From clouds to earth: how to create a production-grade Kubernetes in any conditions
All good! Well, that time has come for our next Devops course . Probably, this is one of the most stable and standard courses, but at the same time it is the most diverse among students, since no group has yet looked like the other: in one developer, almost completely, then in the next engineers, then admins, and so on. And it also means that the time has come for interesting and useful materials, as well as online meetings.

This article contains recommendations for launching the production-grade Kubernetes cluster in on-premise data center or peripheral locations (edge location).
What does production-grade mean?
')
In short, a production-grade means anticipating errors and preparing a recovery with a minimum of problems and delays.

This article focuses on the on-premise deployment of Kubernetes on a hypervisor or bare-metal platform, given the limited amount of support resources in comparison with the increase in core public clouds. Nevertheless, a part of these recommendations can be useful for a public cloud if the budget limits the selected resources.
Deploying a single-metal bare-metal Minikube can be a simple and cheap process, but it is not a production-grade. Conversely, you will not be able to reach the level of Google with Borg in an offline store, branch or peripheral location, although it is unlikely that you need it.
This article outlines tips for achieving a production-level Kubernetes deployment, even in a resource limiting situation.
Important components in the Kubernetes cluster
Before delving into the details, it is important to understand the overall architecture of Kubernetes.
The Kubernetes cluster is a highly distributed system based on the control plane and the architecture of the clustered worker node, as shown below:
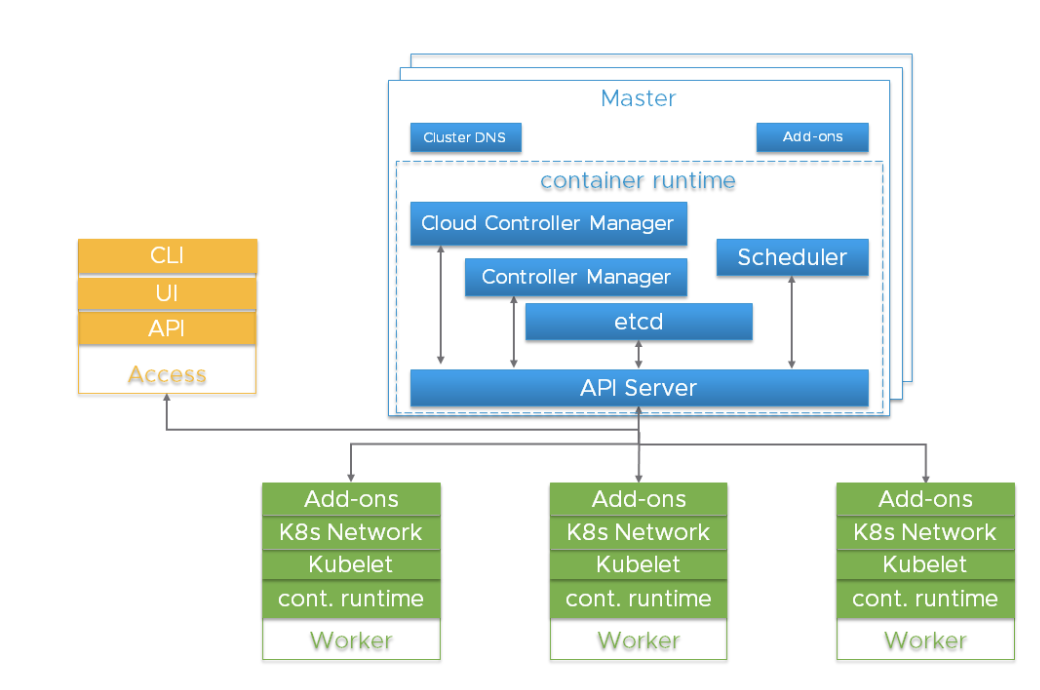
Typically, the components of the API Server, Controller Manager and Scheduler are located in several instances of the nodes of the control level (it is called the Master). Master nodes typically also include etcd, however there are large and highly available scripts that require running etcd on independent hosts. Components can be run as containers and, optionally, under the supervision of Kubernetes, that is, work as static pods.
For high availability, redundant instances of these components are used. Significance and required level of redundancy can vary.
