Examination of the file system HDD video recorder model QCM-08DL

This article is devoted to the study of the file structure of an eight-channel video recorder hard drive with the aim of massively extracting video files. At the end of the article is the implementation of the corresponding program in the C language.
DVR (abbreviated DVR) QCM-08DL is used in video surveillance systems and allows eight-channel recording of video and audio. This model, in my opinion, is one of the cheapest and at the same time reliable in operation. The video compression format is the popular H264 format. For audio, the ADPCM compression format is used. Video and audio are recorded on a standard computer SATA hard disk (HDD) installed inside the DVR. Using the DVR itself, it is possible to view the recordings by searching them by date and time. Also, it is possible to extract data to a file on external media. First, on a USB drive that connects to the USB interface of the DVR. Secondly - to the computer through the WEB-interface of the DVR. The name of the resulting file is long, and includes the recording date, the start and end time, the recording channel, and other additional information. The file extension is “.264”. An examination of the contents of such a file made me understand that the media container in which the audio and video streams are packed is far from standard. Such a file can be opened using the player, which is attached with the DVR. The player is very uncomfortable. But also, you can use the program-repacker in the container AVI, which is also attached. This program repacks the video stream, leaving it in H264 format. And the audio stream converts from ADMCM to PCM, increasing it 4 times in size. The result is an .avi file played by any standard player. I note immediately that this repacker program is very inconvenient. It allows you to perform operations on only one file. To repack multiple files, you have to open them one by one.
The following tasks were set.
')
- Get access to all .264 files from the hard disk of the DVR by connecting the hard disk to the computer.
- Examine the algorithm by which the regular 264-avi repacker program works and create the same program that would perform the same operations, but not on one, but on a whole group of files, and with one click.
The first task, at first glance, may seem very simple: you just need to connect the HDD to the computer and open partitions in the explorer. However, there are some pitfalls. This article is dedicated to the first task.
I already knew in advance that the program shell of the DVR microcontroller is based on an operating system like Linux. Therefore, the layout of the hard drive is also likely to be Linux-like. Therefore, you need a computer running Linux. In my case, the HDD capacity is 1TB, a computer running Xubuntu OS. Having connected the HDD to the computer, I managed to see only one partition for several gigabytes. This is clearly not what is needed. Inside the section there is a set of folders named “YYYY-MM-DD”, corresponding to the dates of entries. Inside each folder - a set of files corresponding to the records. Files of the same name with those obtained when extracting from the DVR. However, their size is several times smaller and the extension is not .264, but .nvr. It is necessary to assume that these same nvr files are keys for the corresponding 264 files (or their media streams), the contents of which are located on the main HDD space. I copied these file folders to a separate media for further research.
I used a variety of software tools for research: a disk editor (it’s also a binary file editor) DiskExplorer (I used WinHex later), MS Excel for auxiliary calculations and fixing of results, Dev-C ++ programming environment for writing auxiliary and final console programs and so on. In this article I will try to talk about this procedure.
First, we will look at the very first HDD sector (one sector (1 LBA) takes 512 Bytes). This sector, as a rule, contains the MBR structure. It includes the bootloader and the basic table of contents of the sections. The structure of this sector, as well as the structure of the section description, is given below (taken from Wikipedia).

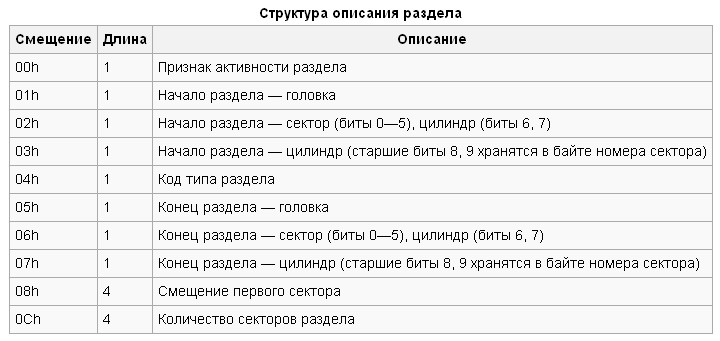
In the case of the HDD under study, we have the following. Looking at the figure below and guided by the tables above, we see that the loader is missing. But we are more interested in the partition table. It is highlighted in red. The last two bytes (blue fill) - MBR signature. From the partition table, you can see the disk is divided into two sections. The code for the type of the first section (yellow fill) is 0x0B. This is the FAT32 section. The type code for the second (orange fill) is 0x83. This is one of the sections of Linux (in the sense of EXT). The bytes of the section type code are circled in blue.
