Compare TCO purchases of "iron" and rent a cloud

Imagine that in the restaurant you were offered to try a new sauce for your favorite dish, noting that it becomes twice as tasty. In this case, you will have nothing left to do but to do it. After all, it is not possible to define otherwise why the waiter rated his subjective feelings as “twice as tasty” and not, for example, at three. When it comes to spending on IT infrastructure, few people are willing to rely on someone else's feelings or intuition in this matter. To choose the “twice as tasty option” you will need to find a reliable and reliable method for evaluating economic efficiency.
Such a calculation is especially important if you need to convince the management, including the financial director, of the correctness of your decision.
')
The purpose of this article is to understand the TCO methodology for different options for obtaining the right to use the IT infrastructure and carry out the appropriate calculations in order to identify the most cost-effective alternative.
RESULTS OF RESEARCH ARE (UPD)
- understanding of the need to take into account the level of fault tolerance of IT systems as a key feature “to compare apples to apples”;
- calculation of the total cost of ownership of the IT infrastructure for two patterns of use: ERP-system and web-based sports portal resources;
- comparative analysis of the total cost of owning your own IT infrastructure and for renting a cloud;
- factor analysis of savings on the benefits of cloud technologies and identifying the most favorable patterns of cloud use.
What is TCO?
The total cost of ownership or life cycle cost ( English Total Cost of Ownership, TCO ) is the total amount of target costs that the owner has to bear from the moment of commencement of the entry into the state of ownership until the moment when the owner acquires and fulfills the full amount of obligations, associated with possession.
The TCO method was developed in the late 80s of the XX century by the Gartner Group to calculate the financial costs of owning computers on the Wintel platform (MS Windows + Intel). It was improved in 1994 by Interpose and reworked into a full-fledged model for analyzing the financial side of using information technology. With this calculation of TCO, the costs of creating a hardware platform, purchasing software licenses, IT labor costs, and so on are the so-called “direct” or “budget” expenses. But there are still implicit financial investments in the maintenance of its IT infrastructure, costs and losses associated with its operation, and so on. Moreover, the authors of the methodology TCO argue that such costs constitute the main share of the total cost of ownership of IT infrastructure. These costs are called “indirect costs”, and according to the long-term practice of TCO calculations, the “direct costs” mentioned above are 3-5 times higher.
That is, in fact, enterprises spend much more on maintenance of their “iron” than they suppose . Why is this happening and is it possible to optimize the costs of your own IT infrastructure?
It is these goals that the TCO technique pursues. But in order to understand how you can manage maintenance costs, you must first clarify how they are calculated [ 1 ].
To date, there is no universal methodology for determining (calculating) the total cost of ownership, since, depending on the object of ownership, the characteristics of ownership, cost structure and principles for their determination may vary significantly. However, there are general approaches to determining cost at all stages of the life cycle. The key principle implemented in the development of methods for determining the total cost of ownership is a systematic approach .
For an integrated estimate of the cost of ownership, simplified methods for calculating the TCO can be applied, revealing, above all, the cost structure, and giving an idea of the likely losses in the process of ownership.
Thus, it is necessary to make an individual calculation of the TCO for each case and, despite the fact that most of the costs can be determined in advance, or predicted with high accuracy, some costs are probabilistic in nature, which entails the risk of significant deviations of the actual costs from the estimated (estimated ).
How we recommend considering the total cost of ownership of the IT infrastructure and why
TCO or the estimate of total cost of ownership due to its probabilistic nature is rather not important in and of itself, as it is applicable for comparing the costs of alternative ways of obtaining the necessary computing resources.
The most popular alternative to buying your own hardware and virtualization software is to rent a complete IT infrastructure in the cloud using the IaaS model ( English Infrastructure as a Service - Infrastructure as a Service).
There is nothing difficult in calculating the TCO of the cloud: we take and add all payments to the provider for the period. It is much more difficult to calculate total expenses for our own infrastructure, and we will discuss this in detail later.
Have you already managed to carry out the necessary calculations? Now you can compare? Yes, if you did it right.
Do not forget about the important characteristic of the created IT infrastructure as a system - the level of fault tolerance or uninterrupted operation of its process. It is clear that the higher the level of availability of services, the better: the work of office staff does not stand idle due to a failure on the server of the accounting automation system, and buyers do not leave the online store due to "error 503".
In general, a business would like to get 99.99% availability. However, creating a solution of this level will require significant investments. This level of fault tolerance has, for example, a solution based on two storage systems with synchronous mirroring, located in a pair of geographically distant data centers. Not surprisingly, the cost of such a service will be 2 times higher.
Does everybody need such a solution? Of course not. If we are talking about the expected level of availability of 99.95% or 4 hours 23 minutes of downtime per year, we are expected to lose only 0.04% of uptime to the solution, which is 2 times more expensive. In a common year, there are 8,760 hours, which means that if there are no natural cataclysms from which only a disaster-proof solution would save us, we add only 3.5 hours per year to the uptime of the IT infrastructure per year by investing significant funds.