The risks of these components include hardware failures, software bugs, bad updates, human errors, network interruptions, and system overload leading to resource depletion. Excessiveness can reduce the impact of these hazards. In addition, thanks to the functions of the hypervisor platform (resource planning, high availability), you can multiply the results using the Linux operating system, Kubernetes, and container runtime.
The API Server uses multiple load balancer instances to achieve scalability and availability. Load balancer is an important component for high availability. Several A-records of the DNS API server can serve as an alternative in the absence of a balancer.
The kube-scheduler and kube-controller-manager participate in the process of choosing a leader instead of using a load balancer. Since cloud-controller-manager is used for certain types of hosting infrastructure, the implementation of which may vary, we will not discuss them - just let us indicate that they are a component of the control layer.
Pods running on the Kubernetes worker are managed by a kubelet agent. Each worker instance runs a kubelet-agent and a CRI- compatible container launch environment. Kubernetes itself is designed to monitor and recover from a crash node. But for critical load functions, managing hypervisor resources and isolating loads, it can be used to improve availability and increase the predictability of their work.
etcd
etcd is the persistent storage for all Kubernetes objects. The availability and recoverability of the etcd cluster should be a priority when deploying a production-grade Kubernetes.
An etcd cluster of five nodes is the best option if you can enable it. Why? Because you will be able to maintain one, and still endure failure. A cluster of three nodes is the minimum that we can recommend for a production-grade service, even if only one host hypervisor is available. More than seven nodes are also not recommended, with the exception of very large installations covering several availability zones.
The minimum recommendations for hosting nodes etcd cluster - 2GB RAM and 8GB SSD hard drive. Usually, 8GB of RAM and 20GB of hard disk space is sufficient. Disk performance affects the recovery time of the node after a failure. Check out to find out details.
In special cases, think about a few etcd clusters.
For very large Kubernetes clusters, consider using a separate etcd cluster for Kubernetes events, so that too many events do not affect the main Kubernetes API service. When using the Flannel network, the configuration is saved in etcd, and the version requirements may differ from Kubernetes. This can make it difficult to back up etcd, so we recommend using a separate etcd cluster specifically for the flannel.
Single Host Deployment
The list of accessibility risks includes hardware, software, and human factors. If you are limited to a single host, the use of redundant storage, error-correcting memory, and dual power supplies can improve security against hardware failures. Running a hypervisor on a physical host allows you to use redundant software components and adds operational benefits associated with deploying, updating, and controlling resource utilization. Even in stressful situations, the behavior remains repeatable and predictable. For example, even if you can only afford to launch singletones from master services, they should be protected from overload and resource depletion, competing with the workload of your application. A hypervisor can be more efficient and easier to use than setting priorities in the Linux scheduler, cgroups, Kubernetes flags, etc.
You can deploy three etc etc virtual machines if resources allow on the host. Each of the VMs must be supported by a separate physical storage device or use separate parts of the storage using redundancy (mirroring, RAID, etc.).
Dual redundant instances of the server API, scheduler, and controller manager are the next upgrade, if your only host has enough resources for this.
Single host deployment options, from least suitable for production to most
Deploy to two hosts
With two hosts, storage problems etcd are similar to the single-host option — you need redundancy. It is preferable to run three encd instances. It may seem non-intuitive, but it is better to concentrate all etcd nodes on the same host. You do not increase reliability by dividing them by 2 + 1 between two hosts - losing nodes with most encd instances leads to interruption, regardless of whether they are 2 or 3. If the hosts are not identical, place the etcd cluster entirely on the more reliable one.
It is recommended to launch redundant API servers, kube-schedulers and kube-controller-managers. They should be shared between hosts to minimize the risk of failure of the container launch environment, operating system, and equipment.
Running a hypervisor layer on physical hosts will allow you to work with redundant program components, ensuring control of resource consumption. It also has the operational advantage of scheduled maintenance.
Deployment options for two hosts, from the least suitable for production to the most
Deploy to three (or more) hosts
Transition to uncompromising production-grade service. We recommend dividing etcd between the three hosts. One equipment failure will reduce the amount of possible application workloads, but will not result in a complete service outage.
Very large clusters will require more instances.
