Pizza ala-semi-supervised
In this article I would like to tell you about some of the techniques for working with data when teaching a model. In particular, how to stretch the segmentation of objects on the boxes, as well as how to train the model and get the markup of the dataset, having marked only a few samples.
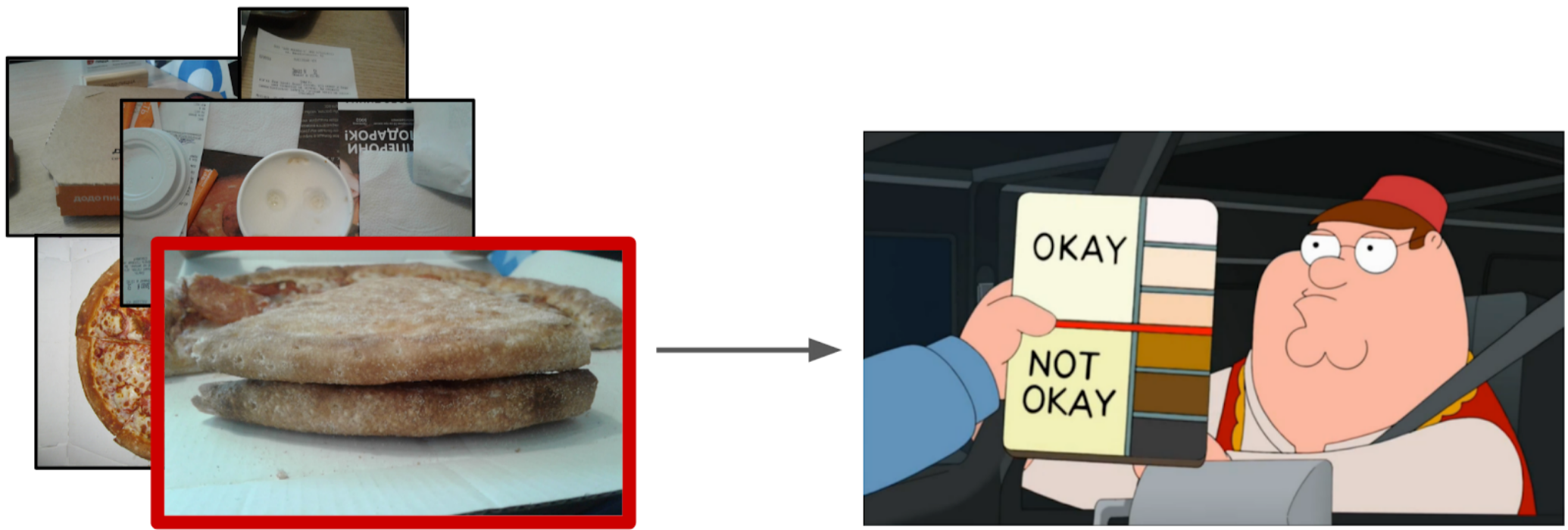
There is a certain process of cooking pizza and photos from its different stages (including not only pizza). It is known that if the dough recipe is spoiled, then there will be white bumps on the cake. There is also a binary markup of the quality of the dough of each pizza made by experts. It is necessary to develop an algorithm that will determine the quality of the test on the photo.
Dataset consists of photos taken from different phones, in different conditions, different angles. Copies of pizza - 17k. Total photos - 60k.
In my opinion, the task is quite typical and well suited to show different approaches to handling data. To solve it you need:
')
1. Select photos where there is a pizza shortbread;
2. On the selected photos to highlight the cake;
3. Train the neural network in the selected areas.
