Ruin the performance
This note is a written version of my report "How to kill performance with an inefficient code" from the JPoint 2018 conference. You can watch videos and slides on the conference page . In the schedule, the report is marked by an insulting glass of smoothie, so there will be nothing super-complex, it is more likely for beginners.
Subject of the report:
- how to look at the code to find bottlenecks in it
- common anti-patterns
- non-obvious rake
- bypass rake
On the sidelines I was pointed out by some inaccuracies / omissions in the report, they are noted here. Comments are also welcome.
Performance Impact on Performance
There is a user class:
class User { String name; int age; } We need to compare objects with each other, so we will declare the equals and hashCode methods:
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; } The code works, the question is different: will the performance of this code be the best? To answer it, let us recall the features of the Object::equals method: it returns a positive result only when all the compared fields are equal, otherwise the result will be negative. In other words, one difference is enough for a negative result.
Looking at the code created for @EqualsAndHashCode we’ll see something like this:
public boolean equals(Object that) { //... if (name == null && that.name != null) { return false; } if (name != null && !name.equals(that.name)) { return false; } return age == that.age; } The order of checking the fields corresponds to the order of their declaration, which in our case is not the best solution, because comparing objects with equals “harder” than comparing simple types.
Well, let's try creating equals/hashCode methods using Ideas:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); } Idea creates smarter code that knows the difficulty of comparing different kinds of data. Well, well, we will @EqualsAndHashCode and we will explicitly prescribe equals/hashCode . Now let's see what happens when the class is expanded:
class User { List<T> props; String name; int age; } Recreate equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props) // <---- && Objects.equals(name, that.name); } Lists are compared before strings are compared, which is meaningless when the strings are different. At first glance, there is not much difference, because strings of equal length are cognitively compared (that is, the comparison grows with the length of the string):
The java.lang.String::equals method is intrinsicized , so no cognitive comparison occurs during execution.
//java.lang.String public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String) anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { // <---- if (v1[i] != v2[i]) return false; i++; } return true; } } return false; } Now consider the comparison of two ArrayList (as the most frequently used list implementation). Examining ArrayList with surprise, we find that it does not have its own equals implementation, but uses the inherited implementation:
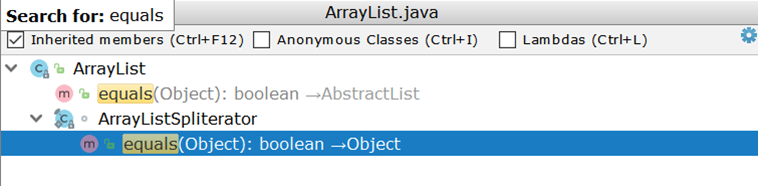
//AbstractList::equals public boolean equals(Object o) { if (o == this) { return true; } if (!(o instanceof List)) { return false; } ListIterator<E> e1 = listIterator(); ListIterator<?> e2 = ((List<?>) o).listIterator(); while (e1.hasNext() && e2.hasNext()) { // <---- E o1 = e1.next(); Object o2 = e2.next(); if (!(o1 == null ? o2 == null : o1.equals(o2))) { return false; } } return !(e1.hasNext() || e2.hasNext()); } The important thing here is the creation of two iterators and a pairwise pass through them. Suppose there are two ArrayList :
- in one number from 1 to 99
- in the second from 1 to 100
Ideally, it would be enough to compare the sizes of the two lists and, if there is a discrepancy, immediately return a negative result (as the AbstractSet does), in reality, 99 comparisons will be executed and it will become clear only on the hundredth that the lists are different.
Che there Kotlinovtsev?
data class User(val name: String, val age: Int); It's all like a broken piece - the order of comparison corresponds to the order of the announcement:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) { // <---- return true; } } return false; } IDEA-170178 IDEA-generated equals ()
https://youtrack.jetbrains.com/issue/IDEA-170178
Reordering of comparison in @ EqualsAndHashCode for better performance # 1543
https://github.com/rzwitserloot/lombok/issues/1543
KT-23184 Auto-generated equals () of data class is not optimal
https://youtrack.jetbrains.com/issue/KT-23184
As a crawl, you can manually order the field declarations.
Complicate the task
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) { // <---- //do smth } } The code assumes access to the database even when the result of checking the condition marked with an arrow is predictable in advance. If the value of the valid variable is false, then the code in the if block will never be executed, which means you can do without the query:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) { //do smth } } // , boolean hasGoodRating(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); return entity.hasGoodRating(); } Sinking can be insignificant, when the entity returned from JpaRepository::findOne already in the first level cache, then there will be no request.
A similar example without explicit branching:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); } Quick return allows you to delay the request:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); } Imagine that a test uses a similar entity:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type; If the check uses the same entity, then it is worthwhile to ensure that the access to the "lazy" child entities / collections is performed after referring to the fields that are already loaded. At first glance, one additional request will not have a significant impact on the overall picture, but everything may change when performing an action in a cycle.
Conclusion: the chain of actions / checks should be ordered in order of increasing complexity of individual operations, perhaps some of them will not have to be performed.
Cycles and mass processing
The following example does not need special explanations:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id); // <---- O(n) enroll(student); } } Due to multiple queries to the database, the code is slow.
Productivity can be even stronger if the enrollStudents method enrollStudents executed outside a transaction: then every call to osdjrJpaRepository::findOne will be executed in a new transaction (see SimpleJpaRepository ), which means getting and returning the database connection, as well as creating and resetting the first level cache.
