The developers remained unknown. Yandex lecture
This report by Alexey Milovidov, the leader of the ClickHouse development team, is a review of the little-known DBMS. Some of them are outdated, some have ceased their development and abandoned. Alexey draws attention to interesting architectural solutions in the listed examples, understands their fate and explains what requirements your open-source project should meet.
- My report will be about the database. Let me immediately ask, which city’s metro map is shown on this slide? All lines go one way.
')
Everything is wrong, it is not metropolitan at all, it is a pedigree of relational databases. If you look closely, you will see that the river is the Codda River.
I will not talk about them. What could be more boring than talking about MySQL, PostgreSQL or something like that? Instead, I will talk about craft databases.

Manual assembly. Systems that are almost unknown to anyone. They are either designed by one person or abandoned long ago.

The first example is EventQL. Please raise your hand if you have ever heard of this system. Not a single person, except those who work at Yandex and have already listened to my report. So, it’s not for nothing that I included this system in my review.

This is a distributed column DBMS designed for event processing and analytics. It performs very fast SQL queries, open source from July 26, 2016, written in C ++, ZooKeeper is used for coordination, except for it there are no dependencies. Something reminds me of it. Our wonderful system, everyone already knows the name. EventQL is like ClickHouse, but better. Distributed, massively parallel, column-oriented, scaled to petabytes, quick range-requests - everything is clear, this is all we have. Almost full support for SQL 2009, realtime inserts and updates, automatic distribution of data across the cluster, and even ChartSQL for describing graphs. So cool! This is what we promise everyone and what we don’t have.
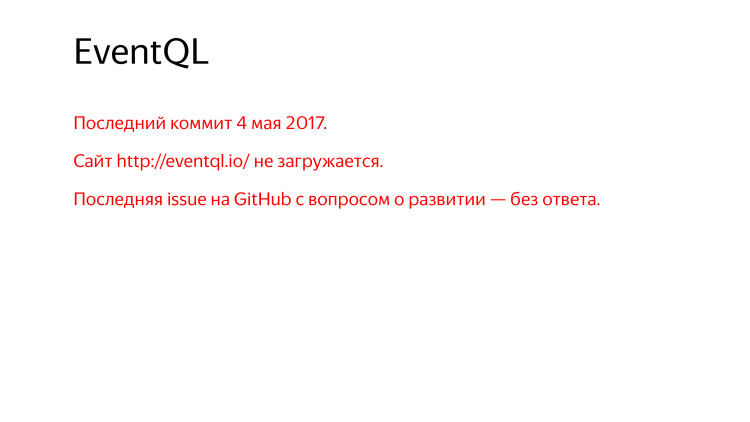
However, the last commit almost a year ago, there is a site that does not load, you have to look through web.archive.org.
Asking for GitHub - what are your plans for development, what will happen next? No one answered.
The system has two developers. One is the backend developer, the second is the frontend. I will not show which of them who, perhaps, will guess themselves. Made in the company DeepCortex. The name seems familiar, but there are many companies with the word Deep and the word Cortex. DeepCortex is some unknown company from Berlin. The system has been developed since 2014, has been developed for quite a long time inside, then it was released into the open source and abandoned a year later.

It looks like this: they threw her into the air and thought that someone might notice her or she would fly away somewhere. Unfortunately not.
Another disadvantage is the AGPL license, which is relatively inconvenient. Even if it does not represent a serious restriction for your company to use, it is still often afraid of it, the legal department may have some points against.
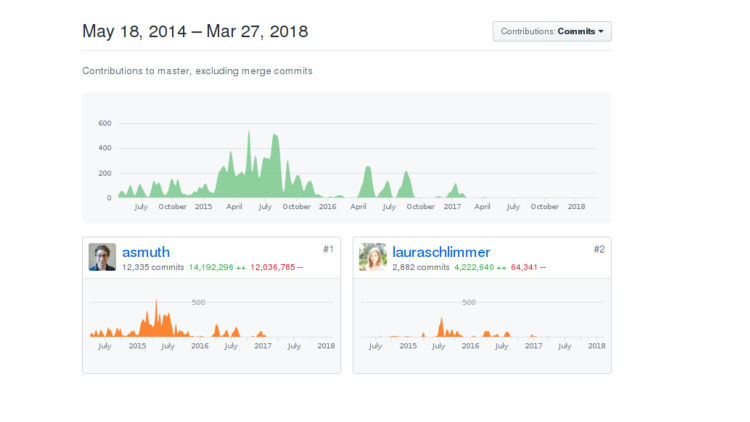
Began to look for what happened, why not developed. I looked at the developer account, in principle, everything is fine, the person lives, continues to commit, however, all commits to a private repository. It is not clear what happened.

Either the person moved to another company and lost interest in support, or the priorities of the company changed, or some life circumstances. Perhaps the company itself was not feeling very bad, and the open source was made just in case. Or just tired. I don’t know the exact answer. If someone knows, please tell me.

