Storage project on MS SQL Server, integration with 1C 7.7 and development automation in SSDT
Time flows and soon there will be almost nothing left from this development, but I still couldn’t have time to describe it.
It will be about a federal company with a large number of branches and sub-branches. But, as usual, it all started a long time ago with one small shop. Over the years, there was a fairly rapid and spontaneous development, branches, divisions and other offices appeared, and the IT infrastructure was not given due attention at that time, and this is also a frequent phenomenon. Of course, 1C77 was used everywhere, without any replication or scaling, therefore, you know, in the end they came to the conclusion that the frankenstein was spawned with tentacles tied with electrical tape — in each branch there was an autonomous mutant that shared with the central base in the "knee-length" mode, only a few directories, without which, well, there was no way at all, and the rest is autonomous. For a while they were content with copies (dozens of them!) Of branch bases in the central office, but the data in them lagged behind for several days.
')
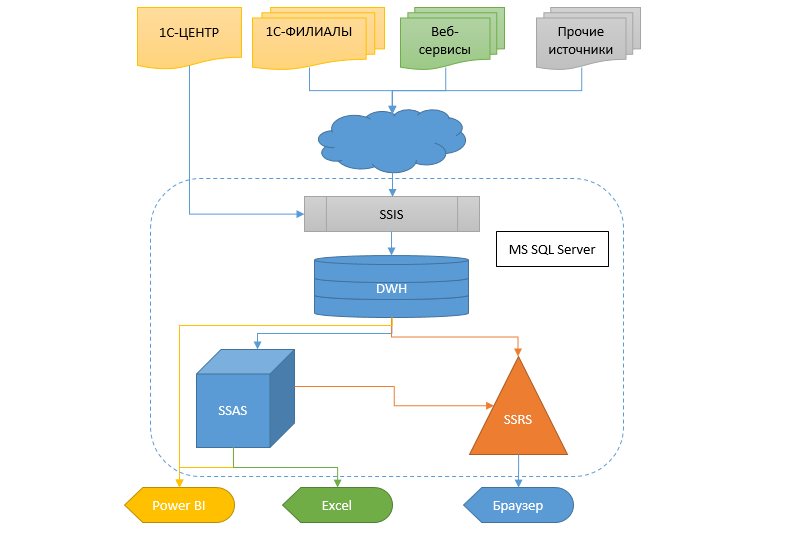
The reality requires receiving information more quickly and flexibly, and something else needs to be done about it. To change from one accounting system to another at such scales is still a swamp. Therefore, it was decided to make a data warehouse (HH) into which information would flow from different databases, so that later other services and analytical system could receive data in the form of cubes, SSRS reports and protocols from this HD.
Looking ahead, I will say that the transition to a new accounting system has almost happened and most of the project described here will be cut out as soon as unnecessary. It is a pity, of course, but nothing can be done.
This is followed by a long article, but before you begin to read, let me say that in no case do I issue this decision as a standard, but someone may find something useful in it.
I will start with a general approach to the project, for which SSDT was chosen as the development environment, with the subsequent publication of the project in Git. I think that today there are enough various articles and tutorials describing the strengths of this tool. But there are a few points whose problem lies outside this environment.
With regards to versions and listings, the project requirements implied:
Since Since enumerations often store logic and are basic values, without which adding records to other tables becomes impossible (due to FK foreign keys), in fact they are part of the database structure, along with metadata. Therefore, changing any element of the enumeration leads to an increment in the database version and, together with this version, the records must be updated to be updated during deployment.
I think all the advantages of deployment blocking without version increment are obvious, one of which is the impossibility of re-launching the publication script if it has already been successfully completed earlier.
Although the network often suggests using only the major version (without fractions) in the network, we decided to use versions in XY format, where Y is a patch, when a typo was corrected in the description of the table, column, the name of the enumeration element or something else small, type of adding a comment to a stored procedure, etc. In all other cases, the major version is increased.
Perhaps for someone there is nothing like this and everything is obvious. But in my time, it took quite a few nerves and forces to internal disputes about how to store transfers in the database project, so that it would be Fengshui ( in accordance with my idea of it ) and so that it was convenient to work with them, at the same time minimizing the likelihood of errors.
With enumerations, in general, everything is simple - we create a PostDeploy file in the project and write code in it to populate the tables. With merdzhami or trunks - this is someone as you like. We chose to merge, first checking whether the number of records in the target table does not exceed the number of records that is in the source (project). If it exceeds, then an exception is called to draw attention to it, for it is strange. Why is there less records in the source? Because one extra? Why should I? And if the database already has links to it? Although we use foreign keys (FK), which will not allow deleting an entry if there are links to it, they still preferred to leave this option. As a result, PostDeploy has turned into an unreadable sheet, because for each table being filled, in addition to the values themselves, there is also a verification code, merge, and so on.
However, if you use PostDeploy in SQLCMD mode, then you can put code blocks into separate files, and as a result only a structured list of file names remains to fill the enumerations in PostDeploy.
With versions of the database there are nuances. On the Internet, there have long been debates about where to store the version of the database, how it should look, and in general, should it be stored somewhere? Suppose we decided that we need it, where in the project to store it? Somewhere in the wilds of the PostDeploy script or put it in a variable that is declared in the first line of the script?
