How to identify risks in state control and why machine learning for this

In the previous article on public risk management, we walked through the basics: why should government agencies manage risks, where to look for them, and what approaches to assessment exist. Today we will talk about the risk analysis process: how to identify the causes of their occurrence and to detect violators.
Risk assessment
To assess the risk - even within a static, even a dynamic approach - you need to find its causes, conditions of occurrence, and determine the main characteristics: probability and potential damage from implementation.
Take, for example, customs clearance: when importing any goods into the country, in addition to a variety of different information (cost, weight, packaging, sender, recipient, etc.), the declaration must state the code according to a special classifier - the foreign trade activity nomenclature (TN VED). According to this code, the duty is then determined for the goods according to the customs tariff (TN VED + rates).
')
The customs tariff is a complex classifier: some goods, at first glance, can be attributed to different codes with different duty rates. For example, you can deal with complex mining equipment only by delving into its drawings. Hence the importer is tempted to declare the wrong (but similar to the truth) code in order to pay less money to the budget.
So we identified the risk - the statement of an unreliable product code in the declaration in order to lower the customs payments. The reason is the presence in the classifier of “borderline” positions with different rates of duty.
It is more difficult to detect the conditions for the occurrence of such a risk — when and with which commodities this occurs in practice. To do this, you need to conduct a risk analysis : examine the history of observations on objects of control, find out when and who claimed the wrong product code, and highlight some common characteristics of these cases. This will allow us to formulate rules for the treatment of risk in the future: which objects will we consider to be risk and what kind of testing to expose.
The easiest way to get such rules is to trust the expert judgment of your employees.
Expert Rules
Such rules for identifying risks are subject matter experts. They are guided by their work experience or summarize the opinions of colleagues who encounter violators every day. The result is simple judgments of the form “if ... then ...”.
The probability of occurrence of risk and potential damage from the threat in this case is determined “by eye” or approximate calculations.
The advantage of expert rules is the ease of their compilation and interpretation by man. The disadvantage is that a large number of persons can fall under the rule at the same time - both violators and respectable subjects of economic activity. Therefore, the effectiveness of the control will be low. At the same time, a part of violators will pass by, for which the expert could not detect and take into account the patterns.
For example, the expert rule for customs control tells us that all batches of apples with a value below a certain threshold are referred to risky supplies:

