Deep learning to determine the style and genre of paintings
Hi, Habr!
Today I want to talk about the second part of the service project for the identification and classification of works of art. Let me remind you that we solved two main tasks:
- search for a picture in the database of a photo taken by a mobile phone;
- definition of the style and genre of the picture, which is not in the database.
Today we will consider the use of a convolutional neural network to classify images by style and genre.

Let's help Dasha understand modern art?
Definition of the style of paintings
Of the nearly 250,000 paintings in the Arthive database, less than 20% is assigned a genre, style or technique, often the classes exhibited in the database do not correspond to the true values, many classes contain too few images. It seems there are even classes containing units of images. Apparently, some authors consider it necessary to create a name for their own style.
In total, about 75 styles were allocated in the database, however, for our work, the customer selected 27 mandatory styles (to which one more was later added), which the system must necessarily recognize.
According to them, the distribution of filling was very uneven.
| Style | qty | Style | qty |
|---|---|---|---|
| Realism | 19594 | Primitivism | 1234 |
| Impressionism | 15864 | Art Deco | 1092 |
| Romanticism | 8963 | Northern Renaissance | 921 |
| Baroque | 7726 | Cubism | 902 |
| Modern | 4882 | Academism | 707 |
| Surrealism | 4793 | Gothic | 608 |
| Revival | 4709 | Modernism | 539 |
| Expressionism | 4329 | Social realism | 481 |
| Symbolism | 4321 | Pop Art | 475 |
| Post-impressionism | 3951 | Pointillism | 275 |
| Abstractionism | 3664 | Fauvism | 217 |
| Ukie-e | 3136 | Avant-garde | 174 |
| Classicism | 1730 | Hyperrealism | 13 |
| Rococo | 1600 | Fantasy | eight |
| Total | 96908 |
| Style | qty | Style | qty | Style | qty |
|---|---|---|---|---|---|
| Realism | 19594 | Pop Art | 475 | Decorative art | 66 |
| Impressionism | 15864 | Biedermeier | 471 | Minimalism | 66 |
| Romanticism | 8963 | Fantastic realism | 386 | Sentimentalism | 66 |
| Baroque | 7726 | Abstract expressionism | 358 | Cloisonianism | 60 |
| Modern | 4882 | Nabi | 339 | Metaphysical painting | 56 |
| Surrealism | 4793 | Pointillism | 275 | Mccchioli | 52 |
| Revival | 4709 | Suprematism | 273 | Orphism | 51 |
| Expressionism | 4329 | Pre-Raphaelites | 252 | Dadaism | 50 |
| Symbolism | 4321 | Magical realism | 248 | Neoimpressionism | 49 |
| Post-impressionism | 3951 | Early Renaissance | 232 | Luminism | 41 |
| Abstractionism | 3664 | Neo-expressionism | 230 | Proto-renaissance | 39 |
| The Golden Age of Holland | 3292 | Fauvism | 217 | Plentanism | 37 |
| Ukie-e | 3136 | Postmodernism | 192 | Tenebrizm | 35 |
| Classicism | 1730 | Avant-garde | 174 | Abstract impressionism | 34 |
| Rococo | 1600 | Modern Art | 149 | Conceptualism | 29 |
| Primitivism | 1234 | Precisionism | 138 | Japonism | 24 |
| Art Deco | 1092 | Cubofuturism | 108 | Postmodern | 24 |
| Northern Renaissance | 921 | Constructivism | 104 | Luchism | 24 |
| Cubism | 902 | Tonalism | 103 | Byzantine | 20 |
| Academism | 707 | Orphism | 94 | Romantic realism | nineteen |
| Gothic | 608 | Regionalism | 93 | Hyperrealism | 13 |
| Neoclassicism | 601 | Analytical realism | 89 | Verism | eleven |
| Mannerism | 544 | Naturalism | 73 | Neo-primitivism | ten |
| Modernism | 539 | Neo-modernism | 70 | Fantasy | eight |
| Social realism | 481 | Futurism | 67 | Metarealism | 7 |
| Total | 106284 |
We are faced with the task of classifying images, but we cannot select some simple signs manually. So, we will use deep machine learning, in which such complex features are automatically highlighted in the learning process.
')
Transfer learning
Consider the inception v3 network.