In my opinion - neither one nor the other. It is more convenient when it is stored in a separate file and there is nothing else there.
Someone will say - in the properties of the project there is the same dacpac and in it you can set the version. Of course, you can even pull up this version in your script, as described here , but this is inconvenient - to change the version of the database, you need to go somewhere far, click a bunch of buttons. I do not understand the logic of the microsoftware - they hid it in a far corner, along with such database parameters as sorting, compatibility level, etc., because the database version changes as often as the sorting parameters, right? When ongoing development is underway, the version grows with each new deployment, and the convenience of tracking changes also plays an important role, because when the modified file with a clear name is lit is one thing, and when the project file is .sqlproj, in which there are many lines in the XML format , and among them, somewhere in the center of the line, one changed digit is highlighted, somehow not very much.
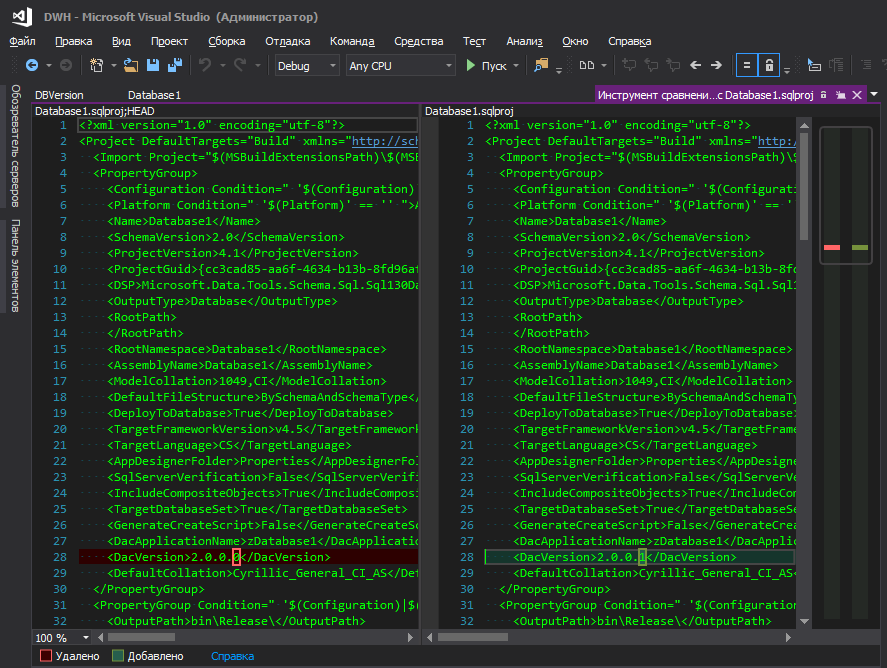
That's better
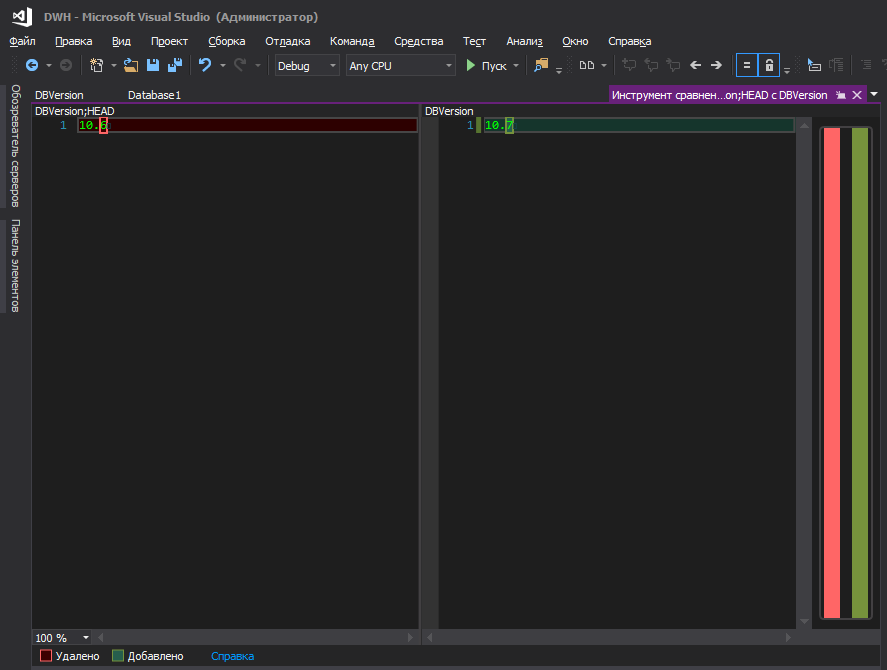
However, perhaps this is only my cockroaches and should not pay attention to them.
Now the question is: where to store this version already in the deployed database. Again, it seems that dacpac does it beautifully - it writes everything to the system labels, but to see the version, you need to execute the request (or can it be otherwise, but I just do not know how to prepare them? It seems that in older versions of SSMS there was an interface for this, but now not)
for the administrator (and not only) it is not very convenient. It is much more logical that the version would be displayed directly in the properties of the database itself.

Or not?
To do this, you need to add a file to the project, which is included in the construction that describes the extended properties.