At first glance, it seems that the easiest thing would be to give this task to the markers, and then to train on clean data. However, I decided that it would be easier for me to mark out a small part myself, than to explain with a marker, which angle was the right one. Moreover, I did not have a hard criterion for the correct angle.
Therefore, this is how I acted:
1. Marked 100 pictures of the edge;

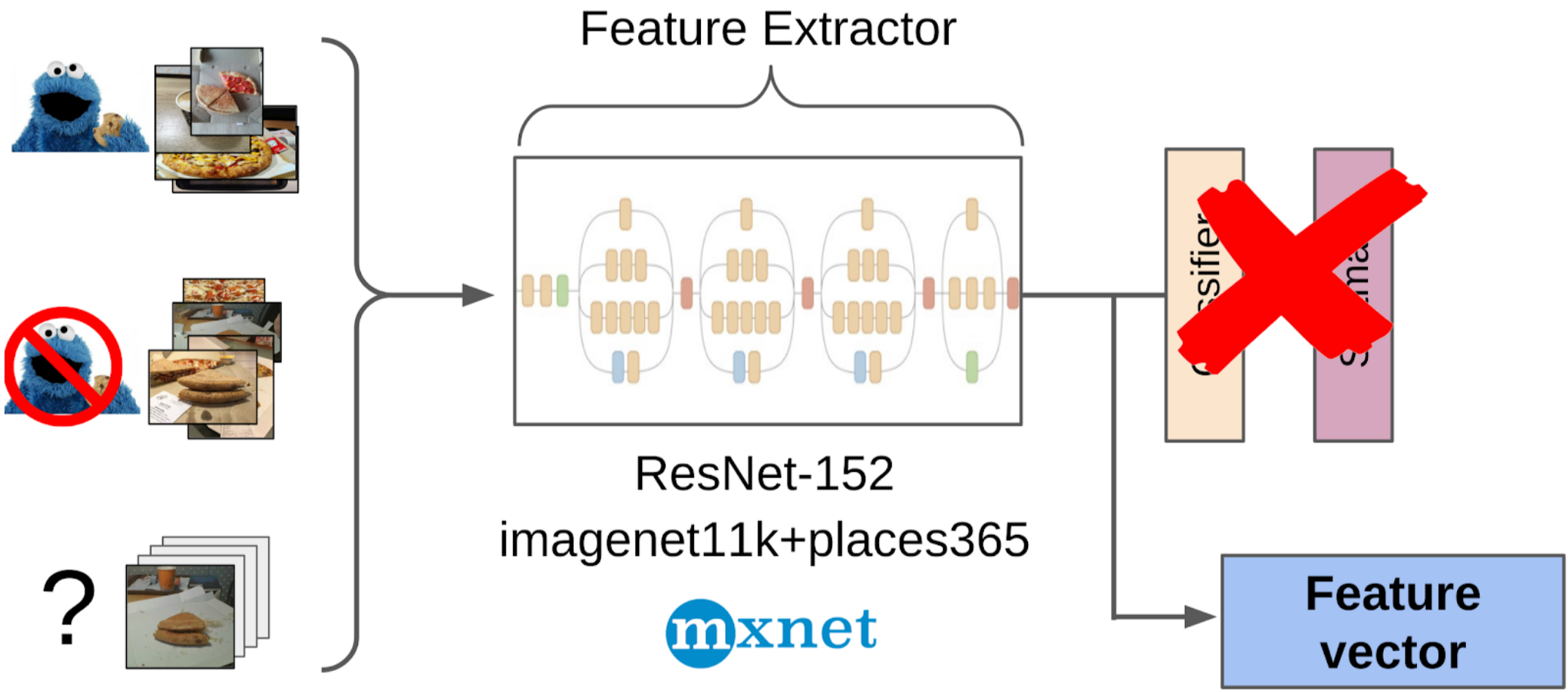
2. I counted features after a global pulling from the resnet-152 grid with weights from imagenet11k_places365;
3. I took the average of the features of each class, getting two anchors;
4. I calculated the distance from each anchor to all features of the remaining 50k photos;
5. Top 300 in proximity to one anchor are relevant to the positive class, the top 500 closest to the other anchor - negative class;
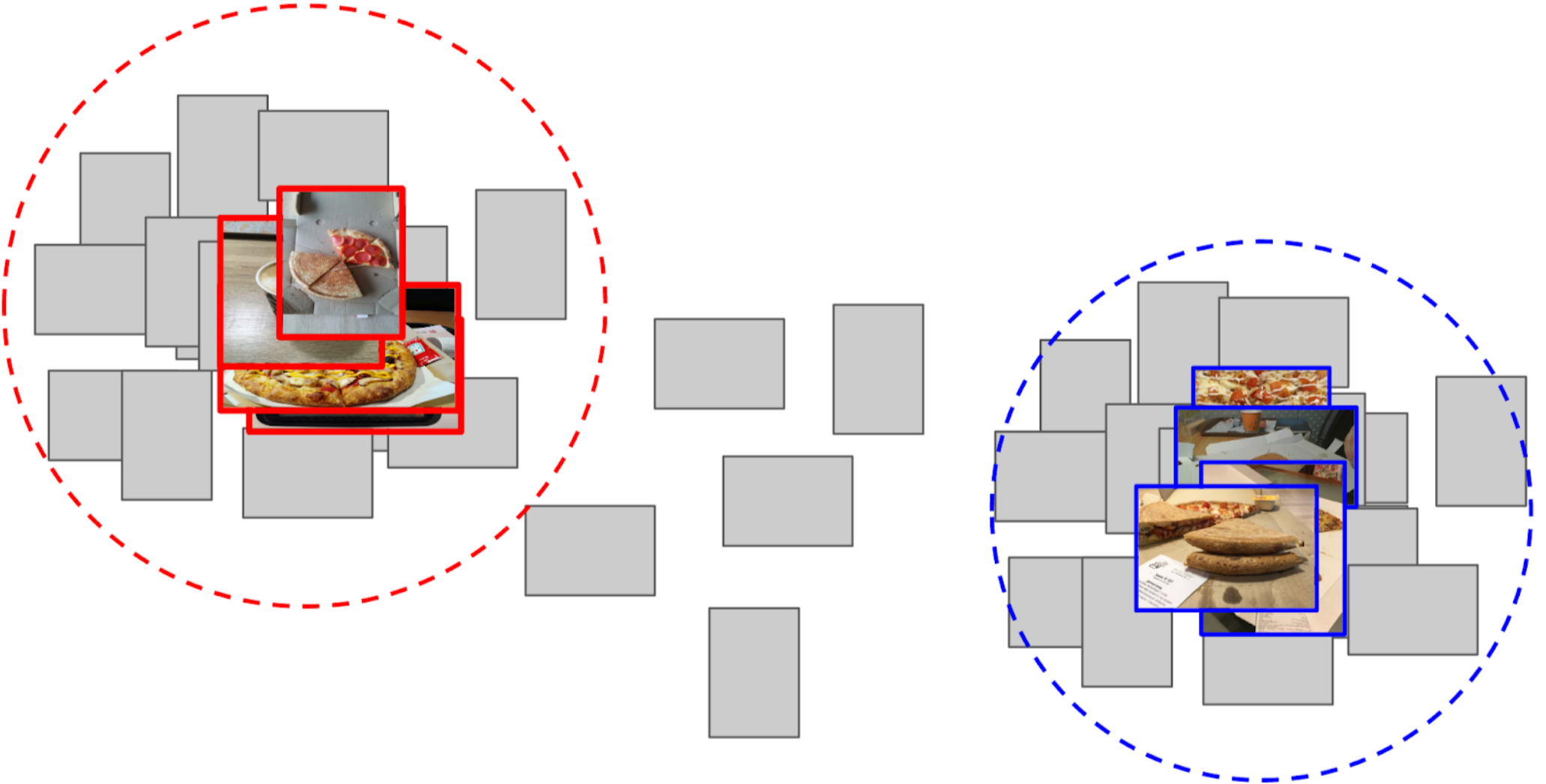
6. In these samples I trained LightGBM on the same features (XGboost is shown in the picture, because it has a logo and is more recognizable, but LightGBM does not have a logo);
7. With the help of this model I got the markup of the whole dataset

I used about the same approach in kaggle competitions as a baseline .
