Finding the right way to split site content with a Webpack
Finding the best way to organize web project materials can be a daunting task. There are many different scenarios for user experience with projects, many technologies and other factors that need to be taken into account.
The author of the material, the translation of which we are publishing today, says that he wants to tell here everything that he needs to know in order to competently prepare materials for web projects for work. Firstly, the discussion will focus on how to select a site file sharing strategy that is best suited for a particular project and its users. Secondly, the means of implementing the chosen strategy will be considered.

According to the Webpack glossary , there are two file sharing strategies. This is bundle splitting and code splitting. These terms may seem interchangeable, but they are not.
')
Separating code seems to be much more interesting than splitting a bundle. And, in fact, there is a feeling that many articles on our topic focus on the separation of code, this technique is considered as the only worthwhile way to optimize site materials.
However, I would like to say that for many sites the first strategy turns out to be much more valuable - the separation of bundles. And, perhaps, literally all web projects can benefit from its implementation.
Let's talk about this in more detail.
A very simple idea is at the core of the bundle separation technique. If you have one huge file and you change one single line of code in it, the regular user will have to download the entire file at the next visit to the site. However, if you divide this file into two files, then the same user will need to download only the one that has been modified, and the second file will be taken from the browser cache.
It is worth noting that since the optimization of site materials by splitting bundles is tied to caching, users visiting the site for the first time, in any case, will have to download all the materials, so there is no difference for them whether these materials are presented as a single file or as several .
It seems to me that too much talk about the performance of web projects is devoted to users who visit the site for the first time. Perhaps this is so, in part, because of the importance of the first impression that the project will have on the user, and also on the fact that the amount of data transmitted to users when you first visit the site is easy and convenient to measure.
When it comes to regular visitors, it can be difficult to measure the impact of applied optimization techniques on them. But we just have to know about the consequences of such optimizations.
To analyze such things you need something like a spreadsheet. You will also need to create a strict list of conditions in which we can test each of the caching strategies under investigation.
Here is a script suitable for the general description given in the previous paragraph:
There are people (like me) who will try to make such a scenario as realistic as possible. But you do not need to do that. The real scenario here does not really matter. Why this is so - we will soon find out.
Suppose the total size of our javascript package is quite 400 kb, and we, in the current environment, transfer all this to the user as one
Webpack calls the resulting
If you are not very good at working with the cache, keep in mind that every time I write
In accordance with the above scenario, when we make some changes to the site code every week, the
If you make a nice sign (with a useless row of totals) containing data on the weekly amount of data loading that falls on this file, then we will have the following.

The amount of data uploaded by the user
As a result, it turns out that the user, in 10 weeks, uploaded 4.12 MB of code. This indicator can be improved.
We divide the large package into two parts. Our own code will be in the
Webpack 4 tries to make the developer's life as easy as possible, so he does everything he can and does not require him to be told exactly how to break the bundles into parts.
Such an automatic behavior of the program leads to a few delights, like: “Well, what a beauty this Webpack is”, and to many questions in the spirit: “And what is this doing here with my bundles?”.
In any case, adding to the configuration configuration
After we have done this basic division of the bundle, Alice, who regularly visits our site weekly, will upload a 200 KB

The amount of data uploaded by the user
The result is that the amount of data uploaded by the user in 10 weeks was 2.64 MB. That is, in comparison with what happened before the bundle split, the volume decreased by 36%. Not so bad result achieved by adding a few lines to the configuration file. By the way, before you read further - do the same in your project. And if you need to upgrade from Webpack 3 to 4 - do it and do not worry, since the process is quite simple and still free.
It seems to me that the improvement considered here looks somewhat abstract, since it is stretched for 10 weeks. However, if we count the volume of data sent to a loyal user, then this is an honest reduction of this volume by 36%. This is a very good result, but it can be improved.
The
Why don't we create separate files for each npm-package? It’s really easy to do, so let's
In the documentation you can find an excellent explanation of the constructions used here, but I, nevertheless, devote a little time to the story about some things, since it took a lot of time to use them correctly.