Correct:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } } 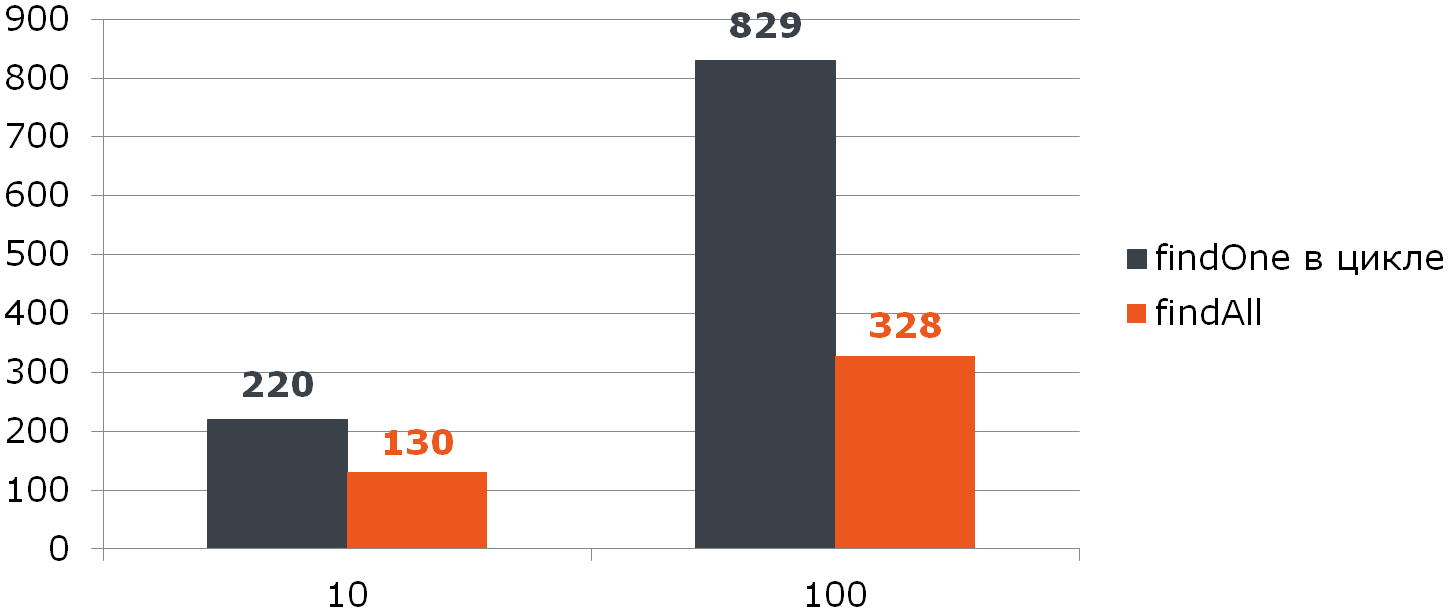
If you use Oracle and transfer more than 1000 keys to findAll , then you will get the exception ORA-01795: maximum number of expressions in a list is 1000 .
Also, performing a heavy (with multiple keys) in query can be worse than n queries. It all depends on the specific application, so a mechanical replacement of the cycle for mass processing can degrade performance.
More complex example on the same topic.
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) { // <---- region = new Region(); region.setId(id); } use(region); } In this case, we cannot replace the loop with JpaRepository::findAll , JpaRepository::findAll it will break the logic: all values obtained from JpaRepository::findAll will not be null and the if block will not work.
To solve this difficulty we will be helped by the fact that for each key of the database
returns either real value or no value. That is, in a sense, a database is a dictionary. Java from the box gives us a ready implementation of the dictionary - HashMap - on top of which we will build the logic for replacing the database:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); } Example in the opposite direction
// class Saver @Transactional(propagation = Propagation.REQUIRES_NEW) public void save(List<AuditEntity> entities) { jpaRepository.save(entities); } This code always creates a new transaction to save the list of entities. Sinking begins with multiple calls to the method opening a new transaction:
// @Transactional public void audit(List<AuditDto> inserts) { inserts.map(this::toEntities).forEach(saver::save); // <---- } // class Saver @Transactional(propagation = Propagation.REQUIRES_NEW) // <---- public void save(List<AuditEntity> entities) { jpaRepository.save(entities); } Solution: use the Saver::save method at once for the entire data set:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream) // <---- .collect(toList()); saver.save(bulk); } 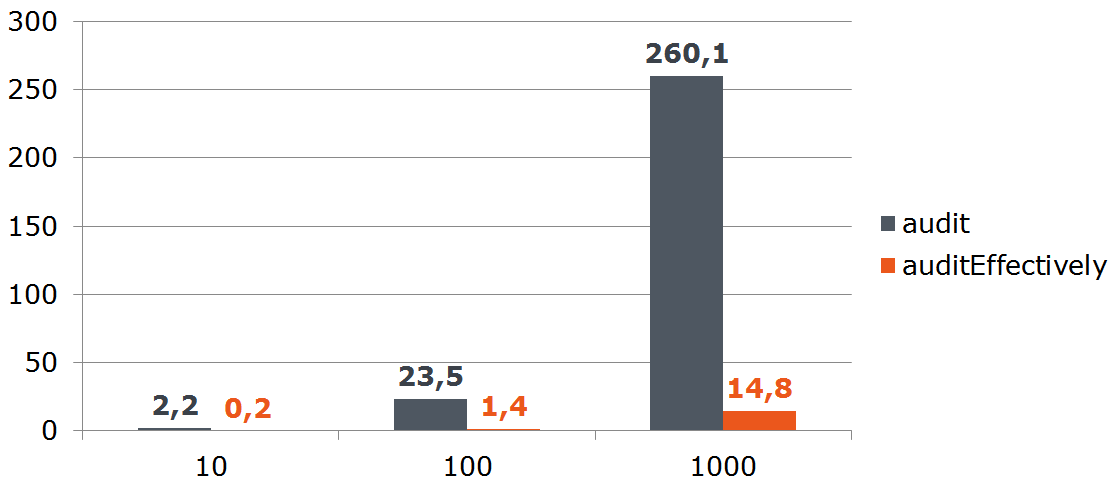
An example with multiple transactions is difficult to formalize, which cannot be said about calling JpaRepository::findOne in a loop.