In ODS recently complained that no one wrote about their Fails. Correcting the situation. About a year ago, I participated in the Kaggle Sea Lions competition with Yevgeny Nizhibitsky . The task was to calculate the fur seals in the pictures from the drone. The markup was given simply in the form of the coordinates of the carcasses, but at some point Vladimir Iglovikov marked them with boxes and generously shared it with the community. At that time, I considered myself the father of semantic segmentation (after Kaggle Dstl ) and decided that Unet would greatly facilitate the task of counting if I learned how to distinguish the seals coolly.
Accordingly, I began to teach segmentation, having as a target in the first stage only box seals. After the first stage of training, I predicted the train and looked at what the predictions look like. With the help of heuristics, it was possible to choose from an abstract confidence mask (confidence of predictions) and conditionally divide the predictions into two groups: where everything is good and where everything is bad.

Predictions where everything is good could be used to train the next iteration of the model. Predicts, where everything is bad, it was possible to choose with large areas without seals, to manually mask the masks and also to dock in the train. And so iteratively, we with Eugene taught a model that has learned to even segment the seals of sea lions for large individuals.
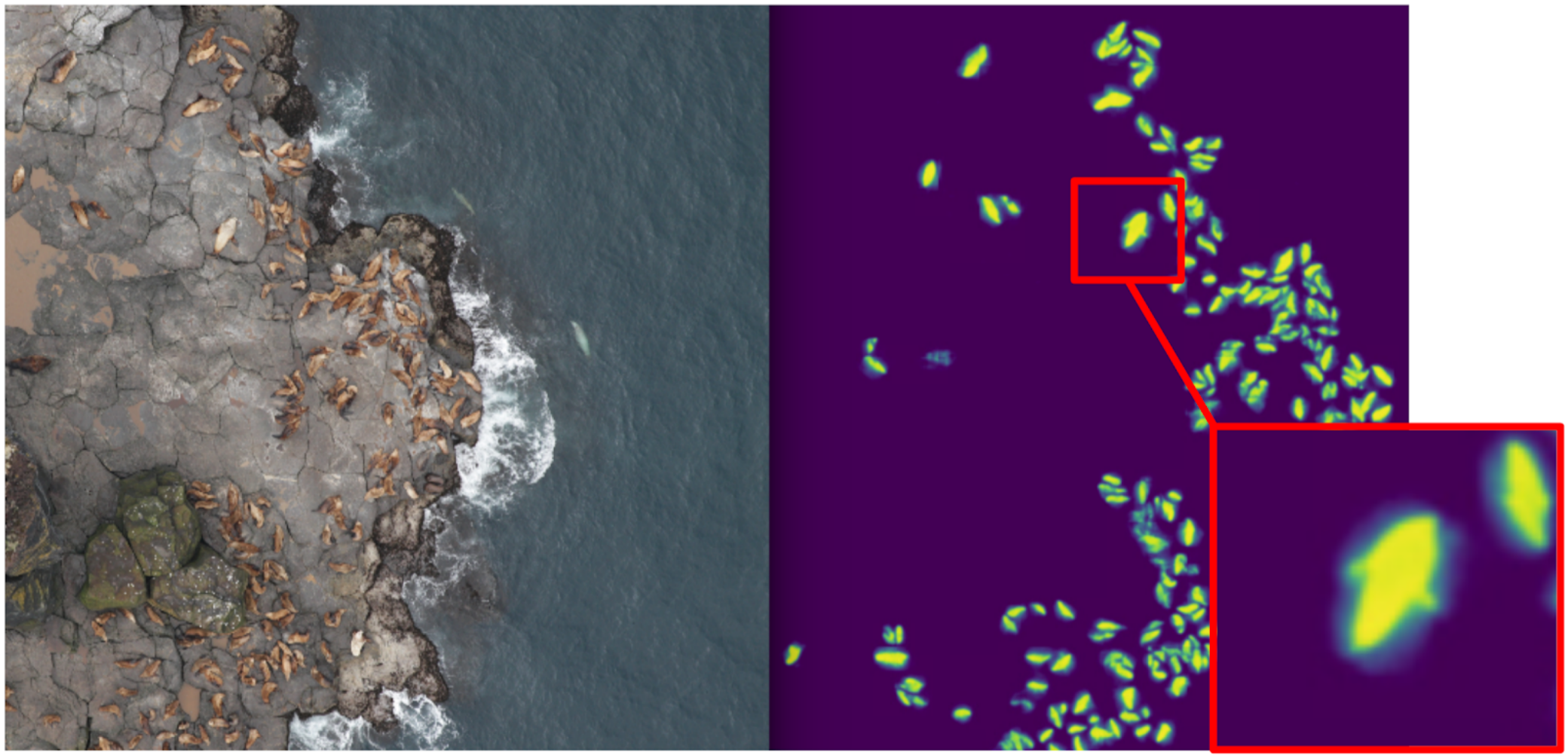
But it was a fierce fayl: we spent a lot of time trying to learn how to segment the seals abruptly and ... It almost didn’t help in their calculation. The assumption that the density of seals (the number of individuals per unit area of the mask) is constant did not work, because the drone flew at different heights, and the pictures had a different scale. And at the same time, the segmentation still did not single out individual individuals, if they lay tight - which happened quite often. And before the innovative approach to the division of objects of the Tocoder team on the DSB2018, there was still a year. As a result, we stayed at the broken trough and finished in 40th place of 600 teams.
However, I made two conclusions: semantic segmentation is a convenient approach for visualizing and analyzing the operation of the algorithm, and you can weld masks out of the boxes with some effort.
