Identifying content profiles in VK
Bots are really difficult to distinguish from people. I myself can not really do it. But on the other hand, I came up with a good bike ... a method for distinguishing "interesting people" from "not very interesting people" in VK. In terms of network communication, of course, but not in life.

If someone knocks you on friends, and at first glance you can’t understand it at all a normal person or who the hell knows who, this method can give some useful information about the user. Using it to identify current target groups is unlikely to come out, because VK has put restrictions on the ability to download the contents of users' walls , and it hurts slow. Those. it is possible, but it is necessary to refine, optimize and dodge strongly in order to bypass the limitations.
The basic idea is that bots, dull (networked) personalities, all sorts of massive collectors of fellow subscribers don't really care who their friends are, although they can “write” quite a lot on their wall of meaningful posts. But sad individuals do not read their tape, and bots do not need it at all. Moreover, it is not necessary for mass subscribers and collectors of stars.
')
But for people who have at least some communicative interests in relation to the VC, it is just very important who their friends are. And, of course, they will not collect 6,000 dudes in their friends, who will only repost, pictures of naked women and discounted barrels advertising from a warehouse in Novy Urengoy.
And on this basis, you can try to make a criterion by which to highlight people who are interested in the content of their tape. Such people show the features of a real person. A person who, at a minimum, performs a meaningful one-sided communicative act. Nowadays, this is not so little.
Immediately I came up with two criteria:
I chose 50 random friends of mine and 50 random subscribers who met some criteria that would cut off completely obvious fakes, children or people who do not use this all. Like that the user should not be deactivated and he should have at the same time more than 50 existing friends.
I looked through all these people and identified which of them was a “bot” and who was not. Naturally, most friends were real, and most subscribers offered to buy something (but a few real people were there).
Then I took the first 100 posts from each of the friends I checked, if there were so many on the wall. For each person I considered two such factors:
Another factor emerged by chance. This is logarithm from Aidie to VC log10 (ID)
At this point I taught the logistic regression , and got this:
log (OR) = 9.92-1.537 * log10 (ID) + 0.067 * SQRT (Dic) -0.023 * Percent
For the test part of the sample we got a very good classifier with AUC = 0.93. Here is his ROC curve :
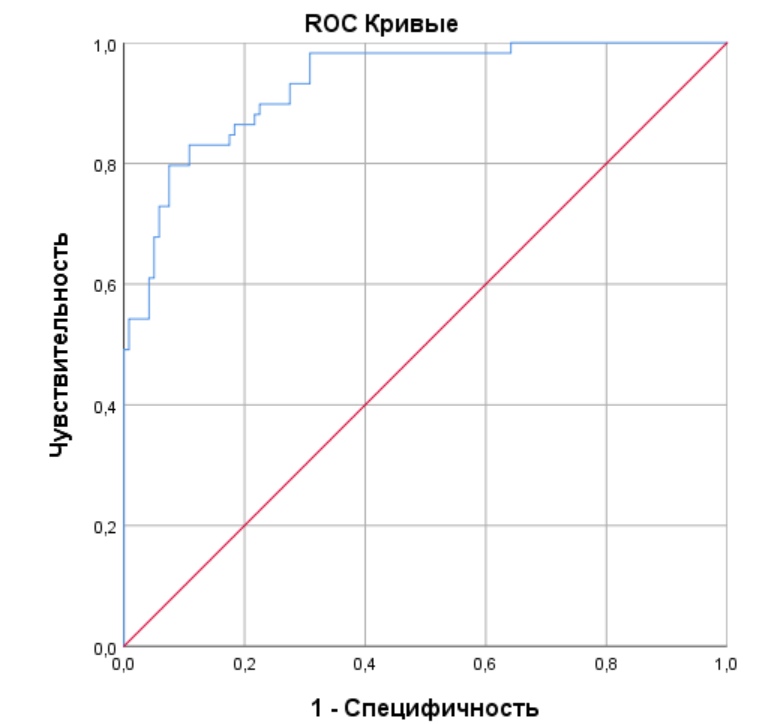
ROC curve of the classifier determining the content of a person’s page
Some questions are caused by the importance of the VC ID for the classification of the content of the personality, but it seems, alas, it works that way. The further the ID from 1, the greater the likelihood that this is just a bot that is made to advertise microcredit. Without ID, the classifier also works, but worse. AUC = 0.78. This is not straight good, but not straight useless.
In any case, the final decision on the usefulness of the character for the decision maker.
I took from one of my comrades all of his 5,000 subscribers, where, of course, advertising slag was 95% and drove the regression without additional training. When cut off by 20%, the results came out such TP = 78%, FP = 11% . That is, in general, it also works less on an arbitrary person.