So, we come to the question of how much a minute of downtime costs for your business and what level of fault tolerance you need. Are you familiar with the scary phrase “cost of downtime”?

According to a survey conducted by the Ponemon Institute in 2014, the average cost of minute downtime is $ 7,900, compared with $ 5,600 per minute four years earlier. Although these numbers may look catastrophic, they can easily be discarded as relevant only to a few of the largest companies in the United States.
For the e-commerce giant, such as Amazon, the numbers are even higher. Losses of up to $ 66,240 per minute of service downtime have been reported. At this time, a minute of downtime for small businesses is much cheaper, the relative cost is still significant. Surprisingly, efforts to measure and manage these risks have only recently become a priority for business. As a result, it is easy to make a mistake by ignoring the danger of IT infrastructure downtime, and not try to assess its impact on the results of operations.
How can you estimate losses during downtime if you are a small or medium business? It is not surprising that the corresponding loss math is less impressive. But don't let the numbers fool you. Even a niche retail store with a relatively modest income will experience the “pain" of downtime. Let's look at the list of factors that together form the total cost of losses:
Direct sales revenue loss

This may seem trivial, but assuming revenue is generated online or strictly dependent on IT, you simply need to divide the annual sales amount by 525,600 (60 min. X 24 hours x 365 days) to determine the average cost of downtime per minute. Thus, the loss formula might look something like this:

Where t denotes the number of minutes your IT infrastructure is down.
Cost of loss in employee productivity
Estimated cost of time, workers who are affected by a simple and who can not work as usual.
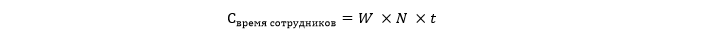
Where W denotes the average hourly wage per employee, and N denotes the number of employees affected by downtime. t in this case is expressed in hours.
IT infrastructure repair cost
The cost of IT staff time restoring your system from a backup or replacing failed hardware.

Where N_IT denotes the number of employees involved in IT recovery operations instead of other business-friendly activities, and t 'denotes the time needed to correct the problems of all affected systems and return them to normal.
Projected loss of income due to reduced customer loyalty
For simplicity, let's assume that the business in question is not widely reported by the media, so we will calculate the projected loss of income based on the loss of possible repeat sales.

Where r denotes the average (rate, percentage) decrease in repeat sales, and D - revenue from repeat sales for the year.
Projected loss of income due to reputation damage
Lost sales to customers exploring the market looking for a better deal or collecting recommendations.
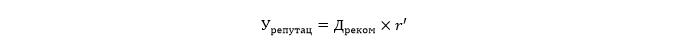
Where r 'denotes the percentage of sales decline associated with customers who come from sites with reviews to compare products / services and social networks.
Thus, the total cost of downtime formula (TCoDT) might look something like this:
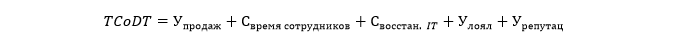
Where U_prodazh, S_time employees, S_vosstan. IT, U_loyal, U_reputz respectively mean lost income, the cost of loss due to reduced employee productivity, the cost of restoring the IT infrastructure, the projected loss of repeat sales and the projected loss due to damage to reputation.
As an example, consider an online store with 50 million rubles in sales and 15 employees in the state. Hourly 5708 rubles or a little more than 95 rubles per minute are direct losses of income.
What is the expected duration of a simple year for the company?
Much depends on how the IT system of this business is organized. Well-studied and typical objects are public data centers. The Uptime Institute has created a layered classification system for the systematic evaluation of various facilities and equipment of data centers in terms of potential infrastructure performance or uptime capability. The system consists of four levels, each level includes the requirements of the lower levels (Tier):
- Tier I: Basic Capacity - base potential, infrastructure without reservation;
- Tier II: Redundant Capacity Components - duplication of critical components, redundant infrastructure;
- Tier III: Concurrently Maintainable - infrastructure with the possibility of parallel repair / maintenance without stopping work;
- Tier IV: Fault Tolerant - fault tolerant infrastructure.
