What's inside XGBoost, and where does Go
In the world of machine learning, one of the most popular types of models is a decisive tree and ensembles based on them. The advantages of trees are: simplicity of interpretation, no restrictions on the type of initial dependence, soft requirements for the sample size. Trees have a major drawback - a tendency to retrain. Therefore, almost always trees are combined into ensembles: a random forest, gradient boosting, etc. The complex theoretical and practical tasks are the compilation of trees and their unification into ensembles.
In this article, we will consider the procedure for the formation of predictions on the already trained model of an ensemble of trees, the features of implementations in the popular libraries of gradient boosting
Consider first the general provisions. Usually work with trees, where:
I took this illustration from the XGBoost documentation
')
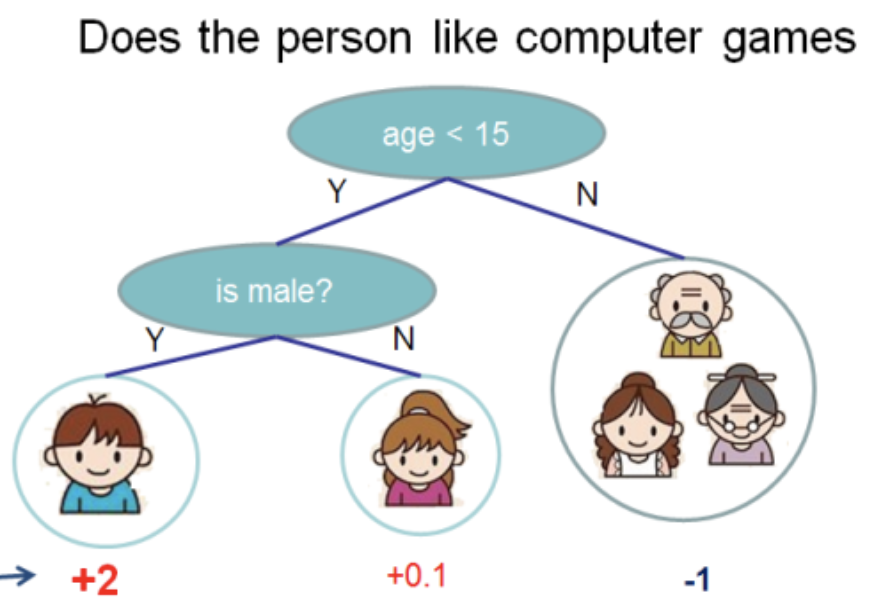
In this tree we have 2 nodes, 2 decision rules and 3 leaves. Below the circles are the values - the result of applying the tree to an object. Usually, a transformation function is applied to the result of computing a tree or ensemble of trees. For example, sigmoid for a binary classification problem.
To obtain predictions from an ensemble of trees obtained by the gradient boosting method, you need to add up the results of the predictions of all the trees:
Hereinafter there will be
Next, consider what is hidden in
In
The
Two things follow from here:
The centerpiece is the
The following features can be distinguished:
In order to be able to trace the path from calling the
In the
LightGBM has no node data structure. Instead, the tree data structure (file
Consider the decision rule for a categorical trait:
It can be seen that, depending on the
i.e., for example, for the categorical feature
This approach has one major drawback: if the categorical feature can take large values, for example 100,500, then a bit field of up to 12,564 bytes in size will be created for each decision rule!
Therefore, it is advisable to renumber the values of the categorical attributes so that they go continuously from 0 to the maximum value .
For my part, I made
Working with real signs is not much different from
For writing a loaded backend service,
So I decided to write a library on pure

The main features of the library:
I will give here a minimal program on
The library API is minimalistic. To use the
Despite the fact that the
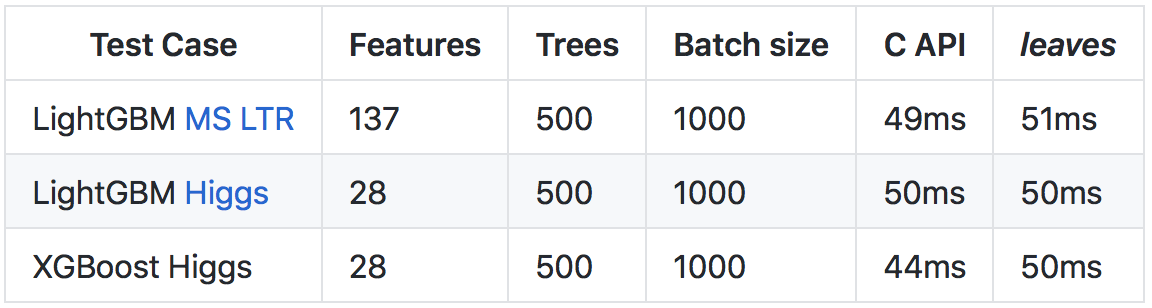
More details about the results and the way of comparisons are in the repository on github .
