When speed and scaling are needed: a server of distributed iOS devices

Many developers of UI tests for iOS probably know the problem of the time of the test run. Badoo runs more than 1,400 end-to-end tests for iOS applications for each regression launch. This is more than 40 machine hours of tests that pass in 30 real minutes.
Nikolay Abalov from Badoo shared how he was able to speed up the execution of tests from 1.5 hours to 30 minutes; how untangled the closely related tests and the iOS infrastructure by going to the device server; how it simplified parallel test runs and made tests and infrastructure easier to maintain and scale.
')
You will learn how to run tests in parallel with tools like fbsimctl and how the separation of tests and infrastructure can simplify the acceptance, support and scaling of your tests.
Initially, Nicholas presented a report at the Heisenbug conference (you can watch the video ), and now for Habr we have made a text version of the report. Next - the story from the first person:
Hello everyone, today I will tell about the scaling of testing under iOS. My name is Nikolai, I'm in Badoo doing mainly iOS infrastructure. Prior to that, he worked for 3 years at 2GIS, worked on development and automation, in particular, he wrote Winium.Mobile - the implementation of WebDriver for Windows Phone. I was taken to Badoo to work on the automation of Windows Phone, but after a while the business decided to halt the development of this platform. And I was offered interesting tasks on iOS automation, and I’ll tell you about it today.
What are we going to talk about? The plan is:
- Informal statement of the problem, introduction to the tools used: how and why.
- Parallel testing on iOS and how it developed (in particular, on the history of our company, since we started doing it back in 2015).
- Device server is the main part of the report. Our new test paralleling model.
- The results we achieved using the server.
- If you do not have 1500 tests, then you may not really need a device server, but you can still pull out interesting things from it, and we’ll talk about them. They can be applied if you have 10-25 tests, and it still gives either acceleration or additional stability.
- And finally, a summary.
Instruments
The first is a little about who uses what. Our stack is a bit non-standard because we both use Calabash and WebDriverAgent at the same time (which gives us speed and Calabash backdoors when automating our application and at the same time full access to the system and other applications via WebDriverAgent). WebDriverAgent is a WebDriver implementation for iOS from Facebook, which is used internally by Appium. And Calabash is an embedded automation server. We write the tests ourselves in a human-readable form using Cucumber. That is, in our company pseudo-BDD. And because we used Cucumber and Calabash, we inherited Ruby, all the code is written in it. There is a lot of code, and you have to continue writing in Ruby. To run tests in parallel, we use parallel_cucumber , a tool written by one of my colleagues in Badoo.
Let's start with what we had. When I started preparing the report, there were 1,200 tests. By the time they were completed, it was 1,300. So far I have arrived here, the tests have already become 1,400. These are end-to-end tests, not unit tests or integration tests. They make up 35-40 hours of computer time on one simulator. They passed earlier in an hour and a half. I'll tell you how they began to take place in 30 minutes.
Our company has a workflow with branches, reviews and tests for these branches. Developers create approximately 10 requests to the main repository of our application. But there are also components in it that shuffle with other applications, so sometimes there are more than ten. As a result, 30 test launches per day, at least. Since the developers are pushing, then they realize that they have started with bugs, perezalivat, and all this starts a complete regression, simply because we can run it. On the same infrastructure, we run additional projects, such as Liveshot, which takes screenshots of the application in the main user scripts in all languages, so that translators can verify the correctness of the translation, whether it is placed on the screen, and so on. As a result, there are about one and a half thousand hours of computer time at the moment.
First of all, we want developers and testers to trust automation and rely on it to reduce manual regression. In order for this to happen, it is necessary to achieve fast and, most importantly, stable and reliable work from automation. If tests pass in an hour and a half, the developer will get tired of waiting for the results, he will start doing another task, his focus will switch. And when some tests fall, he will be very not happy that you have to come back, switch attention and repair something. If the tests are unreliable, then over time people begin to perceive them only as a barrier. They are constantly falling, although there are no bugs in the code. These are Flaky tests, some kind of hindrance. Accordingly, these two points were disclosed in these requirements:
- Tests should take place in 30 minutes or less.
- They must be stable.
- They must be scalable so that we can, by adding another hundred tests, fit in half an hour.
- Infrastructure should be easily maintained and developed.
- On simulators and physical devices, everything should run the same way.
Basically, we are driving tests on simulators, and not on physical devices, because it is faster, more stable and easier. Physical devices are used only for tests that really require it. For example, camera, push notifications and the like.
How to meet these requirements and do everything well? The answer is very simple: we remove two thirds of the tests! This solution fits into 30 minutes (because only a third of the tests remain), scales easily (more tests can be removed), and improves reliability (because first of all we remove the most unreliable tests). I have it all. Questions?
But seriously, in every joke there is some truth. If you have a lot of tests, then you need to revise them and understand what brings real benefits. We had another task, so we decided to see what can be done.
The first approach is filtering tests based on coverage or components. That is, select the appropriate tests based on changes to the files in the application. I will not talk about this, but this is one of the tasks that we are solving at the moment.
Another option is to accelerate and stabilize the tests themselves. You take a specific test, see which steps take the most time in it and whether it is possible to somehow optimize them. If some of them are very often unstable, you rule them, because it reduces the test restarts, and everything goes faster.
And finally, a completely different task - parallelizing tests, distributing them to a large number of simulators and providing a scalable and stable infrastructure so that there is a lot to parallelize.
In this article we’ll talk mainly about the last two points and at the end, at tips & tricks, we’ll touch on the point about speed and stabilization.
Parallel testing for iOS
Let's start with the history of parallel testing for iOS in general and Badoo in particular. For a start, simple arithmetic, here, however, there is an error in the formula, if we compare the dimensions:

There were 1300 tests for one simulator, it turns out 40 hours. Then Satish, my manager, comes in and says that he needs half an hour. It is necessary to invent something. X appears in the formula: how many simulators to run, so that in half an hour everything goes. The answer is 80 simulators. And the question immediately arises, where to put these 80 simulators, because they do not fit anywhere.
There are several options: you can go to clouds like SauceLabs, Xamarin or AWS Device Farm. And you can come up with everything and do it well. Given that this article exists, we did everything right. We decided this because a cloud with such a scale would be quite expensive, and there was a situation when iOS 10 came out and Appium released support for it for almost a month. This means that in SauceLabs we couldn’t automatically test iOS 10 for a month, which didn’t suit us at all. In addition, all clouds are closed, and you can not influence them.
So, we decided to do everything in-house. Began somewhere in 2015, then Xcode could not run more than one simulator. As it turned out, he cannot run more than one simulator under one user on one machine. If you have many users, you can run as many simulators as you want. My colleague Tim Baverstok invented a model on which we lived for a long time.

There is an agent (TeamCity, Jenkins Node and the like), it runs parallel_cucumber, which simply goes to remote machines via ssh. The picture shows two cars for two users. All the necessary test type files are copied and run on remote machines via ssh. And the tests are already running the simulator locally on the current desktop. To make it all work, you had to go to each machine, create, for example, 5 users, if you want 5 simulators, make one user an automatic login, open screensharing for the rest, so that they always have a desktop. And set up an ssh daemon so that it has access to the processes on the desktop. In this simple way we started running tests in parallel. But there are several problems in this picture. First, the tests run the simulator; they are located in the same place as the simulator itself. That is, they must always be run on poppies, they eat up resources that could be spent on running simulators. As a result, you have fewer simulators on the machine and they are more expensive. Another point is that you need to go to each machine, set up users. And then you will simply be buried in the global ulimit. If there are five users and they pick up a lot of processes, then at some point in the system the descriptors will run out. Having reached the limit, the tests will begin to fall when trying to open new files and start new processes.

In 2016-2017, we decided to switch to a slightly different model. We looked at the report of Lawrence Lomax from Facebook - they presented fbsimctl, and partially told how the infrastructure in Facebook works. There was another report by Viktor Koronevich about this model. The picture is not much different from the previous one - we just got rid of users, but this is a big step forward, because now there is only one desktop, fewer processes are running, simulators are cheaper. In this picture there are three simulators, not two, since the resources for the launch of an additional one are freed up. We lived with this model for a very long time, until mid-October 2017, when we began to switch to our server of remote devices.

It looked like iron. On the left is a box with macbooks. Why we all ran tests on them - this is a separate big story. It was not a good idea to run tests on macbooks that we inserted into the iron box, because they started to overheat somewhere for dinner, because of them the heat doesn’t go well when they lie on the surface. Tests became unstable, especially simulators began to fall when loading.
We decided this is simple: put the laptops "tents", the area of the air flow increased and the stability of the infrastructure unexpectedly increased.