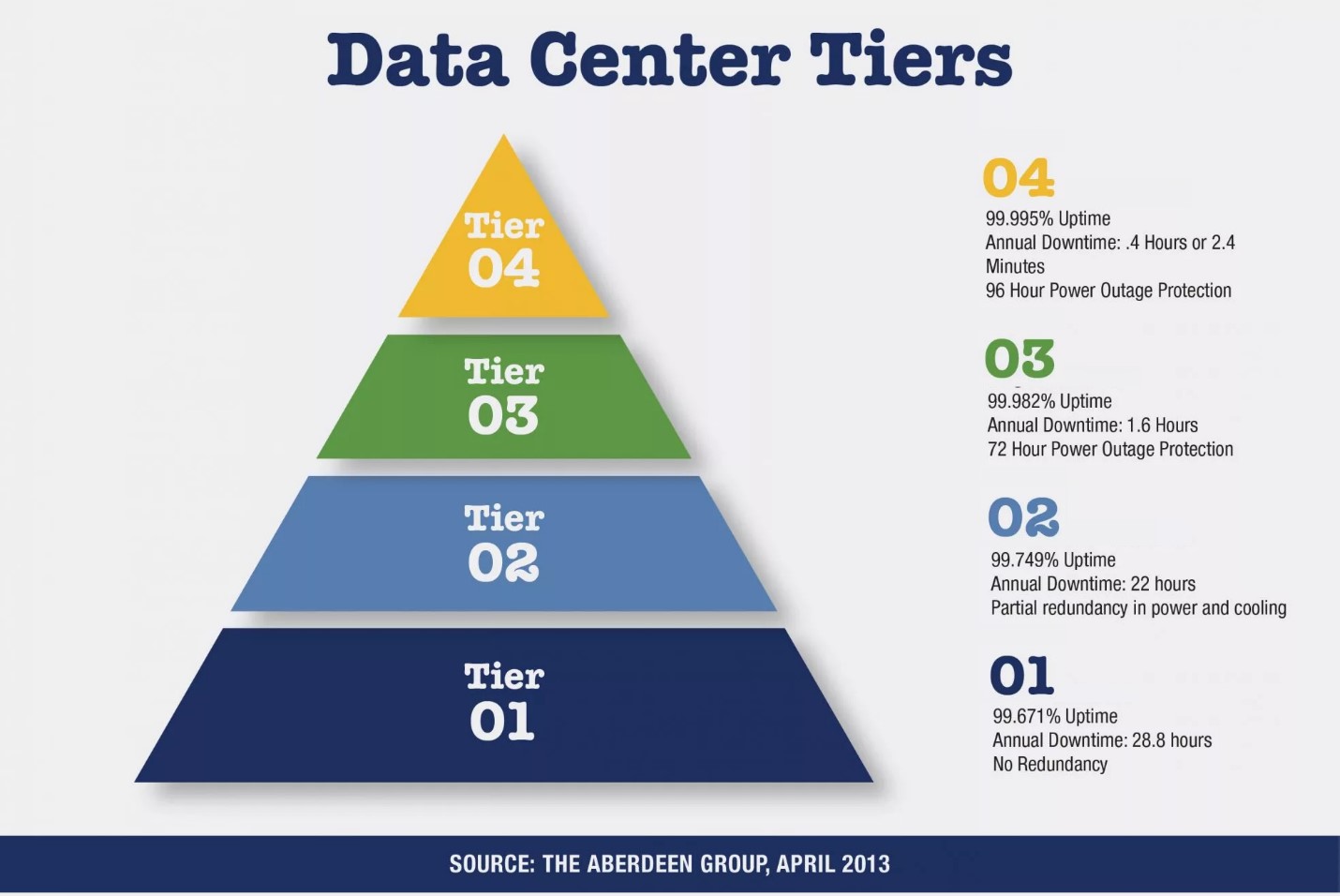
Although the Uptime Institute deleted information about “expected in a simple year” from Tier Standard in 2009 [ 2 , 3 ], we can conclude that, by publishing these data, data center operation experts reported on crashes and to the conclusion that the basic infrastructure without redundancy expectedly works flawlessly 99.671% per year or is idle due to accidents for 28.8 hours.
Often, companies or their remote branches, where servers are located locally, there are no allocated rooms for server and switching nodes, racks are not protected, there is no access control, there is no redundancy, cable organization is low, and specialized cooling and fire extinguishing systems are not at all are thinking. And this is not even Tier 1 with expected downtime for more than a day. A fire in such premises is more likely, and the resulting downtime can last a month and lead to bankruptcy.

The "deplorable" state of the server can cause major accidents
It should be noted here that the entire IT system of an organization is a bundle of support systems (electricity, cooling, security, etc.), communication channels, the actual server, network equipment and data storage systems, system-wide and application software. In such a layered system, the total expected uptime is the product of the fault tolerance levels of each component or
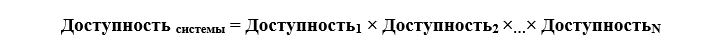
For example, Availability = 99.671% (local data center without redundancy) × 99.671% (IT equipment without redundancy) = 99.343% or about 2.5 days of expected downtime, if failures are caused by different reasons and at different times.
Suppose you have a fairly well-organized activity, and a simple IT infrastructure lasts no more than nine hours a year, a little less than three nines (99.9%). This means that all workers affected by the malfunction (presumably 2/3) could not work normally, at least during this period of time. If we take the average hourly wage with taxes and fees of 500 rubles, it will cost the company 45,000 rubles because of the loss of productivity.
Logically, the IT team will spend some more time figuring out what went wrong, to then prevent recurring crashes. Imagine that your IT geniuses need 50 hours (800 rubles / hour) to fix everything. This time workers could spend on solving the problems of developing your business. Even if you allocate only one employee for this problem, these are additional 40,000 rubles, which should be included in the cost of IT restoration.
Finally, not only customers that you lost, “sending” to one of your competitors, will never return, new customers are less likely to make purchases from you on the advice of partners or on recommendations and reviews on websites to compare products and services.