But back to the pizza. In order to select a cake in the selected and filtered photos, the most appropriate option would be to give the task to the scribe. At that time, we had already implemented the boxes and consensus algorithm for them. So I just threw a couple of examples and put it on the markup. In the end, I got 500 samples with exactly selected area of the cake.
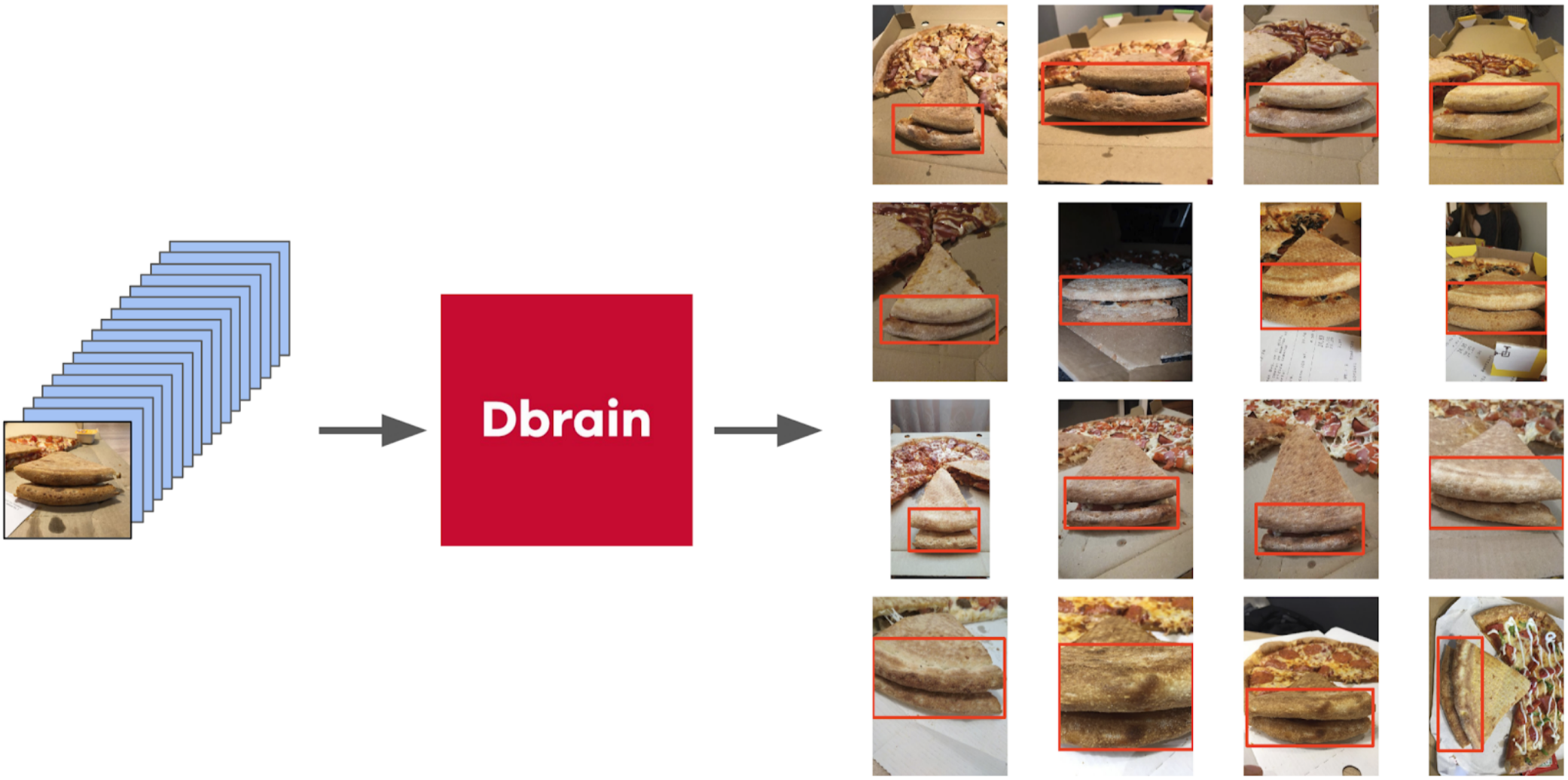
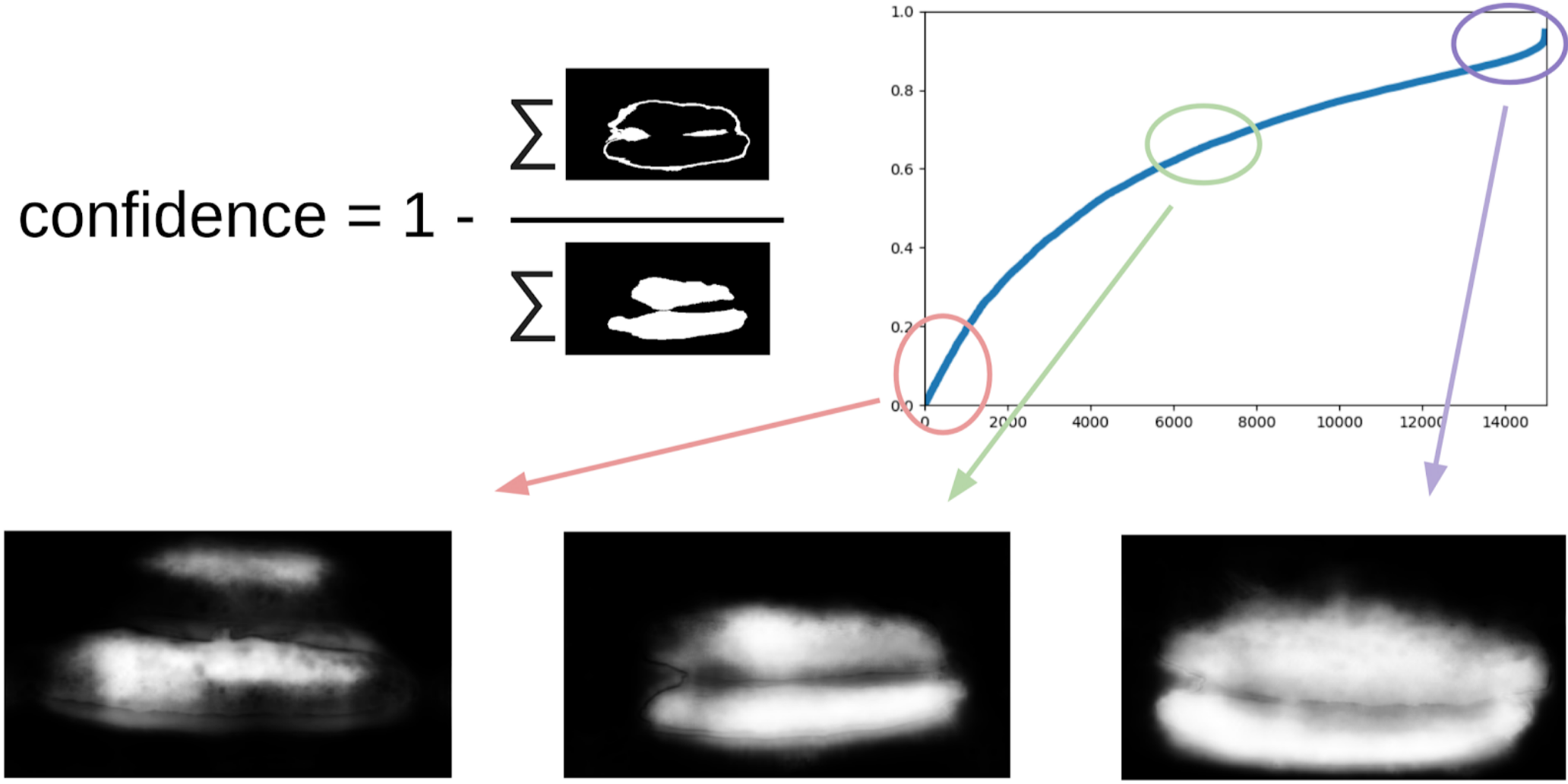