So sometimes you do not have to deal with software, but go around turning laptops.
But if you look at this picture, there is some kind of mash from wires, adapters and generally tin. This is an iron part, and it was still good. In the software, however, a complete interweaving of tests with the infrastructure was going on, and it was impossible to live like this anymore.
We identified the following issues:
- The fact that the tests were closely related to the infrastructure, running simulators and managed their entire life cycle.
- This led to the difficulty of scaling, since the addition of a new node meant setting it up for tests and for running simulators. For example, if you wanted to update Xcode, you had to add workaround directly to the tests, because they run on different versions of Xcode. There are some heaps if to start the simulator.
- Tests are tied to the machine where the simulator is located, and it costs a lot of money, since they have to be run on poppies instead of * nix, which are cheaper.
- And it was always very easy to dig inside the simulator. In some tests we went to the file system of the simulator, deleted some files there or modified them, and everything was fine until it was done in three different ways in three different tests, and then the fourth suddenly started to fall if it was not lucky to start after those three.
- And the last moment - the resources did not rummage. There were, for example, four TeamCity agent, five machines were connected to each, and it was possible to run tests only on their five machines. There was no centralized resource management system, because of this, when only one task arrives, it went on five machines, and all 15 others were idle. Because of this, builds went on for a very long time.
New model
We decided to switch to a beautiful new model.

Removed all the tests on one machine, where TeamCity agent. This machine can now be on * nix or even on Windows, if you so wanted. They will communicate over HTTP with some thing we call device server. All simulators and physical devices will be somewhere there, and the tests will be run here, request the device via HTTP and continue to work with it. The scheme is very simple, just two elements in the diagram.

In reality, of course, behind the server was ssh and so on. But now it does not bother anyone, because the guys writing tests in this scheme are at the top, and they have some specific interface for working with a local or remote simulator, so they are fine. And now I work lower, and everything is as it was for me. Have to live with it.
What does this give?
- First, the division of responsibility. At some point in the automation of testing should be considered as a normal development. It employs the same principles and approaches that developers use.
- It turned out to be a strictly defined interface: you cannot do something directly with the simulator, for this you need to open a ticket in the device server, and we will figure out how to do it optimally, without breaking other tests.
- The test environment has become cheaper, because we raised it to * nix, which is much cheaper than poppies to maintain.
- And there was a sharing of resources, because there is a single layer with which everyone communicates, she can plan the distribution of machines behind her, i.e. resource sharing between agents.
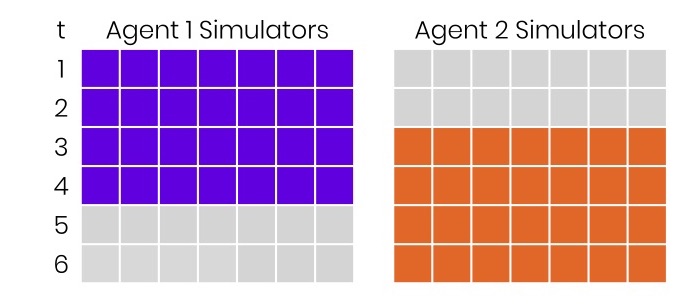
Above is shown as it was before. On the left, the conventional units of time, say, tens of minutes. There are two agents, 7 simulators are connected to each, at time 0 the build comes and takes 40 minutes. After 20 minutes, another one arrives, and it takes the same time. Everything seems fine. But there, and there are gray squares. They mean that we have lost money because we did not use the available resources.
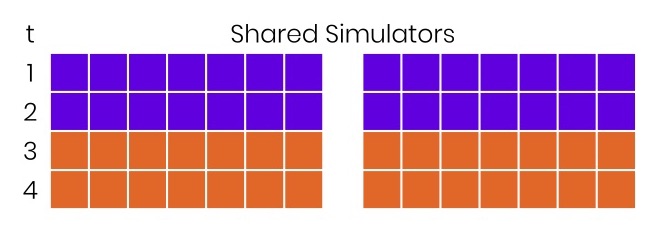
You can do this: the first build comes and sees all the free simulators, is distributed, and the tests are accelerated twice. To do this, nothing had to be done. In reality, this often happens because developers rarely push their brunch at the same moment. Although sometimes this happens, and begin "checkers", "pyramids" and the like. However, in most cases, free acceleration twice as much can be obtained by simply putting a centralized system for managing all resources.
Other reasons to go to this:
- Black boxing, that is, now the device server is a black box. When you write tests, you think only about tests and you think that this black box will always work. If it does not work, you just go and knock on the person who should do it, that is, me. And I have to repair it. Not only me, in fact, several people are involved in the entire infrastructure.
- There is no way to spoil the insides of the simulator.
- No need to put a million utilities on the machine so that everything starts up - you just put one utility hiding all the work in the device server.
- It has become easier to update the infrastructure, as we will talk about somewhere in the end.
Reasonable question: why not Selenium Grid? First, we had a lot of legacy code, 1500 tests, 130 thousand lines of code for different platforms. And all this was controlled by parallel_cucumber, which created the simulator life cycle outside the test. That is, there was a special system that loaded the simulator, waited for it to be fully ready and gave it to the test. In order not to rewrite everything, we decided to try not to use the Selenium Grid.
We also have a lot of non-standard actions, and we rarely use WebDriver. The main part of the tests on Calabash, and WebDriver only auxiliary. That is, we do not use Selenium in most cases.
And, of course, we wanted everything to be flexible, easy to prototype. Because the whole project began simply with an idea that we decided to test, implemented in a month, everything started, and it became the main decision in our company. By the way, at first we wrote Ruby, and then rewrote the device server to Kotlin. Tests appeared on Ruby, and the server on Kotlin.
Device server
Now more about the device server itself, how it works. When we first began to investigate this question, we used the following tools:
- xcrun simctl and fbsimctl - command line utilities for managing simulators (the first is officially from Apple, the second from Facebook, it is a bit more convenient to use)
- WebDriverAgent, also from Facebook, in order to drive applications out of the process, when a push notification or something like that comes
- ideviceinstaller, to put the application on physical devices and then somehow automate on the device.
By the time we started writing the device server, we searched. It turns out that by that time, fbsimctl already knew how to do everything that xcrun simctl and ideviceinstaller could do, so we just threw them out, leaving only fbsimctl and WebDriverAgent. This is already some kind of simplification. Then we thought: why do we need to write something, surely Facebook is already ready. And indeed, fbsimctl can work as a server. You can run it like this:

This will raise the simulator and start the server that will listen to the commands.

When you stop the server, it will automatically shut down the simulator.
What commands can I send? For example, use curl to send a list, and it will display full information about this device:

And this is all in JSON, that is, it is easy to parse from the code, and it is easy to work with. They have implemented a huge pile of commands that allows you to do anything with a simulator.

For example, approve is to give permission to use the camera, location and notification. The open command allows you to open deep links in the application. It would seem that you can not write anything, but take fbsimctl. But it turned out that there are not enough such teams:

It is easy to guess here that without them you will not be able to launch a new simulator. That is, someone must go to the car in advance and lift the simulator. And most importantly: you can not run tests on the simulator. Without these commands, the server cannot be used remotely, so we decided to create a complete list of additional requirements that we need.
- The first is the creation and loading of simulators on demand. That is, liveshot'y can at any time ask for the iPhone X, and then the iPhone 5S, but most of the tests will run on the iPhone 6s. We must be able to create the required number of simulators of each type on demand.
- We also need to somehow be able to run WebDriverAgent or other XCUI tests on simulators or physical devices in order to drive the automation itself.
- And we wanted to completely hide the satisfaction of the requirements. If your tests want to test something on iOS 8 for backward compatibility, then they do not need to know which machine to follow. They simply ask the device server for iOS 8, and if there is such a machine, it will find it, somehow prepare and return the device from this machine. This was not in the fbsimctl.
- Finally, these are various additional actions like deleting cookies in tests, which allows you to save a whole minute in each test, and other various tricks, which we'll talk about at the very end.
- And the last moment is a pooling simulator. We had an idea that since the device server now lives separately from the tests, it is possible to start all simulators at the same time in advance, and when the tests come, the simulator will be ready to start working immediately, and we will save time. As a result, we have not done it, because the download of simulators has already been very fast. And this, too, will be at the very end, these are the spoilers.

The picture is just an example of the interface, we wrote some kind of wrapper, a client for working with this remote device. Here, the dots are different facebook methods that we just duplicated. Everything else is its own methods, for example, fast resetting the device, cleaning the cookies and obtaining various diagnostics.