So, it’s estimated that we’ll add a loss of 50,000 rubles to take into account an additional 1% of the projected loss on repeat sales for the year and 35,000 rubles for a 2% loss of sales from reviews and recommendations caused by downtime. An unpleasant picture emerges, but let's add it all:
| Loss of sales | 51 372 |
| Performance loss | 45,000 |
| IT recovery cost | 40,000 |
| Losses on repeat sales | 50,000 |
| Sales loss by review | 35,000 |
| Total cost of IT infrastructure downtime | 221 372 rubles. |
According to a survey of representatives of big business in the United States, 37% of organizations estimate a day of downtime at a loss of more than 10,000 US dollars, which echoes 38% of respondents who report annual income of more than 10 million dollars. Thus, although the numbers for small and medium businesses are significantly lower than actual losses for corporate downtime, it is also clear that even small businesses that rely on modern technology should be serious about the problem of uptime, given their scale.
With a longer idle time, which your customers have to endure, with each additional hour the potential losses on repeat sales and due to negative feedback grow faster. Thus, an accident in the IT infrastructure can become not only the cause of losses, but also deprive the company of financial stability.
Article 4 of the Law of July 24, 2007 No. 209- and the Resolution of the Government of the Russian Federation of April 4, 2016 No. 265 inform us about income and the number of employees that are criteria for a business to receive a certain legal status.
| The limit value of the average number of employees for the previous calendar year | Revenues for the year according to the rules of tax accounting will not exceed: |
15 people for micro enterprises; 16–100 people - for small enterprises; 101–250 people - for medium-sized enterprises | 120 million rubles. - for microenterprises; 800 million rubles. - for small enterprises; 2000 million rubles - for medium-sized enterprises |
The calculations above describe the work that CIOs must do as a starting point for choosing alternatives. Having determined your risk appetite and the allowable loss from IT system downtime, you need to design all the elements of the system based on the overall planned level of process continuity. The result should be consistent with the tactical and strategic business goals, and not to limit or be an obstacle to their achievement.
As part of this work, we will designate the target level of IT continuity at 99.95% per year. Next, we turn to the calculation of the total cost of ownership for different models of using the IT infrastructure only with a given level of expected fault tolerance.
TCO on-premise solutions
To add a bit of versatility to our example, we will talk about the same hardware configuration, but for two patterns of its use. Our examples will be
- ERP for 350 users
- Popular Sports Portal Website
Calculation of TCO will be made for periods of 3 and 5 years.
Purchase of own equipment
To perform calculations for these tasks, the following hardware configuration will be used. Focusing on the average market prices for high-end server hardware and mid-range storage systems, we obtain the expected costs:
| Equipment | Price |
| 3 + 1 Servers: CPU Xeon® E5 4 core 2,6GHz, RAM 64 Gb, 2x10Gb | 1 500 000 rubles |
| Storage SAS totaling 11 TB (real-time data up to 1TB RAID1, the rest of the historical RAID6) | 2 300 000 rubles |
| 1 + 1 Switches | 200 000 rubles |
The reliability of such systems is calculated in the number of “nines”, of the order, for example, 99.999% of the declared uninterrupted work time per year. Most repair operations and many upgrades for hardware and software (alas, not all) can be done without disruption. And we remember that we stand the system with a general fault tolerance of not less than 99.95%. Thus, we save without buying high-end storage systems, which are several times more expensive, but do not lose in uninterrupted operation.
The server hardware is chosen high-end, since it is for enterprise-level servers that a variety of monitoring and management functions are implemented, fault tolerance and good scalability are ensured.
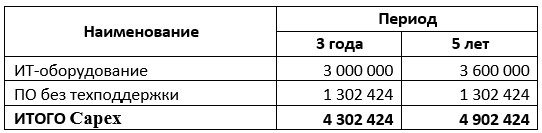
So, we received the first capital expenditure on the purchase of equipment. They amounted to 3 000 000 rubles.
This could be finished with equipment costs, but since we expect TCO for 5 years, and the standard warranty often ends after 3 years, we add the cost of extending warranty service for 2 years. Since the cost of extending the warranty varies for each vendor, we estimate this cost as 20% of the cost of equipment for 2 years or 600,000 rubles in our case. The calculation of the percentage of the cost of after-sales service was carried out using the example of HPE technology [ 4 ].
Place for placement: data center or on-premise
Next we need to decide where we will place our equipment. Well, if you have a great server that is crammed with modern systems, but what if you build it from scratch? How much will such a project cost?
In order to somehow estimate the costs, we turned to the study “Estimated Total Cost of Ownership of a Data Processing Center” L.. Pirogov, V.I. Grekul and B.E. Poklonova [ 5 ]. Based on the analysis of the commercial data center construction market, the authors come to a confidence interval from 59 to 88 thousand US dollars based on the results of regression modeling of capital expenditures for the construction of 1 rack in the data center in Moscow. Thus, even saving on scale, in order to get a reliable platform for equipment placement, which can correspond to the expected equipment downtime of not less than 99.95%, it is necessary to spend about 4.5 million rubles only for construction and equipment without taking into account operating expenses. Of course, the option of such non-core costs disappears for almost all organizations.