Launching a hypervisor layer provides operational advantages and improved isolation of application workloads. This is beyond the scope of the article, but at the level of three or more hosts, improved features may be available (clustered redundant shared storage, resource management with a dynamic load balancer, automated state monitoring with live migration and failover).
Deployment options for three (or more) hosts from the least suitable for production to the most
Configure Kubernetes configuration
Master and Worker nodes must be protected from overload and resource depletion. Hypervisor functions can be used to isolate critical components and reserve resources. There are also Kubernetes configuration settings that can slow things like API speed. Some installation kits and commercial distributions take care of this, but if you are self-deploying Kubernetes, the default settings may not be appropriate, especially for small resources or a cluster that is too large.
The consumption of resources at a managed level correlates with the number of hearths and the outflow rate of hearths. Very large and very small clusters will benefit from the modified settings for slowing down kube-apiserver requests and memory.
Node Allocatable must be configured on the nodes of the worker based on a reasonable supported load density on each node. Namespaces can be created to divide the cluster of the worker node into several virtual clusters with quotas for CPU and memory.
Security
Each Kubernetes cluster has a root Certificate Authority (CA). The Controller Manager, API Server, Scheduler, kubelet client, kube-proxy and administrator certificates must be generated and installed. If you use the tool or distribution kit of installation, then probably you should not deal with it independently. The manual process is described here . You should be ready to reinstall certificates in case of expansion or replacement of nodes.
Since Kubernetes is fully managed by the API, it is extremely important to control and limit the list of those who have access to the cluster. Encryption and authentication options are discussed in this documentation.
Kubernetes application workloads are based on container images. You need the source and contents of these images to be reliable. Almost always this means that you will host the container image in the local repository. Using images from the public Internet can cause problems of reliability and security. You must select a repository that has support for image signing, security scanning, access control for sending and downloading images, and activity logging.
Processes must be configured to support the application of host firmware updates, hypervisor, OS6, Kubernetes, and other dependencies. Versioning is required to support auditing.
Recommendations:
Kubernetes secret objects are suitable for storing small amounts of sensitive data. They are stored in etcd. They can be safely used to store the Kubernetes API credentials, but there are times when a more comprehensive solution is required for the workload or expansion of the cluster itself. The HashiCorp Vault project is a popular solution if you need more than the built-in secret objects can provide.
Disaster Recovery and Backup

Implementing redundancy through the use of multiple hosts and VMs helps reduce the number of certain types of failures. But scenarios such as a natural disaster, a bad update, a hacker attack, software bugs, or a human error can still turn into crashes.
A crucial part of the production deployment is waiting for the need for future recovery.
It is also worth noting that part of your investment in the design, documentation, and automation of the recovery process can be reused if large-scale replicated multi-site deployments are required.
Among the elements of disaster recovery, it is worth noting backups (and possibly replicas), replacements, a planned process, people who will perform this process, and regular training. Frequent test exercises and principles of Chaos Engineering can be used to test your readiness.
Due to availability requirements, it may be necessary to store local copies of the OS, Kubernetes components, and container images to allow recovery even if the Internet fails. The ability to deploy replacement hosts and nodes in a “physical isolation” situation improves security and increases deployment speed.
All Kubernetes objects are stored in etcd. Periodic backup of data of an etcd-cluster is an important element in restoring Kubernetes clusters under abnormal scenarios, for example, if all master nodes are lost.
Cluster etcd can be backed up using the snapshot mechanism built into etcd and copying the result to storage to another failure domain. Snapshot files contain all Kubernetes states and critical information. Encrypt snapshot files to protect sensitive Kubernetes data.
Keep in mind that some Kubernetes extensions can store states in separate etcd clusters, persistent volumes or some other mechanism. If these conditions are critical, they should have a backup and recovery plan.
But some important states are stored outside etcd. Certificates, container images, other settings and states associated with operations can be controlled by an automatic install / update tool. Even if these files can be regenerated again, a backup or replica will speed up disaster recovery. Consider the need for a backup and recovery plan for the following objects:
Load offerings
Anti-affinity specifications can be used to split clustered services between backup hosts. But in this case, the settings are used only if it is scheduled. This means that Kubernetes can restart the failed node of your clustered application, but does not have a built-in mechanism for rebalancing after a failure. This topic deserves a separate article, but additional logic can be useful for achieving optimal placement of workloads after a host or a worker node is restored or expanded. The Prioritization and Crowd Out function can be used to select the desired sorting in case of a shortage of resources caused by a failure.