The above Webpack configuration is good because you can configure it once and then forget about it. It does not require reference to specific packages by name, therefore, after its creation, it, even with changes in the composition of packages, remains relevant.
Alice, our regular visitor, still
Below is a new version of the table with information about the volume of weekly data downloads. By a strange coincidence, the size of each file with npm packages is 20 Kb.
The amount of data uploaded by the user
Now the amount of data downloaded in 10 weeks is 2.24 MB. This means that we have improved the base rate by 44%. The result is already quite decent, but then the question arises whether it is possible to do so in order to achieve a result that exceeds 50%. If this happens, it will be just great.
Let's
Above, I said that our site has two separate sections. The first is a list of products, the second is a page with detailed information about the product. The size of the code, unique for each of them, is 25 Kb (and 150 Kb of code is used both there and there).
Product details page is not subject to change, as we have already brought it to perfection. Therefore, if we separate its code into a separate file, this file, most of the time it takes to work with the site, will be loaded into the browser from the cache.
In addition, as it turned out, we have a huge embedded SVG file used for rendering icons, which weighs as much as 25 Kb and rarely changes.
With this we need to do something.
We manually created several entry points, telling Webpack that he needed to create a separate file for each of these entities.
A hard-working Webpack will also create files for what is common, for example, for
What we have just done will allow Alice to save 50 Kb of traffic almost every week. Please note that the icon description file was edited in the sixth week. Here is our traditional table.
The amount of data uploaded by the user
Now for ten weeks loaded only 1.815 MB of data. This means that the traffic saving was an impressive 56%. In accordance with our theoretical scenario, the regular user will always work with this level of savings.
All this is done due to changes made to the Webpack configuration. We did not change the application code to achieve such results.
Above, I said that the specific scenario in which such a test is conducted does not really play a special role. This is said because, regardless of the script used, the conclusion of everything we talked about is the same: splitting the application into small files that make sense when applied to its architecture reduces the amount of site data uploaded by its regular users.
Very soon we will start talking about code sharing, but first I would like to answer three questions that you are probably thinking about now.
This question can be given a simple short answer: "No, it does not harm." A similar situation resulted in a problem in the old days, when the HTTP / 1.1 protocol was used, and when using HTTP / 2 this is irrelevant.
Although, it should be noted that this article, published in 2016, and this 2015 Khan Academy article concludes that even when using HTTP / 2, the use of too many files slows down the download. But in both of these materials, “too much” means “several hundred.” Therefore, it is worth remembering that if you have to work with hundreds of files, restrictions on parallel data processing may affect the speed of their loading.
If you are interested, HTTP / 2 support is available in IE 11 in Windows 10. In addition, I did extensive research among those using older systems. They unanimously stated that their website loading speed is not particularly a concern.
Yes it is.
Yes it is, too. In fact, I would like to say this:
Let's deal with this in order to understand how bad it is.
I just did a test, during which the code from a file of 190 KB in size was broken into 19 parts. This added about 2% to the amount of data sent to the browser.
The result is that when you first visit the site, the user will download 2% more data, and the next - 60% less, and it will continue for a very, very long time.
So is it worth worrying about it? No, not worth it.
When I compared the system using 1 file and the system with 19 files, I tested it using various protocols, including HTTP / 1.1. The table below strongly supports the idea that more files are better.

Data on working with 2 versions of a site hosted on a static Firebase hosting, the code of which has a size of 190 Kb, but, in the first case, is packaged in 1 file, and in the second - broken into 19
When working in 3G and 4G networks, downloading a site variant with 19 files took 30% less time than downloading a site with one file.
In the data presented in the table, a lot of noise. For example, one download session on 4G (Run 2 in the table) took 646 ms, another (Run 4) - 1116 ms, which is 73% longer. Therefore, there is a feeling that saying that HTTP / 2 "is 30% faster" is somewhat unfair.
I created this table to see what HTTP / 2 uses. But, in fact, the only thing that can be said here is that the use of HTTP / 2 probably does not significantly affect the page load.
