How machine learning has helped me understand some aspects of early child development.
When my first son was only two, he already loved cars, knew all the makes and models (even more than I, thanks to my friends), could recognize them by a small part of the image. Everyone said: genius. Although they noted the complete uselessness of this knowledge. A son, meanwhile, slept with them, rolled them, arranged exactly in a row or a square.

When he was 4, he learned to count, and at 5 he could multiply and add up to 1000. We even played Math Workout (a game like this on Android - I loved to calculate in the subway after work), and at some point he became me do just that. And in his free time, he counted up to a million, which froze those around him. Genius! - they said, but we somehow suspected that not quite.
By the way, he helped the mother quite well in the market - he calculated the total amount faster than the sellers on the calculator.
')
However, he never played on the court, did not communicate with peers, did not get along with children and caregivers in the garden. In general, was a bit of a closed child.
The next step was geography - we tried to channel the love of numbers somewhere, and handed our son the old Soviet atlas. He plunged into it for a month, and after that began to ask us tricky questions in style:
- Dad, what country do you think has a large area: Pakistan or Mozambique?
“Probably Mozambique,” I replied.
- And no! The area of Pakistan is as much as 2350 km2 more, the son happily answered.

At the same time, he was not at all interested in the peoples inhabiting these countries, or their languages, or clothes, or folk music. Only bare numbers: area, population, mineral reserves, etc.
All admired again. “Umen is over the years,” they said around, but again I was worried, because I understood that this is completely useless knowledge, not tied to life experience, and which is difficult to continue to develop. The best use of all that I found was a proposal to calculate how many cars would fit in the parking lot, if any particular country was rolled up with asphalt (without taking into account the mountainous terrain), but quickly broke off, because it smacks of genocide.
What is interesting, the theme of the cars by this time left completely, the son did not even remember the names of the favorite cars from his huge collection, which we, with the loss of interest, began to distribute. And then he began to count more slowly in his mind and soon forgot the area of the countries. At the same time, he began to communicate more with his peers, became more contact. The genius passed, friends stopped admiring, the son became just a good student with a penchant for mathematics and exact sciences.
It would seem, why all this. This is observed in many children. Their parents all declare that their children are brilliant, their grandmothers admire and praise the children for their “knowledge”. And then ordinary simple children grow up from them, not more ingenious than the mum's friend's son.
Studying neural networks, I came across a similar phenomenon, and it seems to me that certain conclusions can be drawn from this analogy. I am not a biologist or a neurobiologist. All further - my guesses without any claim to a special science. I would be happy to comment professionals.
When I tried to understand how my son so abruptly learned to count faster than me (he passed the level in Math Workout in 20.4 seconds, while my record was 21.9), I realized that he did not count at all. He memorized that when 55 + 17 appeared, you need to click on 72. At 45 + 38 you need to click on 83, and so on. At first, he certainly counted, but a jerk in speed occurred at the moment when he was able to remember all the combinations. And quickly enough, he began to memorize not specific letters, but combinations of characters. This is exactly what is taught in school, studying the multiplication table - remember the correspondence table MxN -> P.
It turned out that he perceived most of the information as a connection between the input data and the output, and the very general algorithm that we used to scroll to get an answer was not just reduced to a very well-sharpened, highly specialized two-digit counting algorithm. The tasks were slightly different, he did, but much slower. Those. what seemed super cool to everyone was in fact simply simulated by a well-trained neural network for a specific task.
Why do some children have the ability to memorize this, while others do not?
Imagine the field of interest of the child (here we approach the issue qualitatively, without any measurements). On the left is the field of interests of an ordinary child, and on the right is the field of interests of the “gifted” child. As expected, the main interest is concentrated in areas to which special inclinations. But for everyday things and communication with peers focus is not enough. This knowledge he considers superfluous.