Yes, they are empty, and it looks ugly in the publication script, but it is impossible without them. If they are not described in the project, and they are in the database, the studio will try to remove them every time it is deployed. (There were many attempts to circumvent this succinctly and without unnecessary options during deployment, but to no avail)
Values for them will be set in the PostDeploy script.
Well, it would be nice to keep history, on the subject of who and when deployed the database.
You can deploy metadata changes in the transaction using standard tools by selecting the Enable transaction scripts check box in the Advanced Publishing Settings window. But this flag does not affect scripts (Pre / Post) deploy and they continue to run without a transaction. Of course, nothing prevents you from starting a transaction at the beginning of the PostDeploy script, however, this will be a separate transaction from the metadata, and our task is to roll back the metadata changes if an exception has occurred in PostDeploy.
The solution is simple - start a transaction in PreDeploy, and fix it in PostDeploy, and do not use any checkboxes in the publishing parameters for this purpose.
To make the database version convenient to store in the project and to register it in the desired places during deployment, you can resort to the SQLCMD variables. However, I do not want to store the version somewhere in the wilds of the code, I want it to be on the surface.
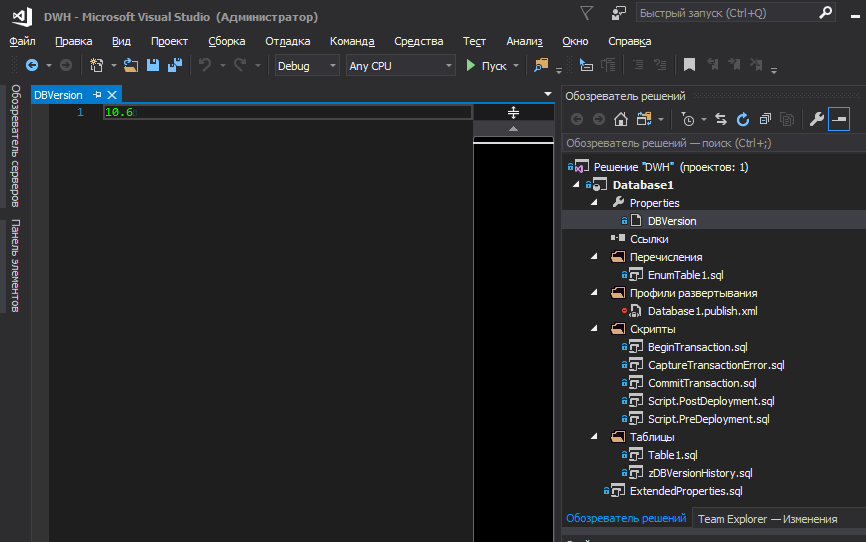
To place the base version in a separate file at the project level and manage the version from there, add the following block to .sqlproj:
This is an instruction for MSBuild to read a string from a file before construction and to create a temporary file based on the read data. MSBuild will create a temporary file
After such manipulations, you can refer to this temporary file from the PreDeploy script and start the global transaction in it:
The
When deploying
Ideally, of course, I would like the version to be displayed at the time of publication.

But it is impossible to pull the value from the file into this window, although MSBuild reads it and places it in the ExtDBVersion property using additional instructions in the .sqlproj file, as in the example above, but the design
does not roll.
The developers of the sequel in their web blog write how to do it. According to their version, the magic lies in the
and ready. Nice try, but no. Perhaps, when this blog entry was published, everything worked, but since then in these Americans of yours they managed to go through the presidential elections three times and no one knows what instruction may stop working tomorrow.

And here one comrade tried all the options, but none of them took off.
Therefore, either take the version from dacpac, or store it in PostDeploy, or in a separate file, or _________ (enter your own version).
The first problem was that the 1C77 has no application server or other daemon that allows you to interact with it without launching the platform. Who worked with 1C77, knows that she does not have a full console mode. You can run the platform with parameters and even do something based on them, but there are very few console parameters and their purpose was different. But even with their help, one can combine a whole combine. However, it can fly out unpredictably, it can display a modal window and wait for someone to click OK and other charms. And, perhaps, the biggest problem - the speed of the platform leaves much to be desired ... Therefore, there is only one solution - direct queries to the 1C database. Considering the structure, it is impossible to simply take and write these requests, but the benefit is that there is a whole community, which at one time developed a great tool - 1C ++ (1cpp.dll), incredible THANKS to it for it! The library allows you to write queries in terms of 1C, which are then converted into real names of tables and fields. If someone does not know, then the request can be written using pseudo names and it will look like this
Such a request is understandable to a person, but there is no such table and field on the server, there are other names, so 1C ++ will turn it into
and such a request is already clear to the server. Everyone is happy, no one swears - neither man nor server. There seems to be a question resolved.
The second problem lay in the configuration plane: in branches, one configuration was used, in the central office another, and in the sub-branches - the third! Class? !! 1 I think so too. And all of them are not typical, and even not a heritage of typical ones, but completely written from scratch in the time of the Vikings and, unfortunately, the foundation of these confes was laid not by the best architects ... Document Implementation, for example, has a different set of details in each configuration. But it is not only the names of some fields that are different, where the names of the details are the same, but the meaning of the data stored in them is DIFFERENT.

In configurations almost no registers are used, everything is built on the intricacies of documents. Therefore, sometimes you had to write a whole sheet on a clean transaction, with a bunch of cases and joins, to repeat the logic of some procedure from the configuration that displays some information in a text field on a form.