The last two lines in this table were a real surprise. Here are the results for not the newest version of Windows with IE11 and HTTP / 1.1. If I tried to predict the results of the test in advance, I would definitely say that such a configuration would load materials much more slowly than others. True, a very fast network connection was used here, and for such tests I probably should use something slower.
And now I will tell you a story. I, in order to investigate my site on an absolutely ancient system, downloaded the Windows 7 virtual machine from the Microsoft site . IE8 was installed there, which I decided to upgrade to IE9. To do this, I went to the Microsoft page, designed to download IE 9. But I did not succeed.
That is bad luck ...
By the way, if we talk about HTTP / 2, I would like to note that this protocol is integrated into Node.js. If you want to experiment - you can use the small HTTP / 2 server I wrote with support for the answer cache, gzip and brotli.
Perhaps, I said everything I wanted about the method of splitting bundles. I think that the only drawback of such an approach, when using which users have to upload a lot of files, in fact, is not such a “minus”.
Now let's talk about code sharing.
The main idea of the code separation technique is: “Do not download unnecessary code”. I was told that using this approach only makes sense for some sites.
I prefer, when it comes to code sharing, to use the 20/20 rule that I just formulated. If there is any part of the site that only 20% of users visit, and its functionality provides more than 20% of the site's JavaScript code, then this code should be downloaded only on request.
These are, of course, not absolute numbers, they can be tailored to a specific situation, and in reality there are much more complex scenarios than the one described above. The most important thing here is balance, and it’s completely normal not to use code separation at all if it makes no sense for your site.
How to find the answer to the question of whether you need code separation or not? Suppose you have an online store and you are thinking about whether the code that is used to receive payment from customers should be separated from the rest of the code, since only 30% of the visitors buy something from you.
What is there to say? First of all, you would have to work on filling the store and selling something that will be interesting to more visitors. Secondly - you need to understand how much code is completely unique for the section of the site where payment is accepted. Since you should always do a “bundle separation” before “code separation”, and you hope so, you probably already know what size the code of interest is.
Perhaps this code may turn out to be less than you think, therefore, before you rejoice at the new opportunity to optimize the site, it is worthwhile to calmly count everything. If you have, for example, a React site, then the storage, reducer, routing system, actions will be shared by all parts of the site. The code that is unique for different parts of the site will be mainly represented by components and auxiliary functions for them.
So, you found out that a completely unique code of the section of the site used to pay for purchases takes 7 Kb. The size of the rest of the site code is 300 Kb. In a situation like this, I wouldn’t deal with code separation for several reasons:
, , , .
.
, , , .
. , . :
Webpack , , npm-. 25 , 90% , .
Webpack 4
, , , — . —
,
, . .
. , , , .
, npm- . , , 100 .
, , URL
. , ,
, .
, ,
. (, URL
,
, , (, , CSS). :
Dear readers! ?

The author of the material, the translation of which we are publishing today, says that he wants to tell here everything that he needs to know in order to competently prepare materials for web projects for work. Firstly, the discussion will focus on how to select a site file sharing strategy that is best suited for a particular project and its users. Secondly, the means of implementing the chosen strategy will be considered.
General information
According to the Webpack glossary , there are two file sharing strategies. This is bundle splitting and code splitting. These terms may seem interchangeable, but they are not.
')
- Bundle splitting is a technique for splitting large bundles into several parts, which are smaller files. Such files, in any case, as when working with a single bundle, will be downloaded by all users of the site. The strength of this technique is to improve the use of browser caching mechanisms.
- Code separation is an approach that implies dynamic code loading as the need arises. This leads to the fact that the user downloads only the code that is necessary for him to work with some part of the site at a certain point in time.
Separating code seems to be much more interesting than splitting a bundle. And, in fact, there is a feeling that many articles on our topic focus on the separation of code, this technique is considered as the only worthwhile way to optimize site materials.