Then I dug out my code from the seals and more formally approached the current procedure. After the first iteration of the training, it was just as well seen where the model is mistaken. And the confidence of predictions can be defined as:
1 - (gray area) / (mask area) # there will be a formula, I promise
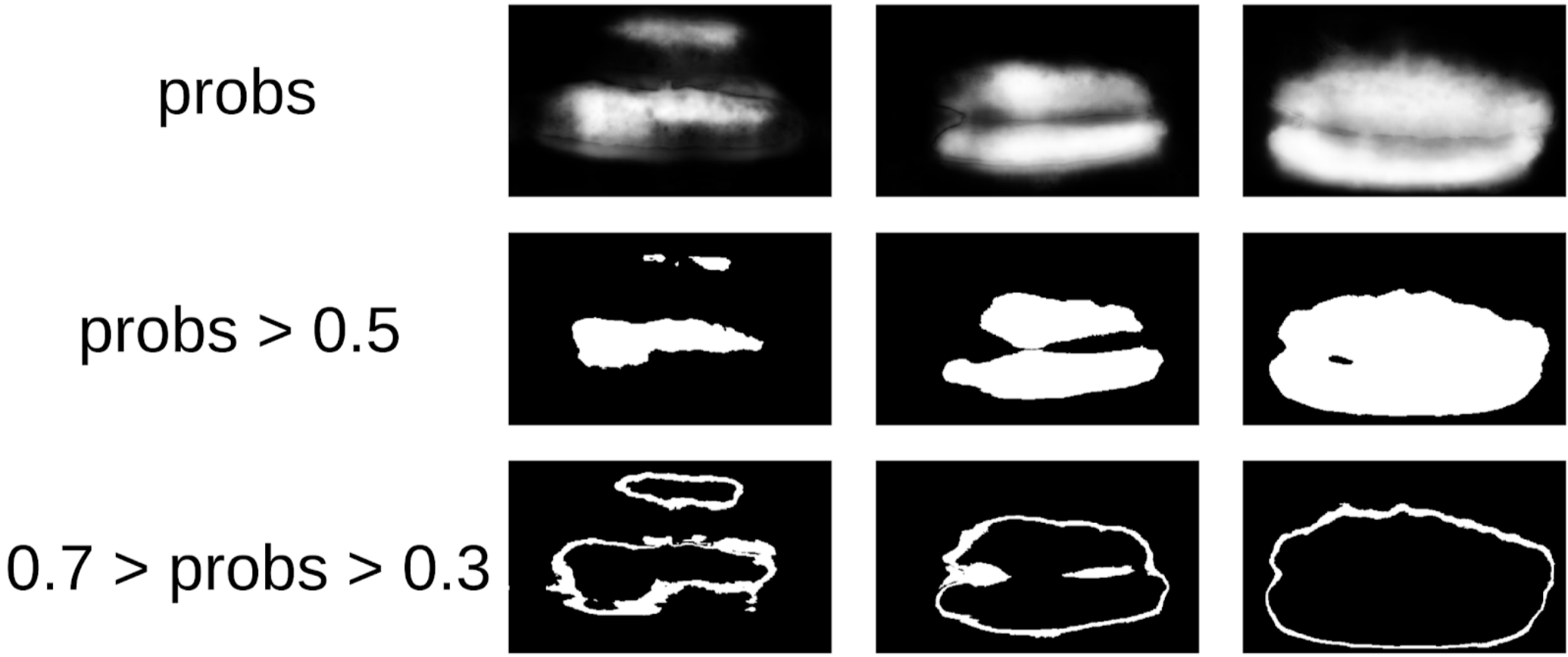
Now, in order to do the next iteration of pulling the box on the mask, a small ensemble will predict a train with a TTA. This can be considered to some extent WAAAAGH knowledge distillation, but it is more correct to call it Pseudo Labeling.