Yes, it is easy enough to generate a bot that has some pseudo-content posts surrounded by friends, but for now nobody needs it. Well, it's hard to bother with different content, because if all the bots are the same to generate, it is also easy to recognize.
Probably it is possible, but I have to break in with the VC. If anyone wants, let him do it himself. It seems the method is described, its idea is simple.
Enough. But suddenly someone will come in handy as a base for their development. This method can be easily complicated, for example, considering not just the length of the dictionaries, but considering the content. Here you can use the full power of NLP and teach on content. You can also take more complex classifiers: trees, neural networks, etc. All this can be complicated, but it is important that even simple ones give something interesting.
If someone knocks you on friends, and at first glance you can’t understand it at all a normal person or who the hell knows who, this method can give some useful information about the user. Using it to identify current target groups is unlikely to come out, because VK has put restrictions on the ability to download the contents of users' walls , and it hurts slow. Those. it is possible, but it is necessary to refine, optimize and dodge strongly in order to bypass the limitations.
main idea
The basic idea is that bots, dull (networked) personalities, all sorts of massive collectors of fellow subscribers don't really care who their friends are, although they can “write” quite a lot on their wall of meaningful posts. But sad individuals do not read their tape, and bots do not need it at all. Moreover, it is not necessary for mass subscribers and collectors of stars.
')
But for people who have at least some communicative interests in relation to the VC, it is just very important who their friends are. And, of course, they will not collect 6,000 dudes in their friends, who will only repost, pictures of naked women and discounted barrels advertising from a warehouse in Novy Urengoy.
And on this basis, you can try to make a criterion by which to highlight people who are interested in the content of their tape. Such people show the features of a real person. A person who, at a minimum, performs a meaningful one-sided communicative act. Nowadays, this is not so little.
Immediately I came up with two criteria:
- The average vocabulary of a person's friends for the last N posts
- The percentage of posts without texts from friends of the person being checked.
And how did I check it in the end?
I chose 50 random friends of mine and 50 random subscribers who met some criteria that would cut off completely obvious fakes, children or people who do not use this all. Like that the user should not be deactivated and he should have at the same time more than 50 existing friends.
I looked through all these people and identified which of them was a “bot” and who was not. Naturally, most friends were real, and most subscribers offered to buy something (but a few real people were there).
Then I took the first 100 posts from each of the friends I checked, if there were so many on the wall. For each person I considered two such factors:
- The average dictionary size of a person's friends for their first 100 posts. Those. 50 friends, each with about 100 posts. For each friend, all the words from 100 posts are raked into a heap, reinforced and counted as the number of unique words of a friend. Next is the average for all 50 friends. From this value was taken root - SQRT (Dic).
- If a friend has more than 60 out of 100 posts without words, it is indicated as “lost”. The percentage of “lost” people in friends is the second factor - Percent.
Another factor emerged by chance. This is logarithm from Aidie to VC log10 (ID)
At this point I taught the logistic regression , and got this:
log (OR) = 9.92-1.537 * log10 (ID) + 0.067 * SQRT (Dic) -0.023 * Percent
For the test part of the sample we got a very good classifier with AUC = 0.93. Here is his ROC curve :
ROC curve of the classifier determining the content of a person’s page
Some questions are caused by the importance of the VC ID for the classification of the content of the personality, but it seems, alas, it works that way. The further the ID from 1, the greater the likelihood that this is just a bot that is made to advertise microcredit. Without ID, the classifier also works, but worse. AUC = 0.78. This is not straight good, but not straight useless.
In any case, the final decision on the usefulness of the character for the decision maker.
additional verification
I took from one of my comrades all of his 5,000 subscribers, where, of course, advertising slag was 95% and drove the regression without additional training. When cut off by 20%, the results came out such TP = 78%, FP = 11% . That is, in general, it also works less on an arbitrary person.
Can they make bots that pass this test?
Yes, it is easy enough to generate a bot that has some pseudo-content posts surrounded by friends, but for now nobody needs it. Well, it's hard to bother with different content, because if all the bots are the same to generate, it is also easy to recognize.
Is it possible to make an application that checks people by ID?
Probably it is possible, but I have to break in with the VC. If anyone wants, let him do it himself. It seems the method is described, its idea is simple.
Is it too trite?
Enough. But suddenly someone will come in handy as a base for their development. This method can be easily complicated, for example, considering not just the length of the dictionaries, but considering the content. Here you can use the full power of NLP and teach on content. You can also take more complex classifiers: trees, neural networks, etc. All this can be complicated, but it is important that even simple ones give something interesting.
Source: https://habr.com/ru/post/422871/
All Articles