We must pay tribute to the development team, which all these years have supported what they inherited from the "implementers", it is a lot of work - to maintain this and even optimize something. Until you see it - you will not understand, at first I myself did not believe that everything could be so difficult. Ask - why not rewrite from scratch? Banal lack of resources. The company developed so quickly that, despite a large team of programmers, they simply did not keep up with the needs of the business, not to mention rewriting the entire concept.
We continue the story of the requests. Obviously, all the data extraction blocks were wrapped in storage so that they could later be run on the server side bypassing the 1C platform. The rule was this: one store is responsible for retrieving one entity. Since Wishlist at the start stage has already accumulated a lot, because it has become painful over the years, then the storage has turned out a few dozen.
The third problem is how to increase the speed and quality of development, and how can we support all this monster? Write a request for 1C ++ and copy-paste the result of its conversion to the storage? It is very inconvenient and tedious, besides the likelihood of errors is great - copy the wrong and wrong place or not select the last line of the request and copy without it. This is especially true when it comes to direct 1C queries, because there are no pseudo-names of the Directory type. Nomenclature. Article, only real names SC2235.SP5278 and therefore it is very easy to copy the request from under the directory of products into the store that retrieves customers. Of course, the query is likely to fall down due to inconsistencies between the types and the number of fields in the destination table, but there are identical labels, such as enumerations, where only two columns are the ID and the Name. In general, there remains only to apply some kind of automation. Well, enough of the lyrics, let's get down to business!
It would be desirable, that process of development was reduced to approximately such actions:
To solve the third problem, an external processing (.ert) was written. In processing, there are a number of procedures, each of which contains the text of a query for retrieving a single entity using pseudo-names, such as
There is a field on the processing form to display the result of the work of a procedure, i.e. request, converted to understandable for the server so that you can quickly try it in. Plus, this request is always added to the debugging block , with the declaration of variables, the names of test databases, servers, and so on. It remains only to copy-paste into SSMS and press F5. You can, of course, execute this request from the processing itself, but the request plan and all that, well, you understand ... In general, this is how debugging is done. Since There are several configurations; it is possible to convert the same query texts with pseudo-names of objects into final queries for different configurations. After all, the Nomenclature is SC123 in one directory, and SC321 in the other. But 1C ++ allows you to load different confesses in rantaime and for each of them generate individual output in accordance with the dictionary.
Next, the batch run mode was added to the processing, when it automatically starts each of the procedures for each configuration, and the output of each of them writes to the .sql files (hereinafter referred to as the base files). Thus, we get a bunch of basic file combinations, which should then automatically be converted into stored procedures using VS. It is worth noting that the basic files include a debugging unit .
It would seem, why not draw the output directly to the final files of stored procedures and keep everything in this processing? The fact is that for some tests, it is necessary to batchly run debug versions of requests in which all variables are declared, plus I wanted the names of stored procedures to be managed from VS, bypassing the launch of 1C, because this is logical, isn't it?
By the way, the base files are also stored in the project, well, and the files of the finished stored procedures, of course. At any time, without starting 1C, you can open the base file in SSMS and execute it without bothering with the declaration of variables.
In processing, all procedures with queries are also template, having the same set of parameters, but in one procedure or another only the necessary parameters are used. In some, everything is involved, and in some, two is enough. Therefore, adding a new procedure is reduced to copying the template and filling in the parameters with the requests themselves.
The code of one of the processing procedures that later becomes a stored procedure.
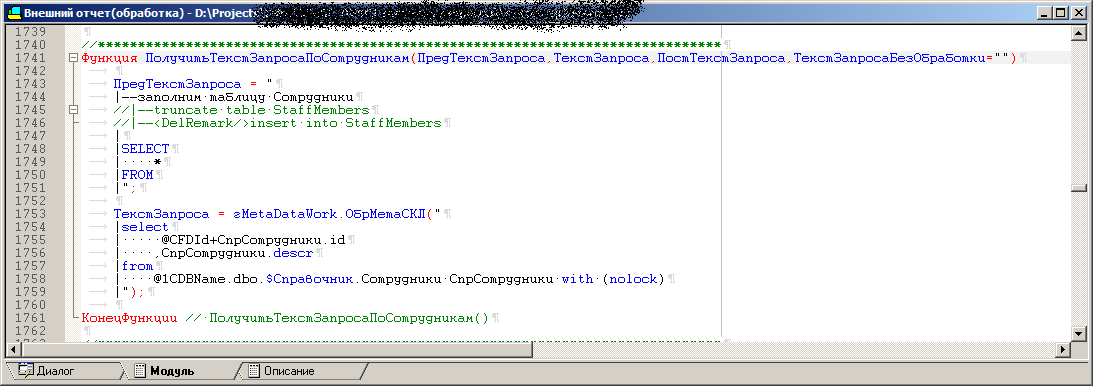
The final query is approximately as follows:
Appearance processing

When switching configurations, the list of available (necessary) for uploading items in the Data list also changes. If possible, the code of procedures in 1C maximally unified. If counterparties are extracted and in different configurations these directories have inconsistencies, then there are different cases inside the generation procedure, such as: this block is fixed for everyone, this one is added to the final query only for such a conf, and that one is for another. It turns out that the stored procedures for one entity but different configurations may differ not only by the names of the tables, but by the whole blocks of joins present in one and missing in another. The set of output fields, of course, is the same and corresponds to the receiver table or container of the SSIS packet, some fields are clogged with plugs for configurations in which these details are not present in principle.