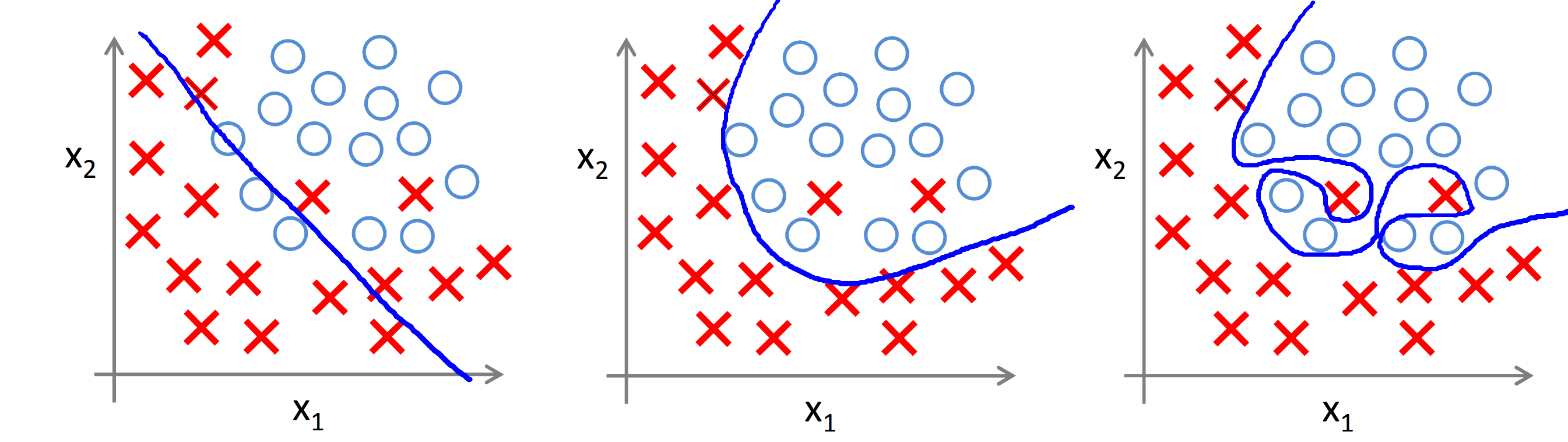
In such children, the brain analyzes and conducts training only on selected topics. By training the neural network in the brain must learn to successfully classify incoming data. But the brain has many, many neurons. Much more than is necessary for normal work with such simple tasks. Usually in life, children solve many different tasks, but here all the same resources are thrown onto a narrower circle of tasks. And training in this mode easily leads to what ML professionals call overfitting. The network, using an abundance of coefficients (neurons), has learned in such a way that it always gives exactly the right answers (but it can produce complete nonsense at intermediate inputs, but no one sees this). Thus, learning did not lead to the fact that the brain identified the main characteristics and remembered them, but to the fact that it adjusted many coefficients in order to produce an exact result on the already known data (as in the picture on the right). And on the other topics, the brain learned so-so, having badly trained (as in the picture on the left).
It seems to me that it is precisely the tendency of the child to a specific topic (obsession) and complete disregard for the other topics, which leads to the fact that when learning too many “factors” are given to these very topics.
Given that the network is configured for specific input data and did not select “features”, but stupidly “remembered” the input data, it cannot be used with some other input data. The applicability of such a network is very narrow. With age, the horizon expands, the focus is blurred, and there is no longer any opportunity to allocate as many neurons to the same task - they begin to be used in new tasks that are more necessary for the child. The “settings” of that overfitted network collapse, the child becomes “normal”, the genius disappears.
Of course, if a child has a skill that is useful in itself and can be developed (for example, music or sports), then its “genius” can be maintained for a long time, and even bring these skills to a professional level. But in most cases this does not work, and from past skills and a trace will not remain by the age of 8-10.
When he was 4, he learned to count, and at 5 he could multiply and add up to 1000. We even played Math Workout (a game like this on Android - I loved to calculate in the subway after work), and at some point he became me do just that. And in his free time, he counted up to a million, which froze those around him. Genius! - they said, but we somehow suspected that not quite.
By the way, he helped the mother quite well in the market - he calculated the total amount faster than the sellers on the calculator.
')
However, he never played on the court, did not communicate with peers, did not get along with children and caregivers in the garden. In general, was a bit of a closed child.
The next step was geography - we tried to channel the love of numbers somewhere, and handed our son the old Soviet atlas. He plunged into it for a month, and after that began to ask us tricky questions in style:
- Dad, what country do you think has a large area: Pakistan or Mozambique?