The whole scheme looks like this: there is a Test Runner that will run the tests and prepare the environment; there is a Device Provider, a client to the Device Server, to request devices from it; Remote Device is a wrapper over a remote device; Device Server - the device server itself. Everything behind it is hidden from the tests, there are some background threads for cleaning the disk and performing other important actions and fbsimctl with WebDriverAgent.
How does all this work? From the tests or from Test Runner we request a device with a specific capability, for example, iPhone 6. The request goes to Device Provider, and it sends the device server, which finds the suitable machine, runs the background-thread on it to prepare the simulator and immediately returns some reference , token, promise that in the future the device will be created and loaded. By this token you can go to the Device Server and ask for the device. This token is turned into an instance of the RemoteDevice class and it will be possible to work with it in tests.
All this happens almost instantly, and in the background the simulator starts loading in parallel with fbsimctl. Now we, for example, ship simulators in headless mode. If anyone remembers the first picture with the iron, one could see a lot of simulator windows on it, before we loaded them not in a headless mode. They are somehow loaded, you will not even see anything. We just wait until the simulator is fully loaded, for example, a record about SpringBoard and other heuristics appears in the syslog to determine the readiness of the simulator.
As soon as it is loaded, we launch XCTest, which will actually raise the WebDriverAgent, and we will start to ask him healthCheck, because WebDriverAgent does not sometimes rise, especially if the system is very heavy. In parallel, at this time, a cycle is started, waiting for the device “ready” state. This is actually the same healthCheck. Once the device is fully loaded and ready for testing, you exit the loop.
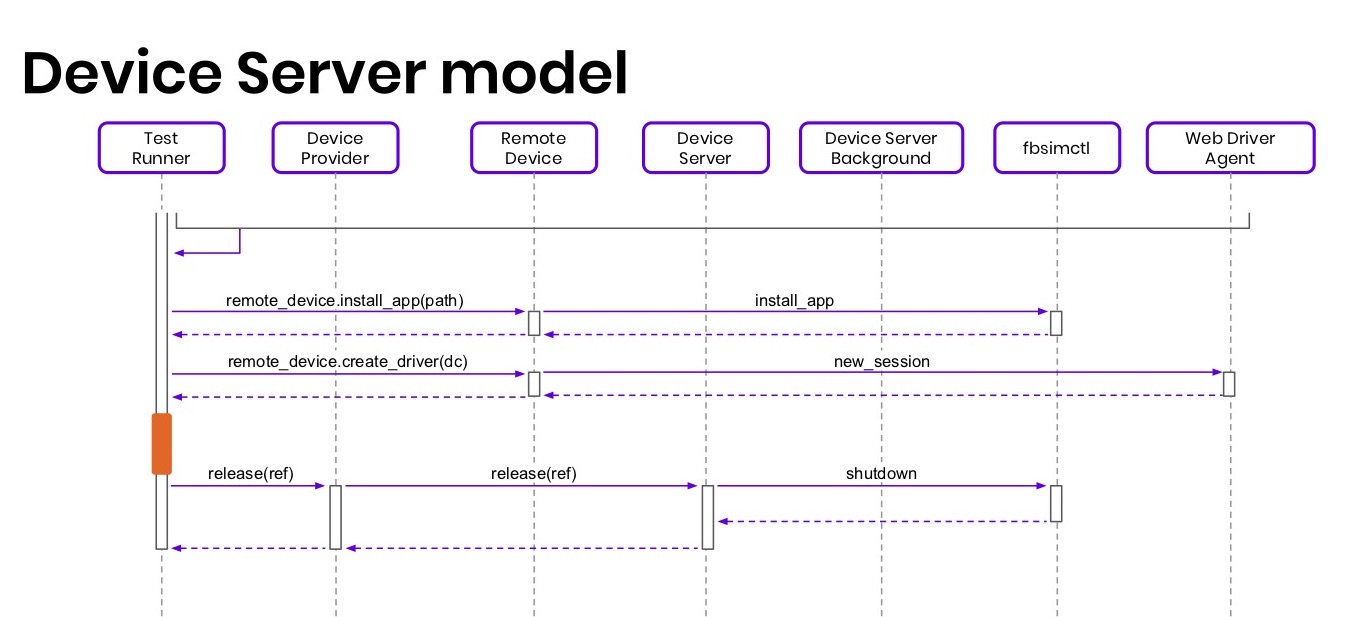
Now you can put an application on it just by sending a request to fbsimctl. It's all elementary. You can still create a driver, the request is proxied to WebDriverAgent, and creates a session. After that, you can run tests.
Tests are such a small part of this whole scheme, in them you can continue to communicate with the device server to perform actions like removing cookies, receiving video, starting a recording, and so on. In the end, you need to release the device (release), it ends, it clears all the resources, resets the cache and the like. Actually release the device is optional. It is clear that the device server itself does this, because sometimes tests fail along with Test Runner and do not explicitly release devices. This scheme is significantly simplified, it does not have many items and background-works that we perform so that the server can work for a whole month without any problems and reloads.
Results and Next Steps
The most interesting part is the results. They are simple. From 30 machines switched to 60. These are virtual machines, not physical machines. Most importantly, we reduced the time from one and a half hours to 30 minutes. And then the question arises: if the machines became twice as large, then why did the time decrease three times?
In fact, everything is simple. I showed a picture about sharing of resources - this is the first reason. He gave an extra boost in speed in most cases when developers have started tasks at different times.
The second point is the separation of tests and infrastructure. After that, we finally understood how everything works, and were able to optimize each of the parts separately and add another slight acceleration to the system. Separation of Concerns is a very important idea, because when everything is intertwined, it becomes impossible to fully embrace the system.
It has become easier to make updates. For example, when I first came to the company, we upgraded to Xcode 9, which took more than a week with that small number of machines. Xcode 9.2, , — . , - .
Test Runner, rsync, ssh . - *nix, Docker-.
: device server ( GitHub ) , ssh, . device server, ssh, .
Tips & tricks
— , , device server .
— . , MacBook Pro, . Mac Pro.

