Upload data to Excel. Civilized
There are tasks in the IT industry that, against the background of success in big data , machine learning , blockchain and other fashion trends, look completely unattractive, but for dozens of years have not ceased to be relevant for an entire army of developers. It will be about the old as the world task of building and uploading Excel-documents, faced by everyone who has ever written business applications.
')
What possibilities of building Excel files exist in principle?
In my opinion, it is the latter method that is now preferable for generating MS Office-compatible documents. On the one hand, it does not require installation of any proprietary software on the server, but on the other hand, it provides a rich API that allows you to use all the functionality of MS Office.
But using Apache POI directly has its drawbacks. First, it is a Java library, and if your application is not written in one of the JVM languages, you can hardly use it. Secondly, it is a low-level library that works with such concepts as “cell”, “column”, “font”. Therefore, the “head-on” written procedure for generating a document quickly turns into an abundant “noodle” of hard-to-read code, where there is no separation between the data model and the presentation, it is difficult to make changes and, in general, pain and shame. And a great reason to delegate the task to the most inexperienced programmer - let him pick.
But it could be completely different. The Xylophone project under the LGPL license, built on the basis of Apache POI, is based on an idea that has approximately 15 years of history. In the projects where I participated, it was used in combination with a variety of platforms and languages - and probably thousands of forms go with the variety of forms made with it in a wide variety of projects. This is a Java project that can work both as a command line utility and as a library (if you have JVM code, you can connect it as a Maven dependency).
Xylophone implements the principle of separating the data model from their presentation. In the upload procedure, you need to generate data in XML format (without worrying about cells, fonts and dividing lines), and Xylophone, using an Excel template and a descriptor that describes how to work around your XML file with data, will generate the result, as shown in the diagram:

The document template (xls / xlsx template) looks like this:

As a rule, the procurement of such a template provides the customer. The involved customer is happy to take part in the creation of the template: starting with choosing the right shape from the “Consultant” or inventing your own from scratch, and ending with font sizes and widths of dividing lines. The advantage of the template is that minor changes to it are easy to make when the report is fully developed.
When the “design” work is done, the developer remains
With unloading in XML, everything is more or less clear: it is enough to choose an adequate XML representation of the data necessary to fill out the form. What is a handle?
If the form we create did not have duplicate elements with different quantities (such as invoice lines, of which there are different numbers for different invoices), then the descriptor would look like this:
Here, root is the name of the root element of our XML file with data, and the range A1: Z100 is the rectangular range of cells from the template that will be copied to the result. In this case, as can be seen from the previous illustration, the wildcard fields, the values of which are replaced with data from the XML file, have the format
What if we need repetitive elements in the report? Naturally, they can be represented as elements of an XML file with data, and a descriptor helps to iterate over them as needed. The repetition of elements in a report can have both a vertical direction (when we insert invoice lines, for example), and horizontal (when we insert analytical report columns). At the same time, we can use nesting of XML elements to reflect as deeply nested repetitive elements of the report as shown in the diagram:

Red squares mark the cells, which will be the upper left corner of the next rectangular fragment that docks the report generator.
There is one more possible variant of repeating elements: sheets in an Excel workbook. The ability to organize such an iteration is also available.
Consider a slightly more complex example. Suppose we need to get a summary report like the following:
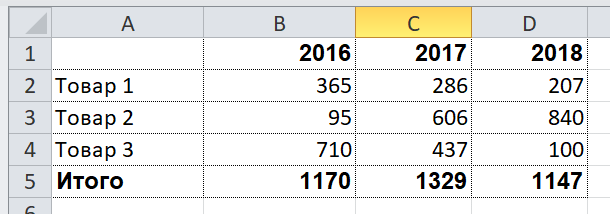
Let the user choose a range of years to upload, so in this report both rows and columns are dynamically generated. The XML data representation for such a report might look like this:
We are free to choose the names of tags to your liking, the structure can also be arbitrary, but with an eye to the ease of conversion into the report. For example, I usually write down the values on the sheet in attributes, because this simplifies XPath expressions (conveniently, when they look like
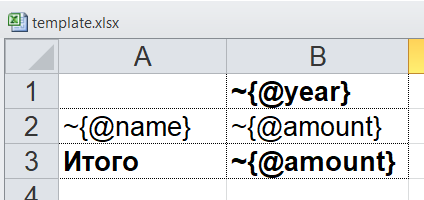
The template for such a report will look like this (compare XPath expressions with the attribute names of the corresponding tags):
Now comes the most interesting part: creating a descriptor. Since this is a report that is almost completely dynamically collected, the handle is rather complicated, in practice (when we only have the header of the document, its lines and the basement) everything is usually much simpler. Here is the handle in this case:
Fully descriptor elements are described in the documentation . In short, the basic descriptor elements mean the following:
In fact, there are many more options in the descriptor, see the documentation.