However, I would like to say that for many sites the first strategy turns out to be much more valuable - the separation of bundles. And, perhaps, literally all web projects can benefit from its implementation.
Let's talk about this in more detail.
Splitting bundles
A very simple idea is at the core of the bundle separation technique. If you have one huge file and you change one single line of code in it, the regular user will have to download the entire file at the next visit to the site. However, if you divide this file into two files, then the same user will need to download only the one that has been modified, and the second file will be taken from the browser cache.
It is worth noting that since the optimization of site materials by splitting bundles is tied to caching, users visiting the site for the first time, in any case, will have to download all the materials, so there is no difference for them whether these materials are presented as a single file or as several .
It seems to me that too much talk about the performance of web projects is devoted to users who visit the site for the first time. Perhaps this is so, in part, because of the importance of the first impression that the project will have on the user, and also on the fact that the amount of data transmitted to users when you first visit the site is easy and convenient to measure.
When it comes to regular visitors, it can be difficult to measure the impact of applied optimization techniques on them. But we just have to know about the consequences of such optimizations.
To analyze such things you need something like a spreadsheet. You will also need to create a strict list of conditions in which we can test each of the caching strategies under investigation.
Here is a script suitable for the general description given in the previous paragraph:
- Alice visits our site once a week for 10 weeks.
- We update the site once a week.
- We are updating the product list page every week.
- In addition, we have a page with product details, but we are not working on it yet.
- On the fifth week, we add a new npm package to the project materials.
- On the eighth week, we are updating one of the npm packages already used in the project.
There are people (like me) who will try to make such a scenario as realistic as possible. But you do not need to do that. The real scenario here does not really matter. Why this is so - we will soon find out.
▍The conditions
Suppose the total size of our javascript package is quite 400 kb, and we, in the current environment, transfer all this to the user as one
main.js file. We have a Webpack configuration, which, in general, is similar to the one below (that which doesn’t apply to our conversation, I removed it from there): const path = require('path'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, }; Webpack calls the resulting
main.js file when there is only one entry in the configuration.If you are not very good at working with the cache, keep in mind that every time I write
main.js here, I actually mean something like main.xMePWxHo.js . An insane sequence of characters is a hash of the contents of the file, something that is called contenthash in the configuration. Using this approach leads to the fact that, when the code changes, the file names also change, which forces the browser to download new files.In accordance with the above scenario, when we make some changes to the site code every week, the
contenthash line of the package changes. As a result, visiting our website weekly, Alice is forced to upload a new file of 400 KB in size.If you make a nice sign (with a useless row of totals) containing data on the weekly amount of data loading that falls on this file, then we will have the following.
The amount of data uploaded by the user
As a result, it turns out that the user, in 10 weeks, uploaded 4.12 MB of code. This indicator can be improved.
▍Division of third-party packages from the main code
We divide the large package into two parts. Our own code will be in the
main.js file, and third-party code in the vendor.js file. It's easy to do this; the following Webpack configuration will help us: const path = require('path'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, optimization: { splitChunks: { chunks: 'all', }, }, }; Webpack 4 tries to make the developer's life as easy as possible, so he does everything he can and does not require him to be told exactly how to break the bundles into parts.
Such an automatic behavior of the program leads to a few delights, like: “Well, what a beauty this Webpack is”, and to many questions in the spirit: “And what is this doing here with my bundles?”.
In any case, adding to the configuration configuration
optimization.splitChunks.chunks = 'all' tells Webpack that we need it to take everything from the node_modules and put it in the vendors~main.js .After we have done this basic division of the bundle, Alice, who regularly visits our site weekly, will upload a 200 KB
main.js file at each visit. But the vendor.js file it will load only three times. It will happen during the visits in the first, fifth and eighth weeks. Here is the corresponding table, in which, by the will of fate, the sizes of the files main.js and vendor.js in the first four weeks coincide and are equal to 200 Kb.The amount of data uploaded by the user
The result is that the amount of data uploaded by the user in 10 weeks was 2.64 MB. That is, in comparison with what happened before the bundle split, the volume decreased by 36%. Not so bad result achieved by adding a few lines to the configuration file. By the way, before you read further - do the same in your project. And if you need to upgrade from Webpack 3 to 4 - do it and do not worry, since the process is quite simple and still free.