In the case of stateful services, external mounted volumes are the Kubernetes recommendation standard for nonclustered services (for example, for a typical SQL database). Currently, external volume snapshots managed by Kubernetes are in the roadmap feature request category, and are most likely related to the integration of the Container Storage Interface (CSI). Thus, the creation of backup copies of such a service will require in-box actions depending on the specific application, which is beyond the scope of this article. Therefore, while we are waiting for the improvement of Kubernetes support for workflow snapshots and backup, it is worth thinking about starting the database service not in a container, but in a virtual machine, and opening it to Kubernetes loads.
Clustered stateful services (for example, Cassandra) can take advantage of the separation between hosts using local persistent volumes, if resources permit. This will require deploying multiple Kubernetes work nodes (there may be VMs on hypervisor hosts) to maintain a quorum at the point of failure.
Other offers
Logs and metrics (if you collect and store them) are useful for diagnosing failures, but given the variety of available technologies, we will not consider them in this article. If you have an Internet connection, it is advisable to keep logs and metrics outside, centrally.
In a production deployment, automated installation, configuration, and upgrade tools should be used (for example, Ansible , BOSH , Chef , Juju , kubeadm , Puppet , etc.). The manual process is too laborious and difficult to scale, it is easy to make mistakes and run into problems of repeatability. Certified distributions are likely to include a means to save the settings when upgrading, but if you use your own toolchain for installation and configuration, storing, backing up and restoring configuration artifacts is of paramount importance. It is worth thinking about using a version control system, like Git, to store components and deployment settings.
Recovery
Ranbuki , in which recovery processes are documented, should be tested and saved offline - perhaps even printed. When an employee is called at 2 am on Fridays, improvisation is not the best option. It is better to complete all the items from the planned and tested checklist - which is accessible both to the employees in the office and to the remote ones.
Final thoughts

Buying a commercial airline ticket is a simple and safe process. But if you are flying to a remote place with a short runway, a commercial flight on an Airbus A320 is not an option. This does not mean that airfare should not be considered at all. It only means that compromises are necessary.
In the context of aviation, engine failure in a single-engine vessel means a crash. With two engines, at a minimum, there will be more opportunities to decide where the crash will occur. Kubernetes on a small number of hosts is similar, and if your business case justifies, you should think about increasing the fleet, consisting of large and small machines (for example, FedEx, Amazon).
When designing Kubernetes production-grade solutions, you have many options and options. A simple article can not give all the answers and has no idea about your priorities. Nevertheless, we hope that she provided a list of things to think about, as well as some useful recommendations. There are options that have not been reviewed (for example, launching Kubernetes components using self-hosting , rather than static pods). Perhaps they should be discussed in the following articles, if there is enough interest. In addition, due to the high rate of improvement of Kubernetes, if your search engine found this article after 2019, some of its materials might already be outdated.
THE END
As always, we are waiting for your questions and comments here, and you can go to the Open Day to Alexander Titov .
This article contains recommendations for launching the production-grade Kubernetes cluster in on-premise data center or peripheral locations (edge location).
What does production-grade mean?
')
- Safe installation;
- Deployment is managed through a repetitive and recorded process;
- Work is predictable and consistent;
- It is safe to update and customize;
- To detect and diagnose errors and lack of resources, there is logging and monitoring;
- The service has sufficient “high availability” given the available resources, including restrictions in money, physical space, power, and so on.
- The recovery process is available, documented and tested for use in case of failures.
In short, a production-grade means anticipating errors and preparing a recovery with a minimum of problems and delays.
This article focuses on the on-premise deployment of Kubernetes on a hypervisor or bare-metal platform, given the limited amount of support resources in comparison with the increase in core public clouds. Nevertheless, a part of these recommendations can be useful for a public cloud if the budget limits the selected resources.
Deploying a single-metal bare-metal Minikube can be a simple and cheap process, but it is not a production-grade. Conversely, you will not be able to reach the level of Google with Borg in an offline store, branch or peripheral location, although it is unlikely that you need it.
