Migrating a non-downgrade database schema for postgresql using the example of django
Introduction
Hi, Habr!
I want to share the experience of writing migrations for postgres and django. This is mainly about postgres, django is a good complement here, since it automatically migrates the data schema for model changes out of the box, that is, has a fairly complete list of work operations for changing the schema. Django can be replaced with any favorite framework / library - approaches are likely to be similar.
I will not describe how I came to this, but now reading the documentation I catch the thought that it was necessary to do this with more care and awareness earlier, therefore I highly recommend it.
Before going further, let me make the following assumptions.
You can divide the logic of working with the database of most applications into 3 parts:
- Migrations - changing the database schema (tables), suppose we always run them in one thread.
- Business logic - direct work with data (in user tables), works with the same data constantly and competitively.
- Data migrations - do not change the data schema, they work essentially as a business logic, by default, when we talk about business logic, we also mean data migration.
Downtime is a state when part of our business logic is not available / is falling / loading for a noticeable time for the user, suppose it is a couple of seconds.
Lack of downtime can be a critical condition for business that must be adhered to by any efforts.
Rolling out process
The main requirements when rolling out:
- we have one working base.
- we have several machines where business logic is spinning.
- Business logic machines are hidden behind the balancer.
- our application works well before, during and after the migration process (the old code works correctly with the old and new base scheme).
- our application works well before, during, and after updating the code on machines (the old and new code works correctly with the current database scheme).
If there are a large number of changes and roll-out ceases to meet these conditions, then it is divided into the necessary number of smaller roll-outs that meet these conditions, otherwise we have downtime.
Direct vykatki order:
- flooded migration;
- removed one machine from the balancer, updated the machine and restarted, returned the machine to the balancer;
- repeated the previous step before updating all the machines.
Reverse rollout order is relevant for deleting tables and columns in a table, when we automatically create migrations using a modified scheme and validate the presence of all migrations to CI:
- removed one machine from the balancer, updated the machine and restarted, returned the machine to the balancer;
- repeated the previous step before updating all the machines;
- flooded migration.
Theory
Postgres is an excellent database, we can write an application that in hundreds and thousands of threads will write and read the same data, and with a high probability to be sure that our data will remain valid and will not be damaged, in general, full ACID. Postgres implements several mechanisms to achieve this, one of which is locking.
In postgres there are several types of locks, more details can be found here , in the framework of the topic, I will only touch on blocking at the table and record level.
Table level locks
At the table level, postgres has several types of locks , the main feature is that they have conflicts, that is, two operations with conflicting locks cannot be performed simultaneously:
ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE | SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE | |
|---|---|---|---|---|---|---|---|---|
ACCESS SHARE | X | |||||||
ROW SHARE | X | X | ||||||
ROW EXCLUSIVE | X | X | X | X | ||||
SHARE UPDATE EXCLUSIVE | X | X | X | X | X | |||
SHARE | X | X | X | X | X | |||
SHARE ROW EXCLUSIVE | X | X | X | X | X | X | ||
EXCLUSIVE | X | X | X | X | X | X | X | |
ACCESS EXCLUSIVE | X | X | X | X | X | X | X | X |
For example, ALTER TABLE tablename ADD COLUMN newcolumn integer and SELECT COUNT(*) FROM tablename must be strictly executed one by one, otherwise we cannot find out which columns to return to COUNT(*) .
The django migrations (full list below) contains the following operations and the corresponding locks:
| blocking | operations |
|---|---|
ACCESS EXCLUSIVE | CREATE SEQUENCE , DROP SEQUENCE , CREATE TABLE , DROP TABLE , ALTER TABLE , DROP INDEX |
SHARE | CREATE INDEX |
SHARE UPDATE EXCLUSIVE | CREATE INDEX CONCURRENTLY , DROP INDEX CONCURRENTLY , ALTER TABLE VALIDATE CONSTRAINT |
Of the notes, not all ALTER TABLE have ACCESS EXCLUSIVE locking, also in django migrations there are no CREATE INDEX CONCURRENTLY and ALTER TABLE VALIDATE CONSTRAINT , but they will be needed for a safer alternative to standard operations a bit later.