When we conduct the inspection, we will find both goods with violations (red) and quite normal supplies (green), the low cost of which is explained by individual discounts, the sender’s struggle with the oversupply or the economic model of enterprises.
Anything higher than this conditional cost threshold (red line) will be out of control (gray circles). But if we check them too, we will find both truly legal supplies and supplies, the real cost of which is even higher than what was stated in the declaration (gray circles with a red dotted outline) and for which customs payments were not paid in full.
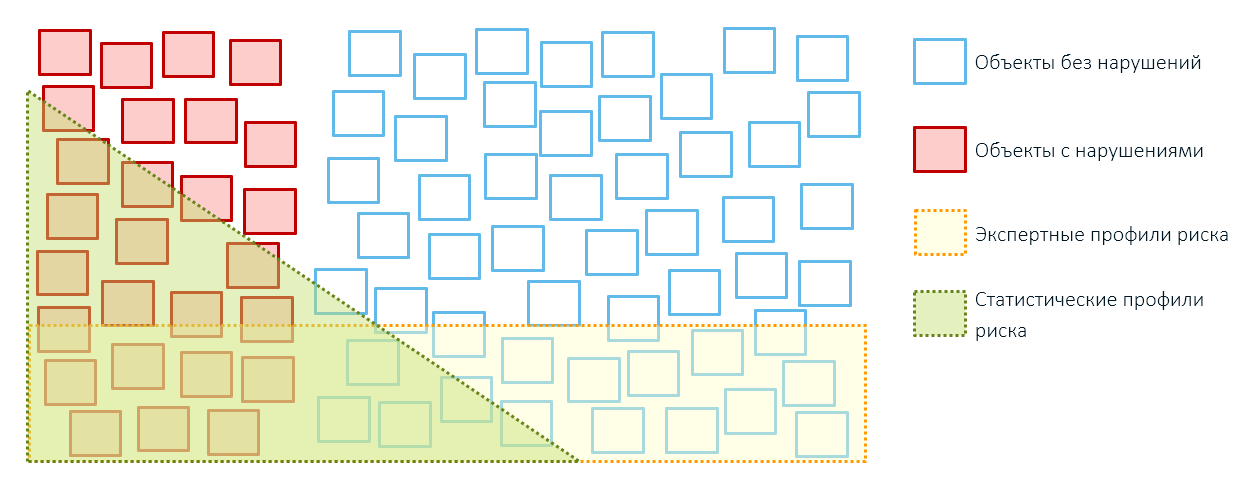
Therefore, the application of expert rules usually leads to excessive coverage of objects of control and small results (remember, our squares from the first article?):
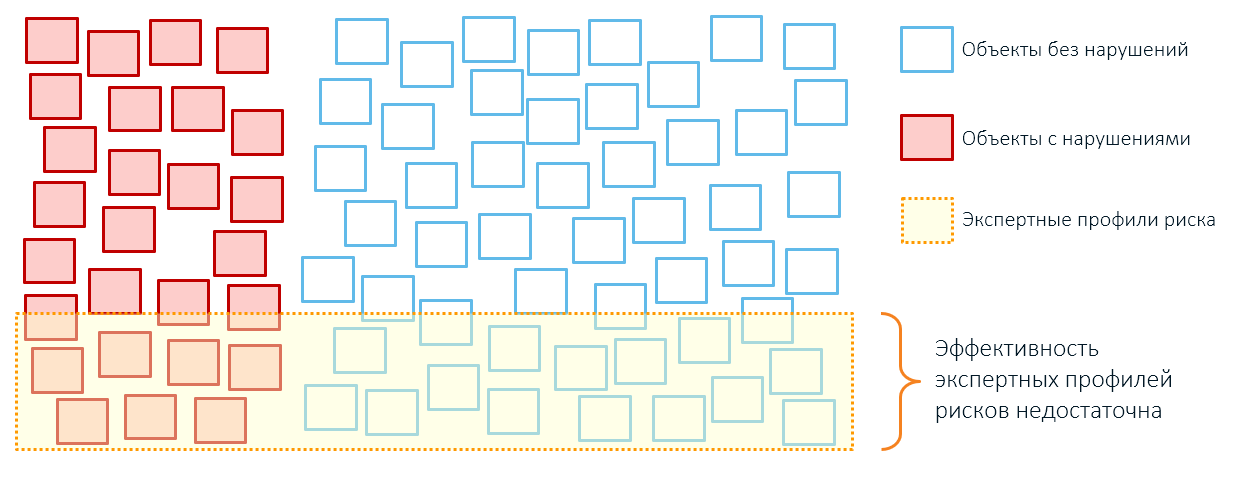
You shouldn't blame the experts: the human consciousness is limited in the objects with which it can operate (a curious article was once published on Habré, the author of which suggested that their number is limited to a family). Hence, large strokes instead of exact details: let's say, the risk of fire is determined only by the year the building was built, the location and the category of residents. All these characteristics once “played”: a fire broke out in the old house, a room caught fire in a disadvantaged area. Therefore, experts expect threats in the future precisely from objects of this type.
But not all of these “dangerous” buildings are actually going to burn, even if they fall under the expert rule: many old and wooden houses are standing, as if nothing had happened. Some dysfunctional homes for years are without a single fire. Simply, the expert could not take into account some subtle individual characteristics of dangerous objects.
This is where machine learning enters the scene, which helps create statistical risk profiles . They are formed when we apply data analysis technologies to the history of violations and information about controlled objects.
Statistical risk profiles
In this case, we solve the problem of binary classification: a specialized analytical algorithm itself determines which characteristics of objects allow us to refer them to “bad” or “good.” If everything is done correctly, we will get fairly accurate risk assessments at the output: detailed conditions and automatically calculated probabilities plus potential damage (which are also somehow “expert” determined by the expert approach). These characteristics define a “risk profile” - what, where, when and how scary.
Statistical risk profiles are created differently. It can be based on a decision tree or a random forest. You can use a clever neural network with a large number of hidden layers.
But we at SAS believe that, for the purposes of state control, it is better to create statistical risk profiles based on interpreted algorithms, for example, regression or a decision tree . Practice has shown that it is difficult for the state body to focus even on an accurate, but incomprehensible car forecast, if it does not explain why this respected person is marked as a scoundrel.