https://youtrack.jetbrains.com/issue/IDEA-165730
IDEA-165730 Warn about efficient usage of JpaRepository
https://youtrack.jetbrains.com/issue/IDEA-165942IDEA-165942 Inspection to replace method call in bulk with bulk operation
Fixed in 2017.1
The approach is applicable not only to the database, so Tagir lany Valeev went further. And if earlier we wrote this:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); } and everything was fine, now the "Idea" offers to correct:
List<Long> list = new ArrayList<>(); list.addAll(items); But even this option does not always satisfy her, because you can make it even shorter and faster:
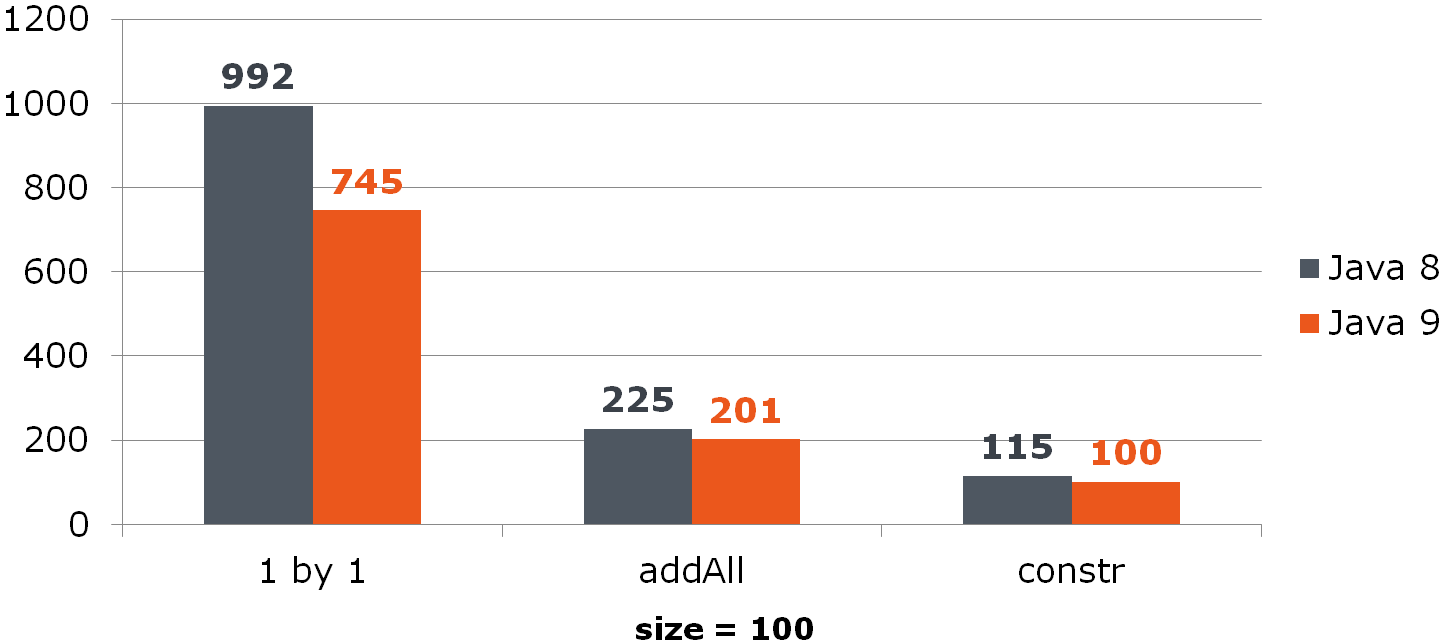
List<Long> list = new ArrayList<>(items); For ArrayList, this improvement gives a noticeable increase:
For HashSet, everything is not so rosy:

https://youtrack.jetbrains.com/issue/IDEA-138456IDEA-138456 New inspection: Collection.addAll () replaceable with parametrized constructor
Fixed at 142.1217
https://youtrack.jetbrains.com/issue/IDEA-178761IDEA-178761 Inspection 'Collection.addAll () replaceable with parametrized constructor' should not be turned on by default
Fixed in 2017.3
Remove from ArrayList
for (int i = from; i < to; i++) { list.remove(from); } The problem with the implementation of the List::remove method:
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved); // <---- } array[--size] = null; // clear to let GC do its work return oldValue; } Decision:
list.subList(from, to).clear(); But what if in the source code the remote value is used?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); } Now you need to first go through the cleared sublist:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear(); If you really want to delete in the cycle, then changing the direction of passage through the list will help ease the pain. Its meaning is to move fewer elements after cleaning the cell:
// , . . for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed, i); } // , . . for (int i = to - 1; i >= from; i--) { E removed = list.remove(i); use(removed, reverseIndex(i)); } Let's compare all three ways (under the columns there is the% of elements to be deleted from the list of 100):
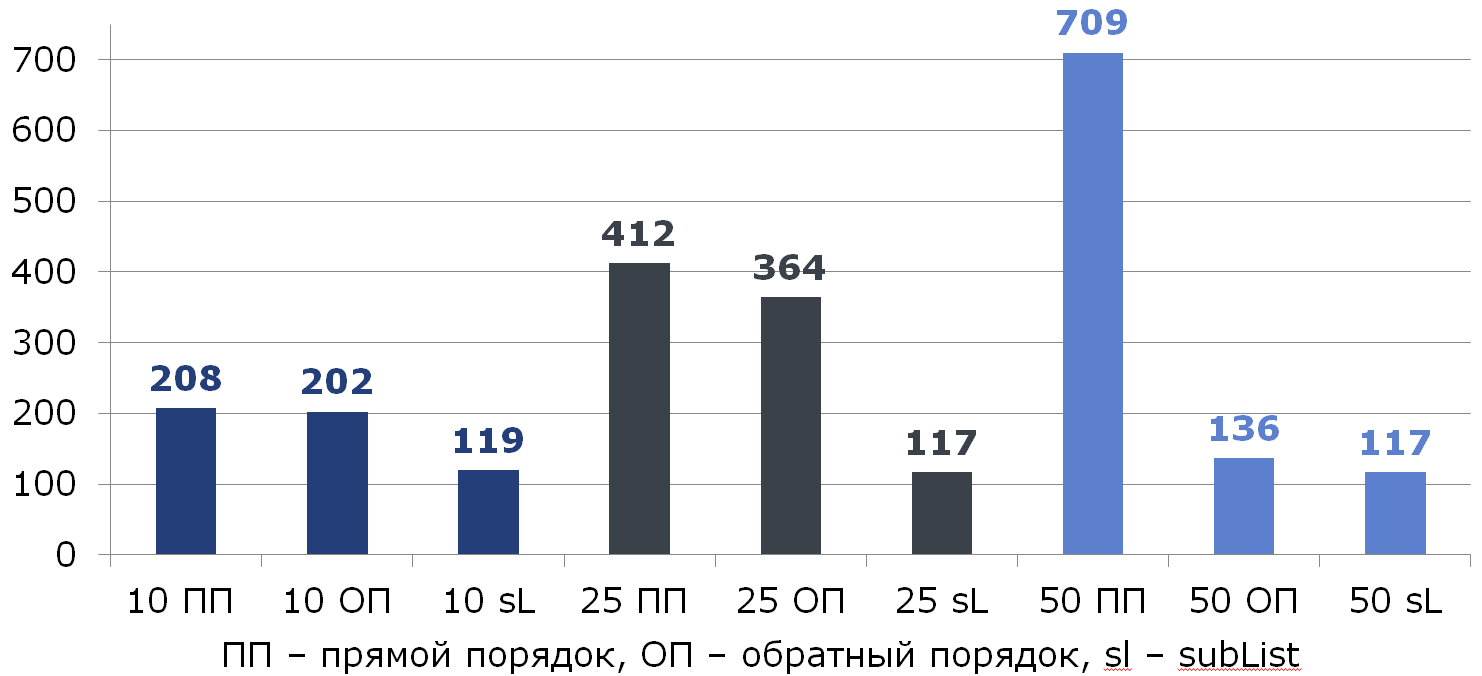
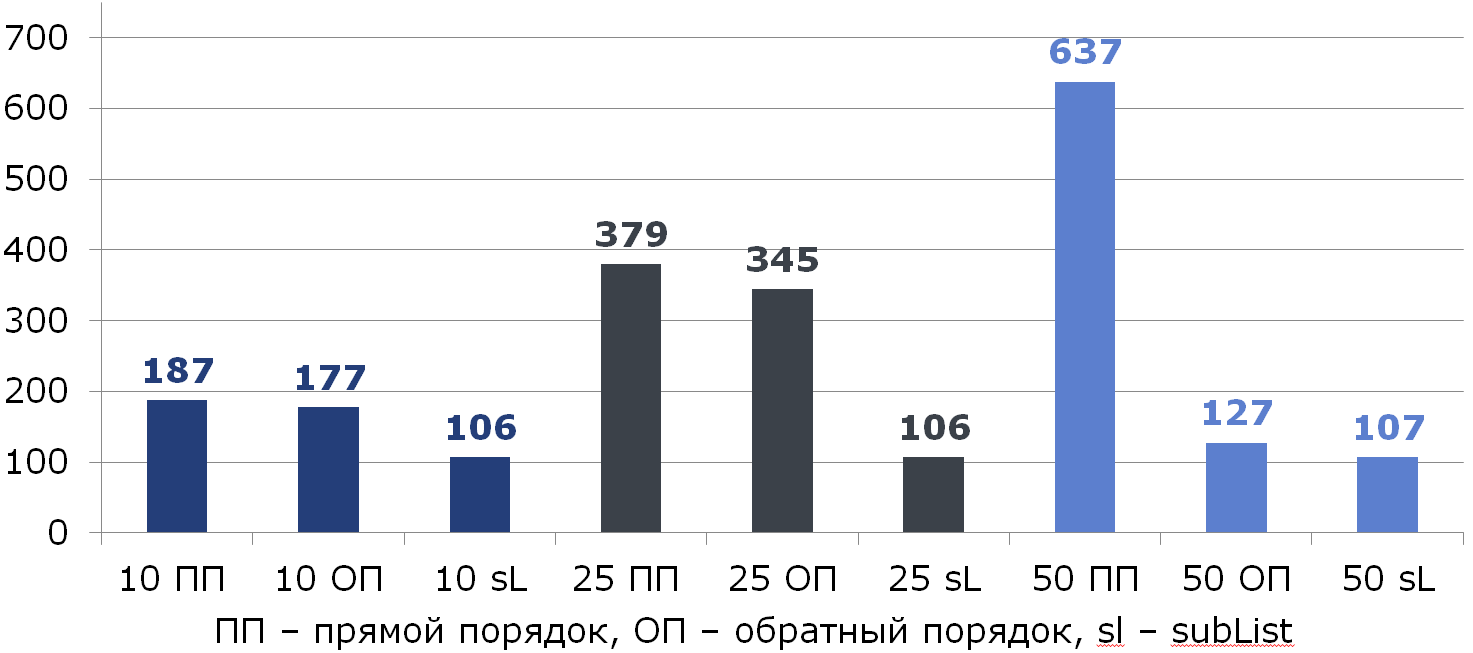
By the way, did someone notice the anomaly?

If we delete half of all data, moving from the end, the last element is always deleted and no shift occurs:
// ArrayList public E remove(int index) { rangeCheck(index); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { // <---- System.arraycopy(elementData, index+1, elementData, index, numMoved); } elementData[--size] = null; // clear to let GC do its work return oldValue; } https://youtrack.jetbrains.com/issue/IDEA-177466IDEA-177466 Detect List.remove (index) called in a loop
Fixed in 2018.2
Conclusion: mass operations are often faster than single.