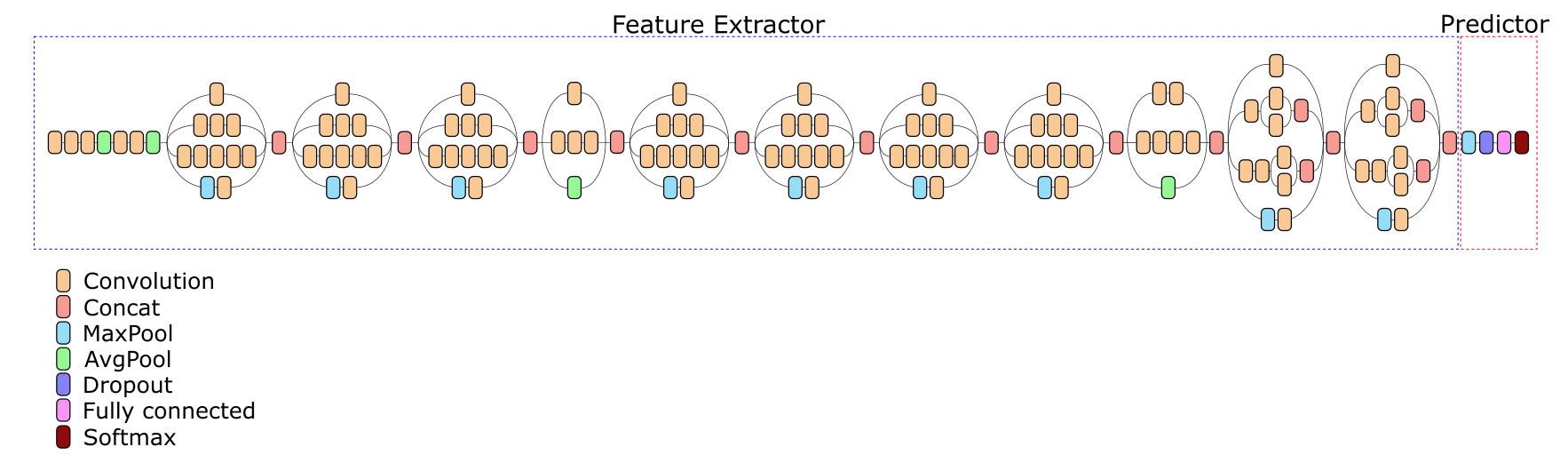
In its architecture (and in any other deep network) we can conditionally distinguish two main components - Feature Extractor and Predictor.
Feature Extractor displays the input color images in a multi-dimensional feature space (multi-channel feature map). The attribute map saves spatial information — that is, it is a three-dimensional tensor with dimensions along the width, height, and number of feature channels; the final pooling has not yet been applied, which completely eliminates the information about the relative position of the features in the original image. Feature Inventor v3 Network Extractor receives a 299 image as input 299 3, and on output forms a feature map of size 17 17 2048. The size of the input can be varied, which will lead to changes in the size of the map of signs and can be useful to reduce the computational cost when working with a network.
A Predictor is a network that generates output data based on a feature map formed by Feature Extractor. As a rule, for the classification problem, the Predictor is a fully connected layer of neurons, the number of outputs of which coincides with the number of classes of the problem.
Classical transfer learning assumes that we take a trained network, separate the Extract Extractor from it, and supplement it with a new predictor with the number of classes we need. The resulting network is trained at low speed with partially or completely frozen scales of the Extract Extractor layers.
Apply transfer learning to classify styles. Take the Inception-v3 network trained on the imagenet dataset and replace the neuron output layer in it, which classifies the input images into the number of selected styles. We trained the resulting network on images of different styles, freezing the training of all layers except the last.
To analyze the data, we displayed the distribution of the validation set by classes.
Each line corresponds to a class from the validation set. The brightness of the squares in the row is proportional to the number of pictures that fall into the class corresponding to the column.