The state body needs to understand which factors indicate the threat and which of the violators were found to have the same characteristics, since there are procedures for approving management decisions (of which risk profiles are a special case). The official must understand what exactly he is launching “into battle”, since he is responsible for the result of the action of the risk profile.
Any verification should be justified and this justification should be expressed in words. Otherwise, then you will have to blush in front of the prosecutor and explain how it turned out that the state agency “squeezes” the domestic business on the basis of the mysterious instructions of deus ex machina.
Therefore, the statistical risk profile also looks like a rule that can be read and understood. Only a list of characteristics that describe potential offenders is larger and more complicated than that of expert profiles:

* values of profile parameters are changed and do not correspond to real ones
The set of risk indicators (conditions) may seem a little fancy. But this is not a “great witchcraft” - just with the help of machine learning technologies and the limited information that we have, we describe a hidden pattern of human behavior that leads to a violation.
The same in the tax control - violators can distinguish from the total mass of taxpayers certain ranges of sums of some operations, deadlines for filing declarations, the number of employees in the company, the number of accounts and another set of 30 different parameters that describe unfair entrepreneurs who underestimate VAT.
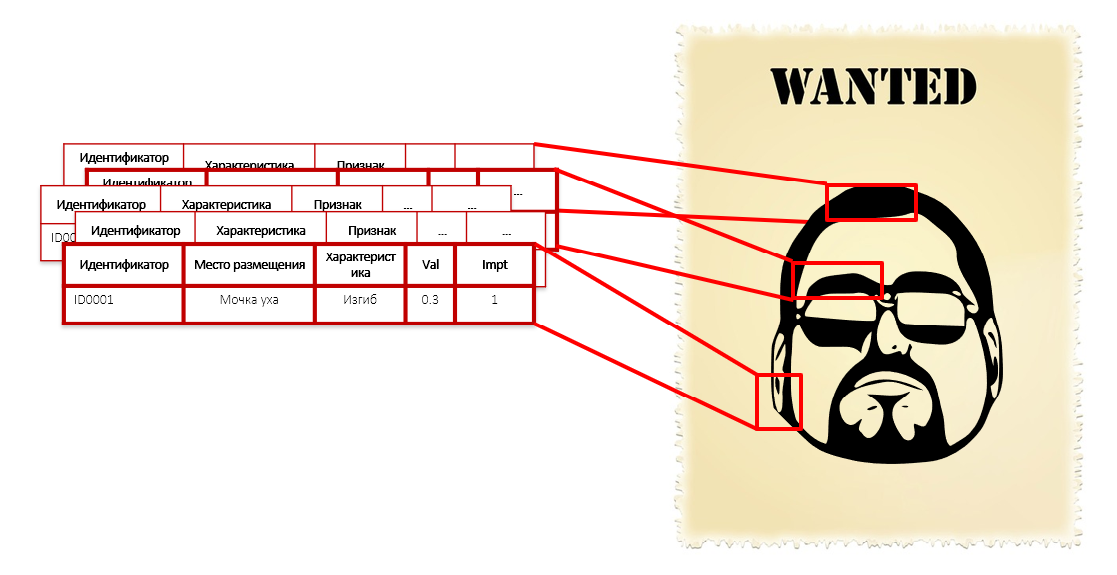
A person will not be able to compare all these characteristics, it will cost three or five, which are easier to understand. And the program can. As detailed as needed. When building a model, the algorithm automatically iterates through the mass of data and finds that the offenders have in common - even if it is a love for red ties in a yellow mesh.
This is similar to the description of the offender in its individual features: the shape of the nose, ears, eyebrow curvature, colors of shirts and the length of the foot. We do not know his face, height and weight, but we have a thousand of his characteristics, including the length of hairs on the phalanx of the left little finger. Each of these parameters separately does not give criminal intent - no need to handcuff a person only for the radius of curvature of his ears. But the whole set of these characteristics together form a fairly accurate portrait of the offender:
When we move from the application of expert rules to statistical profiling based on the analysis of hidden patterns, we get rid of deliberately ineffective checks. The huge field of continuous control is narrowed to a point effect on objects that fall under the pattern of unfair behavior that has been identified.