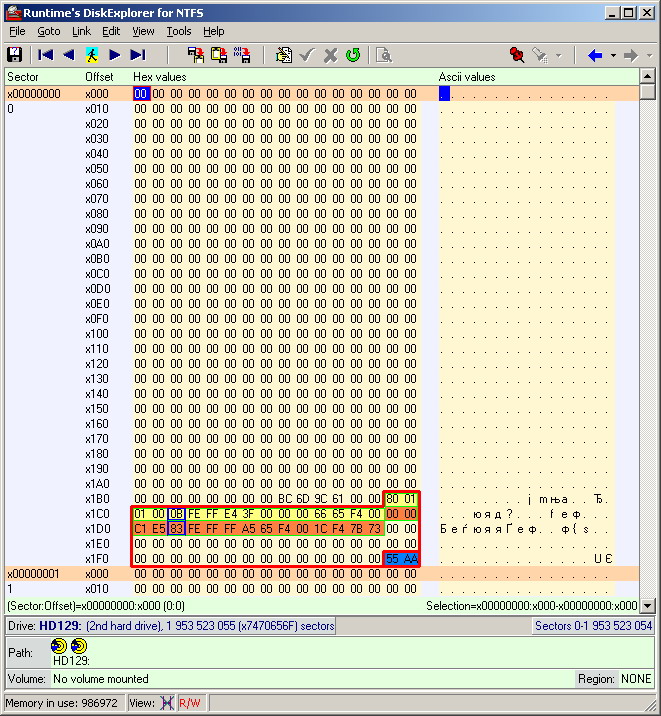
The full decryption of the MBR sector with the partition table and their parameters is shown below.
Paying attention to the size of the partitions (recalculating the number of sectors in gigabytes), it is easy to guess that the computer with OS Xubuntu displayed exactly the first partition, which occupies a small part of the disk space. Incidentally, in Windows XP, only the first section was also displayed, but it did not open from the explorer. And why, then, the second Linux partition did not appear in the Xubuntu OS?
Having studied the structure and organization of the Linux file system on the example of EXT2, I proceeded to the study of the second section.
As can be seen from the partition table, the second partition starts from sector 16016805. The EXT2 file system manual indicates the presence of a so-called superblock, which is located 1024 bytes from the beginning of the partition (that is, two sectors from the beginning). However, the sector 16016805 + 2 = 16016807 was empty. But the first sector 16016805 in its structure resembled a superblock. But its contents did not fully correspond to the description of the contents of the superblock from the manual. The superblock is the main unit, which contains a kind of table of various constants and parameters for the functioning of the file system: the addresses of the positions and the sizes of other necessary blocks, in particular, the headers of the file records and directories. Further research in this section led me to only one conclusion: the DVR uses its unique file system.
Later I decided to take a look at the first sector of the first section (sector 63) and scroll down. It was discovered on sector 65 (two sectors below) the content that is completely similar to the content of the EXT2 FS superblock, which is described in the manual. Further research led to the conclusion that the first section of the HDD DVR is the EXT2 section, which was displayed in the Xubuntu OS, despite the 0x08 mark (not EXT) in the section heading! Thus, the first section of the hard disk of the DVR is the EXT2 section, on which nvr files are recorded, which are the keys to the required video recordings.
I will write briefly about the structure of the .264 files, which I also previously investigated. This information will be further necessary for the study of the second section of the HDD. As in any media container, in “264” there is a header with service information and media tags, as well as audio and video streams, which follow small blocks one after the other. At offset 0x84 bytes from the beginning of the file, the keyword "MDVR96NT_2_R" is written. Before this word are bytes related to the date and time of recording. But this information is contained in the file name, therefore, it does not deserve special attention here. After that comes a lot of bytes of zeros. Basic information from audio and video streams begins at an offset of 65,536 bytes. Blocks of a video stream begin with an 8-byte header “01dcH264” (there is also “00dcH264”). The following 4 bytes describe the size of the current block of the video stream in bytes. After 4 bytes of zeros (00 00 00 00) the video stream block itself begins. Blocks of audio streams have the header “03wb” (although, according to my observations, the first character of the header in some cases was not necessarily “0”). After - 12 bytes of information, which I have not yet divined. And starting from the 17th byte - a fixed-length audio stream of 160 bytes. There are no tags at the end of the file.