But all this was done for a reason. First of all, ChartSQL for the declarative description of graphs. Now something similar is used in the Tabix data visualization system for ClickHouse. EventQL has a blog, however, it is currently unavailable, you have to look through web.archive.org, there are .txt files. The system is implemented very competently, and if you are interested, it is possible to read the code, see interesting architectural solutions.
About her for now. And the next system wins all that I will consider, because it has the best, the most delicious name. Alenka system.
I wanted to add a photo of chocolate packaging, but I'm afraid there will be copyright issues. What is Alenka?

This is an analytical DBMS that performs queries on graphics accelerators. Open Source, license Apache 2, 1103 stars, written in CUDA, slightly C ++, one developer from Minsk. There is even a JDBC driver. Open Source since 2012. True, from 2016 the system for some reason no longer develops.

This is a personal project, not the property of the company, but a real project of one person. This is such a research prototype for researching how to quickly process data on a GPU. There are interesting tests from Mark Litvinchik, if interested, you can look at the blog. Probably, many have already seen his tests there, that ClickHouse is the fastest.

I have no answer why the system is abandoned, just guesswork. Now the person works in the company nVidia, probably, this is just a coincidence.

This is a great example, because it increases interest, outlook, you can see and understand how you can do, how the system can work on the GPU.
But if you are interested in this topic, there are a bunch of other options. For example, the MapD system.
Who heard about MapD? Insult This is a daring startup that also develops a GPU database. Recently released in open source under the Apache 2 license. I don’t know what it is for, good or vice versa. This startup is so successful that it is uploaded to open-source or vice versa, it will close soon.
There are PGStorm. If you are all versed in PostgreSQL, then you should hear about PGStorm. Also open source, developed by one person. From closed systems there is BrytlytDB, Kinetica and the Russian company Polymatik, which makes the Business Intelligence system. Analytics, visualization and all that. And for data processing can also use graphics accelerators, it may be interesting to see.

Is it possible to do something cooler than a GPU? For example, there was a system that processed data on an FPGA. This is a kickfire company. She delivered her solution in the form of hardware with software right away. True, the company has long been closed, this solution was quite expensive and could not compete with other such cabinets, when a vendor brings you this cabinet, and everything works coolly in a magical way.
Next, there are processors that have instructions for speeding up SQL - SQL in Silicon in the new SPARC processor models. But it is not necessary to think that you write join in Assembler, there is no such thing. There are simple instructions that either do a decompression by some simple algorithms and a little bit of filtering. In principle, it is not only SQL can speed up. For example, in Intel processors, there is an SSE 4.2 instruction set for handling strings. When it appeared somewhere in 2008, there was an article on the Intel site “Using new instructions from Intel processors to speed up XML processing.” It's about the same here. Instructions useful for speeding up the database can also be used.
Another very interesting option is to transfer the task of filtering data in part to the SSD. Now SSDs have become quite powerful, this is a small computer with a controller, and in principle you can load your code into it, if you really try. Your data will be read from the SSD, but immediately filtered and transfer only the necessary data to your program. Very cool, but all this is still at the research stage. Here is an article on the VLDB, read.
Further, a certain ViyaDB.

It was open just a month ago. "Analytical database for unsorted data." Why the "unsorted" rendered in the name, it is not clear why this emphasis. What, in other databases, you can work only with sorted ones?
Everything is fine, the source code on GitHub, Apache 2.0 license, is written in the most modern C ++, everything is great. The developer is one, but nothing.

What I liked most of all, where to take an example, is an excellent launch preparation. Therefore, I am surprised that no one heard. There is a wonderful site, there is documentation, there is an article on Habré, there is an article on Medium, LinkedIn, Hacker News. So what? All this for nothing? You have not seen any of this. They say, Habr is not a cake. Well, maybe, but a great thing.
What is this system?

Data in RAM, the system is working with aggregated data. Continuously pre-aggregation is performed. System for analytical queries. There is some initial support for SQL, but it is just beginning to be developed, initially requests had to be written in some kind of JSON. Of the interesting features that you give her a request, and she writes C ++ code to your request herself, this code is generated, compiled, dynamically loaded and processes your data. How would your request be processed as optimally as possible. Perfectly specialized C ++ code written for your query. There is scaling, and Consul is used for coordination. This is also a plus, as you know, it's cooler than ZooKeeper. Or not. I'm not sure, but it seems so.
Some of the prerequisites from which this system comes are somewhat contradictory. I am a big enthusiast of various technologies, and I don’t want to scold anyone. It's just my opinion, maybe I'm wrong.
The prerequisite is that in order to constantly record new data in the system, including backdating, an hour ago, a day ago, a week’s event. And at the same time immediately drive on these data analytical queries.

The author argues that for this the system must necessarily be in-memory. This is not true. If you are wondering why, you can read the article "The Evolution of Data Structures in Yandex.Metrica." One person in the hall read.
It is not necessary to store data in the RAM. I will not say what to do and what system to install if you are interested in solving this problem.