For better clarity, exclude the main diagonal and re-normalize the values of each row.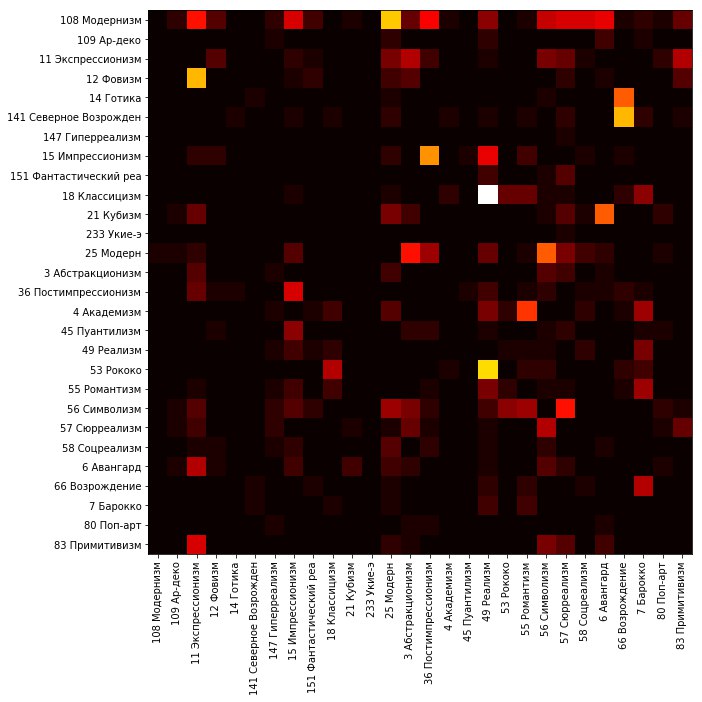
In addition, we will try to map the distribution by style onto a two-dimensional space using TSNE.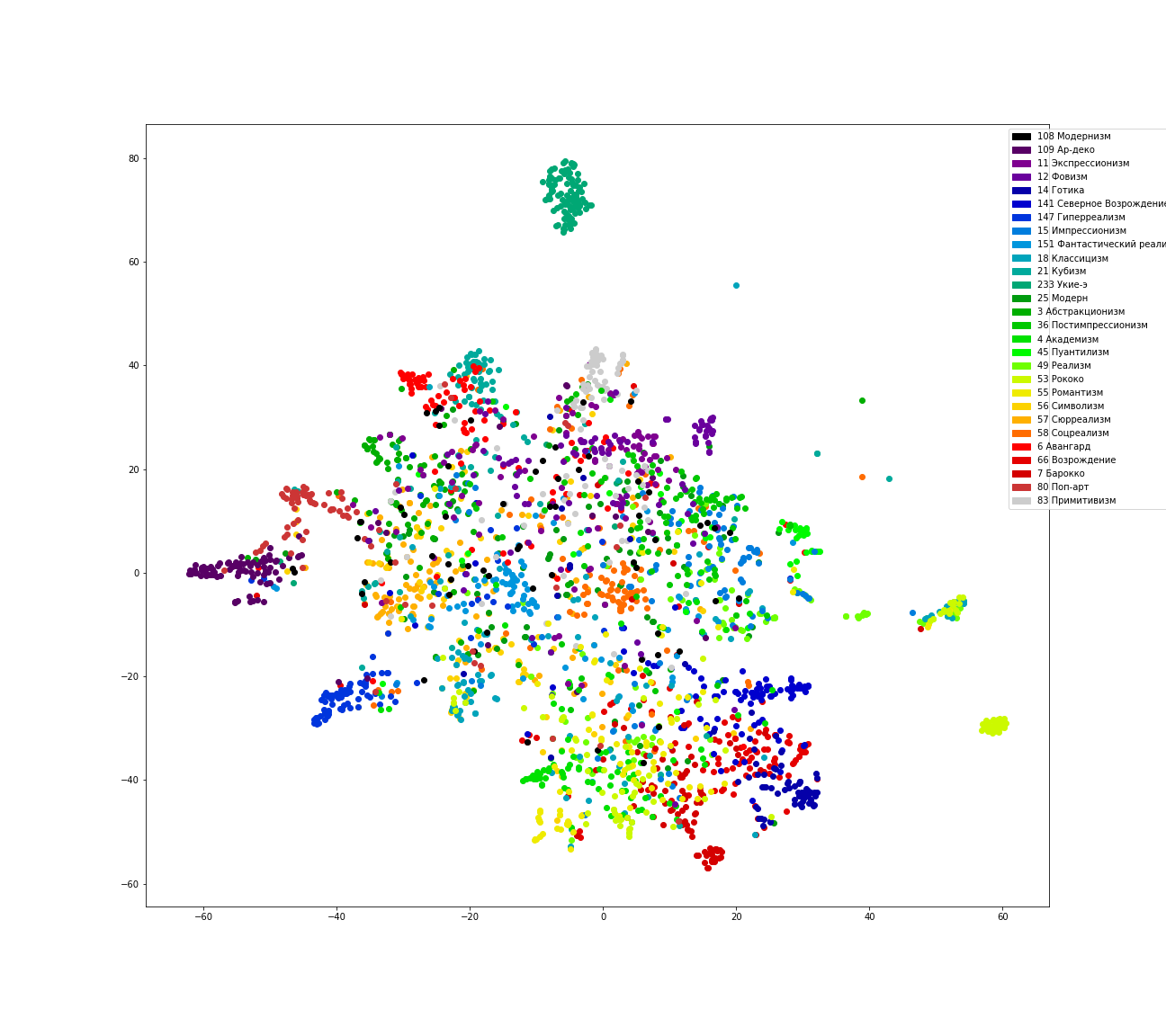
It can be seen that a lot of mistakes are observed, for example, when classifying paintings in the style of Fauvism - a significant part of them belong to expressionism as a network. Northern Renaissance and Gothic often refer to Renaissance. Many images of the Rococo style and classicism are related to realism. Modernism and modern generally break up into many styles.
Throwing a simple script that sorted out the training base by folders in accordance with the style defined by the network, we conducted a brief analysis of errors. It turned out that the base markup at least raises questions.
Many images in the style of modernism (which, although the customer noted as mandatory, but in general is not a style, but rather a direction in art as a whole) were actually duplicated in other styles, especially in modernity (and this is already a style).
In the style of socialist realism there were abstract images, for example, works by Lissitzky. Apparently, they got there thanks to the work of Lissitzky on the Soviet poster, which is very indirectly related to social realism.
In many respects, these are really mistakes, but sometimes the reason is the debatable nature of highlighting some, especially modern styles. It should be borne in mind that the base is filled with various users, and among them sometimes there is no consensus.
Errors in the data lead to corresponding network image classification errors. In the process of cleaning the base, both by us and by an expert art critic on the part of the customer, the marking for the training set has been significantly improved.
However, the majority of network classification errors (by total) are related to more or less well-established styles, such as rococo, classicism, realism. The attribution of works to these styles, as a rule, occurs on the basis of an epoch or authorship, and it seems that there is no doubt or controversy. Why is the network unable to distinguish their style? The main reason is the use of a pre-trained network to extract features.
The point is that this network was trained to classify objects, determine what exactly is depicted, while discarding information that is not essential for the task about how it is depicted. For example, from the point of view of the network, in all the images at the beginning of the article, in general, a person is depicted.
To solve this problem, we made a network with intermediate outputs - it is believed that the signs become more and more difficult as they move along the network, and irrelevant information disappears gradually. We will try to extract from the intermediate layers what was irrelevant for imagenet classification.