We proceed to the study of the structure of files and directories located on the first section of the HDD. As mentioned above, the contents of the section were copied to a separate media through a normal explorer in the Xununtu OS. In each directory (directories), in addition to the nvr files, there is one binary file named “file_list”. Judging by the name, it contains information about the list of files in the current directory. Open this file in a binary editor (see the figure below). I researched the structure of this file, and in principle there is nothing interesting. The file has no information regarding the location of the desired media streams. However, I will briefly write about this structure. The first 32 bytes are a header with some constants. The next 16 bytes are related to the date and time and the number of files in the current directory. This is followed by 48 bytes of constants. Next - 8 bytes of constants, indicating the beginning of the file entry. Next - 96 bytes, indicating the full path to the nvr file, including its name. Then - 24 bytes relating to the time (the number of seconds elapsed from the beginning of the day, the beginning and end of the video) and other attributes of the video. And so on, by analogy, for all nvr files in the current directory. Their number equals the number of videos for the current day, which indicates the name of the current directory. What is this file for? Apparently, to speed up the search for video within the DVR interface.
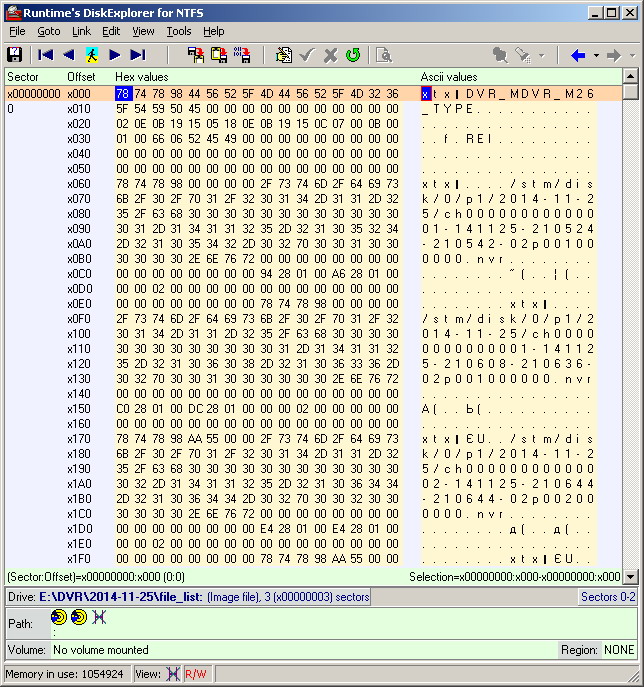
We now turn to the study of the structure of the nvr files themselves. The view of one such file in a binary (more precisely, in hexadecimal) editor is shown in the figure below. Without going into details of the description of the structure of the content (part of which remained a mystery to me), I highlighted the most basic parameters, which are the desired key. These are 32-bit (4-byte) values, located every 32 bytes, starting from byte at offset 40. In the figure, they are highlighted with a red rectangle. In the future, I was convinced that this is quite enough for the key to the videos. I remind you that 4 bytes of the value of this key parameter range from the lowest to the highest, but not vice versa! This notation is due to the PC processor architecture. In the example shown in the figure, the first nvr file of the first directory is shown. It corresponds to the first video recorded by the DVR. It is obvious that the values of the parameters, which I called the key ones, in the given example form a sequence of integers, starting with zero and going in ascending order. Investigating other nvr files, and looking at these particular bytes, they were also seen as integers going in ascending order. But this sequence naturally began no longer from scratch, and in some cases, gaps in one or two numbers were observed in places. For example (numbers from the bald): 435, 436, 438, 439, 442, ... (or in hexadecimal form: B3010000, B4010000, B6010000, B7010000, BA010000, ...).