What good can you learn? An interesting architectural solution is code generation in C ++. If you are interested in this topic, you can pay attention to such a research project DBToaster. Research Institute EPFL, available on GitHub, Apache 2.0. The Scala code, you give a SQL request there, this code generates you C ++ sources, which will read the data from somewhere and process it in the most optimal way. Probably, but not sure.

This is only one approach for code generation, for processing requests. There is an even more popular approach - code generation on LLVM. The bottom line is that your program is dynamically writing code in Assembler. Well, not really, on LLVM. An example is MemSQL. This is originally an OLTP database, but is also a good choice for analytics. Closed, proprietary, C ++ was originally used there for code generation. Then they switched to LLVM. Why? You have written C ++ code, you need to compile it, and it takes precious five seconds. And well, if your requests are more or less the same, you can generate the code once. But when it comes to analytics, you have ad hoc requests there, and it is quite possible that every time they are not only different, but even have a different structure. If code generation on LLVM, milliseconds or tens of milliseconds go there, in different ways, sometimes more.
Another example is Impala. Also uses LLVM. But if we talk about ClickHouse, there is also code generation, but basically ClickHouse relies on vector processing of the request. An interpreter, but which works on arrays, so it works very quickly, like systems like kdb +.
Another interesting example. The best logo in my review.

The first and only relational DBMS, designed specifically for data warehousing and business intelligence. Available on GitHub, Apache 2 license. It used to be the GPL, but it was changed and done right. Written in Java. Last commit six years ago. Initially, the system was developed by the non-profit organization Eigenbase, the organization’s goal was to develop a basis for the most extensible code base for databases, which are not only OLTP, but for example, one for analytics, LucidDB itself, the other StreamBase for processing streaming data.

What was six years ago? Good architecture, well extensible code base, more than one developer. Excellent documentation. Now nothing is loaded, but you can see through WebArchive. Excellent SQL support.

But something is wrong. The idea is good, but it was done by a non-profit organization for some donations, and a couple of startups were there. For some reason, everything bent. They could not find funding, there were no enthusiasts, and all these startups closed long ago.
But not everything is so simple. All this was not in vain.

There is such a framework - Apache Calcite. It is like a front-end for SQL database. It can parse queries, analyze, perform any optimization transformations, draw up a query execution plan, and provide a ready-made JDBC driver.
Imagine that you suddenly woke up, you were in a good mood, and you decided to develop your own relational DBMS. You never know happens. Now you can take Apache Calcite, all you need to do is add data storage, data reading, query processing, replication, fault tolerance, sharding, everything is simple. Apache Calcite is based on the LucidDB codebase, which was so advanced a system that they took the whole frontend from there, which is now used in almost all Apache, Hive, Drill, Samza, Storm and even MapD products, despite the fact that it's written in C ++, somehow hooked this Java code.

All these interesting systems use Apache Calcite.
The next system is InfiniDB. From these names dizzy.

There was a company Calpont, originally InfiniDB a proprietary system, and it was such that sales managers contacted our company and sold us this system. It was interesting to participate in this. They say that analytic DBMS is great, faster than Hadoop, column-oriented, naturally, all queries will work quickly. But then they did not have a cluster, the system did not scale. I say that there is no cluster - we will not be able to buy. I looked, after six months the InfiniDB 4.0 version came out, added integration with Hadoop, scaling, everything is fine.
Half a year has passed, and the source code is available in open source. I then thought about what I was sitting, developing something, I must take it, there is something ready.
Began to watch how you can adapt, use. A year later, the company went bankrupt. But source codes are available.
This is called a posthumous open source. And this is good. If a company starts to feel not very well, it is necessary that at least some legacy remains, so that others can use it.

It was all in vain. Based on the InfiniDB sources, MariaDB now has a table engine called ColumnStore. Essentially, this is InfiniDB. Companies no longer exist, people now work elsewhere, but the legacy remains, and this is wonderful. Everybody knows about MariaDB. If you use it, and you need to fasten a quick analytical column-oriented engine, you can take the ColumnStore. I tell you a secret, this is not the best solution. If you need the best solution, then you know who to go to and what to use.
Another system with the word Infini in the title. They have a strange logo, this line seems to be bent downwards. And another incomprehensible font, for some reason there is no anti-aliasing, as if painted in Paint. And all the letters are big, probably, to scare competitors.

I am an enthusiast of any technology, I am very respectful of any interesting solutions. I do not scoff, do not think.
What was this system like? This is no longer an analytical system, this is OLTP. System for processing transactions on an extreme scale. There is a site, the advantages of this system is that the site is loaded. Because when I look at all the others, I got used to the fact that there will be a parking of domains or something else. Sources are available. Now GPL license. It used to be AGPL, but fortunately, the author quickly changed it. Written in C ++, more than one developer, uploaded to open source in November 2013, and in January 2014 already abandoned. One and a half month. Why? What is the point? Why do so?