Recall the apples from the customs example above. By submitting the history of the conducted checks to the input of the statistical model, we get a risk profile that takes into account the behavioral characteristics of importers-offenders, regardless of at what price they declare the goods:
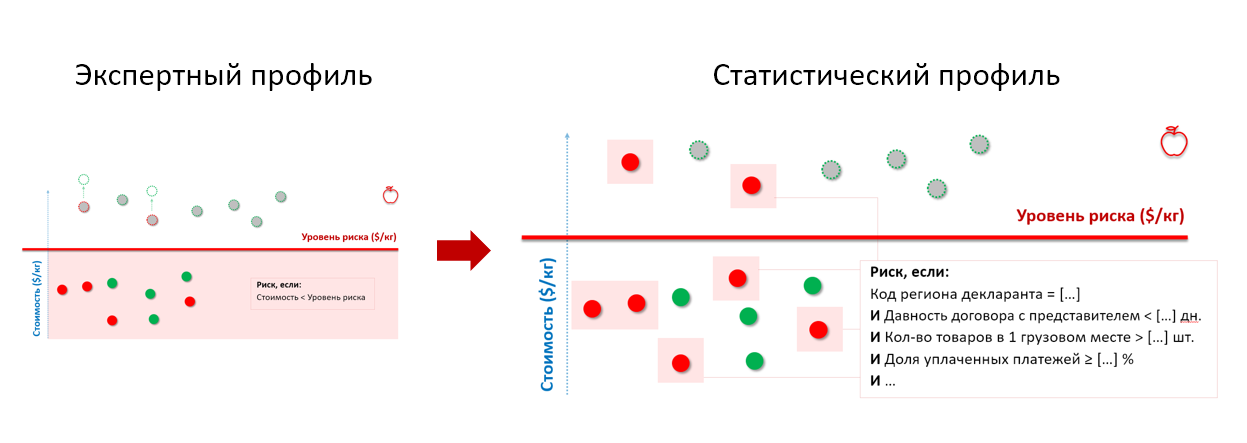
* the set of risk profile parameters is changed and does not correspond to the real
This is how a statistical risk profile is built using algorithms of the “decision tree” class - each level more and more divides the set of inspected subjects into “good” and “bad” and shows which characteristic for separation turned out to be the most significant (in the screenshot of SAS Visual Statistics):
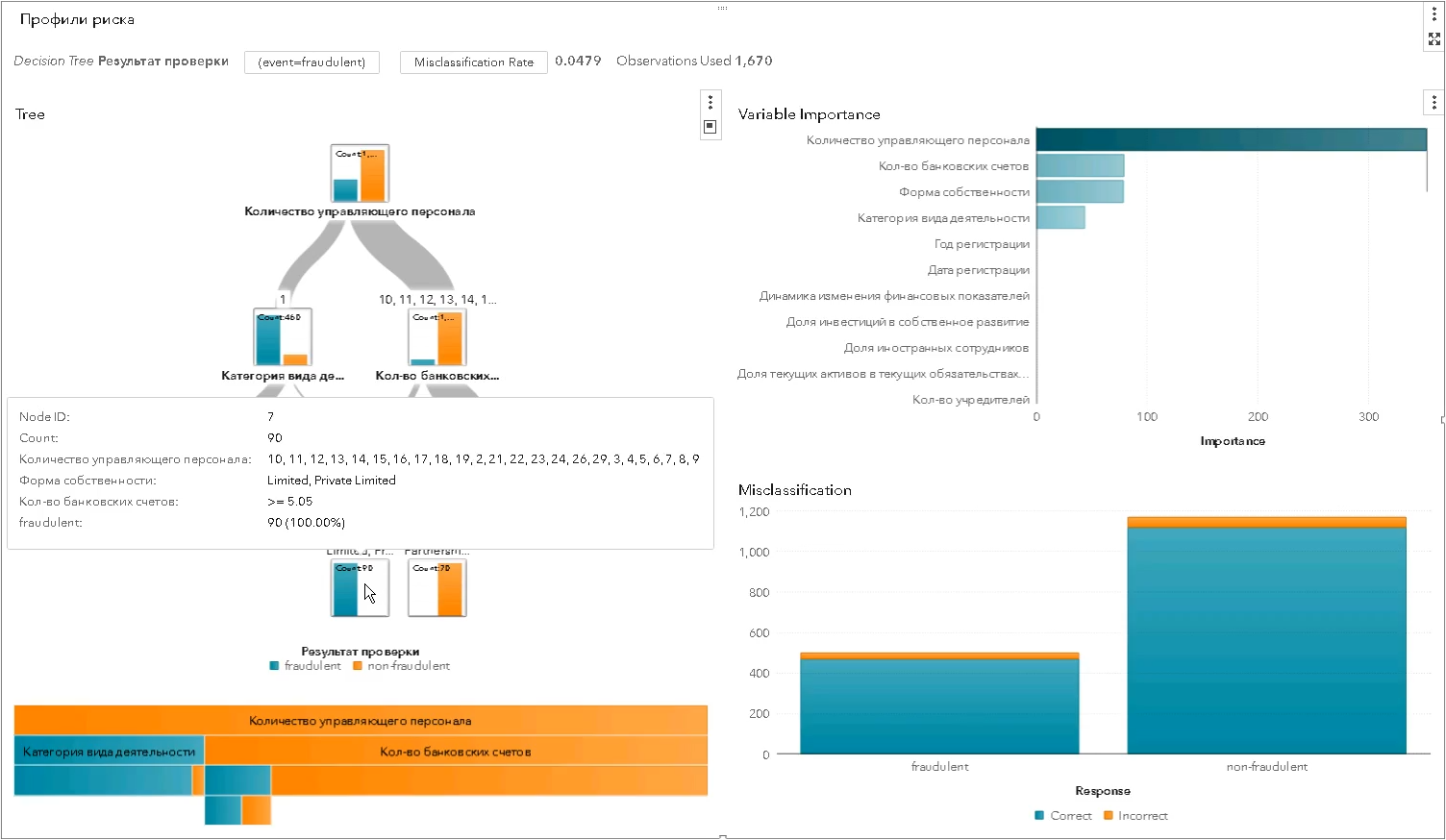
Statistical profiles are better than expert ones — more precisely, more selectively, more impartially. They help improve the effectiveness of inspections by reducing the number of idle “drawouts”:
The lack of statistical profiles is that they are guided by past experience in identifying violations. On known schemes.
If in the history of customs control there were revealed cases of underestimation of value when importing goods, the algorithm will find signs of violators and form a statistical risk profile. If we are looking for some kind of new violation that the state body has not yet come across, and we do not know its characteristics, then we have to act “by touch” - by trial and error.