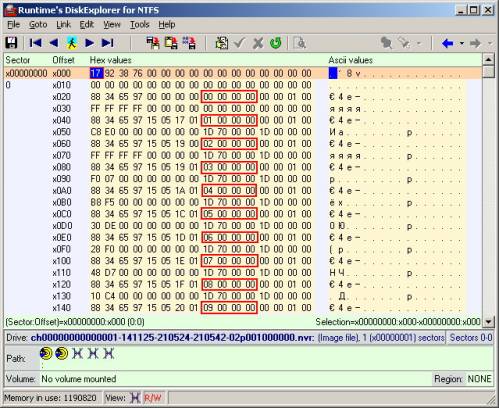
Such a sequence with gaps accounted for nvr files corresponding to the video recordings that the DVR recorded simultaneously from two or more channels. That is, for example, if the sequence “435, 436, 438, 439, 442, ...” refers to video from one channel, then the missing values (437, 440, 441) will refer to video from another channel, which was carried out in the same moment of time. I made sure of this myself by reviewing and comparing the corresponding nvr files, based on their name. There is no doubt that the numbers above form the numbers of some parts related to video recordings. It remains only to unravel the connection between these numbers and the coordinates of the disk space on which the data is located.
Also, it was necessary to find out exactly what data are divided into the above numbered segments? The first assumption is that the data are audio and video streams, which in container 264 are represented by short blocks, and, as was said, the blocks of the video stream are of different sizes. At the same time, the DVR collects these streams at the stage of extracting video to external media and packs them into container 264. The second assumption is that the DVR packs audio and video streams into container 264 at the beginning and at the time of video capture. And while on the HDD, the already generated data of the .264 file is written, which would have been the result of its extraction to external media. Exploring the HDD space somewhere in the middle of the second section, along with the bytes of audio and video streams and their headers of the same kind as in container 264, I also came across the container headers: MDVR96NT_2_R. After this header, many bytes of zeros were also present. In general, the study showed that there is a second variant of the two above. Therefore, to get the required .264 file, most likely, you just need to join together all the segments whose numbers are contained in the corresponding nvr file.
We proceed to the search for dependencies between the number of the segment and the coordinates on the HDD.
The beginning of the data of the container 264 corresponding to the very first video (where the numbering of the segments starts from zero) I found in the sector 16046629 search tools (29824 sectors from the beginning of the section). You can make an assumption about the so-called parameter. the initial bias, which will participate in the formula that describes the desired dependence.
Take two nvr files corresponding to the video from different channels that the DVR captured simultaneously. To do this, take a look at the file names. For example, videos that are pointed to by the files “ch00000000000001-150330-160937-161035-02p101000000.nvr” and “ch00000000000004-150330-160000-163000-00p004000000.nvr” were made simultaneously. The first recording is recording from the 1st channel from 16:09:37 to 16:10:35. The second recording is recording from the 4th channel from 16:00:00 to 16:30:00. Both entries were made on 03/30/2015. On the timeline, obviously, the time interval of the first record is a subset of the time interval of the second record. I also take into account the fact that in a smaller time interval (at the intersection of two intervals) the DVR did not capture video from any of the other 6 channels. View the contents of these nvr files. Make sure that those missing numbers (segment numbers) in the second long file are necessarily present in the first short file, completely and completely. Using the DVR in the usual way, it is required to extract in advance at least one of the .264 files referenced by the nvr files being investigated. Suppose the “ch00000000000001-150330-160937-161035-02p101000000.264” was extracted. Open it in a binary editor. As already mentioned, at the beginning of this file before the keyword “MDVR96NT_2_R” there are unique bytes corresponding to the date and time of the video recorded in the file. We write off all these bytes, starting from a non-zero one and ending with a header (the shorter the chain of bytes, unique for this video, the better). Also, write the offset of this chain of bytes from the beginning of the file. It should be noted that there is an extra 4 bytes of zeros at the beginning of the extracted .264 file. This became noticeable when comparing the first 512 bytes of the .264 file and the sector of disk space from which the data of one of the .264 files begin (the file of almost any file system always starts at the beginning of the sector, moreover, of the cluster). That is, the information in the .264 file is shifted in advance by 4 bytes to the right. The size (in bytes) of any .264 file is a multiple of 512 only after preliminary subtracting the number 4 from the size. We proceed to the search for the sector from which the .264 file being investigated begins. In the disk editor, run the search function. In the field of the desired value we enter a unique string of bytes, written in advance. To speed up the search, enter the offset value in the “search by offset” field, first subtract 4. Start the search. A few hours later the search was completed successfully. Write the number of the sector in which the unique title is found. Let it be the value of s. See the contents of the nvr file for this video. Write off the number of the first segment (4 bytes at offset 40). Let it be the value of b. Total, while we know the sector number of the disk (16046629) for the zero segment number (in the very first video) and the sector number of the found disk s for the segment number just written off b. You can calculate the estimated size of a segment: (s-16046629) / (b-0). Having calculated, I got the value 128. Thus, the segment size is equal to 128 disk sectors (LBA), or 128 * 512 = 65536 bytes!