Magic button
In Visual Studio, there are tools such as MSbuild and some absolutely wonderful T4 templates. Therefore, a C # script for T4 was written as a magic button, which:
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
, OPENQUERY , 1 , , , , EXEC . OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
— . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
Since 1 , , . , ,
, ( ) -, « 1-» .
SSIS
SSIS SQL Server (SQL Server Destination), , OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). Those. , . , , . - — . .
, (.. ) .
, , .
, , , , . — , . - , , .
It will be about a federal company with a large number of branches and sub-branches. But, as usual, it all started a long time ago with one small shop. Over the years, there was a fairly rapid and spontaneous development, branches, divisions and other offices appeared, and the IT infrastructure was not given due attention at that time, and this is also a frequent phenomenon. Of course, 1C77 was used everywhere, without any replication or scaling, therefore, you know, in the end they came to the conclusion that the frankenstein was spawned with tentacles tied with electrical tape — in each branch there was an autonomous mutant that shared with the central base in the "knee-length" mode, only a few directories, without which, well, there was no way at all, and the rest is autonomous. For a while they were content with copies (dozens of them!) Of branch bases in the central office, but the data in them lagged behind for several days.
')
The reality requires receiving information more quickly and flexibly, and something else needs to be done about it. To change from one accounting system to another at such scales is still a swamp. Therefore, it was decided to make a data warehouse (HH) into which information would flow from different databases, so that later other services and analytical system could receive data in the form of cubes, SSRS reports and protocols from this HD.
Looking ahead, I will say that the transition to a new accounting system has almost happened and most of the project described here will be cut out as soon as unnecessary. It is a pity, of course, but nothing can be done.
This is followed by a long article, but before you begin to read, let me say that in no case do I issue this decision as a standard, but someone may find something useful in it.
I will start with a general approach to the project, for which SSDT was chosen as the development environment, with the subsequent publication of the project in Git. I think that today there are enough various articles and tutorials describing the strengths of this tool. But there are a few points whose problem lies outside this environment.
Storage of transfers and database versions
With regards to versions and listings, the project requirements implied:
- Ease of editing and tracking changes in the database version within the project
- Ease of viewing the database version via SSMS for admins
- Saving history of version changes in the database itself (who performed the deployment and when)
- Storage in a project enumerations
- Ease of editing and tracking changes in listings
- Blocking the database deployment over the existing one if there was no version increment
- Installing a new version, recording history, enumeration and restructuring should be performed in one transaction and completely rolled back in case of failure at any of the stages.
Since Since enumerations often store logic and are basic values, without which adding records to other tables becomes impossible (due to FK foreign keys), in fact they are part of the database structure, along with metadata. Therefore, changing any element of the enumeration leads to an increment in the database version and, together with this version, the records must be updated to be updated during deployment.
I think all the advantages of deployment blocking without version increment are obvious, one of which is the impossibility of re-launching the publication script if it has already been successfully completed earlier.
Although the network often suggests using only the major version (without fractions) in the network, we decided to use versions in XY format, where Y is a patch, when a typo was corrected in the description of the table, column, the name of the enumeration element or something else small, type of adding a comment to a stored procedure, etc. In all other cases, the major version is increased.
Perhaps for someone there is nothing like this and everything is obvious. But in my time, it took quite a few nerves and forces to internal disputes about how to store transfers in the database project, so that it would be Fengshui ( in accordance with my idea of it ) and so that it was convenient to work with them, at the same time minimizing the likelihood of errors.
With enumerations, in general, everything is simple - we create a PostDeploy file in the project and write code in it to populate the tables. With merdzhami or trunks - this is someone as you like. We chose to merge, first checking whether the number of records in the target table does not exceed the number of records that is in the source (project). If it exceeds, then an exception is called to draw attention to it, for it is strange. Why is there less records in the source? Because one extra? Why should I? And if the database already has links to it? Although we use foreign keys (FK), which will not allow deleting an entry if there are links to it, they still preferred to leave this option. As a result, PostDeploy has turned into an unreadable sheet, because for each table being filled, in addition to the values themselves, there is also a verification code, merge, and so on.
However, if you use PostDeploy in SQLCMD mode, then you can put code blocks into separate files, and as a result only a structured list of file names remains to fill the enumerations in PostDeploy.
With versions of the database there are nuances. On the Internet, there have long been debates about where to store the version of the database, how it should look, and in general, should it be stored somewhere? Suppose we decided that we need it, where in the project to store it? Somewhere in the wilds of the PostDeploy script or put it in a variable that is declared in the first line of the script?
In my opinion - neither one nor the other. It is more convenient when it is stored in a separate file and there is nothing else there.
Someone will say - in the properties of the project there is the same dacpac and in it you can set the version. Of course, you can even pull up this version in your script, as described here , but this is inconvenient - to change the version of the database, you need to go somewhere far, click a bunch of buttons. I do not understand the logic of the microsoftware - they hid it in a far corner, along with such database parameters as sorting, compatibility level, etc., because the database version changes as often as the sorting parameters, right? When ongoing development is underway, the version grows with each new deployment, and the convenience of tracking changes also plays an important role, because when the modified file with a clear name is lit is one thing, and when the project file is .sqlproj, in which there are many lines in the XML format , and among them, somewhere in the center of the line, one changed digit is highlighted, somehow not very much.