This article outlines tips for achieving a production-level Kubernetes deployment, even in a resource limiting situation.
Important components in the Kubernetes cluster
Before delving into the details, it is important to understand the overall architecture of Kubernetes.
The Kubernetes cluster is a highly distributed system based on the control plane and the architecture of the clustered worker node, as shown below:
Typically, the components of the API Server, Controller Manager and Scheduler are located in several instances of the nodes of the control level (it is called the Master). Master nodes typically also include etcd, however there are large and highly available scripts that require running etcd on independent hosts. Components can be run as containers and, optionally, under the supervision of Kubernetes, that is, work as static pods.
For high availability, redundant instances of these components are used. Significance and required level of redundancy can vary.
| Roles | Consequences of loss | Recommended Instances | |
|---|---|---|---|
| etcd | Maintains the state of all Kubernetes objects | Catastrophic loss of storage. Most of the loss = Kubernetes loses control level, API Server depends on etcd, read-only API calls that do not need quorum, as well as already created workloads, can continue to work. | odd number, 3+ |
| API Server | Provides API for external and internal use. | It is impossible to stop, start, update new scams. Scheduler and Controller Manager depend on API Server. Loads continue if they are independent of API calls (operators, custom controllers, CRD, etc.) | 2+ |
| kube-scheduler | Places pods on nodes | Pods cannot be placed, prioritized and moved between them. | 2+ |
| kube-controller-manager | Controls many controllers | The main control loops responsible for the state stop working. Integration of in-tree cloud provider is breaking. | 2+ |
| cloud-controller-manager (CCM) | Out-of-tree integration of cloud providers | Integration of cloud provider breaks down | one |
| Additions (for example, DNS) | Various | Various | Depends on the add-on (for example, 2+ for DNS) |
The risks of these components include hardware failures, software bugs, bad updates, human errors, network interruptions, and system overload leading to resource depletion. Excessiveness can reduce the impact of these hazards. In addition, thanks to the functions of the hypervisor platform (resource planning, high availability), you can multiply the results using the Linux operating system, Kubernetes, and container runtime.
The API Server uses multiple load balancer instances to achieve scalability and availability. Load balancer is an important component for high availability. Several A-records of the DNS API server can serve as an alternative in the absence of a balancer.
The kube-scheduler and kube-controller-manager participate in the process of choosing a leader instead of using a load balancer. Since cloud-controller-manager is used for certain types of hosting infrastructure, the implementation of which may vary, we will not discuss them - just let us indicate that they are a component of the control layer.
Pods running on the Kubernetes worker are managed by a kubelet agent. Each worker instance runs a kubelet-agent and a CRI- compatible container launch environment. Kubernetes itself is designed to monitor and recover from a crash node. But for critical load functions, managing hypervisor resources and isolating loads, it can be used to improve availability and increase the predictability of their work.
etcd
etcd is the persistent storage for all Kubernetes objects. The availability and recoverability of the etcd cluster should be a priority when deploying a production-grade Kubernetes.
An etcd cluster of five nodes is the best option if you can enable it. Why? Because you will be able to maintain one, and still endure failure. A cluster of three nodes is the minimum that we can recommend for a production-grade service, even if only one host hypervisor is available. More than seven nodes are also not recommended, with the exception of very large installations covering several availability zones.
The minimum recommendations for hosting nodes etcd cluster - 2GB RAM and 8GB SSD hard drive. Usually, 8GB of RAM and 20GB of hard disk space is sufficient. Disk performance affects the recovery time of the node after a failure. Check out to find out details.
In special cases, think about a few etcd clusters.
For very large Kubernetes clusters, consider using a separate etcd cluster for Kubernetes events, so that too many events do not affect the main Kubernetes API service. When using the Flannel network, the configuration is saved in etcd, and the version requirements may differ from Kubernetes. This can make it difficult to back up etcd, so we recommend using a separate etcd cluster specifically for the flannel.