I conducted another additional interesting experiment to finally dispel all doubts. It is described below.
From the beginning of the sector s, select the area on the disk with a size comparable to the size of the .264 file that starts with this sector. If my guesses are correct, then the segments of another .264 file that was captured on the HDD at the same time as the first one will fall into the selected area. Save this area to a file (create an image). We cut the resulting image into files of 65536 bytes (segment size). This can be done using the "Split File" function in Total Commander. Let it be pieces M1, M2, M3, .... Similarly, we will cut the .264 file under investigation (which was user-extracted from the DVR), but having previously removed 4 bytes of zeros at the beginning. Let it be pieces of K1, K2, K3, .... Using the function “Compare by content” in Total Commander, we can compare pieces of the image and pieces from the .264 file in turn. (M1 with K1, M2 with K2, etc.), guided by the segment numbers from the corresponding nvr file. This results in the following. Suppose (numbers are from noodles), the chain of numbers in nvr is as follows: 435, 436, 438, 439, 442, ... In this scenario, M1 = K1, M2 = K2, M4 = K3, M5 = K4, M8 = K5, .... That is, the pieces into which the image file and the .264 file were broken are equal to each other, taking into account the corresponding advance on the numbers of the image file pieces, according to the omission of numbers in the sequence. So here!
Total, we got the expected dependency: S = 16046629 + 128 * d, where d is the segment number in the nvr file, and S is the sector number on the HDD, starting from the very beginning of the disk, from which the segment content data begins. Segment size - 128 sectors. The above formula does not take into account the existence of the second section. The dependency is found only for a specific example with HDD on 1TB. Perhaps, if you put another capacity in DVR HDD, the constants will take a different look.
To verify the validity of the formula, we calculate the position of the first segment of any other arbitrary .264 file, guided by the corresponding nvr file. Paying attention to the date and time in the file name, compare them with the first bytes in the .264 header located on the calculated sector. The bytes, encoding separately the day, month, year, hour, minute, second, correspond to the time data in the file name. Consequently, "hit the mark"! We calculate the number of cs segments in the nvr file corresponding to the pre-extracted .264 file. In general, their number is cs = sf / 32-1, where sf is the size of the nvr file. If the .264 file consists of cs segments, then its size should be cs * 65536 + 4 (the number of segments multiplied by the size of the segment in bytes, plus 4 of those same bytes of zeros). And indeed it is!
Still, try to explore the second section. As noted earlier, something similar to the superblock is located directly in the first sector of the partition (16016805). And its exact copy was found seven sectors below (16016812). Obviously, a non-zero basic information is in the first sector of the superblock. Its appearance in the disk editor is shown in the figure below.
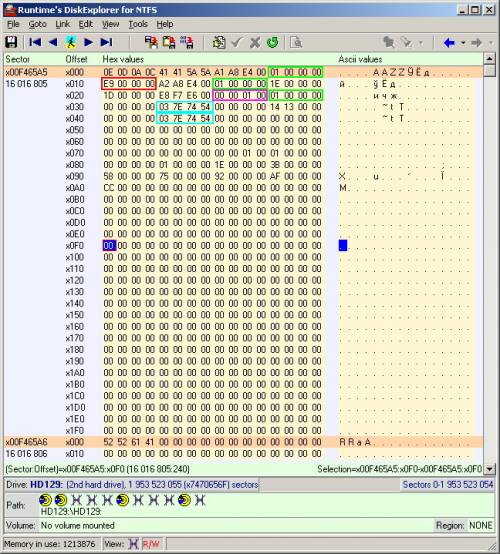
I managed to decipher a part of 4-byte parameters. The date and time of partition mounting are highlighted in blue. The date and time are presented in the special “Unix time” notation (the number of seconds since midnight on January 1, 1970). In the given example, “03 7E 74 54” (decimal value 1416920579) corresponds to “Tue, 25 Nov 2014 13:02:59 GMT”. To translate the values, I used a special online calculator. 65536. , DVR, ( ). 1. .. ( ). , 16016933 (16016805+128*1). 233. .264 : 16016805+128*233=16046629.