Next you need to use your eyes to choose a certain threshold of confidence, starting from which we form a new train. And optionally you can mark the most difficult samples with which the ensemble has failed. I decided that it would be useful, and I painted about 20 pictures somewhere while digesting dinner.
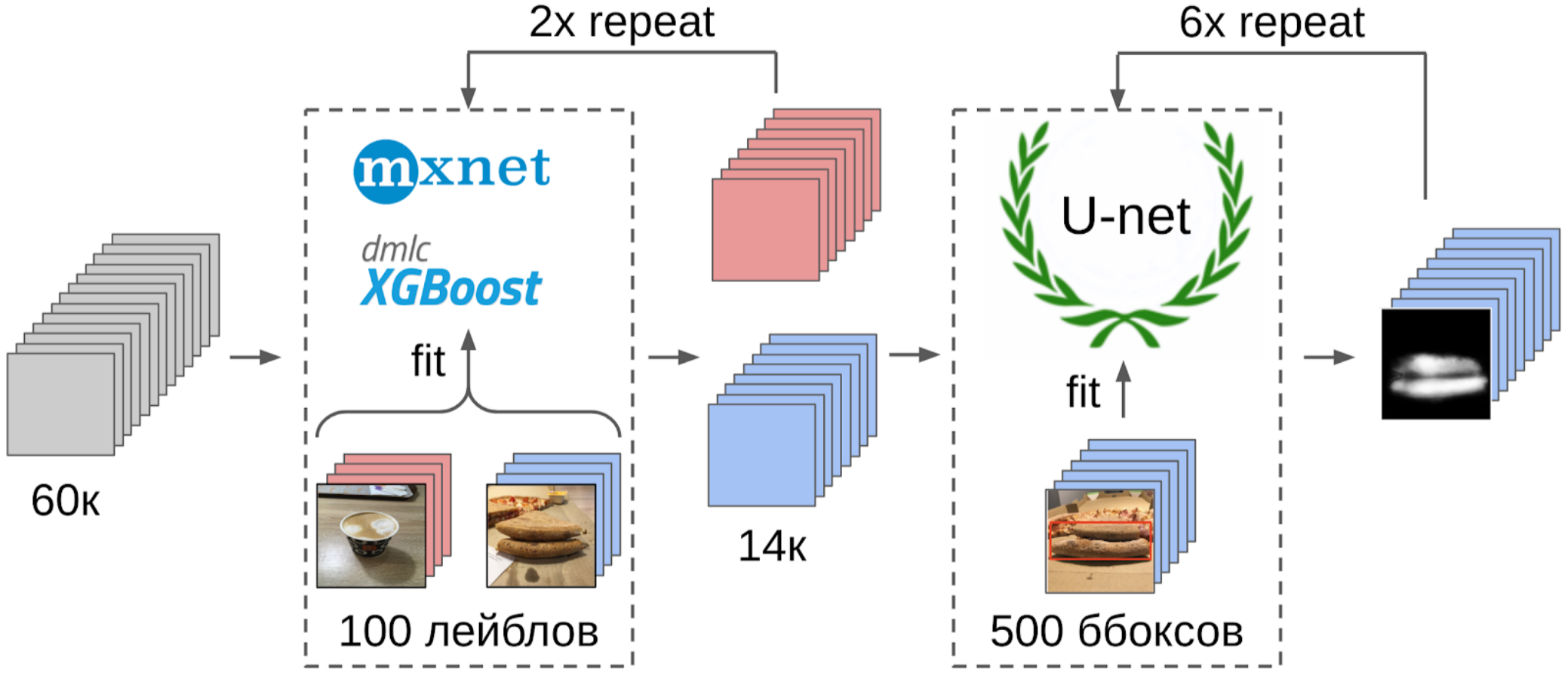
And now the final part of the pipeline: learning the model. To prepare the samples, I extracted the area of the cake on the mask. I also fanned the mask a little and applied it to the image to remove the background, since there should not be any information about the quality of the test. And then I just refilled some models from the Imagenet Zoo. In total, I managed to collect about 12k confident samples. Therefore, I did not teach the entire neural network, but only the last group of convolutions, so that the model would not retrain.