Single Host Deployment
The list of accessibility risks includes hardware, software, and human factors. If you are limited to a single host, the use of redundant storage, error-correcting memory, and dual power supplies can improve security against hardware failures. Running a hypervisor on a physical host allows you to use redundant software components and adds operational benefits associated with deploying, updating, and controlling resource utilization. Even in stressful situations, the behavior remains repeatable and predictable. For example, even if you can only afford to launch singletones from master services, they should be protected from overload and resource depletion, competing with the workload of your application. A hypervisor can be more efficient and easier to use than setting priorities in the Linux scheduler, cgroups, Kubernetes flags, etc.
You can deploy three etc etc virtual machines if resources allow on the host. Each of the VMs must be supported by a separate physical storage device or use separate parts of the storage using redundancy (mirroring, RAID, etc.).
Dual redundant instances of the server API, scheduler, and controller manager are the next upgrade, if your only host has enough resources for this.
Single host deployment options, from least suitable for production to most
| Type of | Specifications | Result |
|---|---|---|
| Singleton etcd and master components. | Home laboratory, not at all production-grade. Several single points of failure (Single Point of Failure, SPOF). Recovery is slow, and with the loss of storage is completely absent. | |
| Improved storage redundancy | etcd singleton and master components, etcd storage is redundant. | At a minimum, you can recover from a storage failure. |
| Managed level redundancy | No hypervisor, multiple instances of managed-level components in static hearths. | There was protection against software bugs, but the OS and container launch environment are still single points of failure with devastating updates. |
| Adding Hypervisor | Run three redundant managed level instances in the VM. | There was protection against software bugs and human error and an operational advantage in installation, resource management, monitoring and security. OS upgrades and container launch environments are less destructive. The hypervisor is the only single point of failure. |
Deploy to two hosts
With two hosts, storage problems etcd are similar to the single-host option — you need redundancy. It is preferable to run three encd instances. It may seem non-intuitive, but it is better to concentrate all etcd nodes on the same host. You do not increase reliability by dividing them by 2 + 1 between two hosts - losing nodes with most encd instances leads to interruption, regardless of whether they are 2 or 3. If the hosts are not identical, place the etcd cluster entirely on the more reliable one.
It is recommended to launch redundant API servers, kube-schedulers and kube-controller-managers. They should be shared between hosts to minimize the risk of failure of the container launch environment, operating system, and equipment.
Running a hypervisor layer on physical hosts will allow you to work with redundant program components, ensuring control of resource consumption. It also has the operational advantage of scheduled maintenance.
Deployment options for two hosts, from the least suitable for production to the most
| Type of | Specifications | Result |
|---|---|---|
| Two hosts, without redundant storage. Singleton etcd and master components on the same host. | etcd - a single point of failure, it makes no sense to run two on other master services. The separation between two hosts increases the risk of a managed level of failure. The potential advantage of resource isolation is by running a managed layer on one host and application workloads on another. If the storage is lost, there is no recovery. | |
| Improved storage redundancy | Singleton etcd and master components on the same host, etcd storage is redundant. | At a minimum, you can recover from a storage failure. |
| Managed level redundancy | No hypervisor, multiple instances of managed-level components in static hearths. etcd cluster on the same host, the other components of the managed level are separated. | Hardware failure, firmware upgrades, operating systems, and container launch environments on a host without etcd are less destructive. |
| Adding a hypervisor to both hosts | The virtual machines run three redundant components of the managed level, etcd cluster on the same host, the components of the managed level are separated. Application workloads can reside on both VM nodes. | Improved isolation of application loads. Updates of the operating system and container launch environments are less destructive. Routine hardware / firmware maintenance becomes non-destructive if the hypervisor supports VM migration. |
Deploy to three (or more) hosts
Transition to uncompromising production-grade service. We recommend dividing etcd between the three hosts. One equipment failure will reduce the amount of possible application workloads, but will not result in a complete service outage.
Very large clusters will require more instances.
Launching a hypervisor layer provides operational advantages and improved isolation of application workloads. This is beyond the scope of the article, but at the level of three or more hosts, improved features may be available (clustered redundant shared storage, resource management with a dynamic load balancer, automated state monitoring with live migration and failover).
