and doing for the effective functioning of containers in Kubernetes. Those wishing to delve into the details should read the material Best Practices for Operating Containers , as well as pay attention to our earlier post about the assembly of containers.
1. Use native container mechanisms for logging
If the application is running in the Kubernetes cluster, not much is needed for logs. A centralized logging system is probably already built into the cluster in use. In the case of Kubernetes Engine, Stackdriver Logging is responsible for this. ( Note : when using your own Kubernetes installation, we recommend you take a closer look at our Open Source solution - loghouse .) Make it easy for yourself and use native container journaling mechanisms. Write logs to stdout and stderr - they will be automatically received, saved and indexed.
If you wish, you can also write logs in JSON format . This approach makes it easy to add metadata to them. And along with them in Stackdriver Logging, it will be possible to search logs using this metadata.
2. Ensure that the containers are stateless and immutable
For the containers to function correctly in a Kubernetes cluster, they must be stateless and immutable. When these conditions are met, Kubernetes will be able to do its job, creating and destroying the essence of the application, when and where it is needed.
Stateless means that any state (persistent data of any kind) is stored outside the container. For this, depending on the needs, different types of external storage can be used: Cloud Storage , Persistent Disks , Redis , Cloud SQL or other managed databases. ( Note : read more about this also in our article “ Operators for Kubernetes: How to run stateful applications .”)
Immutable means that the container will not be modified during its lifetime: no updates, patches, changes in configuration. If you need to update the application code or apply a patch, create a new image and back it up. It is recommended to take out the container configuration (port for listening, options for the executable environment, etc.) outside - in Secrets and ConfigMaps . They can be updated without having to build a new container image. For simple creation of pipelines with image assembly, you can use Cloud Build . ( Note : For this purpose, we use the open source tool dapp .)
An example of updating the Deployment configuration in Kubernetes using a ConfigMap mounted in the hearth as a config
3. Avoid privileged containers.
You do not run applications as root on your servers, right? If the attacker penetrates the application, he will gain root access. The same considerations are valid in order not to run privileged containers. If you need to change the settings on the host, you can provide specific capabilities to the container using the Kubernetes
securityContext option. If you want to modify sysctls , Kubernetes has a separate annotation for this. In general, try to make the most of the init and sidecar containers to perform these privileged operations. They do not need accessibility for either internal or external traffic.If you administer a cluster, you can use the Pod Security Policy to limit the use of privileged containers.
4. Avoid running as root.
Privileged containers have already been mentioned, but it will be even better if, in addition to this, you do not run applications as root under the container. If an attacker finds a remote vulnerability with the ability to execute code in an application with root privileges, after which he can exit the container through an as-yet unknown vulnerability, he will receive root on the host.
The best way to avoid this is first of all not to run anything as root. To do this, you can use the
USER directive in Dockerfile or runAsUser in Kubernetes. The cluster administrator can also set up enforceable behavior using the Pod Security Policy .5. Make the application easy to monitor.
Like logging, monitoring is an integral part of application management. A popular monitoring solution in the Kubernetes community is Prometheus , a system that automatically detects scams and services that require monitoring. ( Note : See also our detailed report on monitoring with Prometheus and Kubernetes.) Stackdriver is able to monitor Kubernetes clusters and includes its own version of Prometheus for monitoring applications.
Kubernetes Dashboard in Stackdriver
Prometheus expects the application to forward metrics to the HTTP endpoint. Prometheus client libraries are available for this. The same format is used by other tools like OpenCensus and Istio .
6. Make the application health state available.
Managing an application in production helps its ability to report its state to the entire system. Is the application running? Is it ok? Is it ready to accept traffic? How does it behave? The most common way to solve this problem is to implement health checks . Kubernetes have two types of them: liveness and readiness probes .
For liveness probe (viability testing), the application must have an HTTP endpoint that returns the “200 OK” response if it is functioning and its basic dependencies are satisfied. For readiness probe (check for readiness for service), the application must have another HTTP endpoint returning the answer “200 OK” if the application is in a healthy state, the initialization steps are completed and any correct request does not lead to an error. Kubernetes will only send traffic to the container if the application is ready according to these checks. Two endpoints can be combined if there is no difference between the states of vitality (liveness) and readiness (readiness).
You can read more about this in the corresponding article from Sandeep Dinesh, the Developer Advocate from Google: " Kubernetes best practices: Setting up health checks ."
7. Carefully choose the version of the image.
Most public and private images use a tagging system similar to that described in Best Practices for Building Containers . If an image uses a system close to semantic versioning , it is necessary to take into account the specifics of tagging. For example, the
latest tag can often move from image to image — you cannot rely on it if you need predictable and reproducible builds and installations.You can use the
XYZ tag (they are almost always the same), but in this case, keep track of all patches and updates to the image. If the image used has an XY tag, this is a good version of the golden mean. By selecting it, you automatically get patches and at the same time rely on a stable version of the application.PS from translator
Read also in our blog:
- " New CNCF Container, Cloud Native and Kubernetes Statistics ";
- “ 7 principles for designing container-based applications ”;
- “ 11 ways to (not) become a victim of hacking at Kubernetes ”;
- “ Our experience with Kubernetes in small projects ” (review and video of the report) ;
- “ Monitoring and Kubernetes ” (review and video of the report) ;
- “ We assemble Docker images for CI / CD quickly and conveniently along with dapp ” (review and video of the report) ;
- " Practices of Continuous Delivery with Docker " (review and video of the report) ;
- "The death of microservice madness in 2018 ".
Source: https://habr.com/ru/post/425085/
All Articles