The logical option is to place the servers or rent a rack in a commercial data center, the so-called Colocation. The market for commercial data center services is well developed, this approach to the placement of equipment has become generally accepted for reasons of obvious economic feasibility.
Placing 6 units in the Tier III data center (redundancy of power supply, cooling systems, telecom infrastructure and fire extinguishing systems, the ability to repair systems without stopping the server room) in Moscow at average market prices, taking into account additional to the basic tariffs of power consumption and a guaranteed channel will be about 40,000 rubles per month.
If you decide to place the equipment in your own server room, then you should take into account the total power consumption of your data center (server) - this is the power consumption of IT equipment plus the consumption of everything that supports its work, namely:
- power supply systems, including UPS, switchgear, generators, batteries; This also includes losses in the distribution of external power to IT equipment;
- components of cooling systems: chillers, cooling towers, pumps, ventilation systems and air conditioners in engine rooms, humidifiers, etc .;
- other loads, such as data center lighting.
To determine the energy efficiency in the industry, it is customary to use the PUE indicator. The PUE (Power Usage Effectiveness) parameter is defined as the ratio of the energy requirements of the IT infrastructure to the total energy supplied to the data center. The ideal PUE value is equal to one, in this case all the energy used by the site goes to support the operation of the servers. In practice, this situation is impossible, the minimum PUE values reach around 1.1-1.15, the organization of work using the “best methods” gives an average of 1.6, and the average PUE for TIER III data centers is 1 in the world , 98.
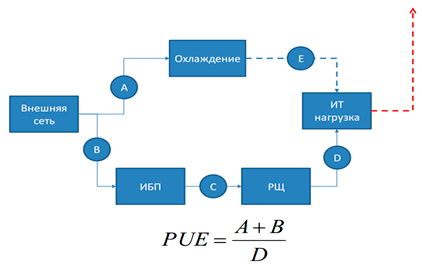
Source: APC by Schneider Electric, 2010
Thus, if your IT equipment has a rated power of 4 kW, then with a PUE of 2, you need 8 kWh. If the server works 24 hours a day, about 5,800 kW will be released within a month, which at a rate of 5 rubles per kW will cost 29,000 rubles. From this it becomes clear that in the price of placement in a commercial data center a significant part of the cost is electricity, and other expenses are distributed to numerous tenants who pay less than if they would have implemented such conditions in the enterprise locally.
We fix the costs of 40,000 rubles per month for the placement of equipment in a commercial data center as an economically optimal choice and in the future we will use only this option for calculations.
Software costs
Why we will consider an example using virtualization? Virtualization can increase the adaptability, flexibility and scalability of the IT environment and significantly reduce costs. Virtualization accelerates the deployment of workloads, increases their productivity and availability, and also provides an opportunity to automate processes, as a result of which the company's IT infrastructure becomes more manageable and cost-effective. Additional benefits include the following:
- reduction of capital and operating costs;
- minimizing or eliminating downtime;
- increased responsiveness, adaptability and overall performance of IT staff;
- accelerate the initialization of applications and resources;
- business continuity and disaster recovery;
- simplified data center management;
- creation of fully software data center.
IT departments are faced with the limitations of modern x86 servers, which are designed to run only one operating system and one application at a time. As a result, even in small data centers, a large number of servers have to be deployed, each of which is only 5–15% loaded. It is ineffective from any point of view [ 6 ].
In virtualization, software is used to simulate the availability of equipment and create a virtual computer system. Because of this, business units can run multiple virtual systems, as well as multiple operating systems and applications on a single server. This approach provides economies of scale and efficiency.
Can I use free virtualization platforms?
In case you do NOT need a massive deployment of virtual servers in your organization, constant monitoring of the performance of physical servers under varying load, and a high degree of availability, you can use virtual machines based on free platforms to maintain the organization’s internal servers [ 7 ]. With the increase in the number of virtual servers and their high degree of consolidation on physical platforms, the use of powerful tools to manage and maintain the virtual infrastructure is required. Depending on whether you need to use different systems and storage networks, such as the Storage Area Network (SAN), backup and disaster recovery tools, and live migration of running virtual machines to other equipment, you may not have enough free Virtualization platforms, however, should be noted that free platforms are constantly updated and acquire new functions, which expands the scope of their use.
Another important point is technical support. Free virtualization platforms exist either within the framework of the Open Source community, where many enthusiasts are engaged in finalizing the product and its support, or are supported by the platform vendor.The first option involves the active participation of users in the development of the product, making error reports by them and does not guarantee solving your problems when using the platform, in the second case, more often than not, technical support is not provided at all. Therefore, the qualification of personnel deploying free platforms should be at a high level.
Thus, we come to the conclusion that for a corporate use case, for example, an ERP system, we will need paid virtualization software with advanced functionality. Leading positions in the market occupy VMware. All Fortune 500 companies choose the VMware infrastructure platform, which has helped customers save tens of billions of dollars.