I hope this article I opened the door in the implementation of trees in the libraries
For those who are interested in the topic of using gradient boosting models in their services in the Go language, I recommend you to get acquainted with the leaves library. With the help of
Successes!
In this article, we will consider the procedure for the formation of predictions on the already trained model of an ensemble of trees, the features of implementations in the popular libraries of gradient boosting
XGBoost and LightGBM . As well as the reader will get acquainted with the leaves library for Go, which allows you to make predictions for tree ensembles, without using the original libraries C API.Where do trees grow from?
Consider first the general provisions. Usually work with trees, where:
- splitting in a node occurs by one attribute
- tree is binary - each node has a left and right descendant
- in the case of a real attribute, the decision rule consists of comparing the characteristic value with a threshold value
I took this illustration from the XGBoost documentation
')
In this tree we have 2 nodes, 2 decision rules and 3 leaves. Below the circles are the values - the result of applying the tree to an object. Usually, a transformation function is applied to the result of computing a tree or ensemble of trees. For example, sigmoid for a binary classification problem.
To obtain predictions from an ensemble of trees obtained by the gradient boosting method, you need to add up the results of the predictions of all the trees:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values); Hereinafter there will be
C++ , since XGBoost and LightGBM are written in this language. I will omit irrelevant details and try to give the most concise code.Next, consider what is hidden in
Predict , and how the tree data structure is organized.XGBoost trees
In
XGBoost there are several classes (in the sense of OOP) of trees. We will talk about RegTree (see include/xgboost/tree_model.h ), which is the main word from the documentation. If you leave only the details that are important for predictions, the members of the class look as simple as possible: class RegTree { // vector of nodes std::vector<Node> nodes_; }; The
GetNext rule is implemented in the GetNext function. The code is slightly modified, without affecting the result of the calculations: // get next position of the tree given current pid int RegTree::GetNext(int pid, float fvalue, bool is_unknown) const { const auto& node = nodes_[pid] float split_value = node.info_.split_cond; if (is_unknown) { return node.DefaultLeft() ? node.cleft_ : node.cright_; } else { if (fvalue < split_value) { return node.cleft_; } else { return node.cright_; } } } Two things follow from here:
RegTreeworks only with real signs (typefloat)- missing attribute values supported
The centerpiece is the
Node class. It contains the local tree structure, the decision rule and the leaf value: class Node { public: // feature index of split condition unsigned SplitIndex() const { return sindex_ & ((1U << 31) - 1U); } // when feature is unknown, whether goes to left child bool DefaultLeft() const { return (sindex_ >> 31) != 0; } // whether current node is leaf node bool IsLeaf() const { return cleft_ == -1; } private: // in leaf node, we have weights, in non-leaf nodes, we have split condition union Info { float leaf_value; float split_cond; } info_; // pointer to left, right int cleft_, cright_; // split feature index, left split or right split depends on the highest bit unsigned sindex_{0}; }; The following features can be distinguished:
- sheets are represented as nodes whose
cleft_ = -1 - The
info_fieldinfo_represented as aunion, i.e. two data types (in this case, the same) divide one section of memory depending on the type of node - the high bit in
sindex_is responsible for where the object goes, for which the attribute value is omitted
In order to be able to trace the path from calling the
RegTree::Predict method to getting an answer, I’ll provide the missing two functions: float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; } In the
GetLeafIndex function GetLeafIndex we loop down through the nodes of the tree until we get to the leaf.LightGBM trees
LightGBM has no node data structure. Instead, the tree data structure (file