OLTP-base with the original support of SQL, a personal project, it is not behind any company. The author himself at Hackers News says that he posted it in the open source hoping to attract enthusiasts who will work on this product.

This hope is always doomed to failure. You have an idea, you are a good fellow, you are an enthusiast. So you do this idea. Hardly anyone else can be inspired by this. Or you will have to try hard to inspire someone. So it is difficult to hope that from nowhere on the other side of the world there will appear a person who will start writing another's code on GitHub.
Secondly, perhaps, just underestimating the complexity. Developing a DBMS is not an adventure for 20 minutes. It is difficult, long, expensive.
This is a very interesting case, many have heard, RethinkDB. This example is not an analytical database, not OLTP, but a document-oriented one.

This system has repeatedly changed the concept. Redesigned. For example, in 2011 it was written that this is the engine for MySQL, which is a hundred times faster on SSD, it was written on the official website. Then it was said that this system with the memcached protocol is also optimized for SSD. And after a while, that this is a database for realtime applications. That is, in order to subscribe to the data and receive updates directly in real time. Say, all sorts of interactive chat rooms, online games. Attempt to find a niche. Document-oriented system, JSON data model. In this regard, this system is often compared with MongoDB. Although it is unfair. What do MongoDB developers who are well behaved think? MongoDB must die. These are not my words, I do not wish anyone harm, so said Oleg from the company PostgreSQL Professional.
And in general, what do such developers think? Mongo - they do everything wrong. They could not properly implement the consensus protocol and even the system does not cope with the task of storing data. It seems to be in the new versions with this better, before it was not particularly.
What is RethinkDB? Replication is done correctly, people implemented the RAFT consensus protocol. The query language is wonderful because it is embedded in the client libraries, and the developers write queries in such a way that they are happy to write queries. Not stupid JSON, but something like LINQ or even more convenient. ReQL query language, written in C ++, which is not surprising, the same Mongo in C ++.

But that's not all. Really cool site. The system has long been developed, much more than one developer, simply super documentation on this system, and most importantly, community support. So good that it is the best example to take an example from. 20938 stars on github. This is already transcendental.

The system is still being developed, but if you look at the commits schedule, it is clear that there was a period when it was being actively developed, and now it has gradually faded. Why? What's wrong?

This is a startup, in 2009 we received investments, further search for a niche, a search for how best to position this product. Unfortunately, the startup did not grow, in 2016 the company closed. The developers went to work at another company, and it would seem, that's all, but no. And this is very good, because the developers were able to create a wonderful community around their system, and thanks to donations they managed to redeem the rights to the RethinkDB product, name, logo and everything else, and transfer them to The Linux Foundation. At the same time changed the license from AGPL to Apache 2, significantly less restrictive. Now the product is completely free, I don’t want to commute.

Development continues, new releases are coming out, and in principle, I recommend, if you are interested, it makes sense to see what it is. The system is wonderful, I really think so.
If you are wondering why the startup has collapsed and why it has ceased to actively develop, that is, a story about mistakes from the founder of the company. This is very valuable, because it’s not me who will speak to you for some fragmentary information, but it’s really written there, which, in the opinion of the company’s founder, mistakes were made.
Moving on. Sometimes it happens that it is not separate database management systems that are no longer relevant, but entire areas. Let's say the direction of XML databases was popular about 15 years ago.
If you open some news site during this time, the mid-2000s, you can see funny quotes. For example, in the future, XML technology will play an increasing role in processing and storing data. Says a top manager of a company that started developing these great databases. This future has already come, and then passed by.

Consider one example, the database management system Sedna. Inborn XML database, developed at the Institute for System Programming of the Russian Academy of Sciences. Do not think that professors with punch cards are walking along dark corridors. For example, one of the main developers of this system is currently working at Yandex. Of course, he is no longer developing this Sedna, everything has long been forgotten, now he is doing one super DBMS, which is just a miracle, everything is done right there and even better. I hope, then this person will tell about it himself.
The last commit in 2013, and is not specifically developed, because it is already irrelevant. XML databases were popular, now unpopular, no one needs.
I could not add a separate section to my report - the DBMS from Konstantin Knizhnik.
Konstantin Knizhnik is the person who should have been included in the Guinness Book of Records as the person who single-handedly developed the largest number of DBMSs. There is a personal site garret.ru, judge for yourself what interesting DBMS. Fully sure that all these systems work reliably. I went to the personal site of this person, everything is perfectly described, documentation, architecture. And there is his personal address and telephone number.

He continues to regularly write new DBMS and engines. 2014 - IMCS, an extension for PostgreSQL, is intended for storing and processing time series. You connect to PostgreSQL, the system is not so well integrated in SQL, available in the form of some table functions, and partly in its own language. But you can write type select, create a time series and the like. Judging by the juz-case, this is for analytics of stock data. I am sure that it is not just so designed, but for real tasks, real customers. And it is very cool when one person can make a specialized system. Wrote, done, and works better than anything else. Specially made what was ordered.
Why does it happen that some open-end products are abandoned? Causes can be classified.