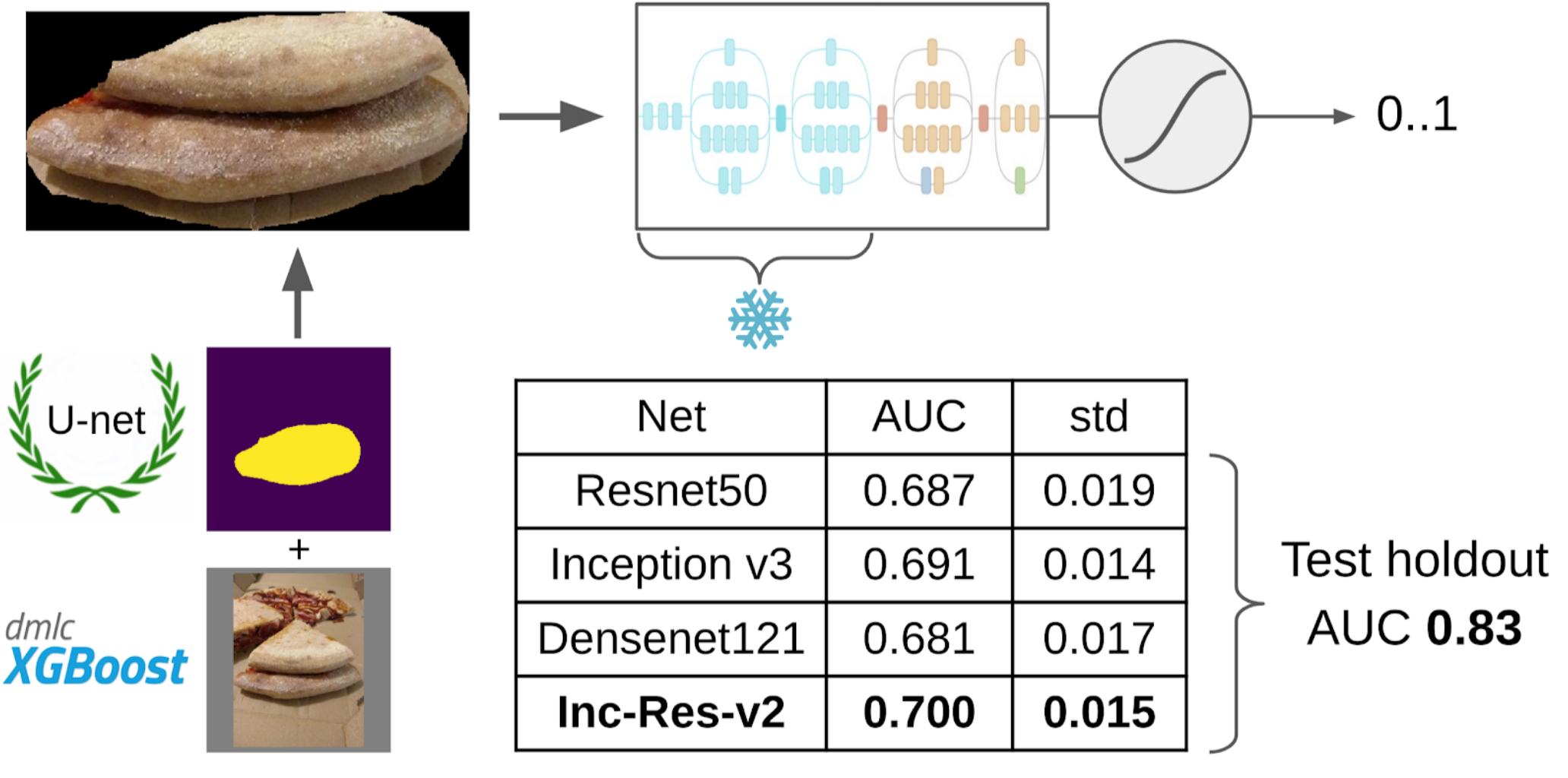
Inception-Resnet-v2 turned out to be the best single model, and for her ROC-AUC on one fold was 0.700. If you don’t select anything and feed raw pictures as they are, then ROC-AUC will be 0.58. While I was developing a solution, DODO pizza cooked the next batch of data, and you could test the entire pipeline on an honest holdout. We checked the entire pipeline on it and got a ROC-AUC 0.83.
Let's now look at the errors:
Top False Negative

Here it can be seen that they are associated with the error of marking the shortcake, since there are clearly signs of a spoiled dough.
Top False Positive

Here, errors are related to the fact that the first model selected a not very good angle, which is difficult to find the key signs of the quality of the test.
Colleagues sometimes tease me that I solve many problems by segmentation using Unet. However, in my opinion, this is quite a powerful and convenient approach. It allows you to visualize model errors and the confidence of its predictions. In addition, the entire pipeline looks very simple and now there are a lot of repositories for any framework.
Task
There is a certain process of cooking pizza and photos from its different stages (including not only pizza). It is known that if the dough recipe is spoiled, then there will be white bumps on the cake. There is also a binary markup of the quality of the dough of each pizza made by experts. It is necessary to develop an algorithm that will determine the quality of the test on the photo.
Dataset consists of photos taken from different phones, in different conditions, different angles. Copies of pizza - 17k. Total photos - 60k.
In my opinion, the task is quite typical and well suited to show different approaches to handling data. To solve it you need:
')
1. Select photos where there is a pizza shortbread;
2. On the selected photos to highlight the cake;
3. Train the neural network in the selected areas.
Photo Filtering
At first glance, it seems that the easiest thing would be to give this task to the markers, and then to train on clean data. However, I decided that it would be easier for me to mark out a small part myself, than to explain with a marker, which angle was the right one. Moreover, I did not have a hard criterion for the correct angle.
Therefore, this is how I acted:
1. Marked 100 pictures of the edge;
2. I counted features after a global pulling from the resnet-152 grid with weights from imagenet11k_places365;
3. I took the average of the features of each class, getting two anchors;
4. I calculated the distance from each anchor to all features of the remaining 50k photos;
5. Top 300 in proximity to one anchor are relevant to the positive class, the top 500 closest to the other anchor - negative class;
6. In these samples I trained LightGBM on the same features (XGboost is shown in the picture, because it has a logo and is more recognizable, but LightGBM does not have a logo);
7. With the help of this model I got the markup of the whole dataset
I used about the same approach in kaggle competitions as a baseline .
The explanation on the fingers why this approach works at all
A neural network can be perceived as a strongly non-linear transformation of a picture. In the case of classification, the picture is converted into the probabilities of the classes that were in the training set. And these probabilities can essentially be used as features for Light GBM. However, this is a rather poor description, and in the case of pizza, we will thus say that the class of the shortcake is conditionally 0.3 cats and 0.7 dogs, and trash is everything else. Instead, you can use less sparse features, after the Global Average Pooling. They have such a property that they will generate features from the samples of the training sample, which must be separated by a linear transformation (a fully connected layer with Softmax). However, due to the fact that there was no explicit pizza in the imagenet'a train, in order to divide the classes of the new training set, it is better to take the nonlinear transformation in the form of trees. In principle, you can go even further and take features from some intermediate layers of the neural network. They will be better in that they have not yet lost the locality of the objects. But they are much worse due to the size of the feature vector. And besides, they are less linear than before a fully connected layer.