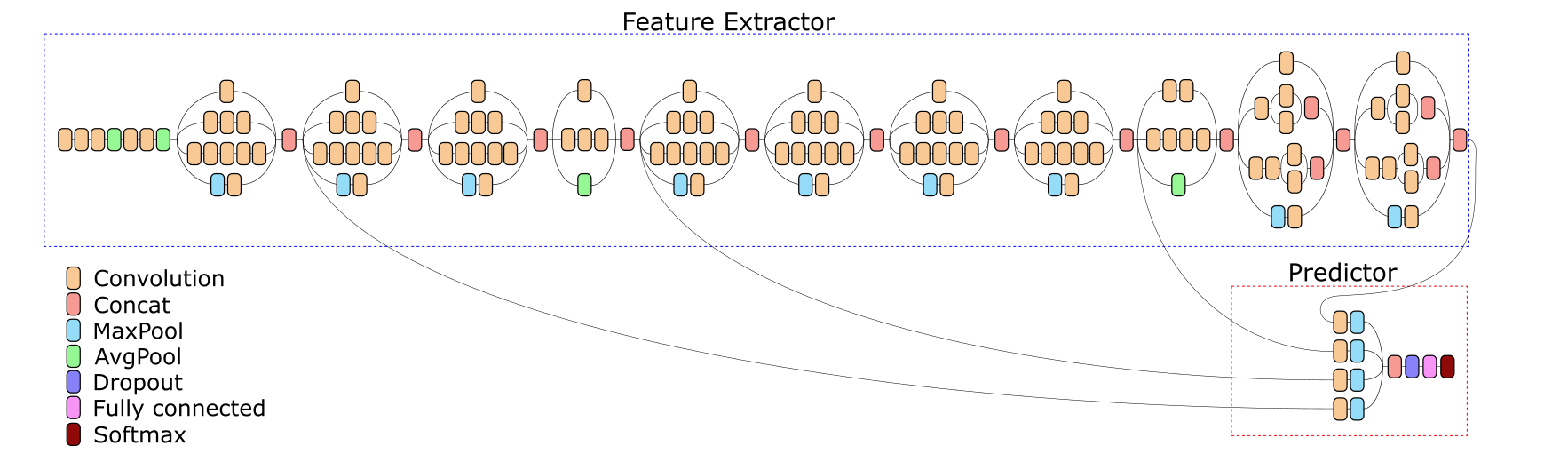
There is another problem - graphics, prints, sketches. In imagenet, on which the inception network was pre-trained, there is simply nothing of the kind, and, accordingly, the features distinguished by the network are not suitable for classifying such images.
 |  |
| Realism, Impressionism. Camille Caro, Hagar and the Angel | Baroque Rembrandt Harmens van Rhine, Hagar and the Angel |
On the other hand, beautifully hung as a separate cloud of the Ukye-e- style painting is a kind of engraving that has become widespread in Japan since the 17th century. Although initially they were not on our mandatory list, we added them there.

After working with data, it was possible to achieve a better distribution of classes.
We understand the genres
Of the total number of genres, 13 were selected (bold)
| Genre | qty |
|---|---|
| Allegorical scene | 2500 |
| Portrait | 2308 |
| Landscape | 2213 |
| Fantasy | 2191 |
| Literary scene | 2096 |
| Cityscape | 2048 |
| Nu | 1981 |
| Still life | 1932 |
| Genre scene | 1736 |
| Animalism | 1587 |
| Religious scene | 1417 |
| Mythological scene | 1368 |
| Marina | 1210 |
| Architecture | 958 |
| Interior | 635 |
| Historical scene | 534 |
| Battle scene | 201 |
| Zakli | 180 |
| Lead | 124 |
| Urban landscape | sixteen |
| Total | 27235 |
Basically, the reduction in the number of genres has been achieved by reducing the genres of various scenes - "religious", "mythological", "allegorical", "literary" and combining them under the common name "genre scene". We came to the conclusion that the separation of these genres can hardly be done with sufficient accuracy without significant cultural analysis.
For example, for an allegorical scene, by definition, it is assumed that there is a hidden meaning in the image, the use of the figurative meaning of the objects depicted. There is a difficulty with the "religious scene": it is very likely that the network trained to issue such a class will call them caricature images (for example, parodying the "Last Supper" da Vinci), and this may offend someone .
The layout of data by genres initially seems to be quite good, except for several genres for which there are few images in the database. Searching on the Internet, we were able to slightly expand the number of images in the genres (mainly the battle scene, twists and vedutas).
After combining difficult genres into a common "genre scene", we immediately tried to educate the network head-on using the inception transfer learning network.
