Analysis of service requests using machine learning
As part of product support, we constantly serve appeals from users. This is a standard process. And like any process, it needs to be critically evaluated and improved regularly.
We are aware of some systematically problems that are well-solved and, if possible, without attracting additional resources:
- Errors in dispatching requests: we get something "alien", other teams sometimes get something "our".
- It is difficult to assess the "complexity" of the application. If the application is difficult - it can be transferred to a strong analyst, and a simple one - and the beginner will cope.
The solution of any of these problems will positively affect the speed of processing applications.
The application of machine learning, in application to the analysis of the content of the application, looks like a real opportunity to improve the process of dispatching.
In our case, the task can be formulated with the following classification tasks:
- Ensure that the request is correctly related to:
- configuration unit (one of 5 within the application or "others")
- service categories (incident, request for information, service request)
- Estimate the expected time to close the request (as a high-level indicator of "complexity").
What and how we will work
To create an algorithm, we will use the "standard set": Python with the scikit-learn library.
For real use 2 scenarios will be implemented:
Training:
- getting "training" data from the tracker applications
- running the algorithm for training the model, saving the model
Using:
- receiving data from the application tracker for classification
- model loading, classification of applications, saving results
- updating requests in the tracker based on the classification carried out
All that relates to the pipeline (interaction with the tracker) can be implemented on anything. In this case, powershell scripts were written, although it was possible to continue in python.
The machine learning algorithm will receive data for classification / training in the form of a .csv file. The processed results will also be output to a .csv file.
Input data
In order for the algorithm to turn out to be as independent as possible from the opinion of service teams, we will take into account only the data received from the creator of the application as input parameters of the model:
- Short description / title (text)
- Detailed description of the problem, if any (text). This is the first message in the request flow.
- Name of the customer (employee, category)
- The names of other employees included in the list of notifications (watch list), on request (list of employees)
- Application time (date / time).
Training dataset
For learning algorithms, data on closed calls for the last 3 years were used - ~ 3,500 records.
Additionally, for training the classifier to recognize "other" configuration units, closed applications were added to the training set, processed by other departments for other configuration units. Total additional entries - about 17,000.
For all such additional requests, the configuration unit will be set as “other”
Pretreatment
Text
Text preprocessing is extremely simple:
- We translate all in lower case
- We leave only numbers and letters - the rest is replaced by spaces.
List of notifications (list)
The list is available for analysis in the form of a string in which the names are presented in the form of Last Name, First Name, and are separated by a semicolon. For analysis, we will convert it to a list of strings.
Combining the lists we get a set of unique names based on all applications of the training set. This common list will form a vector of names.
Application processing time
For our purposes (priority management, release planning), it is sufficient to classify the application to a specific class for the duration of the service. It also allows you to transfer a task from regression to a classification with a small number of classes.
Form the signs
Text
- We combine the "title" and "description of the problem."
- Pass to TfidfVectoriser to form a vector of words
Name of the order writer
Since it is expected that the person who created the application will be an important attribute of further classification - we will translate it into one-of encoding individually using the DictionaryVectorisor
Names of people included in the notification list
The list of people included in the order of the application will be converted into a vector in the basis of all the names prepared earlier: if the person was on the list - the corresponding component will be set to 1, otherwise - to 0. One application may have several people on the watch - respectively, several components will have a single value.
date of creation
Creation date will be presented in the form of a set of numeric attributes - year, month, day of the month, day of the week.
This is done on the assumption that:
- The processing speed of requests changes over time.
- Processing speed is seasonal.
- Day of the week (especially requests on weekends) can help in identifying the configuration unit and service category
We teach the model
Classification algorithm
For all three classification tasks, logistic regression was used. It supports multi-class classification (in the One-vs-All model), and learns pretty quickly.
For the training of models that determine the category of service and the duration of processing applications, we will use only applications that are known to belong to our configuration units.
Learning outcomes
Definition of configuration units
The model demonstrates high indicators of completeness and accuracy when assigning requests to configuration units. Also, the model well defines events when requests refer to foreign configuration units.