That's better
However, perhaps this is only my cockroaches and should not pay attention to them.
Now the question is: where to store this version already in the deployed database. Again, it seems that dacpac does it beautifully - it writes everything to the system labels, but to see the version, you need to execute the request (or can it be otherwise, but I just do not know how to prepare them? It seems that in older versions of SSMS there was an interface for this, but now not)
select * from msdb.dbo.sysdac_instances_internal for the administrator (and not only) it is not very convenient. It is much more logical that the version would be displayed directly in the properties of the database itself.
Or not?
To do this, you need to add a file to the project, which is included in the construction that describes the extended properties.
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = ''; Yes, they are empty, and it looks ugly in the publication script, but it is impossible without them. If they are not described in the project, and they are in the database, the studio will try to remove them every time it is deployed. (There were many attempts to circumvent this succinctly and without unnecessary options during deployment, but to no avail)
Values for them will be set in the PostDeploy script.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime; sp_updateextendedproperty without any checks, because by the time the block starts from PostDeploy, all properties have already been created if they were not.Well, it would be nice to keep history, on the subject of who and when deployed the database.
You can deploy metadata changes in the transaction using standard tools by selecting the Enable transaction scripts check box in the Advanced Publishing Settings window. But this flag does not affect scripts (Pre / Post) deploy and they continue to run without a transaction. Of course, nothing prevents you from starting a transaction at the beginning of the PostDeploy script, however, this will be a separate transaction from the metadata, and our task is to roll back the metadata changes if an exception has occurred in PostDeploy.
The solution is simple - start a transaction in PreDeploy, and fix it in PostDeploy, and do not use any checkboxes in the publishing parameters for this purpose.
To make the database version convenient to store in the project and to register it in the desired places during deployment, you can resort to the SQLCMD variables. However, I do not want to store the version somewhere in the wilds of the code, I want it to be on the surface.
To place the base version in a separate file at the project level and manage the version from there, add the following block to .sqlproj:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target> This is an instruction for MSBuild to read a string from a file before construction and to create a temporary file based on the read data. MSBuild will create a temporary file
SetPreDepVarsTmp.sql , in which it will :setvar DBVersion $(ExtDBVersion) line :setvar DBVersion $(ExtDBVersion) , where $(ExtDBVersion) is the value read from our file storing the version of the database.After such manipulations, you can refer to this temporary file from the PreDeploy script and start the global transaction in it:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql" Intermediate version
Initially, in the ExtendedProperties.sql file, not empty values were assigned, but values from variables
The variables, in turn, were set in the SetPreDepVarsTmp.sql file automatically by MSBuild like this:
With this approach, you do not need to reinstall these properties in PostDeploy, but the trouble is that SetPreDepVarsTmp.sql contained static values and if the publishing script was generated now, but deployed after an hour, or even worse, the next day (the developer re-tested it for a long time) visually, for example), the date of publication, written in the properties, will differ from the actual date of publication and does not coincide with the date in history.
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; The variables, in turn, were set in the SetPreDepVarsTmp.sql file automatically by MSBuild like this:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target> With this approach, you do not need to reinstall these properties in PostDeploy, but the trouble is that SetPreDepVarsTmp.sql contained static values and if the publishing script was generated now, but deployed after an hour, or even worse, the next day (the developer re-tested it for a long time) visually, for example), the date of publication, written in the properties, will differ from the actual date of publication and does not coincide with the date in history.
Contents of the BeginTransaction.sql file
In essence, this is just copy-paste from the standard transaction start block that the studio generates when the Enable transaction scripts checkbox is checked , but we use it in our own way. In the script, only the temporary table name was changed from
#tmpErrors to #tmpErrorsManual , so that there is no name conflict if someone turns on the checkbox. IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE #tmpErrorsManual GO CREATE TABLE #tmpErrorsManual (Error int) GO SET XACT_ABORT ON GO SET TRANSACTION ISOLATION LEVEL READ COMMITTED GO BEGIN TRANSACTION GO PostDeploy Script
The variable SkipEnumDeploy, as has already become clear, allows you to skip the update process for transfers, this can be useful for minor cosmetic changes. Although, from the point of view of religion, this may be wrong, but at the design stage it definitely comes in handy.
declare @TableName VarChar(255) = null -- if $(SkipEnumDeploy) = 0 begin PRINT N' ...' :r ..\\EnumTable1.sql end -- PRINT N' ...'; declare @username varchar(256) = suser_sname() , @curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') if $(DBVersion) > (select isnull( MAX( DBVersion),0) from zDBVersionHistory) begin insert into zDBVersionHistory( DBVersion, DeploymentDate, DeployerName) values ($(DBVersion),@curdatetime,@username) EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime; end else begin RaisError ( N': , . , DBVersion .' , 16 , 1 ) WITH SETERROR; end GO :r ".\CaptureTransactionError.sql" :r ".\CommitTransaction.sql" The variable SkipEnumDeploy, as has already become clear, allows you to skip the update process for transfers, this can be useful for minor cosmetic changes. Although, from the point of view of religion, this may be wrong, but at the design stage it definitely comes in handy.