An important factor in choosing a VMware software platform is the lowest total cost of ownership compared to competing solutions. You can independently use the calculators of total cost of ownership and return on investment for comparison with alternatives, such as solutions from Microsoft and traditional IT infrastructure [ 8 ].
Since we initially decided that we will consider two use cases, then for a case with a sports portal, we agree that free, open-source software solutions will be used, and in the case of ERP - licensed software from VMware.

Total for virtualization software - 1.2 million rubles. The annual cost of technical support and access to update products - 334 thousand rubles.
Add to this the license for software for storage medium level - 100 thousand rubles.
Staff costs
While actual personnel costs to support the stable operation of the IT infrastructure typically consist of several different people’s salaries, for simplicity, we will use a simple ratio between the number of servers and the number of people that AWS derived for use in their cost models. Let's call this the “server-to-admin” ratio.
Based on customer discussions, AWS found that a 50-to-1 ratio is a good average from a range of companies. We recommend adjusting this assumption based on your own research and experience and include in the staff costs all the people involved in setting up and managing your physical data center, and not just the people who install and administer the servers. The actual relationship between people and servers can vary greatly, since it depends on a number of factors, such as the complexity of the automation, the tools used, the choice in favor of a virtualized or non-virtualized environment.
Since we are talking about some abstract employee who will have different specializations corresponding to current tasks, we will use the median monthly salary of an IT specialist for the first half of 2018 from the My Circle service report [ 9 ].
According to the survey, it amounts to 90,000 rubles per person after deducting all taxes and fees. Adding another 50% to payments to the Pension Fund, the MHIF, the Social Insurance Fund and personal income tax, we get 135,000 rubles. This is the cost of one IT specialist who is 100% loaded with working with IT infrastructure, the creation of which we describe in our case.
Since we have 4 servers and 1 storage system, applying “server-to-admin” equal to 50 to 1, we get about 10% of the cost of working time of one “universal” employee or 13.5 thousand rubles of expenses per month.
Total costs for own infrastructure
Capex (capital expense or capital expenditure) means capital expenditure or expenses. These are expenses, as a rule, one-time (irregular), directed by the company to purchase non-current assets, their modernization and reconstruction.
Opex (English operating expense, operating expenditure - operating costs) - the costs incurred by the company in the course of its current activities to ensure operation. Such expenses are also called expenses of the current period.

The total TCO of such infrastructure will amount to 7,331,498 rubles over 3 years, and 9,884,214 rubles over 5 years.
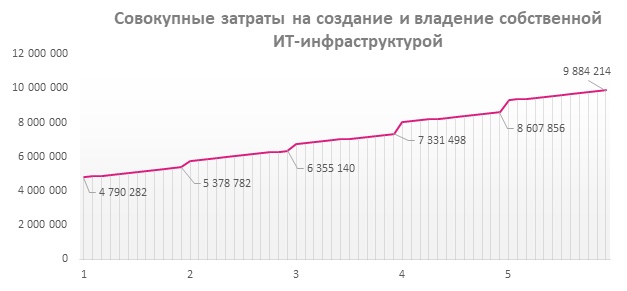
Thus, the initial investment in software and equipment will increase by more than 2 times over the next 5 years. By themselves, the 4.8 millions needed to run this infrastructure also contain risks.
First, the price of a mistake. If we are not talking about a stable enterprise with a well-predicted need for computing power, but are considering a startup with a new service that is trying to conquer the market, all initial investments can be wasted. Yes, of course, the purchased equipment can be sold. However, such transactions are carried out with a large discount, and the search for a buyer can last for months.
Secondly, the value of money.Often such projects are implemented with the involvement of credit funds. Having received a loan of 4 million rubles with an interest rate near the minimum threshold for legal entities. persons at 12% per annum, the amount of interest for 3 years will amount to 783 thousand rubles.
We will not add these optional costs to our TCO calculation , however, when you do an analysis of your case, you must take into account the conditions for receiving money by your business and add the corresponding costs.
It turns out, owning "their own iron" is quite expensive. An alternative option is the use of cloud services. Let's move on to the comparison.
Calculate TCO clouds
Since we cannot talk about the costs of the cloud without choosing a specific provider, we will do our own TCO analysis.
Since its inception in 2009, the Cloud4Y corporate cloud provider has been focused on the needs and high demands of the business for IT services. We offer software-configured data centers (vDC) based on VMware vSphere cluster solutions managed by the VMware vCloud Director self-service portal.
In addition to the IaaS model (infrastructure as a service), we have developed and successfully provide clients with many relevant and popular SaaS products (1C in the cloud, remote desktops, corporate mail, antispam, and more).
Used VMware technology stack (vSphere, NSX, vCloud Director), reliable hardware(HP blade servers, all-flash storage systems, Cisco and Juniper switches) located in the TIER 3 secure data center network, connected by a high availability optical ring with duplicate communication channels, ensure proper quality of services and fault tolerance required for enterprise clients.