First of all, to whom does this all belong, who did? The first example is the easiest if our open source is a personal project. Everything is simple: tired, changed some circumstances, lost interest. And in the end, how much time you can spend personally on your project. Or just underestimating labor costs.
If a startup is also easy. Received funding, the startup does not grow, the company closes. Could not choose a niche on which to position your product, could not get the next round of investment.
The most frequent example is a third-party company product. The company is not engaged exclusively in what makes this open source product. She does something else, but as a bonus - here you are, we have laid out, do something about it.
There may have been several developers or even one inside the company, but he left.
Another example - the company just thinks, why waste resources? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
. . , , . . , XML — - . , XML . , . , , . , . , pull-. — , , , , , . . That's all, thank you.
- My report will be about the database. Let me immediately ask, which city’s metro map is shown on this slide? All lines go one way.
')
Everything is wrong, it is not metropolitan at all, it is a pedigree of relational databases. If you look closely, you will see that the river is the Codda River.
I will not talk about them. What could be more boring than talking about MySQL, PostgreSQL or something like that? Instead, I will talk about craft databases.
Manual assembly. Systems that are almost unknown to anyone. They are either designed by one person or abandoned long ago.
Link from the slide
The first example is EventQL. Please raise your hand if you have ever heard of this system. Not a single person, except those who work at Yandex and have already listened to my report. So, it’s not for nothing that I included this system in my review.
This is a distributed column DBMS designed for event processing and analytics. It performs very fast SQL queries, open source from July 26, 2016, written in C ++, ZooKeeper is used for coordination, except for it there are no dependencies. Something reminds me of it. Our wonderful system, everyone already knows the name. EventQL is like ClickHouse, but better. Distributed, massively parallel, column-oriented, scaled to petabytes, quick range-requests - everything is clear, this is all we have. Almost full support for SQL 2009, realtime inserts and updates, automatic distribution of data across the cluster, and even ChartSQL for describing graphs. So cool! This is what we promise everyone and what we don’t have.
However, the last commit almost a year ago, there is a site that does not load, you have to look through web.archive.org.
Asking for GitHub - what are your plans for development, what will happen next? No one answered.
The system has two developers. One is the backend developer, the second is the frontend. I will not show which of them who, perhaps, will guess themselves. Made in the company DeepCortex. The name seems familiar, but there are many companies with the word Deep and the word Cortex. DeepCortex is some unknown company from Berlin. The system has been developed since 2014, has been developed for quite a long time inside, then it was released into the open source and abandoned a year later.
It looks like this: they threw her into the air and thought that someone might notice her or she would fly away somewhere. Unfortunately not.
Another disadvantage is the AGPL license, which is relatively inconvenient. Even if it does not represent a serious restriction for your company to use, it is still often afraid of it, the legal department may have some points against.
Began to look for what happened, why not developed. I looked at the developer account, in principle, everything is fine, the person lives, continues to commit, however, all commits to a private repository. It is not clear what happened.
Either the person moved to another company and lost interest in support, or the priorities of the company changed, or some life circumstances. Perhaps the company itself was not feeling very bad, and the open source was made just in case. Or just tired. I don’t know the exact answer. If someone knows, please tell me.
But all this was done for a reason. First of all, ChartSQL for the declarative description of graphs. Now something similar is used in the Tabix data visualization system for ClickHouse. EventQL has a blog, however, it is currently unavailable, you have to look through web.archive.org, there are .txt files. The system is implemented very competently, and if you are interested, it is possible to read the code, see interesting architectural solutions.
About her for now. And the next system wins all that I will consider, because it has the best, the most delicious name. Alenka system.
I wanted to add a photo of chocolate packaging, but I'm afraid there will be copyright issues. What is Alenka?
Link from the slide
This is an analytical DBMS that performs queries on graphics accelerators. Open Source, license Apache 2, 1103 stars, written in CUDA, slightly C ++, one developer from Minsk. There is even a JDBC driver. Open Source since 2012. True, from 2016 the system for some reason no longer develops.
Link from the slide
This is a personal project, not the property of the company, but a real project of one person. This is such a research prototype for researching how to quickly process data on a GPU. There are interesting tests from Mark Litvinchik, if interested, you can look at the blog. Probably, many have already seen his tests there, that ClickHouse is the fastest.
I have no answer why the system is abandoned, just guesswork. Now the person works in the company nVidia, probably, this is just a coincidence.
This is a great example, because it increases interest, outlook, you can see and understand how you can do, how the system can work on the GPU.
But if you are interested in this topic, there are a bunch of other options. For example, the MapD system.
Who heard about MapD? Insult This is a daring startup that also develops a GPU database. Recently released in open source under the Apache 2 license. I don’t know what it is for, good or vice versa. This startup is so successful that it is uploaded to open-source or vice versa, it will close soon.