If the migrations are performed in one stream sequentially, then everything looks good, since the migration will not conflict with another migration, but our business logic will work just during the migration and conflict.
| blocking | operations | conflicts with locks | conflicts with operations |
|---|---|---|---|
ACCESS SHARE | SELECT | ACCESS EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW SHARE | SELECT FOR UPDATE | ACCESS EXCLUSIVE , EXCLUSIVE | ALTER TABLE , DROP INDEX |
ROW EXCLUSIVE | INSERT , UPDATE , DELETE | ACCESS EXCLUSIVE , EXCLUSIVE , SHARE ROW EXCLUSIVE , SHARE | ALTER TABLE , DROP INDEX , CREATE INDEX |
Here you can summarize two points:
- if there is an alternative with a lighter lock, you can use it like
CREATE INDEXandCREATE INDEX CONCURRENTLY. - most migrations of data schema changes conflict with business logic, and conflict with
ACCESS EXCLUSIVE, that is, we cannot even make aSELECTwhile holding this lock and potentially downtime here, except if this operation does not work out instantly and our downtime is a couple of seconds.
There must be a choice, or we always avoid ACCESS EXCLUSIVE , that is, we create new labels and copy data there — reliably, but for a long time for a large amount of data, or we make ACCESS EXCLUSIVE as fast as possible and make additional warnings against downtime — potentially dangerous, but quickly.
Write level locks
The record level also has its own locks https://www.postgresql.org/docs/current/static/explicit-locking.html#LOCKING-ROWS , they also conflict with each other, but only affect our business logic:
FOR KEY SHARE | FOR SHARE | FOR NO KEY UPDATE | FOR UPDATE | |
|---|---|---|---|---|
FOR KEY SHARE | X | |||
FOR SHARE | X | X | ||
FOR NO KEY UPDATE | X | X | X | |
FOR UPDATE | X | X | X | X |
Here is the main point in data migrations, that is, if we make UPDATE on the entire table data migration, then the rest of the business logic that updates the data will wait for the lock to be released and may exceed our downtime threshold, so it is better to do updates for data migrations. It is also worth noting that when using more complex sql queries for data migrations, splitting into parts can work faster, as it can use a more optimal plan and indexes.
The sequence of operations
Another important knowledge is how operations will be performed, when and how they take and release locks:
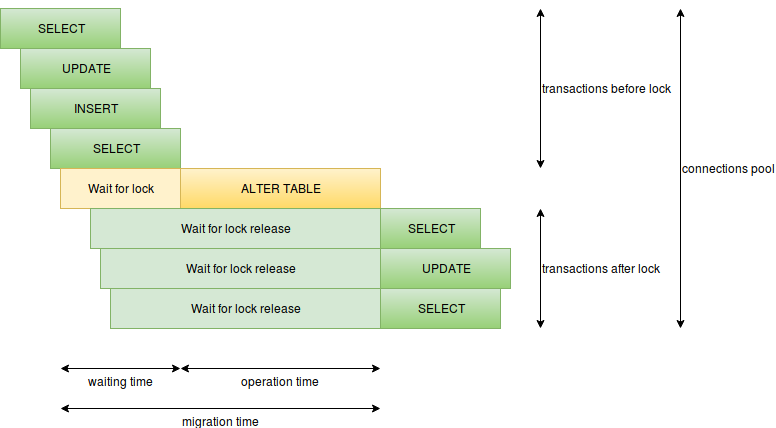
Here you can highlight the following items:
- operation time - for migration, this is the lock hold time, if a heavy lock is held for a long time - we will have downtime, for example, this can be with
CREATE INDEXorALTER TABLE ADD COLUMN SET DEFAULT(in postgres 11 this is better). - waiting time for conflicting locks - that is, migration waits for all conflicting requests to work, but at this time new requests will wait for our migration, slow requests can be very dangerous either as simple as not optimal or analytical, so slow requests should not be migration.
- number of requests per second - if we have a lot of requests for a long time, then free connections can quickly end and instead of one problematic place, the entire database can go to downtime (only the connection limit for the superuser will remain), here you need to avoid slow requests, reduce the number of requests , for example, to start migrations during the minimum load, to separate critical components into different services with their bases.
- many migrations in one transaction - the more transactions in one transaction, the longer a heavy lock is held, so it is better to separate heavy operations, no
ALTER TABLE VALIDATE CONSTRAINTor data migrations in a single transaction with a heavy lock.
Timeouts
lock_timeout has settings such as lock_timeout and statement_timeout , which can secure the launch of migrations, both from poorly written migration and bad conditions in which the migration can be started. Can be installed both globally and for the current connection.
SET lock_timeout TO '2s' allows you to avoid downtime when waiting for slow requests / transactions before migration: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-LOCK-TIMEOUT .