Deployment options for three (or more) hosts from the least suitable for production to the most
| Type of | Specifications | Result |
|---|---|---|
| Three hosts. Etcdd on each node Master components on each node. | Loss of a node reduces performance, but does not lead to a drop in Kubernetes. The possibility of recovery remains. | |
| Add hypervisor to hosts | In virtual machines on three hosts running etcd, API server, schedulers, controller manager. Workloads are running on the VM on each host. | Added protection against OS / environment of container / software launch and human error. Operational benefits of installation, upgrades, resource management, monitoring, and security. |
Configure Kubernetes configuration
Master and Worker nodes must be protected from overload and resource depletion. Hypervisor functions can be used to isolate critical components and reserve resources. There are also Kubernetes configuration settings that can slow things like API speed. Some installation kits and commercial distributions take care of this, but if you are self-deploying Kubernetes, the default settings may not be appropriate, especially for small resources or a cluster that is too large.
The consumption of resources at a managed level correlates with the number of hearths and the outflow rate of hearths. Very large and very small clusters will benefit from the modified settings for slowing down kube-apiserver requests and memory.
Node Allocatable must be configured on the nodes of the worker based on a reasonable supported load density on each node. Namespaces can be created to divide the cluster of the worker node into several virtual clusters with quotas for CPU and memory.
Security
Each Kubernetes cluster has a root Certificate Authority (CA). The Controller Manager, API Server, Scheduler, kubelet client, kube-proxy and administrator certificates must be generated and installed. If you use the tool or distribution kit of installation, then probably you should not deal with it independently. The manual process is described here . You should be ready to reinstall certificates in case of expansion or replacement of nodes.
Since Kubernetes is fully managed by the API, it is extremely important to control and limit the list of those who have access to the cluster. Encryption and authentication options are discussed in this documentation.
Kubernetes application workloads are based on container images. You need the source and contents of these images to be reliable. Almost always this means that you will host the container image in the local repository. Using images from the public Internet can cause problems of reliability and security. You must select a repository that has support for image signing, security scanning, access control for sending and downloading images, and activity logging.
Processes must be configured to support the application of host firmware updates, hypervisor, OS6, Kubernetes, and other dependencies. Versioning is required to support auditing.
Recommendations:
- Strengthen the default security settings for components of the managed level (for example, blocking a worker node );
- Use the Podov Security Policy ;
- Consider the integration of NetworkPolicy available for your network solution, including tracking, monitoring, and troubleshooting;
- Use RBAC to make authorization decisions;
- Consider physical security, especially when deployed in peripheral or remote locations that may be left unattended. Add storage encryption to limit the effects of device theft, and protect against the connection of malicious devices, such as USB keys;
- Protect the text credentials of the cloud provider (access keys, tokens, passwords, etc.).
Kubernetes secret objects are suitable for storing small amounts of sensitive data. They are stored in etcd. They can be safely used to store the Kubernetes API credentials, but there are times when a more comprehensive solution is required for the workload or expansion of the cluster itself. The HashiCorp Vault project is a popular solution if you need more than the built-in secret objects can provide.
Disaster Recovery and Backup
Implementing redundancy through the use of multiple hosts and VMs helps reduce the number of certain types of failures. But scenarios such as a natural disaster, a bad update, a hacker attack, software bugs, or a human error can still turn into crashes.
A crucial part of the production deployment is waiting for the need for future recovery.
It is also worth noting that part of your investment in the design, documentation, and automation of the recovery process can be reused if large-scale replicated multi-site deployments are required.
Among the elements of disaster recovery, it is worth noting backups (and possibly replicas), replacements, a planned process, people who will perform this process, and regular training. Frequent test exercises and principles of Chaos Engineering can be used to test your readiness.
Due to availability requirements, it may be necessary to store local copies of the OS, Kubernetes components, and container images to allow recovery even if the Internet fails. The ability to deploy replacement hosts and nodes in a “physical isolation” situation improves security and increases deployment speed.
All Kubernetes objects are stored in etcd. Periodic backup of data of an etcd-cluster is an important element in restoring Kubernetes clusters under abnormal scenarios, for example, if all master nodes are lost.
Cluster etcd can be backed up using the snapshot mechanism built into etcd and copying the result to storage to another failure domain. Snapshot files contain all Kubernetes states and critical information. Encrypt snapshot files to protect sensitive Kubernetes data.