Scope and performance
This code does not need special explanations:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving(); // <---- if (settings.leaveBothCategories()) { leaveForTheSecondYear(naughty, underAchieving); // <---- return; } leaveForTheSecondYear(naughty); } We narrow the scope, which gives a minus 1 request:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving(); // <---- leaveForTheSecondYear(naughty, underAchieving); // <---- return; } leaveForTheSecondYear(naughty); } And here the attentive reader should ask: what about static analysis? Why did the “Idea” not tell us about the improvement on the surface?
The fact is that the possibilities of static analysis are limited: if the method is complex (especially interacting with the database) and affects the general state, then the transfer of its execution can break the application. A static analyzer is able to report very simple versions, the transfer of which, say, inside the unit will not break anything.
As an ersatz, you can use the highlighting of variables, but, I repeat, use caution, since side effects are always possible. You can use the @org.jetbrains.annotations.Contract(pure = true) annotation , available from the jetbrains-annotations library, to indicate methods that do not change state:
// com.intellij.util.ArrayUtil @Contract(pure = true) public static int find(@NotNull int[] src, int obj) { return indexOf(src, obj); } Conclusion: most often, extra work only degrades performance.
The most unusual example
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true) // <---- public int countContracts(Dto dto) { if (dto.isInvalid()) { return -1; // <---- } return contractCounter.countContracts(dto); } } This implementation opens a transaction even when no transaction is needed (quick return -1 from the method).
All that needs to be done is to remove the transactionism inside the ContractCounter::countContracts , where it is needed, and remove it from the "external" method.
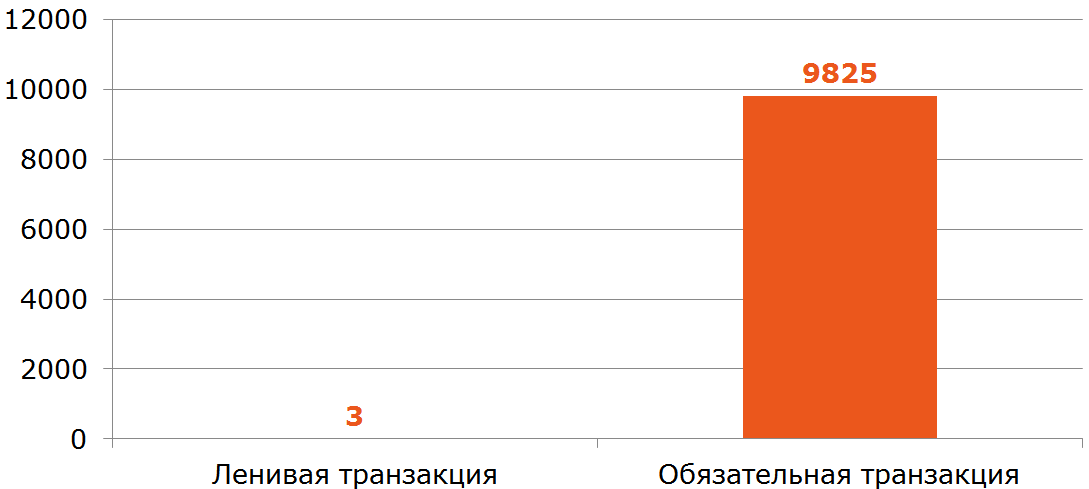
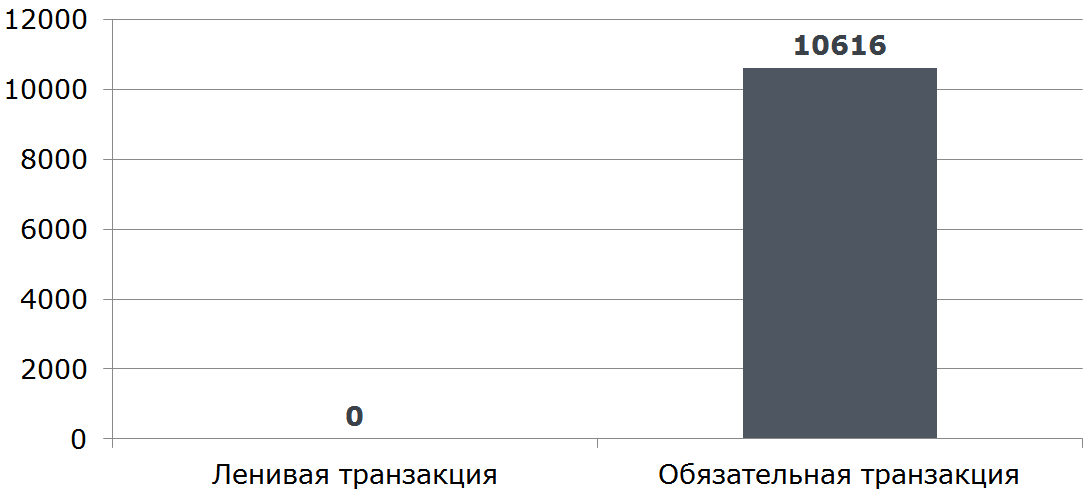
Conclusion: controllers and looking outward services should be freed from transactionalities (this is not their responsibility) and all the logic of input data validation that does not require access to the database and transactional components should be carried out.