There are PGStorm. If you are all versed in PostgreSQL, then you should hear about PGStorm. Also open source, developed by one person. From closed systems there is BrytlytDB, Kinetica and the Russian company Polymatik, which makes the Business Intelligence system. Analytics, visualization and all that. And for data processing can also use graphics accelerators, it may be interesting to see.
Link from the slide
Is it possible to do something cooler than a GPU? For example, there was a system that processed data on an FPGA. This is a kickfire company. She delivered her solution in the form of hardware with software right away. True, the company has long been closed, this solution was quite expensive and could not compete with other such cabinets, when a vendor brings you this cabinet, and everything works coolly in a magical way.
Next, there are processors that have instructions for speeding up SQL - SQL in Silicon in the new SPARC processor models. But it is not necessary to think that you write join in Assembler, there is no such thing. There are simple instructions that either do a decompression by some simple algorithms and a little bit of filtering. In principle, it is not only SQL can speed up. For example, in Intel processors, there is an SSE 4.2 instruction set for handling strings. When it appeared somewhere in 2008, there was an article on the Intel site “Using new instructions from Intel processors to speed up XML processing.” It's about the same here. Instructions useful for speeding up the database can also be used.
Another very interesting option is to transfer the task of filtering data in part to the SSD. Now SSDs have become quite powerful, this is a small computer with a controller, and in principle you can load your code into it, if you really try. Your data will be read from the SSD, but immediately filtered and transfer only the necessary data to your program. Very cool, but all this is still at the research stage. Here is an article on the VLDB, read.
Further, a certain ViyaDB.
Link from the slide
It was open just a month ago. "Analytical database for unsorted data." Why the "unsorted" rendered in the name, it is not clear why this emphasis. What, in other databases, you can work only with sorted ones?
Everything is fine, the source code on GitHub, Apache 2.0 license, is written in the most modern C ++, everything is great. The developer is one, but nothing.
Links from the slide: to the site and to Habr
What I liked most of all, where to take an example, is an excellent launch preparation. Therefore, I am surprised that no one heard. There is a wonderful site, there is documentation, there is an article on Habré, there is an article on Medium, LinkedIn, Hacker News. So what? All this for nothing? You have not seen any of this. They say, Habr is not a cake. Well, maybe, but a great thing.
What is this system?
Data in RAM, the system is working with aggregated data. Continuously pre-aggregation is performed. System for analytical queries. There is some initial support for SQL, but it is just beginning to be developed, initially requests had to be written in some kind of JSON. Of the interesting features that you give her a request, and she writes C ++ code to your request herself, this code is generated, compiled, dynamically loaded and processes your data. How would your request be processed as optimally as possible. Perfectly specialized C ++ code written for your query. There is scaling, and Consul is used for coordination. This is also a plus, as you know, it's cooler than ZooKeeper. Or not. I'm not sure, but it seems so.
Some of the prerequisites from which this system comes are somewhat contradictory. I am a big enthusiast of various technologies, and I don’t want to scold anyone. It's just my opinion, maybe I'm wrong.
The prerequisite is that in order to constantly record new data in the system, including backdating, an hour ago, a day ago, a week’s event. And at the same time immediately drive on these data analytical queries.
Link from the slide
The author argues that for this the system must necessarily be in-memory. This is not true. If you are wondering why, you can read the article "The Evolution of Data Structures in Yandex.Metrica." One person in the hall read.
It is not necessary to store data in the RAM. I will not say what to do and what system to install if you are interested in solving this problem.
Link from the slide
What good can you learn? An interesting architectural solution is code generation in C ++. If you are interested in this topic, you can pay attention to such a research project DBToaster. Research Institute EPFL, available on GitHub, Apache 2.0. The Scala code, you give a SQL request there, this code generates you C ++ sources, which will read the data from somewhere and process it in the most optimal way. Probably, but not sure.
Link from the slide
This is only one approach for code generation, for processing requests. There is an even more popular approach - code generation on LLVM. The bottom line is that your program is dynamically writing code in Assembler. Well, not really, on LLVM. An example is MemSQL. This is originally an OLTP database, but is also a good choice for analytics. Closed, proprietary, C ++ was originally used there for code generation. Then they switched to LLVM. Why? You have written C ++ code, you need to compile it, and it takes precious five seconds. And well, if your requests are more or less the same, you can generate the code once. But when it comes to analytics, you have ad hoc requests there, and it is quite possible that every time they are not only different, but even have a different structure. If code generation on LLVM, milliseconds or tens of milliseconds go there, in different ways, sometimes more.
Another example is Impala. Also uses LLVM. But if we talk about ClickHouse, there is also code generation, but basically ClickHouse relies on vector processing of the request. An interpreter, but which works on arrays, so it works very quickly, like systems like kdb +.
Another interesting example. The best logo in my review.
Link from the slide