Small lyrical digression
In ODS recently complained that no one wrote about their Fails. Correcting the situation. About a year ago, I participated in the Kaggle Sea Lions competition with Yevgeny Nizhibitsky . The task was to calculate the fur seals in the pictures from the drone. The markup was given simply in the form of the coordinates of the carcasses, but at some point Vladimir Iglovikov marked them with boxes and generously shared it with the community. At that time, I considered myself the father of semantic segmentation (after Kaggle Dstl ) and decided that Unet would greatly facilitate the task of counting if I learned how to distinguish the seals coolly.
Explanation of semantic segmentation
Semantic segmentation is essentially a pixel-by-pixel classification of a picture. That is, each source pixel of the image must be assigned a class. In the case of binary segmentation (the case of an article), this will be either a positive or a negative class. In the case of multi-class segmentation, each pixel is inserted into the corresponding class from the training sample (background, grass, cat, person, etc.). In the case of binary segmentation at that time, the U-net neural network architecture worked well. This neural network is similar in structure to a normal encoder-decoder, but with forwarding features from the encoder-part to the decoder at stages corresponding in size.

In the vanilla form, however, no one uses it anymore, but at least Batch Norm is added. Well, as a rule, they take a fat encoder and inflate a decoder. The new-fashioned FPN segmentation grids, which show a good performance on some tasks, have now replaced the U-net-like archectures. However, Unet-like architecture has not lost its relevance to this day. They work well as a baseline, they are easy to train, and it’s very easy to vary the depth / size of the neurosis by changing different encoders.
In the vanilla form, however, no one uses it anymore, but at least Batch Norm is added. Well, as a rule, they take a fat encoder and inflate a decoder. The new-fashioned FPN segmentation grids, which show a good performance on some tasks, have now replaced the U-net-like archectures. However, Unet-like architecture has not lost its relevance to this day. They work well as a baseline, they are easy to train, and it’s very easy to vary the depth / size of the neurosis by changing different encoders.
Accordingly, I began to teach segmentation, having as a target in the first stage only box seals. After the first stage of training, I predicted the train and looked at what the predictions look like. With the help of heuristics, it was possible to choose from an abstract confidence mask (confidence of predictions) and conditionally divide the predictions into two groups: where everything is good and where everything is bad.
Predictions where everything is good could be used to train the next iteration of the model. Predicts, where everything is bad, it was possible to choose with large areas without seals, to manually mask the masks and also to dock in the train. And so iteratively, we with Eugene taught a model that has learned to even segment the seals of sea lions for large individuals.
But it was a fierce fayl: we spent a lot of time trying to learn how to segment the seals abruptly and ... It almost didn’t help in their calculation. The assumption that the density of seals (the number of individuals per unit area of the mask) is constant did not work, because the drone flew at different heights, and the pictures had a different scale. And at the same time, the segmentation still did not single out individual individuals, if they lay tight - which happened quite often. And before the innovative approach to the division of objects of the Tocoder team on the DSB2018, there was still a year. As a result, we stayed at the broken trough and finished in 40th place of 600 teams.
However, I made two conclusions: semantic segmentation is a convenient approach for visualizing and analyzing the operation of the algorithm, and you can weld masks out of the boxes with some effort.
But back to the pizza. In order to select a cake in the selected and filtered photos, the most appropriate option would be to give the task to the scribe. At that time, we had already implemented the boxes and consensus algorithm for them. So I just threw a couple of examples and put it on the markup. In the end, I got 500 samples with exactly selected area of the cake.
Then I dug out my code from the seals and more formally approached the current procedure. After the first iteration of the training, it was just as well seen where the model is mistaken. And the confidence of predictions can be defined as:
1 - (gray area) / (mask area) # there will be a formula, I promise
Now, in order to do the next iteration of pulling the box on the mask, a small ensemble will predict a train with a TTA. This can be considered to some extent WAAAAGH knowledge distillation, but it is more correct to call it Pseudo Labeling.
Next you need to use your eyes to choose a certain threshold of confidence, starting from which we form a new train. And optionally you can mark the most difficult samples with which the ensemble has failed. I decided that it would be useful, and I painted about 20 pictures somewhere while digesting dinner.
And now the final part of the pipeline: learning the model. To prepare the samples, I extracted the area of the cake on the mask. I also fanned the mask a little and applied it to the image to remove the background, since there should not be any information about the quality of the test. And then I just refilled some models from the Imagenet Zoo. In total, I managed to collect about 12k confident samples. Therefore, I did not teach the entire neural network, but only the last group of convolutions, so that the model would not retrain.
Why do you need to freeze layers
From this there are two profits: 1. The network learns faster, because you do not need to count the gradients for frozen layers. 2. The network is not retrained, since it now has fewer free parameters. At the same time, it is argued that the first several groups of convolutions during training at Imagenet generate fairly general features such as sharp color transitions and textures that are suitable for a very wide class of objects in a photograph. This means that they can not be trained during Transer Learning.
Inception-Resnet-v2 turned out to be the best single model, and for her ROC-AUC on one fold was 0.700. If you don’t select anything and feed raw pictures as they are, then ROC-AUC will be 0.58. While I was developing a solution, DODO pizza cooked the next batch of data, and you could test the entire pipeline on an honest holdout. We checked the entire pipeline on it and got a ROC-AUC 0.83.
Let's now look at the errors:
Top False Negative
Here it can be seen that they are associated with the error of marking the shortcake, since there are clearly signs of a spoiled dough.
Top False Positive
Here, errors are related to the fact that the first model selected a not very good angle, which is difficult to find the key signs of the quality of the test.
Conclusion
Colleagues sometimes tease me that I solve many problems by segmentation using Unet. However, in my opinion, this is quite a powerful and convenient approach. It allows you to visualize model errors and the confidence of its predictions. In addition, the entire pipeline looks very simple and now there are a lot of repositories for any framework.
Source: https://habr.com/ru/post/422873/
All Articles