Well, it's time to download Xylophone and start generating a report.
Take the archive from bintray or Maven Central (NB: at the time of reading this article, there may be more recent versions). A shell script is located in the / bin folder, and if you run it without parameters, you will see a hint about the command line parameters. To get the result, we need to “feed” the xylophone all the previously prepared ingredients:
Open the report.xlsx file and make sure that we get exactly what we need:
Since the library ru.curs: xylophone is available on Maven Central under the LGPL license, it can be used without problems in programs in any JVM language. Perhaps the most compact fully working example is in Groovy, the code does not need comments:
The
An important option that I haven’t mentioned so far is the ability to choose between DOM and SAX parsers at the stage of parsing a file with XML data. As you know, the DOM parser loads the entire file into memory as a whole, builds its object representation and makes it possible to bypass its contents in an arbitrary manner (including re-returning to the same element). The SAX parser never puts the entire data file in memory, instead it treats it as a “stream” of elements, making it impossible to return to the element again.
Using SAX mode in Xylophone (via the command line parameter
I hope that the method of uploading to Excel via Xylophone you liked and will save a lot of time and nerves - as it saved us.
And finally, once again links:
')
What possibilities of building Excel files exist in principle?
- VBA macros. Nowadays, for security reasons, the idea of using macros is often not appropriate.
- Automate Excel external program through API. Requires Excel on the same machine as the program that generates Excel reports. At a time when customers were thick and were written in the form of Windows desktop applications, this method was suitable (although it did not differ in speed and reliability), in today's realities this is a difficult case to be achieved.
- Generate an XML Excel file directly. As you know, Excel supports the XML format for saving the document, which can potentially be generated / modified using any XML tool. This file can be saved with the .xls extension, and although, strictly speaking, it is not an xls file, Excel opens it well. Such an approach is quite popular, but the disadvantages include the fact that any solution based on direct editing of the XML-Excel format is a one-time hack, lacking in common.
- Finally, it is possible to generate Excel files using open source libraries, of which Apache POI is especially known. Apache POI developers have done a titanic work on reverse engineering of binary formats of MS Office documents, and continue to maintain and develop this library for many years. The result of this reverse engineering, for example, is used in Open Office to implement saving documents in formats compatible with MS Office.
In my opinion, it is the latter method that is now preferable for generating MS Office-compatible documents. On the one hand, it does not require installation of any proprietary software on the server, but on the other hand, it provides a rich API that allows you to use all the functionality of MS Office.
But using Apache POI directly has its drawbacks. First, it is a Java library, and if your application is not written in one of the JVM languages, you can hardly use it. Secondly, it is a low-level library that works with such concepts as “cell”, “column”, “font”. Therefore, the “head-on” written procedure for generating a document quickly turns into an abundant “noodle” of hard-to-read code, where there is no separation between the data model and the presentation, it is difficult to make changes and, in general, pain and shame. And a great reason to delegate the task to the most inexperienced programmer - let him pick.
But it could be completely different. The Xylophone project under the LGPL license, built on the basis of Apache POI, is based on an idea that has approximately 15 years of history. In the projects where I participated, it was used in combination with a variety of platforms and languages - and probably thousands of forms go with the variety of forms made with it in a wide variety of projects. This is a Java project that can work both as a command line utility and as a library (if you have JVM code, you can connect it as a Maven dependency).