include/LightGBM/tree.h ) contains arrays of values, where the node number is used as the index. The values in the leaves are also stored in separate arrays. class Tree { // Number of current leaves int num_leaves_; // A non-leaf node's left child std::vector<int> left_child_; // A non-leaf node's right child std::vector<int> right_child_; // A non-leaf node's split feature, the original index std::vector<int> split_feature_; //A non-leaf node's split threshold in feature value std::vector<double> threshold_; std::vector<int> cat_boundaries_; std::vector<uint32_t> cat_threshold_; // Store the information for categorical feature handle and mising value handle. std::vector<int8_t> decision_type_; // Output of leaves std::vector<double> leaf_value_; }; LightGBM supports categorical features. Support is provided using a cat_threshold_ stored in cat_threshold_ for all nodes. The cat_boundaries_ stores to which node which part of the bit field corresponds to. The threshold_ field for the categorical case is converted to an int and corresponds to the index in cat_boundaries_ to search for the beginning of the bit field.Consider the decision rule for a categorical trait:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) { // NaN is always in the right if (missing_type == 2) { return right_child_[node]; } int_fval = 0; } int cat_idx = static_cast<int>(threshold_[node]); if (FindInBitset(cat_threshold_.data() + cat_boundaries_[cat_idx], cat_boundaries_[cat_idx + 1] - cat_boundaries_[cat_idx], int_fval)) { return left_child_[node]; } return right_child_[node]; } It can be seen that, depending on the
missing_type value NaN automatically lowers the solution along the right branch of the tree. Otherwise, NaN is replaced with 0. Finding a value in a bit field is quite simple: bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; } i.e., for example, for the categorical feature
int_fval=42 checked whether the 41st (numbering with 0) bits are set in the array.This approach has one major drawback: if the categorical feature can take large values, for example 100,500, then a bit field of up to 12,564 bytes in size will be created for each decision rule!
Therefore, it is advisable to renumber the values of the categorical attributes so that they go continuously from 0 to the maximum value .
For my part, I made
LightGBM to the LightGBM and accepted them .Working with real signs is not much different from
XGBoost , and I’ll skip this for short.leaves - Go library for predictions
XGBoost and LightGBM very powerful libraries for building gradient LightGBM models on decision trees. To use them in the backend service, where machine learning algorithms are necessary, it is necessary to solve the following tasks:- Periodic training of models in offline
- Delivery models in the backend service
- Online Model Survey
For writing a loaded backend service,
Go is a popular language. XGBoost or LightGBM through C API and cgo is not the easiest solution - the program builds up, due to careless handling you can catch SIGTERM , problems with the number of system streams (OpenMP inside libraries vs go runtime).So I decided to write a library on pure
Go for predictions using models built in XGBoost or LightGBM . It is called leaves .The main features of the library:
- For
LightGBMmodels- Reading models from a standard format (text)
- Support for real and categorical features
- Missing Value Support
- Optimization of work with categorical variables
- Optimizing predictions with predictive-only data structures
- For
XGBoostmodels- Reading models from a standard format (binary)
- Missing Value Support
- Prediction optimization
I will give here a minimal program on
Go that loads the model from disk and displays the prediction on the screen: package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() { // 1. path := "lightgbm_model.txt" reader, err := os.Open(path) if err != nil { panic(err) } defer reader.Close() // 2. LightGBM model, err := leaves.LGEnsembleFromReader(bufio.NewReader(reader)) if err != nil { panic(err) } // 3. ! fvals := []float64{1.0, 2.0, 3.0} p := model.Predict(fvals, 0) fmt.Printf("Prediction for %v: %f\n", fvals, p) } The library API is minimalistic. To use the
XGBoost model XGBoost simply call the leaves.XGEnsembleFromReader method instead of the one above. Predictions can be made in batches by calling the PredictDense or model.PredictCSR . More usage scenarios can be found in the tests for leaves .Despite the fact that the
Go language is slower than C++ (mainly due to the heavier runtime and runtime checks), a number of optimizations have resulted in prediction speeds comparable to the C API call of the original libraries.More details about the results and the way of comparisons are in the repository on github .
Behold the root
I hope this article I opened the door in the implementation of trees in the libraries
XGBoost and LightGBM . As you can see, the basic constructs are quite simple, and I encourage readers to take advantage of open source — to study the code when there are questions about how it works.For those who are interested in the topic of using gradient boosting models in their services in the Go language, I recommend you to get acquainted with the leaves library. With the help of
leaves you can quite simply use the leading edge solutions in machine learning in your production environment, practically not losing in speed compared to the original C ++ implementations.Successes!
Source: https://habr.com/ru/post/423495/
All Articles