The first and only relational DBMS, designed specifically for data warehousing and business intelligence. Available on GitHub, Apache 2 license. It used to be the GPL, but it was changed and done right. Written in Java. Last commit six years ago. Initially, the system was developed by the non-profit organization Eigenbase, the organization’s goal was to develop a basis for the most extensible code base for databases, which are not only OLTP, but for example, one for analytics, LucidDB itself, the other StreamBase for processing streaming data.
What was six years ago? Good architecture, well extensible code base, more than one developer. Excellent documentation. Now nothing is loaded, but you can see through WebArchive. Excellent SQL support.
But something is wrong. The idea is good, but it was done by a non-profit organization for some donations, and a couple of startups were there. For some reason, everything bent. They could not find funding, there were no enthusiasts, and all these startups closed long ago.
But not everything is so simple. All this was not in vain.
Link from the slide
There is such a framework - Apache Calcite. It is like a front-end for SQL database. It can parse queries, analyze, perform any optimization transformations, draw up a query execution plan, and provide a ready-made JDBC driver.
Imagine that you suddenly woke up, you were in a good mood, and you decided to develop your own relational DBMS. You never know happens. Now you can take Apache Calcite, all you need to do is add data storage, data reading, query processing, replication, fault tolerance, sharding, everything is simple. Apache Calcite is based on the LucidDB codebase, which was so advanced a system that they took the whole frontend from there, which is now used in almost all Apache, Hive, Drill, Samza, Storm and even MapD products, despite the fact that it's written in C ++, somehow hooked this Java code.
All these interesting systems use Apache Calcite.
The next system is InfiniDB. From these names dizzy.
Link from the slide
There was a company Calpont, originally InfiniDB a proprietary system, and it was such that sales managers contacted our company and sold us this system. It was interesting to participate in this. They say that analytic DBMS is great, faster than Hadoop, column-oriented, naturally, all queries will work quickly. But then they did not have a cluster, the system did not scale. I say that there is no cluster - we will not be able to buy. I looked, after six months the InfiniDB 4.0 version came out, added integration with Hadoop, scaling, everything is fine.
Half a year has passed, and the source code is available in open source. I then thought about what I was sitting, developing something, I must take it, there is something ready.
Began to watch how you can adapt, use. A year later, the company went bankrupt. But source codes are available.
This is called a posthumous open source. And this is good. If a company starts to feel not very well, it is necessary that at least some legacy remains, so that others can use it.
Link from the slide
It was all in vain. Based on the InfiniDB sources, MariaDB now has a table engine called ColumnStore. Essentially, this is InfiniDB. Companies no longer exist, people now work elsewhere, but the legacy remains, and this is wonderful. Everybody knows about MariaDB. If you use it, and you need to fasten a quick analytical column-oriented engine, you can take the ColumnStore. I tell you a secret, this is not the best solution. If you need the best solution, then you know who to go to and what to use.
Another system with the word Infini in the title. They have a strange logo, this line seems to be bent downwards. And another incomprehensible font, for some reason there is no anti-aliasing, as if painted in Paint. And all the letters are big, probably, to scare competitors.
Links from the slide: to the website , to GitHib
I am an enthusiast of any technology, I am very respectful of any interesting solutions. I do not scoff, do not think.
What was this system like? This is no longer an analytical system, this is OLTP. System for processing transactions on an extreme scale. There is a site, the advantages of this system is that the site is loaded. Because when I look at all the others, I got used to the fact that there will be a parking of domains or something else. Sources are available. Now GPL license. It used to be AGPL, but fortunately, the author quickly changed it. Written in C ++, more than one developer, uploaded to open source in November 2013, and in January 2014 already abandoned. One and a half month. Why? What is the point? Why do so?
OLTP-base with the original support of SQL, a personal project, it is not behind any company. The author himself at Hackers News says that he posted it in the open source hoping to attract enthusiasts who will work on this product.
This hope is always doomed to failure. You have an idea, you are a good fellow, you are an enthusiast. So you do this idea. Hardly anyone else can be inspired by this. Or you will have to try hard to inspire someone. So it is difficult to hope that from nowhere on the other side of the world there will appear a person who will start writing another's code on GitHub.
Secondly, perhaps, just underestimating the complexity. Developing a DBMS is not an adventure for 20 minutes. It is difficult, long, expensive.
This is a very interesting case, many have heard, RethinkDB. This example is not an analytical database, not OLTP, but a document-oriented one.
This system has repeatedly changed the concept. Redesigned. For example, in 2011 it was written that this is the engine for MySQL, which is a hundred times faster on SSD, it was written on the official website. Then it was said that this system with the memcached protocol is also optimized for SSD. And after a while, that this is a database for realtime applications. That is, in order to subscribe to the data and receive updates directly in real time. Say, all sorts of interactive chat rooms, online games. Attempt to find a niche. Document-oriented system, JSON data model. In this regard, this system is often compared with MongoDB. Although it is unfair. What do MongoDB developers who are well behaved think? MongoDB must die. These are not my words, I do not wish anyone harm, so said Oleg from the company PostgreSQL Professional.