It seems to me that the improvement considered here looks somewhat abstract, since it is stretched for 10 weeks. However, if we count the volume of data sent to a loyal user, then this is an honest reduction of this volume by 36%. This is a very good result, but it can be improved.
▍Packaging packages into separate files
The
vendor.js file suffers from the same problem as the original main.js It lies in the fact that changing any package that is included in this file leads to the need for the regular user to reload this entire file.Why don't we create separate files for each npm-package? It’s really easy to do, so let's
react our react , lodash , redux , moment , and so on, into separate files. The following Webpack configuration will help us with this: const path = require('path'); const webpack = require('webpack'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), plugins: [ new webpack.HashedModuleIdsPlugin(), // ], output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, optimization: { runtimeChunk: 'single', splitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 0, cacheGroups: { vendor: { test: /[\\/]node_modules[\\/]/, name(module) { // , node_modules/packageName/not/this/part.js // node_modules/packageName const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]; // npm- , , // URL, @ return `npm.${packageName.replace('@', '')}`; }, }, }, }, }, }; In the documentation you can find an excellent explanation of the constructions used here, but I, nevertheless, devote a little time to the story about some things, since it took a lot of time to use them correctly.
- Webpack has quite reasonable standard settings, which, in fact, turn out to be not so reasonable. For example, the maximum number of output files is set to 3, the minimum file size is 30 KB (that is, smaller files will be merged). I redefined it.
cacheGroupsis where we set the rules for how Webpack should group data in output files. I have one group here,vendor, that will be used for any module loaded fromnode_modules. Usually the name for the output file is set as a string. But I set thenamein the form of a function that will be called for each processed file. Then I take the package name from the module path. As a result, we get one file for each package. For example,npm.react-dom.899sadfhj4.js.- Package names, in order for them to be published to npm, must be suitable for use in URLs , so we do not need to perform an
encodeURIoperation forpackageNamenames. However, I ran into a problem, which is that the .NET server refuses to work with files that have an@symbol in their names (such names are used for packages with a given scope of the so-called scoped packages), so I’ve code fragment, get rid of these characters.
The above Webpack configuration is good because you can configure it once and then forget about it. It does not require reference to specific packages by name, therefore, after its creation, it, even with changes in the composition of packages, remains relevant.
Alice, our regular visitor, still
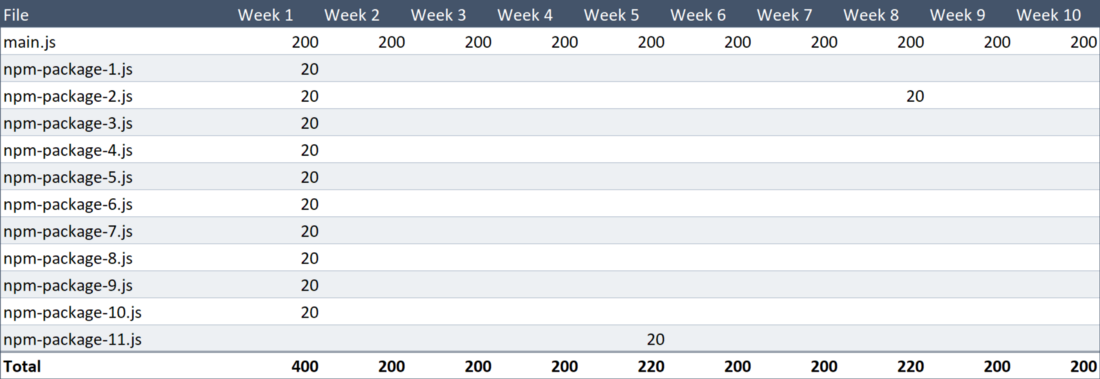
main.js 200-kilobyte main.js every week, and when she first visits the site, she has to download 200 KB of npm-packages, but she will not have to download the same packages twice.Below is a new version of the table with information about the volume of weekly data downloads. By a strange coincidence, the size of each file with npm packages is 20 Kb.