Cloud4Y provides full hardware redundancy of server and network equipment. Backup is carried out in a geographically remote data center. VMware cluster options are implemented by default: vMotion “live migration”, automatic transfer of a virtual machine to a backup host in case of VMware HA (High availability) failure, load balancing between VMware DRS hosts.
If you need to reduce downtime to a minimum time, it is possible to use the technology of VMware Fault Tolerance. The main idea of the option can be described as creating a synchronous replica of a virtual machine on another server and instantly switching to it when the primary host fails.
Technical support is provided in the mode of 24 * 7 * 365. The support is divided into three lines:
- The first line of technical support deals with issues of accessibility and technical issues up to the OS level inclusive, gets tickets and advises clients. In the case of queries that do not affect the data and do not relate to finance, customer issues can be resolved by any of the available methods.
- , , , , .
- , .
We see that all components of the Cloud4Y cloud are designed to ensure the maximum level of business continuity. This suggests a total expected system availability level of 99.982% per year. Not a single element of the system, be it a network, equipment, site or virtualization platform, is a weak link.
The availability level is 99.982% higher than the minimum level we planned. So, let's proceed to the calculation of TCO in the cloud and find out if we can get services without a premium for increased fault tolerance.
An alternative nominal configuration in the cloud will be 32 vCPU, 256 Gb RAM and 11 Tb Medium SAS (4400 IOPS). When calculating on the calculator on the site, we get 250,824 rubles a month and a discount offer. Depending on the project, the discount will be different, but we plan a possible discount at the level of 20%, which ultimately will give us 2,407,910 rubles a year, 7.22 million over 3 years and 12 million rubles over 5 years.
At this stage, the cloud solution loses the creation of its own IT infrastructure, but do not rush to conclusions.
Reservation
First, the hardware reservation is already provided by the provider, in case of failure, you will be allocated another host from the provider resource pool. This means an alternative power configuration is 24 vCPU, 196 Gb RAM and 1 Tb Medium SAS and 10 Tb Low. We receive already 187 793 rubles a month or 150 234 rubles. with discount.
With this adjustment, we are already at a cumulative cost lower than our own architecture. We talked about 7.3 million rubles for 3 years, and 9.9 million rubles for 5 years for our own "iron". At this stage, the cloud is already cheaper - 5.4 and 9 million rubles, respectively.
Elasticity
An important advantage of cloud computing is elasticity (rapid elasticity). Resources can be quickly allocated and released, in some cases automatically, for rapid scaling, commensurate with demand. For the consumer, the possibilities of providing resources are seen as unlimited, that is, they can be assigned in any quantity and at any time.
In other words, if you need 30 CPUs, then you just rent 30 CPUs in the cloud. But, if you build your own resources, then you definitely will not create exactly 30. Imagine that you are the CIO of a sports web portal, and are preparing the computing power for passing the World Cup. In this case, you should be ready for peak visits during this period, and the key question for you is what resources will be sufficient. If there are too few of them to plan, then there will not be enough of them during major sports events, and if there are too many, they will stand idle the rest of the time.
In the beginning, we talked about considering two usage patterns. In the case of the ERP system, we will increase the amount of resources used from 2/3 in the first three years, to full utilization (payload) for 4 and 5 years. For the resources of the sports portal, we will provide two peaks of almost 100% downloads per year for 1 month each, the rest of the time resources will be used only by 40%.

It is the high utilization of resources and effective management that allows cloud providers to earn in their business. How does this help save tenants?
We proceed to the calculations.
ERP scenario: 2/3 of resources utilization (121 thousand rubles / month) in the first three years will cost 4,356 million rubles, and all 5 years taking into account the growth - 7.961 million rubles.
Sports portal:1/6 of utilization is up to 100% of the maximum amount of resources, and 5/6 - 40% of utilization. Storage resources - growth from 40% to 90% in 5 years.
In the graph below, you can see how costs are growing over the course of 5 years and how user portal peaks in the portal affect spending on cloud infrastructure.
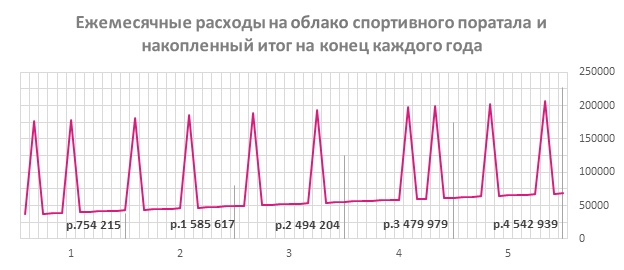
Using resources as needed, you can reduce costs to 2.494 million rubles. for three years and 4,543 million rubles. for 5 years.
So, we are finally ready to compare the TCO of the cloud solution and the purchase of our own hardware.

According to our calculations, the cloud for the corporate use scenario is cheaper by 1.9 million rubles or 19.5% cheaper in 5 years and 40.5% cheaper in the future 3 years.
We have added options using free virtualization software and with renting physical servers in the data center with our license, but even they lose to the cloud for 3 years. When comparing a 5-year-old TCO, these options turn out to be “more profitable”, but they imply a decrease in controllability, resiliency and flexibility. Such options are poorly applicable for corporate IT, in the scenario of use for the sports portal these options are losing to the cloud even in TCO-5 years.