. . 6 . , - , , . Mac Pro 18 — , 4 12 . — 18 . , - , , , . 18 , .

. , , , . MacBook Pro £400, Mac Pro £330. £70 .
, , , , . , Ethernet, Wi-Fi , . £30, 6, £5 . , -, 20 5 , MacBook, , Mac Pro . , , , - . Mac Pro , , .
Mac Pro . , ESXi. bare metal-, , , . , . macOS - , Parallels, 2 - Apple. , CoreSimulator, , , , 6 , - , 18 . , ESXi £0, , - , .
pooling? , . , , , - . — (shutdown) , (erase) (boot).

, , 18 . . Apple, , . backup. , , .

8 : . , Ruby- . , .
. Bumble, Badoo, , . Facebook. , , . WebDriverAgent Safari, Facebook, Sign out. , . . .
, Facebook A/B-, , . , . fbsimctl list_apps, .
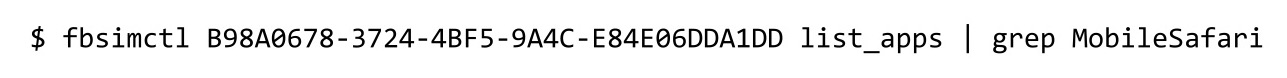
MobileSafari:

DataContainer, :

— 20 . 100 , , - Facebook. . , 100 , . .
: .

, Appium, — . , . Appium . , - . , .

, . , . LocationMode 3101. ? Apple, - . , , . , -, fbsimctl . , , -.

— Chrome, , . . , , . , headless. , . , .

, -. SlowMotionAnimation, . , . , . , Chrome, cmd+T, . . cmd+T — 10 . , , , .
, , , — . 60 ( 64 + 6 TeamCity agents) . xcversion — fastlane, gem Ruby, : Xcode. Ansible, playbooks, fbsimctl , Xcode device server. Ansible . iOS 11, iOS 10. , iOS 10, Ansible . .

How it works? xcversion 60 , , Apple . , , , xcversion install Xcode, . . . ~/Library/Caches/XcodeInstall. Ceph, , - web- . Python, HTTP-.

xcversion install . xip ( , ), , — , . Xcode, . , , curl wget, , xcversion simulators --install. Ansible- 60 . . , , . Ansible , .
. : , . , . , , , , , . .
: — , , , . , , , .
: , , - . , , cookies. , 100 , . .
, Heisenbug, Heisenbug : 6-7 , (, , ).
Source: https://habr.com/ru/post/423901/
All Articles