“Probably Mozambique,” I replied.
- And no! The area of Pakistan is as much as 2350 km2 more, the son happily answered.
At the same time, he was not at all interested in the peoples inhabiting these countries, or their languages, or clothes, or folk music. Only bare numbers: area, population, mineral reserves, etc.
All admired again. “Umen is over the years,” they said around, but again I was worried, because I understood that this is completely useless knowledge, not tied to life experience, and which is difficult to continue to develop. The best use of all that I found was a proposal to calculate how many cars would fit in the parking lot, if any particular country was rolled up with asphalt (without taking into account the mountainous terrain), but quickly broke off, because it smacks of genocide.
What is interesting, the theme of the cars by this time left completely, the son did not even remember the names of the favorite cars from his huge collection, which we, with the loss of interest, began to distribute. And then he began to count more slowly in his mind and soon forgot the area of the countries. At the same time, he began to communicate more with his peers, became more contact. The genius passed, friends stopped admiring, the son became just a good student with a penchant for mathematics and exact sciences.
Repetition - the mother of learning
It would seem, why all this. This is observed in many children. Their parents all declare that their children are brilliant, their grandmothers admire and praise the children for their “knowledge”. And then ordinary simple children grow up from them, not more ingenious than the mum's friend's son.
Studying neural networks, I came across a similar phenomenon, and it seems to me that certain conclusions can be drawn from this analogy. I am not a biologist or a neurobiologist. All further - my guesses without any claim to a special science. I would be happy to comment professionals.
When I tried to understand how my son so abruptly learned to count faster than me (he passed the level in Math Workout in 20.4 seconds, while my record was 21.9), I realized that he did not count at all. He memorized that when 55 + 17 appeared, you need to click on 72. At 45 + 38 you need to click on 83, and so on. At first, he certainly counted, but a jerk in speed occurred at the moment when he was able to remember all the combinations. And quickly enough, he began to memorize not specific letters, but combinations of characters. This is exactly what is taught in school, studying the multiplication table - remember the correspondence table MxN -> P.
It turned out that he perceived most of the information as a connection between the input data and the output, and the very general algorithm that we used to scroll to get an answer was not just reduced to a very well-sharpened, highly specialized two-digit counting algorithm. The tasks were slightly different, he did, but much slower. Those. what seemed super cool to everyone was in fact simply simulated by a well-trained neural network for a specific task.
Extra knowledge
Why do some children have the ability to memorize this, while others do not?
Imagine the field of interest of the child (here we approach the issue qualitatively, without any measurements). On the left is the field of interests of an ordinary child, and on the right is the field of interests of the “gifted” child. As expected, the main interest is concentrated in areas to which special inclinations. But for everyday things and communication with peers focus is not enough. This knowledge he considers superfluous.
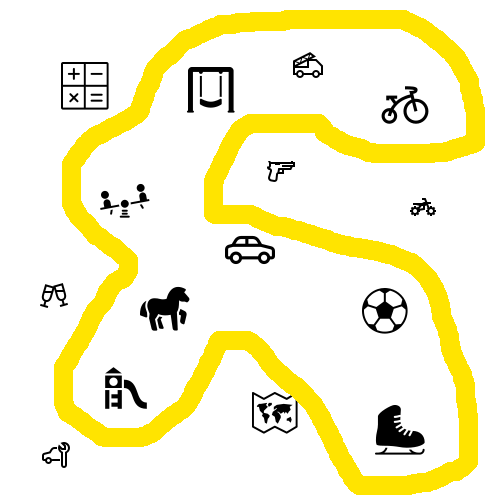 |  |
| The interests of an ordinary child 5 years | Interests of the "genius" child 5 years |
In such children, the brain analyzes and conducts training only on selected topics. By training the neural network in the brain must learn to successfully classify incoming data. But the brain has many, many neurons. Much more than is necessary for normal work with such simple tasks. Usually in life, children solve many different tasks, but here all the same resources are thrown onto a narrower circle of tasks. And training in this mode easily leads to what ML professionals call overfitting. The network, using an abundance of coefficients (neurons), has learned in such a way that it always gives exactly the right answers (but it can produce complete nonsense at intermediate inputs, but no one sees this). Thus, learning did not lead to the fact that the brain identified the main characteristics and remembered them, but to the fact that it adjusted many coefficients in order to produce an exact result on the already known data (as in the picture on the right). And on the other topics, the brain learned so-so, having badly trained (as in the picture on the left).