Xylophone implements the principle of separating the data model from their presentation. In the upload procedure, you need to generate data in XML format (without worrying about cells, fonts and dividing lines), and Xylophone, using an Excel template and a descriptor that describes how to work around your XML file with data, will generate the result, as shown in the diagram:
The document template (xls / xlsx template) looks like this:
As a rule, the procurement of such a template provides the customer. The involved customer is happy to take part in the creation of the template: starting with choosing the right shape from the “Consultant” or inventing your own from scratch, and ending with font sizes and widths of dividing lines. The advantage of the template is that minor changes to it are easy to make when the report is fully developed.
When the “design” work is done, the developer remains
- Create a procedure for uploading the necessary data in XML format.
- Create a descriptor that describes how to crawl the elements of the XML file and copy fragments of the template into the resulting report
- Bind template cells to elements of an XML file using XPath expressions.
With unloading in XML, everything is more or less clear: it is enough to choose an adequate XML representation of the data necessary to fill out the form. What is a handle?
If the form we create did not have duplicate elements with different quantities (such as invoice lines, of which there are different numbers for different invoices), then the descriptor would look like this:
<element name="root"> <output range="A1:Z100"/> </element> Here, root is the name of the root element of our XML file with data, and the range A1: Z100 is the rectangular range of cells from the template that will be copied to the result. In this case, as can be seen from the previous illustration, the wildcard fields, the values of which are replaced with data from the XML file, have the format
~{XPath-} (tilde, brace, XPath-expression relative to the current XML element, the closing brace).What if we need repetitive elements in the report? Naturally, they can be represented as elements of an XML file with data, and a descriptor helps to iterate over them as needed. The repetition of elements in a report can have both a vertical direction (when we insert invoice lines, for example), and horizontal (when we insert analytical report columns). At the same time, we can use nesting of XML elements to reflect as deeply nested repetitive elements of the report as shown in the diagram:
Red squares mark the cells, which will be the upper left corner of the next rectangular fragment that docks the report generator.
There is one more possible variant of repeating elements: sheets in an Excel workbook. The ability to organize such an iteration is also available.
Consider a slightly more complex example. Suppose we need to get a summary report like the following:
Let the user choose a range of years to upload, so in this report both rows and columns are dynamically generated. The XML data representation for such a report might look like this:
testdata.xml
<?xml version="1.0" encoding="UTF-8"?> <report> <column year="2016"/> <column year="2017"/> <column year="2018"/> <item name=" 1"> <year amount="365"/> <year amount="286"/> <year amount="207"/> </item> <item name=" 2"> <year amount="95"/> <year amount="606"/> <year amount="840"/> </item> <item name=" 3"> <year amount="710"/> <year amount="437"/> <year amount="100"/> </item> <totals> <year amount="1170"/> <year amount="1329"/> <year amount="1147"/> </totals> </report> We are free to choose the names of tags to your liking, the structure can also be arbitrary, but with an eye to the ease of conversion into the report. For example, I usually write down the values on the sheet in attributes, because this simplifies XPath expressions (conveniently, when they look like
@ ).The template for such a report will look like this (compare XPath expressions with the attribute names of the corresponding tags):
Now comes the most interesting part: creating a descriptor. Since this is a report that is almost completely dynamically collected, the handle is rather complicated, in practice (when we only have the header of the document, its lines and the basement) everything is usually much simpler. Here is the handle in this case:
descriptor.xml
<?xml version="1.0" encoding="UTF-8"?> <element name="report"> <!-- --> <output worksheet="" sourcesheet="1"/> <!-- --> <iteration mode="horizontal"> <element name="(before)"> <!-- --> <output range="A1"/> </element> <element name="column"> <output range="B1"/> </element> </iteration> <!-- : , --> <iteration mode="vertical"> <element name="item"> <!-- - --> <iteration mode="horizontal"> <element name="(before)"> <!-- --> <output range="A2"/> </element> <!-- --> <element name="year"> <output range="B2"/> </element> </iteration> </element> </iteration> <iteration> <element name="totals"> <iteration mode="horizontal"> <element name="(before)"> <!-- --> <output range="A3"/> </element> <!-- --> <element name="year"> <output range="B3"/> </element> </iteration> </element> </iteration> </element> Fully descriptor elements are described in the documentation . In short, the basic descriptor elements mean the following:
- element — Switch to the read mode for the element in the XML file. It can either be the root element of a descriptor, or it can be inside an
iteration. Using thenameattribute, various filters can be set for elements, for examplename="foo"- elements with tag name fooname="*"- all elementsname="tagname[@attribute='value']"- elements with a specific name and attribute valuename="(before)",name="(after)"- “virtual” elements preceding the iteration and closing the iteration.