Convert date / time to string
One of the eternal tasks is turning a date / time into a string. Up to the "eight" we did this:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date); With the release of JDK 8, we have LocalDate/LocalDateTime and, accordingly, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate); Let's measure its performance:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); } 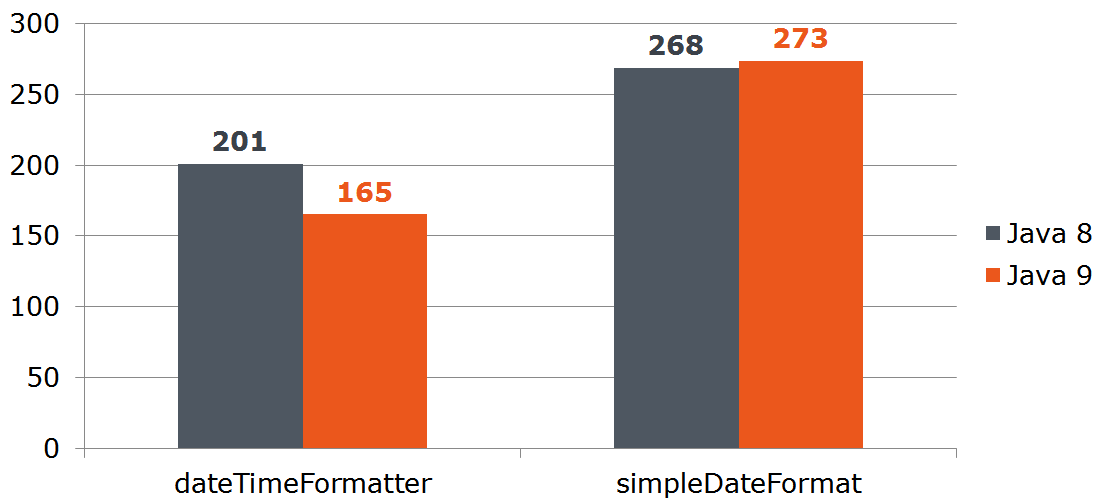
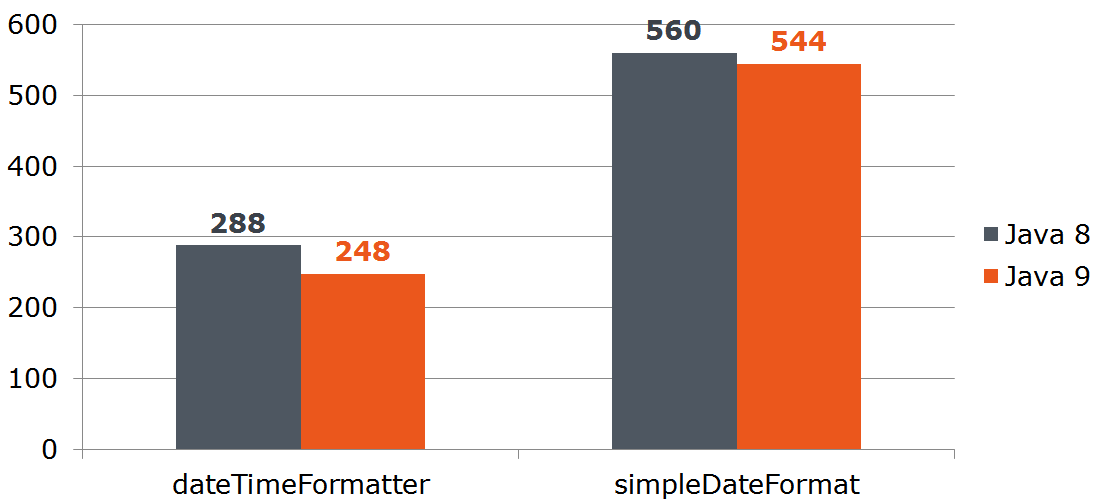
Question: let's say our service receives data from the outside and we cannot refuse java.util.Date . Will it be profitable for us to convert Date to LocalDate if the latter is faster converted to a string? Calculate:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); } 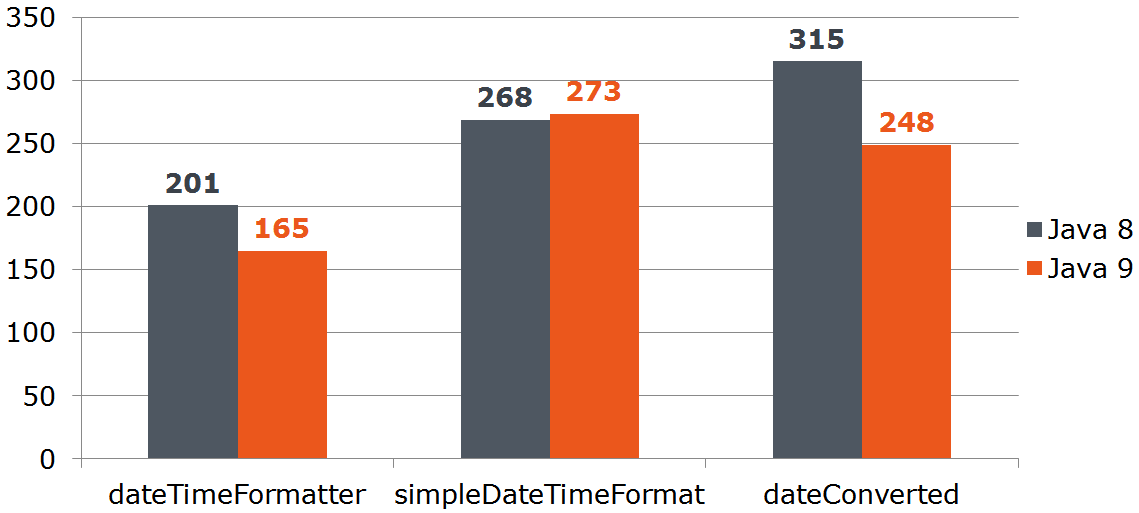

Thus, the Date -> LocalDate beneficial when using the "nine". At the "eight", the costs of conversion will devour all the advantages of DateTimeFormatter -a.
Conclusion: take advantage of new solutions.