What is underfitting and overfitting?
For those who are not in the subject, I will tell quite briefly. When teaching a neural network, the task is to select a certain number of parameters (weights of connection between neurons) so that the network responds to the training data (training sample) to respond as closely and accurately as possible.
If there are too few of such parameters, the network will not be able to take into account the details of the sample, which will lead to a very rough and averaged response that does not work well even on the training sample. Approximately as in the left picture above. This is underfitting.
With an adequate number of parameters, the network will give a good result, “swallowing” strong deviations in the training data. Such a network will respond well not only to the training sample, but also to other intermediate values. Something like the middle picture above.
But if the network gives too many customizable parameters, then it will be trained to reproduce even strong deviations and fluctuations (including those caused by errors), which can lead to complete nonsense when trying to get an answer to the input data not from the training sample. Something like the right picture above. This is overfitting.
A simple illustrative example.

Imagine that you have several points (blue circles). You need to draw a smooth curve that allows you to predict the position of other points. If we take, for example, a polynomial, then at small degrees (up to 3 or 4) our smooth curve will be fairly accurate (blue curve). At the same time, the blue curve may not pass through the initial points (blue points).
However, if the number of coefficients (and hence the degree of the polynomial) is increased, the accuracy of passing the blue points will increase (or even be 100% hit), but the behavior between these points will become unpredictable (see how the red curve fluctuates).
If there are too few of such parameters, the network will not be able to take into account the details of the sample, which will lead to a very rough and averaged response that does not work well even on the training sample. Approximately as in the left picture above. This is underfitting.
With an adequate number of parameters, the network will give a good result, “swallowing” strong deviations in the training data. Such a network will respond well not only to the training sample, but also to other intermediate values. Something like the middle picture above.
But if the network gives too many customizable parameters, then it will be trained to reproduce even strong deviations and fluctuations (including those caused by errors), which can lead to complete nonsense when trying to get an answer to the input data not from the training sample. Something like the right picture above. This is overfitting.
A simple illustrative example.
Imagine that you have several points (blue circles). You need to draw a smooth curve that allows you to predict the position of other points. If we take, for example, a polynomial, then at small degrees (up to 3 or 4) our smooth curve will be fairly accurate (blue curve). At the same time, the blue curve may not pass through the initial points (blue points).
However, if the number of coefficients (and hence the degree of the polynomial) is increased, the accuracy of passing the blue points will increase (or even be 100% hit), but the behavior between these points will become unpredictable (see how the red curve fluctuates).
It seems to me that it is precisely the tendency of the child to a specific topic (obsession) and complete disregard for the other topics, which leads to the fact that when learning too many “factors” are given to these very topics.
Given that the network is configured for specific input data and did not select “features”, but stupidly “remembered” the input data, it cannot be used with some other input data. The applicability of such a network is very narrow. With age, the horizon expands, the focus is blurred, and there is no longer any opportunity to allocate as many neurons to the same task - they begin to be used in new tasks that are more necessary for the child. The “settings” of that overfitted network collapse, the child becomes “normal”, the genius disappears.
Of course, if a child has a skill that is useful in itself and can be developed (for example, music or sports), then its “genius” can be maintained for a long time, and even bring these skills to a professional level. But in most cases this does not work, and from past skills and a trace will not remain by the age of 8-10.
findings
- Do you have a brilliant child? it will pass;)
- outlook and "genius" are related things, and they are connected precisely through the mechanism of learning
- this visible "genius" is most likely not at all genius, but the effect of too strong brain training on a specific task without understanding it - just all the resources were devoted to this task
- when correcting the narrowness of the interests of the child, his genius disappears
- if your child is “brilliant” and a bit more closed than peers, then you need to develop these same skills carefully, actively developing your horizons in parallel, and not focus on these “cool” but usually useless skills
Source: https://habr.com/ru/post/424201/
All Articles