And in general, what do such developers think? Mongo - they do everything wrong. They could not properly implement the consensus protocol and even the system does not cope with the task of storing data. It seems to be in the new versions with this better, before it was not particularly.
What is RethinkDB? Replication is done correctly, people implemented the RAFT consensus protocol. The query language is wonderful because it is embedded in the client libraries, and the developers write queries in such a way that they are happy to write queries. Not stupid JSON, but something like LINQ or even more convenient. ReQL query language, written in C ++, which is not surprising, the same Mongo in C ++.
Links from the slide: to the website , to GitHib
But that's not all. Really cool site. The system has long been developed, much more than one developer, simply super documentation on this system, and most importantly, community support. So good that it is the best example to take an example from. 20938 stars on github. This is already transcendental.
The system is still being developed, but if you look at the commits schedule, it is clear that there was a period when it was being actively developed, and now it has gradually faded. Why? What's wrong?
This is a startup, in 2009 we received investments, further search for a niche, a search for how best to position this product. Unfortunately, the startup did not grow, in 2016 the company closed. The developers went to work at another company, and it would seem, that's all, but no. And this is very good, because the developers were able to create a wonderful community around their system, and thanks to donations they managed to redeem the rights to the RethinkDB product, name, logo and everything else, and transfer them to The Linux Foundation. At the same time changed the license from AGPL to Apache 2, significantly less restrictive. Now the product is completely free, I don’t want to commute.
Link from the slide
Development continues, new releases are coming out, and in principle, I recommend, if you are interested, it makes sense to see what it is. The system is wonderful, I really think so.
If you are wondering why the startup has collapsed and why it has ceased to actively develop, that is, a story about mistakes from the founder of the company. This is very valuable, because it’s not me who will speak to you for some fragmentary information, but it’s really written there, which, in the opinion of the company’s founder, mistakes were made.
Moving on. Sometimes it happens that it is not separate database management systems that are no longer relevant, but entire areas. Let's say the direction of XML databases was popular about 15 years ago.
If you open some news site during this time, the mid-2000s, you can see funny quotes. For example, in the future, XML technology will play an increasing role in processing and storing data. Says a top manager of a company that started developing these great databases. This future has already come, and then passed by.
Links from the slide: to the website , on GitHub
Consider one example, the database management system Sedna. Inborn XML database, developed at the Institute for System Programming of the Russian Academy of Sciences. Do not think that professors with punch cards are walking along dark corridors. For example, one of the main developers of this system is currently working at Yandex. Of course, he is no longer developing this Sedna, everything has long been forgotten, now he is doing one super DBMS, which is just a miracle, everything is done right there and even better. I hope, then this person will tell about it himself.
The last commit in 2013, and is not specifically developed, because it is already irrelevant. XML databases were popular, now unpopular, no one needs.
I could not add a separate section to my report - the DBMS from Konstantin Knizhnik.
Link from the slide
Konstantin Knizhnik is the person who should have been included in the Guinness Book of Records as the person who single-handedly developed the largest number of DBMSs. There is a personal site garret.ru, judge for yourself what interesting DBMS. Fully sure that all these systems work reliably. I went to the personal site of this person, everything is perfectly described, documentation, architecture. And there is his personal address and telephone number.
Link from the slide
He continues to regularly write new DBMS and engines. 2014 - IMCS, an extension for PostgreSQL, is intended for storing and processing time series. You connect to PostgreSQL, the system is not so well integrated in SQL, available in the form of some table functions, and partly in its own language. But you can write type select, create a time series and the like. Judging by the juz-case, this is for analytics of stock data. I am sure that it is not just so designed, but for real tasks, real customers. And it is very cool when one person can make a specialized system. Wrote, done, and works better than anything else. Specially made what was ordered.
Why does it happen that some open-end products are abandoned? Causes can be classified.
First of all, to whom does this all belong, who did? The first example is the easiest if our open source is a personal project. Everything is simple: tired, changed some circumstances, lost interest. And in the end, how much time you can spend personally on your project. Or just underestimating labor costs.
If a startup is also easy. Received funding, the startup does not grow, the company closes. Could not choose a niche on which to position your product, could not get the next round of investment.
The most frequent example is a third-party company product. The company is not engaged exclusively in what makes this open source product. She does something else, but as a bonus - here you are, we have laid out, do something about it.
There may have been several developers or even one inside the company, but he left.
Another example - the company just thinks, why waste resources? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .
, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
. . , , . . , XML — - . , XML . , . , , . , . , pull-. — , , , , , . . That's all, thank you.
Source: https://habr.com/ru/post/423905/
All Articles