Another "eight"
In this code, we see obvious redundancy:
Iterator<Long> iterator = items // ArrayList<Integer> .stream() .map(Long::valueOf) .collect(toList()) // <---- ? .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); } Remove it:
Iterator<Long> iterator = items // ArrayList<Integer> .stream() .map(Long::valueOf) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); } 

Amazing isn't it? Above, I argued that excess work degrades performance. But we remove too much - and (suddenly) it gets worse. To understand what is happening, take two iterators and look at them under a magnifying glass:
Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator(); 
The first iterator is the usual ArrayList$Itr .
public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; } 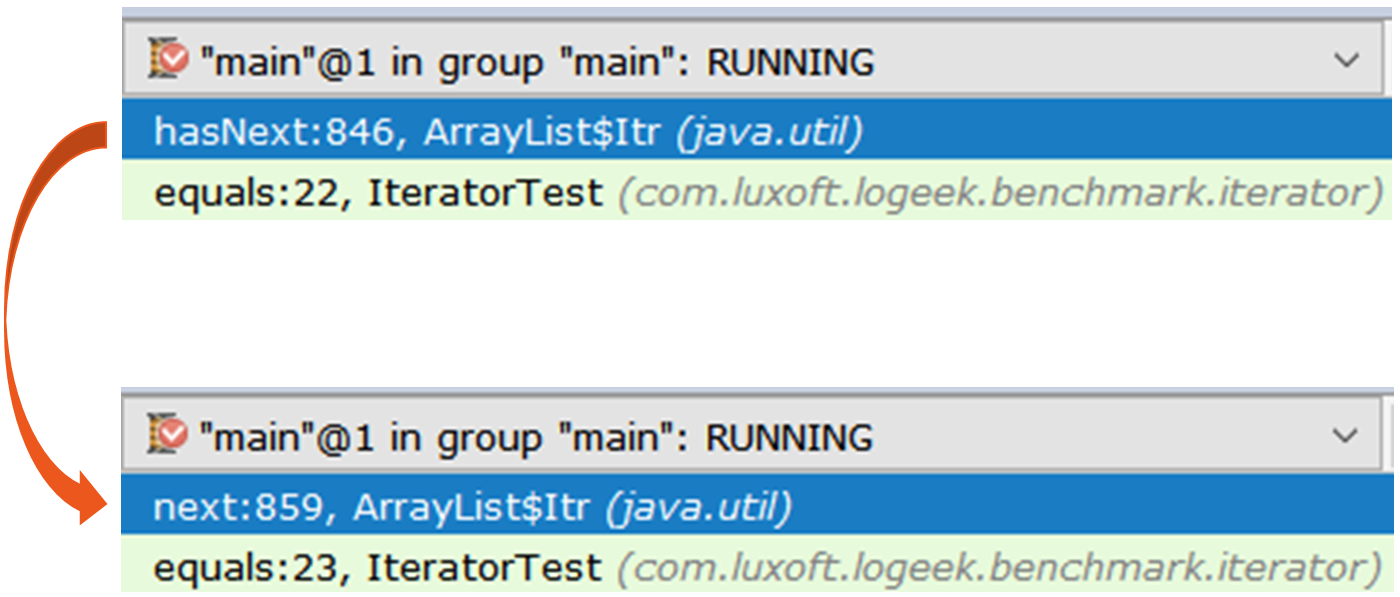
The second is more curious, it is Spliterators$Adapter , based on the ArrayList$ArrayListSpliterator .
// java.util.Spliterators$Adapter public boolean hasNext() { if (!valueReady) spliterator.tryAdvance(this); return valueReady; } public T next() { if (!valueReady && !hasNext()) throw new NoSuchElementException(); else { valueReady = false; return nextElement; } } 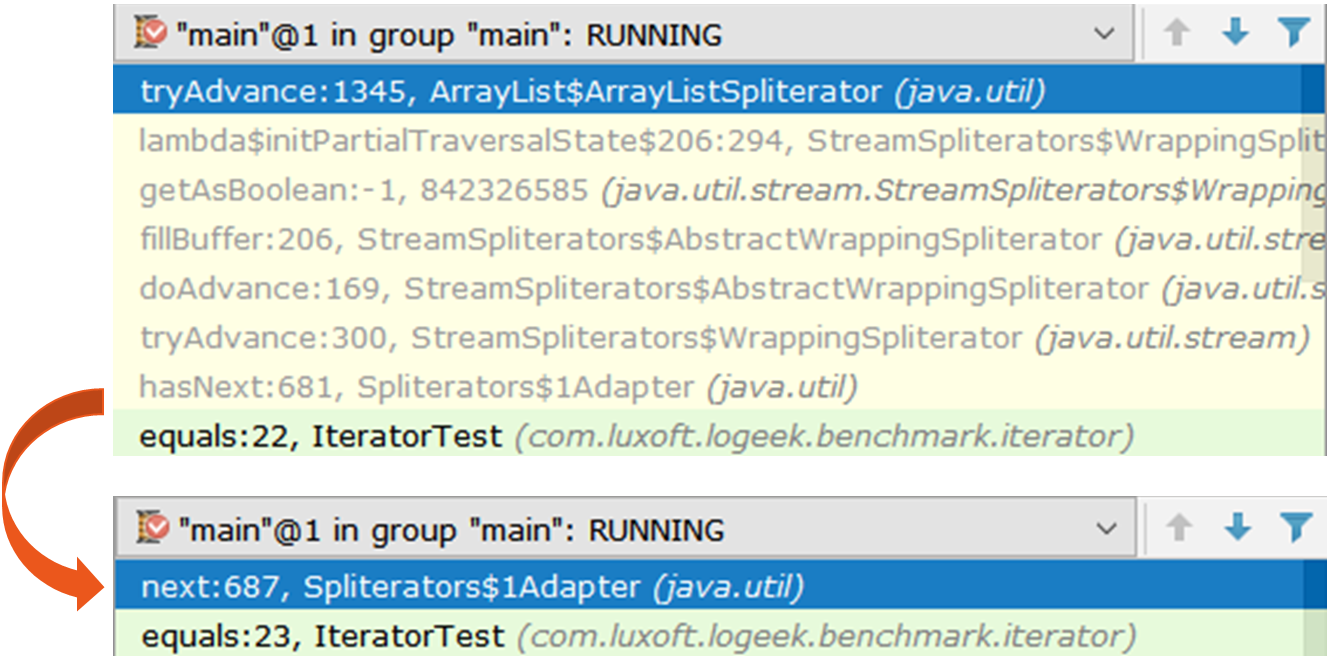
Let's look at iterating through the async-profiler iterator:
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply It can be seen that most of the time is spent on passing through the iterator, although by and large, we do not need it, because the search can be done in the following way:
items .stream() .map(Long::valueOf) .forEach(bh::consume); 
Stream::forEach clearly a winner, but this is strange: the ArrayListSpliterator is still the basis, but the performance of its use has improved significantly.