Cost of money
At the very least, the money saved could have been used by the business for other projects, and therefore it would be profitable. Taking a return on investment of 10% per year, we can talk
- 1,7 . ( on-premise cloud ) 1,9 . 5 ERP
- 2,5 . «» 5,3 . .
Pay as you go
Cloud4Y provides the “Pay as you go” payment model for each type of resource separately. This approach makes it possible to pay for resources upon consumption. We use today just as many cores and RAM as needed. It is worth noting that in all cases, the fee for the CPU and RAM is taken only for the "on" time, at the time when you are not using the virtual machine - no fee is charged. But the storage will have to be paid regardless of whether the machine is turned on or off - the fee is taken until the disk has data, if the disk is clean - no fee is charged.
On the site you can find a calculator of the cost of services, but it is worth noting that it works based on the assumption of using the VM in 24x7x30 mode. Using a VM in 12x5x30 mode, the cost of the service for you may be lower by more than 50-60%. Such a pattern of resource utilization is typical, for example, of the infrastructure of virtual remote desktops or “cloud office”. When employees of the organization are not working, the virtual machines with their desktops are turned off, and savings begin. We did not consider such a use case versus TCO, but it is logical and tested in practice that the cloud bypasses other alternatives in this case.
findings
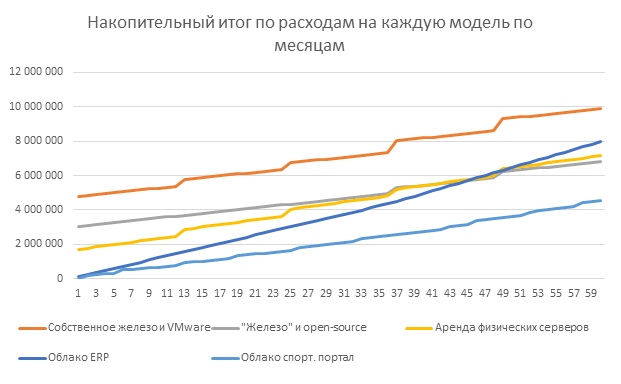
The graph clearly shows that during the entire 5-year lifespan of the IT infrastructure, Cloud4Y cloud benefits from buying its own hardware. Outside of this period, servers are likely to become morally obsolete and it will be necessary to purchase new ones. The provider itself is also responsible for updating the equipment in the cloud. Thus, consideration of a longer period will not change the situation with the economic viability of the cloud.
There are options when the cloud will be less profitable. Basically, these are cases with the presence of already acquired and idle equipment or the purchase of servers in order to slightly increase the already existing and effectively used resources. It is also possible to conclude that cloud services are more significant in scenarios with abrupt or unpredictable capacity utilization.
In order to get advice and calculate TCO in the cloud for the case of your organization, please contact any Cloud4Y manager in the way that suits you.
Sources
- Optimization of IT costs // Corporate Governance Internet project. URL: www.cfin.ru/itm/tco.shtml (appeal date 09/20/2018)
- The official site of the Uptime Institute. URL: en.uptimeinstitute.com (appeal date: 09/19/2018 )
- Myths and misconceptions regarding the Tier-certification system Uptime Institute // Cloud4Y Site. URL: www.cloud4y.ru/about/news/Myths-and-Misconceptions-Regarding-the-Uptime-Institute%E2%80%99s-Tier-Certification-System (appeal date: 09/19/2018 )
- Hewlett Packard Enterprise Support Services Central site. URL: ssc.hpe.com/portal/site/ssc/?action=determineNodeContents&nodeId=30749 (access date: 09/24/2018, selected duration is 2 years)
- "Estimation of the total cost of ownership of the data center." URL: bijournal.hse.ru/data/2016/08/11/1118257058/%D0%9F%D0%B8%D1%80%D0Be%D0%B3%D0Be%D0%B2%D0%B0 % 20% D0% 93% D1% 80% D0% B5% D0% BA% D1% 83% D0% BB% 20% D0% 9F% D0% BE% D0% BA% D0% BB% D0% BE% D0 % BD% D0% BE% D0% B2% 20% D0% A0% D0% A3% D0% A1.pdf (reference date: 09/24/2018)
- Virtualization Principles // VMware Official Website. URL: www.vmware.com/ru/solutions/virtualization.html (appeal date: 09/25/2018)
- Free server virtualization platform. URL: www.ixbt.com/cm/virtualization-servers-free.shtml (access date: 09/25/2018)
- VMware TCO Comparison Calculator. URL: tco.vmware.com/tcocalculator (access date: 09/24/2018)
- Salaries of IT professionals in the middle of 2018 // My Circle service blog on Habr URL: habr.com/company/moikrug/blog/420391 (appeal date: 09/20/2018)
Free Download link White Paper: Calculate TCO Cloud vs Purchase Servers (.pdf)
Source: https://habr.com/ru/post/425003/
All Articles