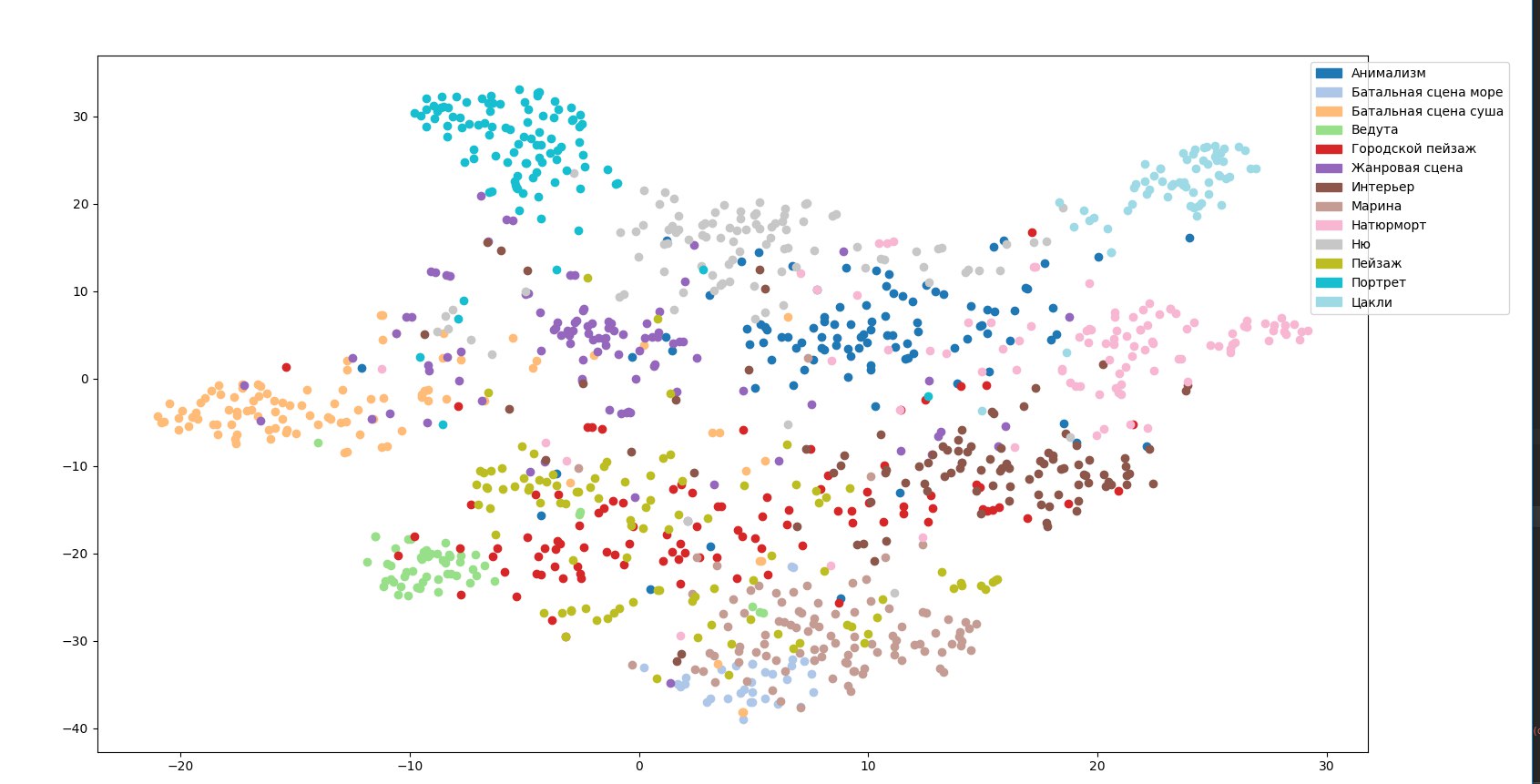
It is seen that the points corresponding to images of different genres are mixed. For these images, the network gives high values of the probabilities of belonging to several genres at once, and the genre is most likely determined almost randomly. The reason seems to be that genres, unlike styles, have a more pronounced hierarchy. We tried to understand these links, we got such a map of genres:
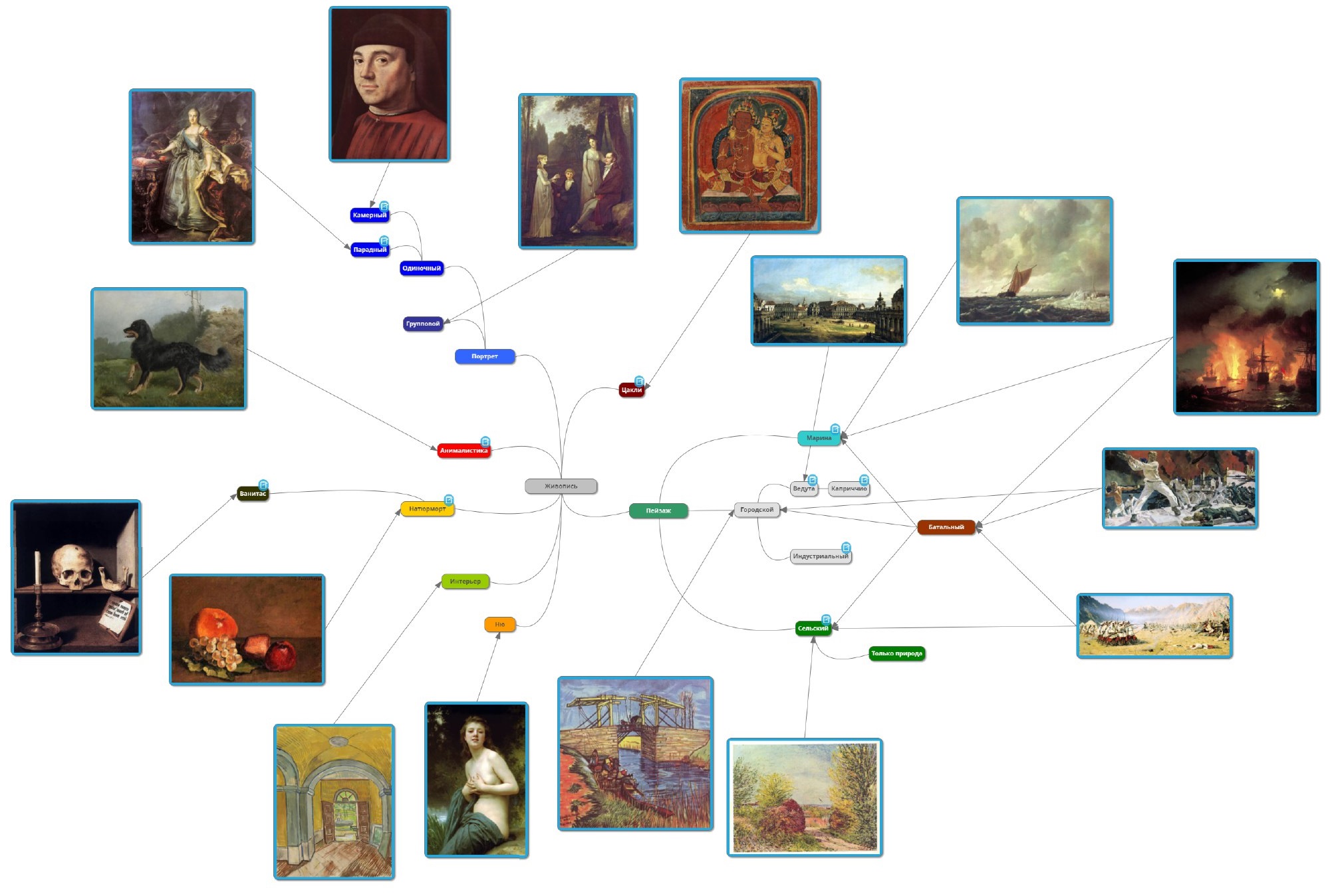
Child and parental hierarchy genres often have common features from a network point of view (and from our point of view, too). For example, a battle scene on land as a whole has the same characteristics as an ordinary landscape - an image of a large open area or city, and a battle scene at sea looks more like a marina genre. Therefore, we have divided the battle scene genre into two - on land and at sea. Another example: portraits, genre scenes and nudes from the point of view of the pre-trained network all have a common feature - the presence of people.
In a database, pictures of similar content often refer either to a child or to a parent genre, depending on where it was determined by the expert who contributed the pictures to the database. In this regard, a large-scale cleaning and redevelopment of the base was carried out taking into account the possible hierarchy of genres, which took a lot of effort (we managed to automate it, but not much).
In order to transfer the hierarchy of genres to the network, we abandoned the one-hot presentation and set a unit for images not only in one genre, but also in its parent, if there is one, and also replaced the target function of the learning process and the output layer activation function . Thus, the task became the Multilabel classification (the input image can belong to several classes).