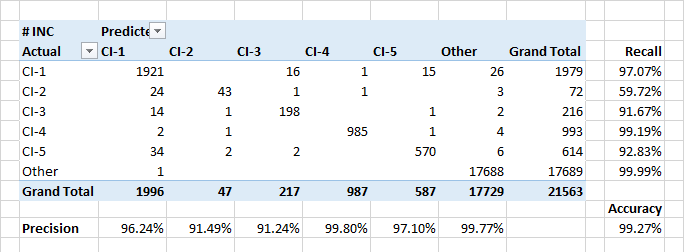
The relatively low completeness for class CI-2 is partly due to real classification errors in the data. In addition, CI-2 submit "technical" applications performed for other CIs. So, from the point of view of the description and the users involved, such applications may be similar to applications from other classes.
The most important attributes for the assignment of applications to classes CI-? expectedly were the names of customers of applications and people included in the alert list. But there were some keywords that were in the first 30 ke in importance. Date of creation of the application does not matter.
Definition of application category
The quality of classification by category is somewhat lower.
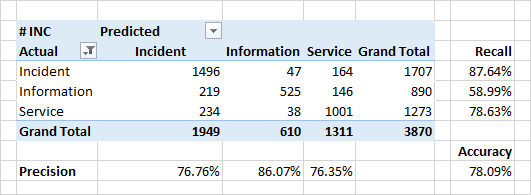
A very serious reason for the discrepancy between the predicted categories and categories in the source data is real errors in the source data. Due to a number of organizational reasons, the classification may be incorrect. For example, instead of an "incident" (a defect in the system, an unexpected system behavior), the application may be marked as "information" ("this is not a bug - this is a feature") or "service" ("yes, it broke, but we just restart it - and everything will be OK").
It is the identification of such inconsistencies and is one of the tasks of the classifier.
Significant attributes for classification in the case of categories of steel words from the content of applications. For incidents, these are the words "error", "fix", "when". Also, there are words denoting some modules of the system - these are the modules with which users work directly and observe the appearance of direct or indirect errors.
Interestingly, for applications defined as "service" - the top words also define some modules of the system. Reason to think, check, and finally fix them.
Determination of the application processing time
Least of all, it was possible to predict the processing time of applications.
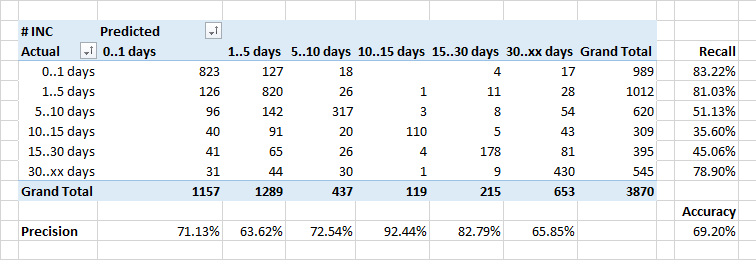
In general, the dependence of the number of applications that are closed for a certain time ideally should look like the inverse of the exponent. But given the fact that some incidents require corrections in the system, and this is done in the framework of regular releases, the duration of the execution of some requests is artificially increased.
Therefore, perhaps, the classifier refers some “long” applications to the class “faster” - he does not know about the timing of the planned releases, and believes that the application should be closed faster.
This is also a good reason to think ...
Implementing a model as a class
The model is implemented as a class that encapsulates all used standard scikit-learn classes — scaling, vectoring, classifier, and meaningful settings.
The preparation, training and subsequent use of the model are implemented as class methods based on auxiliary objects.
The object implementation allows you to conveniently generate derived versions of the model that use other classes of classifiers and / or predict the values of other attributes of the original data set. All this is done by overriding virtual methods.
In this case, all data preparation procedures may remain common to all options.
In addition, the implementation of the model in the form of an object allowed us to naturally solve the problem of intermediate storage of the trained model between use sessions - through serialization / deserialization.
To serialize the model, the standard Python mechanism was used - pickle / unpickle.
Since it allows you to serialize several objects into the same file, it will help to consistently save and restore several models included in the general processing flow.
Conclusion
The obtained models, even being relatively simple, give very interesting results:
- identified systematic "blunders" in the classification by category
- it became clear what parts of the system are associated with problems (apparently - not without a reason)
- Application processing times are clearly dependent on external factors that need to be improved separately.
We have yet to rebuild the internal processes based on the received "prompts". But even this small experiment allowed us to evaluate the power of machine learning methods. It also prompted the team’s additional interest in analyzing their own process and improving it.
')
Source: https://habr.com/ru/post/421711/
All Articles