The
CaptureTransactionError.sql and CommitTransaction.sql files CaptureTransactionError.sql also copy-paste (with minor edits) from the standard transaction operation algorithm that the studio generates when the above-described check box is set, and which we now reproduce on our own.Content CaptureTransactionError.sql
IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO #tmpErrorsManual (Error) VALUES (1); BEGIN TRANSACTION; END Content CommitTransaction.sql
IF EXISTS (SELECT * FROM #tmpErrorsManual) ROLLBACK TRANSACTION GO DROP TABLE #tmpErrorsManual GO IF @@TRANCOUNT>0 BEGIN PRINT N' .' COMMIT TRANSACTION END ELSE RaisError ( N' .' , 16 , 1 ); Contents EnumTable1.sql
set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists #tmpEnums; select * into #tmpEnums from (values ( 0, ' 1') , ( 1, ' 2') , ( 2, ' 3') ) as tmp ( Id , Title ) set nocount off -- If ((select count(*) from Table1) > (select count(*) from #tmpEnums)) begin RaisError ( N': , .' , 0 , 1 ) WITH SETERROR; end set Identity_insert Table1 on Merge Table1 as target Using ( select * from #tmpEnums except select * from dbo.Table1 ) as source on target.Id = source.Id when matched then update set target.Title = source.Title when not matched by target then insert ( Id , Title ) values ( source.Id , source.Title ); set Identity_insert Table1 off drop table if exists #tmpEnums; END TRY begin catch IF @@trancount > 0 ROLLBACK TRANSACTION set @Error_Message = Error_Message(); RaisError ( N': %s.' , 0 , 1 , @Error_Message ) WITH SETERROR; end catch :r "..\\CaptureTransactionError.sql" When deploying
Publish script will have the following structure -- PreDeploy ----:setvar DBVersion "10.6" -- , DBVersion ---- -- , -- PostDeploy ---- ---- ---- Ideally, of course, I would like the version to be displayed at the time of publication.
But it is impossible to pull the value from the file into this window, although MSBuild reads it and places it in the ExtDBVersion property using additional instructions in the .sqlproj file, as in the example above, but the design
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable> does not roll.
The developers of the sequel in their web blog write how to do it. According to their version, the magic lies in the
SqlCommandVariableOverride statement, from which everything is simple - we add a couple of lines to the .sqlproj project file. <ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup> and ready. Nice try, but no. Perhaps, when this blog entry was published, everything worked, but since then in these Americans of yours they managed to go through the presidential elections three times and no one knows what instruction may stop working tomorrow.
And here one comrade tried all the options, but none of them took off.
Therefore, either take the version from dacpac, or store it in PostDeploy, or in a separate file, or _________ (enter your own version).
Integration with 1C
The first problem was that the 1C77 has no application server or other daemon that allows you to interact with it without launching the platform. Who worked with 1C77, knows that she does not have a full console mode. You can run the platform with parameters and even do something based on them, but there are very few console parameters and their purpose was different. But even with their help, one can combine a whole combine. However, it can fly out unpredictably, it can display a modal window and wait for someone to click OK and other charms. And, perhaps, the biggest problem - the speed of the platform leaves much to be desired ... Therefore, there is only one solution - direct queries to the 1C database. Considering the structure, it is impossible to simply take and write these requests, but the benefit is that there is a whole community, which at one time developed a great tool - 1C ++ (1cpp.dll), incredible THANKS to it for it! The library allows you to write queries in terms of 1C, which are then converted into real names of tables and fields. If someone does not know, then the request can be written using pseudo names and it will look like this
select from $. Such a request is understandable to a person, but there is no such table and field on the server, there are other names, so 1C ++ will turn it into
select SP5278 from SC2235 and such a request is already clear to the server. Everyone is happy, no one swears - neither man nor server. There seems to be a question resolved.
The second problem lay in the configuration plane: in branches, one configuration was used, in the central office another, and in the sub-branches - the third! Class? !! 1 I think so too. And all of them are not typical, and even not a heritage of typical ones, but completely written from scratch in the time of the Vikings and, unfortunately, the foundation of these confes was laid not by the best architects ... Document Implementation, for example, has a different set of details in each configuration. But it is not only the names of some fields that are different, where the names of the details are the same, but the meaning of the data stored in them is DIFFERENT.
In configurations almost no registers are used, everything is built on the intricacies of documents. Therefore, sometimes you had to write a whole sheet on a clean transaction, with a bunch of cases and joins, to repeat the logic of some procedure from the configuration that displays some information in a text field on a form.
We must pay tribute to the development team, which all these years have supported what they inherited from the "implementers", it is a lot of work - to maintain this and even optimize something. Until you see it - you will not understand, at first I myself did not believe that everything could be so difficult. Ask - why not rewrite from scratch? Banal lack of resources. The company developed so quickly that, despite a large team of programmers, they simply did not keep up with the needs of the business, not to mention rewriting the entire concept.
We continue the story of the requests. Obviously, all the data extraction blocks were wrapped in storage so that they could later be run on the server side bypassing the 1C platform. The rule was this: one store is responsible for retrieving one entity. Since Wishlist at the start stage has already accumulated a lot, because it has become painful over the years, then the storage has turned out a few dozen.