29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map In this profile, most of the time is spent on “swallowing” the values inside the Blackhole . Compared to the iterator, much of the time is spent directly on executing a Java code. It can be assumed that the cause is a smaller proportion of garbage collection, compared with iterator iteration. Check:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op And indeed, Stream::forEach gives you half the memory consumption.
The call chain from the beginning to the “black hole” looks like this:
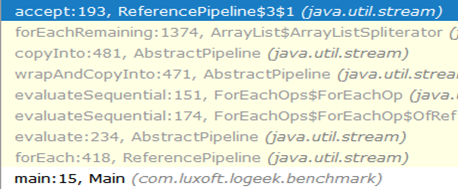
As you can see, the ArrayListSpliterator::tryAdvance call disappeared from the chain, and ArrayListSpliterator::forEachRemaining appeared ArrayListSpliterator::forEachRemaining :
// ArrayListSpliterator public void forEachRemaining(Consumer<? super E> action) { int i, hi, mc; // hoist accesses and checks from loop ArrayList<E> lst; Object[] a; if (action == null) throw new NullPointerException(); if ((lst = list) != null && (a = lst.elementData) != null) { if ((hi = fence) < 0) { mc = lst.modCount; hi = lst.size; } else mc = expectedModCount; if ((i = index) >= 0 && (index = hi) <= a.length) { for (; i < hi; ++i) { @SuppressWarnings("unchecked") E e = (E) a[i]; // <---- action.accept(e); } if (lst.modCount == mc) return; } } throw new ConcurrentModificationException(); } The high speed of ArrayListSpliterator::forEachRemaining achieved by using the entire array in a ArrayListSpliterator::forEachRemaining method call. When using an iterator, the passage is limited to one element, so we always run into ArrayListSpliterator::tryAdvance .ArrayListSpliterator::forEachRemaining has access to the entire array and ArrayListSpliterator::forEachRemaining over it with a counting cycle without additional calls.
Note that mechanical replacement
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); } on
items .stream() .map(Long::valueOf) .forEach(bh::consume); not always equivalent, since in the first case we use a copy of the data for the passage, without affecting the stream itself, while in the second case the data is taken directly from the stream.
Conclusion: in dealing with complex data representations, be prepared for the fact that even the "iron" rules (too much work hurts) stop working. The example above shows that the seemingly superfluous intermediate list gives an advantage in the form of a faster implementation of the search.
Two tricks
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]); // <---- The first thing that catches your eye is a foul "improvement", namely, the transfer to the Collection::toArray array of nonzero length. Here it is very detailed why it hurts.
The second problem is not so obvious, and for its understanding it is possible to draw a parallel between the work of the reviewer and the historian.
, , [] – . . , , ...
. :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth); // 0 // StackTraceElement[] newTrace = Arrays.copyOfRange(trace, 0, depth); // 0 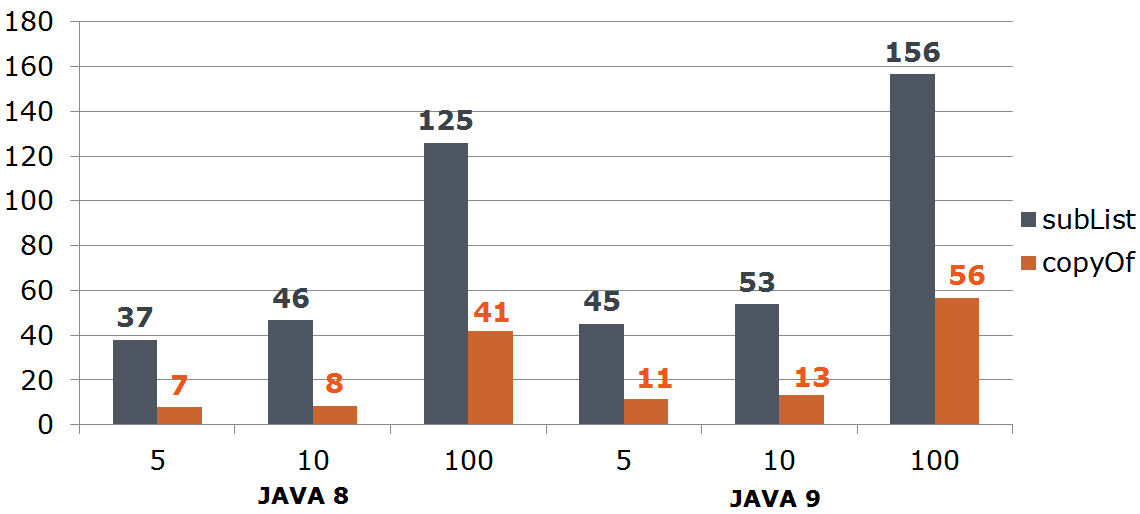
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains); // ? , , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list); 
:
interface FileNameLoader { String[] loadFileNames(); } :
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) { // <---- use(str); } } , forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) { // <---- use(str); } } 
https://youtrack.jetbrains.com/issue/IDEA-182206IDEA-182206 Simplification for Arrays.asList().subList().toArray()
2018.1
https://youtrack.jetbrains.com/issue/IDEA-180847IDEA-180847 Inspection 'Call to Collection.toArray with zero-length array argument' brings pessimization
2018.1
https://youtrack.jetbrains.com/issue/IDEA-181928IDEA-181928 Stream.allMatch(Collection::contains) can be simplified to Collection.containsAll()
2018.1
https://youtrack.jetbrains.com/issue/IDEA-184240IDEA-184240 Unnecessary array-to-collection wrapping should be detected
2018.1
: :
, , , . , : "" ( ), "" ( ), .
')
Source: https://habr.com/ru/post/423305/
All Articles