- iteration - transition to the iteration mode. Can only be inside
element. Various parameters can be set, for examplemode="horizontal"-mode="horizontal"output mode (default is vertical)index=0- limit iteration to only the very first element encountered
- output - switch to output mode. The main attributes are as follows:
sourcesheet— A book of the template from which the output range is taken. If not specified, the current (last used) sheet is applied.range- the range of the pattern to be copied to the resulting document, for example “A1: M10”, or “5: 6”, or “C: C”. (Using row ranges of the type “5: 6” in the horizontal output mode and column ranges of the type “C: C” in the vertical output mode will result in an error).worksheet- if defined, a new sheet is created in the output file and the output position is shifted to cell A1 of this sheet. The value of this attribute, equal to the constant or XPath expression, is substituted into the name of the new sheet.
In fact, there are many more options in the descriptor, see the documentation.
Well, it's time to download Xylophone and start generating a report.
Take the archive from bintray or Maven Central (NB: at the time of reading this article, there may be more recent versions). A shell script is located in the / bin folder, and if you run it without parameters, you will see a hint about the command line parameters. To get the result, we need to “feed” the xylophone all the previously prepared ingredients:
xylophone -data testdata.xml -template template.xlsx -descr descriptor.xml -out report.xlsx Open the report.xlsx file and make sure that we get exactly what we need:
Since the library ru.curs: xylophone is available on Maven Central under the LGPL license, it can be used without problems in programs in any JVM language. Perhaps the most compact fully working example is in Groovy, the code does not need comments:
@Grab('ru.curs:xylophone:6.1.3') import ru.curs.xylophone.XML2Spreadsheet baseDir = '.' new File(baseDir, 'testdata.xml').withInputStream { input -> new File(baseDir, 'report.xlsx').withOutputStream { output -> XML2Spreadsheet.process(input, new File(baseDir, 'descriptor.xml'), new File(baseDir, 'template.xlsx'), false, output) } } println 'Done.' The
XML2Spreadsheet class has several overloaded variants of the static process method, but they all boil down to passing all the same “ingredients” needed to prepare the report.An important option that I haven’t mentioned so far is the ability to choose between DOM and SAX parsers at the stage of parsing a file with XML data. As you know, the DOM parser loads the entire file into memory as a whole, builds its object representation and makes it possible to bypass its contents in an arbitrary manner (including re-returning to the same element). The SAX parser never puts the entire data file in memory, instead it treats it as a “stream” of elements, making it impossible to return to the element again.
Using SAX mode in Xylophone (via the command line parameter
-sax or by setting the useSax parameter to true XML2Spreadsheet.process ) is critically useful in cases when you need to generate very large files. Due to the speed and efficiency of the resources of the SAX parser, the speed of file generation increases many times. This is at the cost of some small restrictions on the descriptor (described in the documentation), but in most cases the reports satisfy these restrictions, so I would recommend using the SAX mode wherever possible.I hope that the method of uploading to Excel via Xylophone you liked and will save a lot of time and nerves - as it saved us.
And finally, once again links:
- source code is here: github.com/CourseOrchestra/xylophone
- Documentation - here: courseorchestra.imtqy.com/xylophone
- All code samples from this article are here: github.com/inponomarev/xylophone-example .
Source: https://habr.com/ru/post/422059/
All Articles