The amount of data uploaded by the user
Now the amount of data downloaded in 10 weeks is 2.24 MB. This means that we have improved the base rate by 44%. The result is already quite decent, but then the question arises whether it is possible to do so in order to achieve a result that exceeds 50%. If this happens, it will be just great.
▍Disposing the application code into fragments
Let's
main.js back to the main.js file, which unfortunate Alice has to load constantly.Above, I said that our site has two separate sections. The first is a list of products, the second is a page with detailed information about the product. The size of the code, unique for each of them, is 25 Kb (and 150 Kb of code is used both there and there).
Product details page is not subject to change, as we have already brought it to perfection. Therefore, if we separate its code into a separate file, this file, most of the time it takes to work with the site, will be loaded into the browser from the cache.
In addition, as it turned out, we have a huge embedded SVG file used for rendering icons, which weighs as much as 25 Kb and rarely changes.
With this we need to do something.
We manually created several entry points, telling Webpack that he needed to create a separate file for each of these entities.
module.exports = { entry: { main: path.resolve(__dirname, 'src/index.js'), ProductList: path.resolve(__dirname, 'src/ProductList/ProductList.js'), ProductPage: path.resolve(__dirname, 'src/ProductPage/ProductPage.js'), Icon: path.resolve(__dirname, 'src/Icon/Icon.js'), }, output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash:8].js', }, plugins: [ new webpack.HashedModuleIdsPlugin(), // ], optimization: { runtimeChunk: 'single', splitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 0, cacheGroups: { vendor: { test: /[\\/]node_modules[\\/]/, name(module) { // , node_modules/packageName/not/this/part.js // node_modules/packageName const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]; // npm- , , // URL, @ return `npm.${packageName.replace('@', '')}`; }, }, }, }, }, }; A hard-working Webpack will also create files for what is common, for example, for
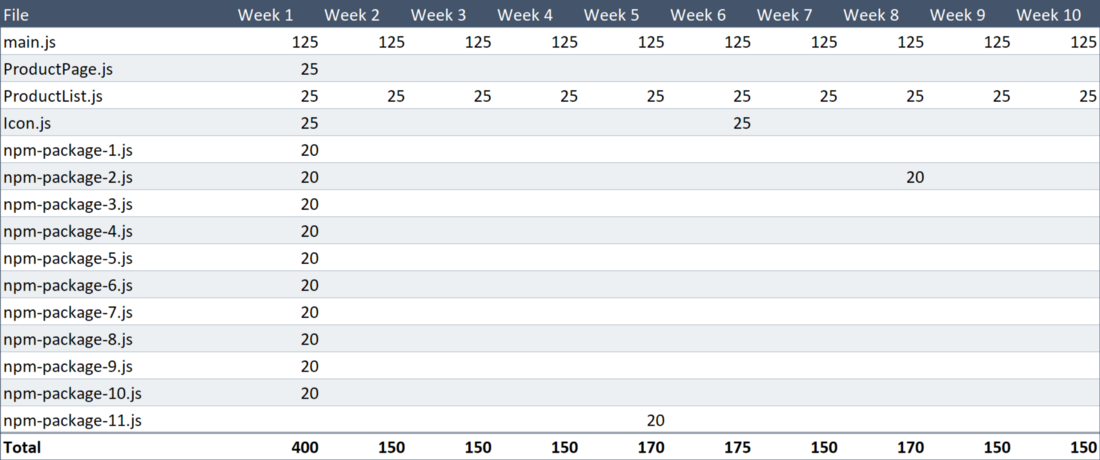
ProductList and ProductPage , that is, there will be no duplicate code here.What we have just done will allow Alice to save 50 Kb of traffic almost every week. Please note that the icon description file was edited in the sixth week. Here is our traditional table.