The third problem is how to increase the speed and quality of development, and how can we support all this monster? Write a request for 1C ++ and copy-paste the result of its conversion to the storage? It is very inconvenient and tedious, besides the likelihood of errors is great - copy the wrong and wrong place or not select the last line of the request and copy without it. This is especially true when it comes to direct 1C queries, because there are no pseudo-names of the Directory type. Nomenclature. Article, only real names SC2235.SP5278 and therefore it is very easy to copy the request from under the directory of products into the store that retrieves customers. Of course, the query is likely to fall down due to inconsistencies between the types and the number of fields in the destination table, but there are identical labels, such as enumerations, where only two columns are the ID and the Name. In general, there remains only to apply some kind of automation. Well, enough of the lyrics, let's get down to business!
It would be desirable, that process of development was reduced to approximately such actions:
- Fix an SQL query with pseudo names and save it
- Click the magic button and get the output stored procedure on the converted SQL, understandable to the server
Few details
To solve the third problem, an external processing (.ert) was written. In processing, there are a number of procedures, each of which contains the text of a query for retrieving a single entity using pseudo-names, such as
select * from $. There is a field on the processing form to display the result of the work of a procedure, i.e. request, converted to understandable for the server so that you can quickly try it in. Plus, this request is always added to the debugging block , with the declaration of variables, the names of test databases, servers, and so on. It remains only to copy-paste into SSMS and press F5. You can, of course, execute this request from the processing itself, but the request plan and all that, well, you understand ... In general, this is how debugging is done. Since There are several configurations; it is possible to convert the same query texts with pseudo-names of objects into final queries for different configurations. After all, the Nomenclature is SC123 in one directory, and SC321 in the other. But 1C ++ allows you to load different confesses in rantaime and for each of them generate individual output in accordance with the dictionary.
Next, the batch run mode was added to the processing, when it automatically starts each of the procedures for each configuration, and the output of each of them writes to the .sql files (hereinafter referred to as the base files). Thus, we get a bunch of basic file combinations, which should then automatically be converted into stored procedures using VS. It is worth noting that the basic files include a debugging unit .
It would seem, why not draw the output directly to the final files of stored procedures and keep everything in this processing? The fact is that for some tests, it is necessary to batchly run debug versions of requests in which all variables are declared, plus I wanted the names of stored procedures to be managed from VS, bypassing the launch of 1C, because this is logical, isn't it?
By the way, the base files are also stored in the project, well, and the files of the finished stored procedures, of course. At any time, without starting 1C, you can open the base file in SSMS and execute it without bothering with the declaration of variables.
In processing, all procedures with queries are also template, having the same set of parameters, but in one procedure or another only the necessary parameters are used. In some, everything is involved, and in some, two is enough. Therefore, adding a new procedure is reduced to copying the template and filling in the parameters with the requests themselves.
The code of one of the processing procedures that later becomes a stored procedure.
The final query is approximately as follows:
++"("+OPENQUERY()+")"+ Appearance processing
When switching configurations, the list of available (necessary) for uploading items in the Data list also changes. If possible, the code of procedures in 1C maximally unified. If counterparties are extracted and in different configurations these directories have inconsistencies, then there are different cases inside the generation procedure, such as: this block is fixed for everyone, this one is added to the final query only for such a conf, and that one is for another. It turns out that the stored procedures for one entity but different configurations may differ not only by the names of the tables, but by the whole blocks of joins present in one and missing in another. The set of output fields, of course, is the same and corresponds to the receiver table or container of the SSIS packet, some fields are clogged with plugs for configurations in which these details are not present in principle.
Magic button
In Visual Studio, there are tools such as MSbuild and some absolutely wonderful T4 templates. Therefore, a C # script for T4 was written as a magic button, which:
- Registers an empty configuration in the registry (otherwise, 1C will display a modal window with the offer to register a con and wait for user actions)
- Creates an empty database for this config on the SQL server, because without it 1C will generate an error
- It launches 1C and through OLE tells it to perform processing (that .ert), also passing a unique GUID to 1C
- The output is a series of files with ready (converted) requests and a token file to which the GUID written at startup is written.
- Registration of a konfa is deleted from the registry and a temporary empty database is deleted from the server.
- Checks the contents of the token file. If the marker file that we transferred to 1C when it is launched is in the marker file, it means that it worked to the end, did not crash, etc., then proceed to the next step, or output an error
- We create.
- We decompile the .ert file using gcomp to get the module text and form processing, well, convert it to unicode, for later sending to Git and displaying it correctly there. For those who did not work with the 1C: .ert file, this is a binary and the studio along with git trumpeting that the .ert file is changed, but it’s not clear what changed in it, maybe someone just moved the button one pixel to the left (what unacceptable without justification)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
.Is done.
?
Since , , .sqlproj,
On
« ». , , , :)
, , (, ) . ( ), , - - - , .
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup> On
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup> « ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
, OPENQUERY , 1 , , , , EXEC . OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^-- 8 , , , , . , .. ... join ... ) join ... CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END — . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
ETL
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
Since 1 , , . , ,
truncate ., ( ) -, « 1-» .
SSIS
,
SSIS SQL Server (SQL Server Destination), , OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). Those. , . , , . - — . .
, (.. ) .
, , .
PS
, , , , . — , . - , , .
Source: https://habr.com/ru/post/423205/
All Articles