Keep in mind that some Kubernetes extensions can store states in separate etcd clusters, persistent volumes or some other mechanism. If these conditions are critical, they should have a backup and recovery plan.
But some important states are stored outside etcd. Certificates, container images, other settings and states associated with operations can be controlled by an automatic install / update tool. Even if these files can be regenerated again, a backup or replica will speed up disaster recovery. Consider the need for a backup and recovery plan for the following objects:
- Certificate and key pairs: CA, API Server, Apiserver-kubelet-client, ServiceAccount authentication, “Front proxy”, Front proxy client;
- Important DNS records;
- Assign and reserve IP / Subnet;
- External load balancer;
- Kubeconfig files;
- LDAP and other authentication details;
- The account and configuration data of the cloud provider.
Load offerings
Anti-affinity specifications can be used to split clustered services between backup hosts. But in this case, the settings are used only if it is scheduled. This means that Kubernetes can restart the failed node of your clustered application, but does not have a built-in mechanism for rebalancing after a failure. This topic deserves a separate article, but additional logic can be useful for achieving optimal placement of workloads after a host or a worker node is restored or expanded. The Prioritization and Crowd Out function can be used to select the desired sorting in case of a shortage of resources caused by a failure.
In the case of stateful services, external mounted volumes are the Kubernetes recommendation standard for nonclustered services (for example, for a typical SQL database). Currently, external volume snapshots managed by Kubernetes are in the roadmap feature request category, and are most likely related to the integration of the Container Storage Interface (CSI). Thus, the creation of backup copies of such a service will require in-box actions depending on the specific application, which is beyond the scope of this article. Therefore, while we are waiting for the improvement of Kubernetes support for workflow snapshots and backup, it is worth thinking about starting the database service not in a container, but in a virtual machine, and opening it to Kubernetes loads.
Clustered stateful services (for example, Cassandra) can take advantage of the separation between hosts using local persistent volumes, if resources permit. This will require deploying multiple Kubernetes work nodes (there may be VMs on hypervisor hosts) to maintain a quorum at the point of failure.
Other offers
Logs and metrics (if you collect and store them) are useful for diagnosing failures, but given the variety of available technologies, we will not consider them in this article. If you have an Internet connection, it is advisable to keep logs and metrics outside, centrally.
In a production deployment, automated installation, configuration, and upgrade tools should be used (for example, Ansible , BOSH , Chef , Juju , kubeadm , Puppet , etc.). The manual process is too laborious and difficult to scale, it is easy to make mistakes and run into problems of repeatability. Certified distributions are likely to include a means to save the settings when upgrading, but if you use your own toolchain for installation and configuration, storing, backing up and restoring configuration artifacts is of paramount importance. It is worth thinking about using a version control system, like Git, to store components and deployment settings.
Recovery
Ranbuki , in which recovery processes are documented, should be tested and saved offline - perhaps even printed. When an employee is called at 2 am on Fridays, improvisation is not the best option. It is better to complete all the items from the planned and tested checklist - which is accessible both to the employees in the office and to the remote ones.
Final thoughts
Buying a commercial airline ticket is a simple and safe process. But if you are flying to a remote place with a short runway, a commercial flight on an Airbus A320 is not an option. This does not mean that airfare should not be considered at all. It only means that compromises are necessary.
In the context of aviation, engine failure in a single-engine vessel means a crash. With two engines, at a minimum, there will be more opportunities to decide where the crash will occur. Kubernetes on a small number of hosts is similar, and if your business case justifies, you should think about increasing the fleet, consisting of large and small machines (for example, FedEx, Amazon).
When designing Kubernetes production-grade solutions, you have many options and options. A simple article can not give all the answers and has no idea about your priorities. Nevertheless, we hope that she provided a list of things to think about, as well as some useful recommendations. There are options that have not been reviewed (for example, launching Kubernetes components using self-hosting , rather than static pods). Perhaps they should be discussed in the following articles, if there is enough interest. In addition, due to the high rate of improvement of Kubernetes, if your search engine found this article after 2019, some of its materials might already be outdated.
THE END
As always, we are waiting for your questions and comments here, and you can go to the Open Day to Alexander Titov .
Source: https://habr.com/ru/post/422179/
All Articles