, EXT2. , , . . . , . .264 ( ), ( ) nvr . , ? .
.264. , Windows . nvr, 1TB HDD. , .264 , HDD. HDD «DVR», , « » . nvr, . . , , .
, , . , : , , . fopen. HDD WinAPI . .
.
#include <windows.h> #include <stdio.h> #include <string.h> And I completely copied these functions from some forum.
HANDLE openDevice(int device) { HANDLE handle = INVALID_HANDLE_VALUE; if (device <0 || device >99) return INVALID_HANDLE_VALUE; char _devicename[20]; sprintf(_devicename, "\\\\.\\PhysicalDrive%d", device); // Creating a handle to disk drive using CreateFile () function .. handle = CreateFile(_devicename, GENERIC_READ, FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING, 0, NULL); return handle; } HANDLE openOutputFile(const char * filename) { return CreateFile ( filename, // Open Two.txt. GENERIC_WRITE, // Open for writing 0, // Do not share NULL, // No security OPEN_ALWAYS, // Open or create FILE_ATTRIBUTE_NORMAL, // Normal file NULL); // No template file } The copy function contains the formula for linear dependence, which figured in theory above.
void copy(HANDLE device, HANDLE file, unsigned long int s){ LONG HPos; LONG LPos; __int64 sector; sector = 16046629+128*s; HPos = (sector*512)>>32; LPos = (sector*512); SetFilePointer (device, LPos, &HPos, FILE_BEGIN); DWORD dwBytesRead; DWORD dwBytesWritten; unsigned char buf[65536]; ReadFile(device, buf, 65536, &dwBytesRead, NULL); WriteFile(file, buf, dwBytesRead, &dwBytesWritten, NULL); } The main function is also quite simple.
int main(){ HANDLE hdd = openDevice(1); // HDD DVR, ; SetFilePointer (hdd, 0, NULL, FILE_BEGIN); DWORD dwBytesRead; char name[100]; unsigned int bl; // ; unsigned int N; // ; unsigned long int pt; // ; WIN32_FIND_DATA fld,fld1; // nvr ; HANDLE hf,hf1; hf=FindFirstFile("E:\\DVR\\*",&fld); FindNextFile(hf,&fld);// "."; FindNextFile(hf,&fld);// ".."; do{ char *str = new char; sprintf(str,"%s%s%s","E:\\DVR\\",fld.cFileName,"\\*.nvr"); printf("\n\nFOLDER: %s\n\n",str); hf1=FindFirstFile(str,&fld1); do{ FILE *nvr; sprintf(name,"%s%s%s%s","E:\\DVR\\",fld.cFileName,"\\",fld1.cFileName); nvr=fopen(name,"rb"); name[strlen(name)-3]='2'; // , name[strlen(name)-2]='6'; // ; name[strlen(name)-1]='4'; HANDLE out = openOutputFile(name); SetFilePointer(out, 4, NULL, FILE_BEGIN); // "", 4 ( ); bl=0; N=fld1.nFileSizeLow/32-1; // (); printf("\t%s\n\t%i Blocks\n\n",fld1.cFileName,N); for(bl=0;bl<N;bl++){ // ; fseek(nvr,40+32*bl,SEEK_SET); //; fread(&pt,1,4,nvr); // ; copy(hdd,out,pt); // ; } CloseHandle(out); fclose(nvr); }while(FindNextFile(hf1,&fld1)); FindClose(hf1); delete str; }while(FindNextFile(hf,&fld)); FindClose(hf); CloseHandle(hdd); system("PAUSE"); return 0; } On an old computer with a Pentium 4 processor and a PCI SATA controller, the program successfully completed the full HDD with several thousand .264 files on average over 7 hours. On a new computer - three times faster. As I have already noted, the program is not universal, all constants and variables are adjusted to my specific case from HDD to 1TB. However, you can work a little more and make it universal, draw a graphical interface to it.
In the second part of the article I will write how to do it yourself using the “hands” to repack from the “264” container into the standard “avi” container.
Source: https://habr.com/ru/post/421933/
All Articles