The amount of data uploaded by the user
Now for ten weeks loaded only 1.815 MB of data. This means that the traffic saving was an impressive 56%. In accordance with our theoretical scenario, the regular user will always work with this level of savings.
All this is done due to changes made to the Webpack configuration. We did not change the application code to achieve such results.
Above, I said that the specific scenario in which such a test is conducted does not really play a special role. This is said because, regardless of the script used, the conclusion of everything we talked about is the same: splitting the application into small files that make sense when applied to its architecture reduces the amount of site data uploaded by its regular users.
Very soon we will start talking about code sharing, but first I would like to answer three questions that you are probably thinking about now.
▍ Question number 1. Doesn’t the necessity of fulfilling a multitude of requests harm the speed of loading a site?
This question can be given a simple short answer: "No, it does not harm." A similar situation resulted in a problem in the old days, when the HTTP / 1.1 protocol was used, and when using HTTP / 2 this is irrelevant.
Although, it should be noted that this article, published in 2016, and this 2015 Khan Academy article concludes that even when using HTTP / 2, the use of too many files slows down the download. But in both of these materials, “too much” means “several hundred.” Therefore, it is worth remembering that if you have to work with hundreds of files, restrictions on parallel data processing may affect the speed of their loading.
If you are interested, HTTP / 2 support is available in IE 11 in Windows 10. In addition, I did extensive research among those using older systems. They unanimously stated that their website loading speed is not particularly a concern.
▍ Question number 2. In Webpack-bandla there is an auxiliary code. Does it create additional load on the system?
Yes it is.
▍ Question number 3. When working with many small files, their compression level worsens, doesn’t it?
Yes it is, too. In fact, I would like to say this:
- More files means more auxiliary Webpack code.
- More files means less compression.
Let's deal with this in order to understand how bad it is.
I just did a test, during which the code from a file of 190 KB in size was broken into 19 parts. This added about 2% to the amount of data sent to the browser.
The result is that when you first visit the site, the user will download 2% more data, and the next - 60% less, and it will continue for a very, very long time.
So is it worth worrying about it? No, not worth it.
When I compared the system using 1 file and the system with 19 files, I tested it using various protocols, including HTTP / 1.1. The table below strongly supports the idea that more files are better.
Data on working with 2 versions of a site hosted on a static Firebase hosting, the code of which has a size of 190 Kb, but, in the first case, is packaged in 1 file, and in the second - broken into 19
When working in 3G and 4G networks, downloading a site variant with 19 files took 30% less time than downloading a site with one file.
In the data presented in the table, a lot of noise. For example, one download session on 4G (Run 2 in the table) took 646 ms, another (Run 4) - 1116 ms, which is 73% longer. Therefore, there is a feeling that saying that HTTP / 2 "is 30% faster" is somewhat unfair.
I created this table to see what HTTP / 2 uses. But, in fact, the only thing that can be said here is that the use of HTTP / 2 probably does not significantly affect the page load.
The last two lines in this table were a real surprise. Here are the results for not the newest version of Windows with IE11 and HTTP / 1.1. If I tried to predict the results of the test in advance, I would definitely say that such a configuration would load materials much more slowly than others. True, a very fast network connection was used here, and for such tests I probably should use something slower.
And now I will tell you a story. I, in order to investigate my site on an absolutely ancient system, downloaded the Windows 7 virtual machine from the Microsoft site . IE8 was installed there, which I decided to upgrade to IE9. To do this, I went to the Microsoft page, designed to download IE 9. But I did not succeed.
That is bad luck ...
By the way, if we talk about HTTP / 2, I would like to note that this protocol is integrated into Node.js. If you want to experiment - you can use the small HTTP / 2 server I wrote with support for the answer cache, gzip and brotli.
Perhaps, I said everything I wanted about the method of splitting bundles. I think that the only drawback of such an approach, when using which users have to upload a lot of files, in fact, is not such a “minus”.
Now let's talk about code sharing.