SET statement_timeout TO '2s' allows you to avoid downtime when you start a heavy migration with heavy locking: https://www.postgresql.org/docs/current/static/runtime-config-client.html#GUC-STATEMENT-TIMEOUT .
Deadlocks
Deadlocks in migrations are not about downtime, but pleasantly enough, when the migration is written, it works fine on a test environment, but catches deadlock when you roll on a prod. The main sources of problems can be a large number of operations in one transaction and Foreign Key, since it creates locks in both tables, so it is better to separate the operations of migrations, the more atomic - the better.
Keeping records
Postgres stores different types of values in different ways : if the types are stored differently, then converting between them will require a complete rewriting of all the values, fortunately, some types are stored the same way and do not require rewriting when changing. For example, lines are stored equally regardless of the size and the reduction / increase in the dimension of the line does not require rewriting, but the reduction requires checking that all the lines do not exceed the smaller size. Other types can also be stored in a similar manner and have similar features.
Multiversion Concurrency Control (MVCC)
According to the documentation , the consistency in postgres is based on the multiversion of data, that is, each transaction and operation sees its version of the data. This feature does a great job with competitive access, and also has an interesting effect when changing a schema like adding and deleting columns only changes the schema, if there are no additional operations to change data, indexes or constraints, after which low-level insert and update operations will create records with all necessary values, the deletion will mark the corresponding record as deleted. VACUUM or AUTO VACUUM is responsible for cleaning up the remaining debris.
Django example
We now have an idea of what downtime can depend on and how it can be avoided, but before you apply the knowledge you can see what django gives out of the box ( https://github.com/django/django/blob/2.1.2/django /db/backends/base/schema.py and https://github.com/django/django/blob/2.1.2/django/db/backends/postgresql/schema.py ):
| operation | |
|---|---|
| one | CREATE SEQUENCE |
| 2 | DROP SEQUENCE |
| 3 | CREATE TABLE |
| four | DROP TABLE |
| five | ALTER TABLE RENAME TO |
| 6 | ALTER TABLE SET TABLESPACE |
| 7 | ALTER TABLE ADD COLUMN [SET DEFAULT] [SET NOT NULL] [PRIMARY KEY] [UNIQUE] |
| eight | ALTER TABLE ALTER COLUMN [TYPE] [SET NOT NULL|DROP NOT NULL] [SET DEFAULT|DROP DEFAULT] |
| 9 | ALTER TABLE DROP COLUMN |
| ten | ALTER TABLE RENAME COLUMN |
| eleven | ALTER TABLE ADD CONSTRAINT CHECK |
| 12 | ALTER TABLE DROP CONSTRAINT CHECK |
| 13 | ALTER TABLE ADD CONSTRAINT FOREIGN KEY |
| 14 | ALTER TABLE DROP CONSTRAINT FOREIGN KEY |
| 15 | ALTER TABLE ADD CONSTRAINT PRIMARY KEY |
| sixteen | ALTER TABLE DROP CONSTRAINT PRIMARY KEY |
| 17 | ALTER TABLE ADD CONSTRAINT UNIQUE |
| 18 | ALTER TABLE DROP CONSTRAINT UNIQUE |
| nineteen | CREATE INDEX |
| 20 | DROP INDEX |
My needs for django migrations are very good, now we can discuss with our knowledge safe and dangerous operations for migrations without downtime.
We will call safe migrations with SHARE UPDATE EXCLUSIVE lock or ACCESS EXCLUSIVE , which works out instantly.
Dangerous call migration with SHARE and ACCESS EXCLUSIVE locks that take considerable time.
I will leave in advance a useful link to the documentation with great examples.
Creating and deleting a table
CREATE SEQUENCE , DROP SEQUENCE , CREATE TABLE , DROP TABLE can be called safe, because the business logic either still or does not work with the table being migrated, the behavior of deleting the table with FOREIGN KEY will be a little later.
Heavily supported operations on worksheets
ALTER TABLE RENAME TO - I can not call it safe, because it is hard to write logic that works with such a table before and after migration.
ALTER TABLE SET TABLESPACE is unsafe, since it physically moves the tablet, and this can be long on a large volume.
On the other hand, these operations are rather rare, as an alternative you can suggest creating a new table and copying data into it.
Creating and deleting a column
ALTER TABLE ADD COLUMN , ALTER TABLE DROP COLUMN - can be called safe (creating it without DEFAULT / NOT NULL / PRIMARY KEY / UNIQUE), because the business logic either does not work or does not work with the column being migrated, the behavior of deleting a column with FOREIGN KEY, other constructs and indexes will be later.