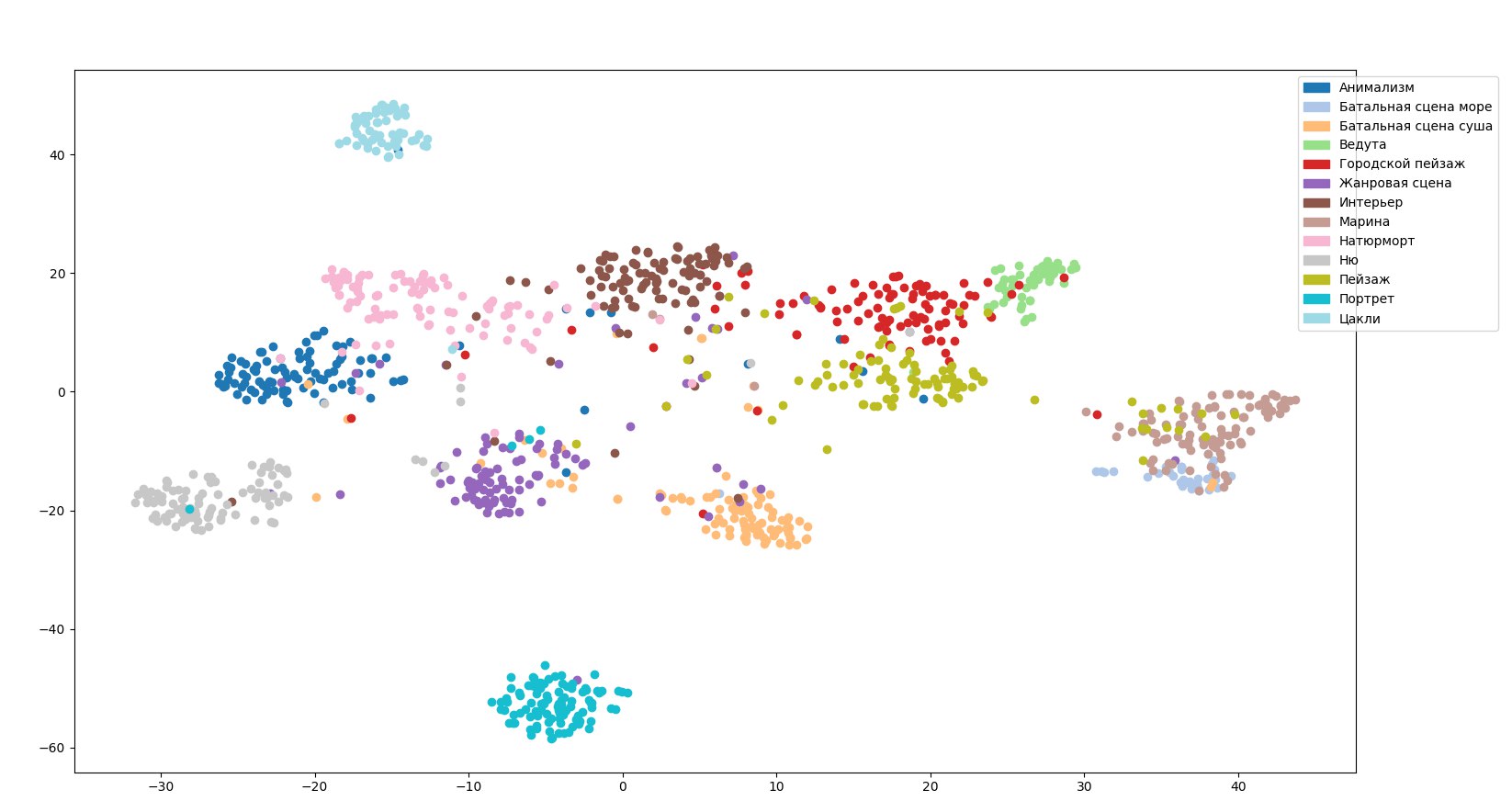
It seems to us that there is not enough of another genre here - abstraction. Strictly speaking, it is not exactly a genre. At least the experts insisted that there was no such genre. In order for the network not to give random images to abstract images, another one was added to the general division of genres called “failed to identify”, including abstract and controversial images.
Instead of conclusion
In general, it was possible to achieve a satisfactory classification accuracy of styles and genres of images, but there is much to improve.
Unfortunately, the classification of styles and techniques was not completed - the service support was not implemented.
Source: https://habr.com/ru/post/422357/
All Articles