Code separation
The main idea of the code separation technique is: “Do not download unnecessary code”. I was told that using this approach only makes sense for some sites.
I prefer, when it comes to code sharing, to use the 20/20 rule that I just formulated. If there is any part of the site that only 20% of users visit, and its functionality provides more than 20% of the site's JavaScript code, then this code should be downloaded only on request.
These are, of course, not absolute numbers, they can be tailored to a specific situation, and in reality there are much more complex scenarios than the one described above. The most important thing here is balance, and it’s completely normal not to use code separation at all if it makes no sense for your site.
▍Divide or not?
How to find the answer to the question of whether you need code separation or not? Suppose you have an online store and you are thinking about whether the code that is used to receive payment from customers should be separated from the rest of the code, since only 30% of the visitors buy something from you.
What is there to say? First of all, you would have to work on filling the store and selling something that will be interesting to more visitors. Secondly - you need to understand how much code is completely unique for the section of the site where payment is accepted. Since you should always do a “bundle separation” before “code separation”, and you hope so, you probably already know what size the code of interest is.
Perhaps this code may turn out to be less than you think, therefore, before you rejoice at the new opportunity to optimize the site, it is worthwhile to calmly count everything. If you have, for example, a React site, then the storage, reducer, routing system, actions will be shared by all parts of the site. The code that is unique for different parts of the site will be mainly represented by components and auxiliary functions for them.
So, you found out that a completely unique code of the section of the site used to pay for purchases takes 7 Kb. The size of the rest of the site code is 300 Kb. In a situation like this, I wouldn’t deal with code separation for several reasons:
- If you download these 7 KB in advance, the site is not slow. Remember that the files are downloaded in parallel and try to measure the difference needed to download 300 KB and 307 KB of code.
- If you download this code later, then the user will have to wait after clicking on the "Pay" button. And this is the very moment when you need everything to go as smoothly as possible.
- Separating the code requires changes to the application. In the code, in those places where before everything was done synchronously, asynchronous logic appears. Of course, there are no cosmic difficulties in such code transformations, but this is still an additional amount of work, which, I think, should be done for a tangible improvement in the user experience of working with the site.
, , , .
.
▍
, , , .
. , . :
require('whatwg-fetch'); require('intl'); require('url-polyfill'); require('core-js/web/dom-collections'); require('core-js/es6/map'); require('core-js/es6/string'); require('core-js/es6/array'); require('core-js/es6/object'); index.js , : import './polyfills'; import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } render(); // , Webpack , , npm-. 25 , 90% , .
Webpack 4
import() ( import ), : import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } if ( 'fetch' in window && 'Intl' in window && 'URL' in window && 'Map' in window && 'forEach' in NodeList.prototype && 'startsWith' in String.prototype && 'endsWith' in String.prototype && 'includes' in String.prototype && 'includes' in Array.prototype && 'assign' in Object && 'entries' in Object && 'keys' in Object ) { render(); } else { import('./polyfills').then(render); } , , , — . —
render() . , Webpack npm-, , render() .,
import() Babel dynamic-import . , Webpack, import() , ., . .
▍ React,
. , , , .
, npm- . , , 100 .
, , URL
/admin , <AdminPage> . Webpack , import AdminPage from './AdminPage.js' .. , ,
import('./AdminPage.js') , Webpack , ., .
, ,
AdminPage , , URL /admin . , : import React from 'react'; class AdminPageLoader extends React.PureComponent { constructor(props) { super(props); this.state = { AdminPage: null, } } componentDidMount() { import('./AdminPage').then(module => { this.setState({ AdminPage: module.default }); }); } render() { const { AdminPage } = this.state; return AdminPage ? <AdminPage {...this.props} /> : <div>Loading...</div>; } } export default AdminPageLoader; . (, URL
/admin ), ./AdminPage.js , .render() , <AdminPage> , <div>Loading...</div> , <AdminPage> , .,
react-loadable , React .Results
, , (, , CSS). :
- — .
- , — .
Dear readers! ?
Source: https://habr.com/ru/post/423483/
All Articles