ALTER TABLE ADD COLUMN SET DEFAULT , ALTER TABLE ADD COLUMN SET NOT NULL , ALTER TABLE ADD COLUMN PRIMARY KEY , ALTER TABLE ADD COLUMN UNIQUE - unsafe operations, because they add a column and, without releasing the lock, update the data by defaulting or creating a set of patterns. nullable columns and further change.
It is worth mentioning the faster SET DEFAULT in postgres 11, it can be considered as safe, but it does not become very useful in django, because django uses SET DEFAULT only to fill the column and then does DROP DEFAULT , and in the interval between migration and updating machines business logic, records can be created for which default will be absent, that is, then still do the data migration.
Heavily supported operations on a worksheet
ALTER TABLE RENAME COLUMN - I also cannot call it safe, since it is hard to write logic that works with such a column before and after migration. Rather, this operation will also not be frequent, as an alternative can be offered to create a new column and copy data into it.
Column change
ALTER TABLE ALTER COLUMN TYPE - the operation can be both dangerous and safe. Safe if postgres only changes the schema, and the data is already stored in the correct format and no additional type checks are needed, for example:
- type change from
varchar(LESS)tovarchar(MORE); - type change from
varchar(ANY)totext; - change type from
numeric(LESS, SAME)tonumeric(MORE, SAME).
ALTER TABLE ALTER COLUMN SET NOT NULL is dangerous, as it passes through the data inside and checks for NULL, fortunately this constructor can be replaced with another CHECK IS NOT NULL . It is worth noting that this replacement will lead to a different scheme, but with identical properties.
ALTER TABLE ALTER COLUMN DROP NOT NULL , ALTER TABLE ALTER COLUMN SET DEFAULT , ALTER TABLE ALTER COLUMN DROP DEFAULT - safe operations.
Creating and deleting indexes and constructs
ALTER TABLE ADD CONSTRAINT CHECK and ALTER TABLE ADD CONSTRAINT FOREIGN KEY are unsafe operations, but they can be declared as NOT VALID and then made ALTER TABLE VALIDATE CONSTRAINT .
ALTER TABLE ADD CONSTRAINT PRIMARY KEY and ALTER TABLE ADD CONSTRAINT UNIQUE unsafe, because inside they create a unique index, but you can create a unique index like CONCURRENTLY , then create the corresponding count using the ready-made index via USING INDEX .
CREATE INDEX is an insecure operation, but the index can be created as CONCURRENTLY .
ALTER TABLE DROP CONSTRAINT CHECK , ALTER TABLE DROP CONSTRAINT FOREIGN KEY , ALTER TABLE DROP CONSTRAINT PRIMARY KEY , ALTER TABLE DROP CONSTRAINT UNIQUE , DROP INDEX - safe operations.
It is worth noting that ALTER TABLE ADD CONSTRAINT FOREIGN KEY and ALTER TABLE DROP CONSTRAINT FOREIGN KEY make locking of two tables at once.
We apply knowledge in django
Django has an operation in migrations to execute any SQL: https://docs.djangoproject.com/en/2.1/ref/migration-operations/#django.db.migrations.operations.RunSQL . Through it, you can set the necessary timeouts and apply alternative operations for migrations, with indication of state_operations - the migration that we are replacing.
This works well for your code, although it requires additional scribbling, but you can leave the dirty work on db backend, for example, https://github.com/tbicr/django-pg-zero-downtime-migrations/blob/master/django_zero_downtime_migrations_postgres_backend/schema .py collect the described practices and replace unsafe operations with safe counterparts, and this will work for third-party libraries.
At last
These practices allowed me to get an identical scheme created by django out of the box, with the exception of replacing the CHECK IS NOT NULL constructor instead of NOT NULL and the names of some constructs (for example, for ALTER TABLE ADD COLUMN UNIQUE and the alternative). Another compromise may be the lack of transactionality for alternative migration operations, especially where CREATE INDEX CONCURRENTLY and ALTER TABLE VALIDATE CONSTRAINT .
If you do not go beyond postgres, then there are many options for changing the data scheme, and they can be combined in various ways for specific conditions:
- use jsonb as schamaless solution
- the opportunity to go to downtime
- requirement to do migration without downtime
In any case, I hope that the material was useful either to increase uptime or to expand consciousness.
')
Source: https://habr.com/ru/post/425063/
All Articles