Search unknown
Feel the unknown in several ways.
The first is a random sample . We take an arbitrary object (within its authority) - a product, enterprise, building or citizen - and carefully consider it. The approach is fairly impartial, but not very effective - a respectable subject can equally well get under the “debriefing”. The forces of the state body and budget money will be spent in vain.
The second is the detection of anomalies . In this case, to check take the object, the parameters of which stand out from the rest. When we analyze anomalous events, and not just randomly “poke” into a bunch of objects, the probability of finding a violation is higher.
For example, when conducting environmental monitoring it turns out that the plant consumes unexpectedly a lot of electricity:
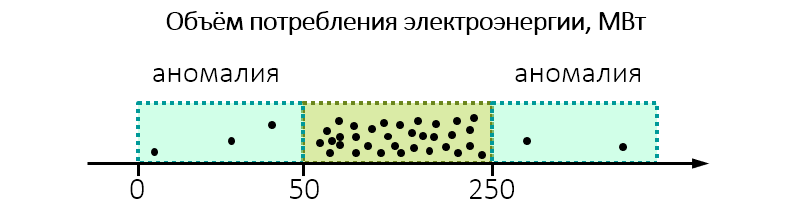
Perhaps you should look at him and check whether the plant does not dump into the water or the air is more than permissible.
Or goods at customs have an unusual ratio of weight of goods and packaging:
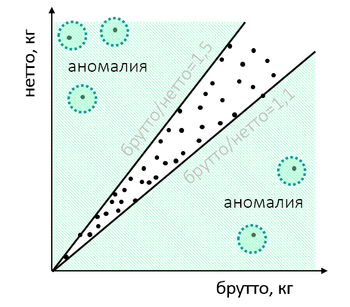
After the check, it may turn out that the importer “played” with the weight to cover up any violations: he underestimated the cost and thus wanted to tighten one of the verification values or issues some goods under the guise of others. “Natural” weight characteristics, if well digged, are different from the invented ones.
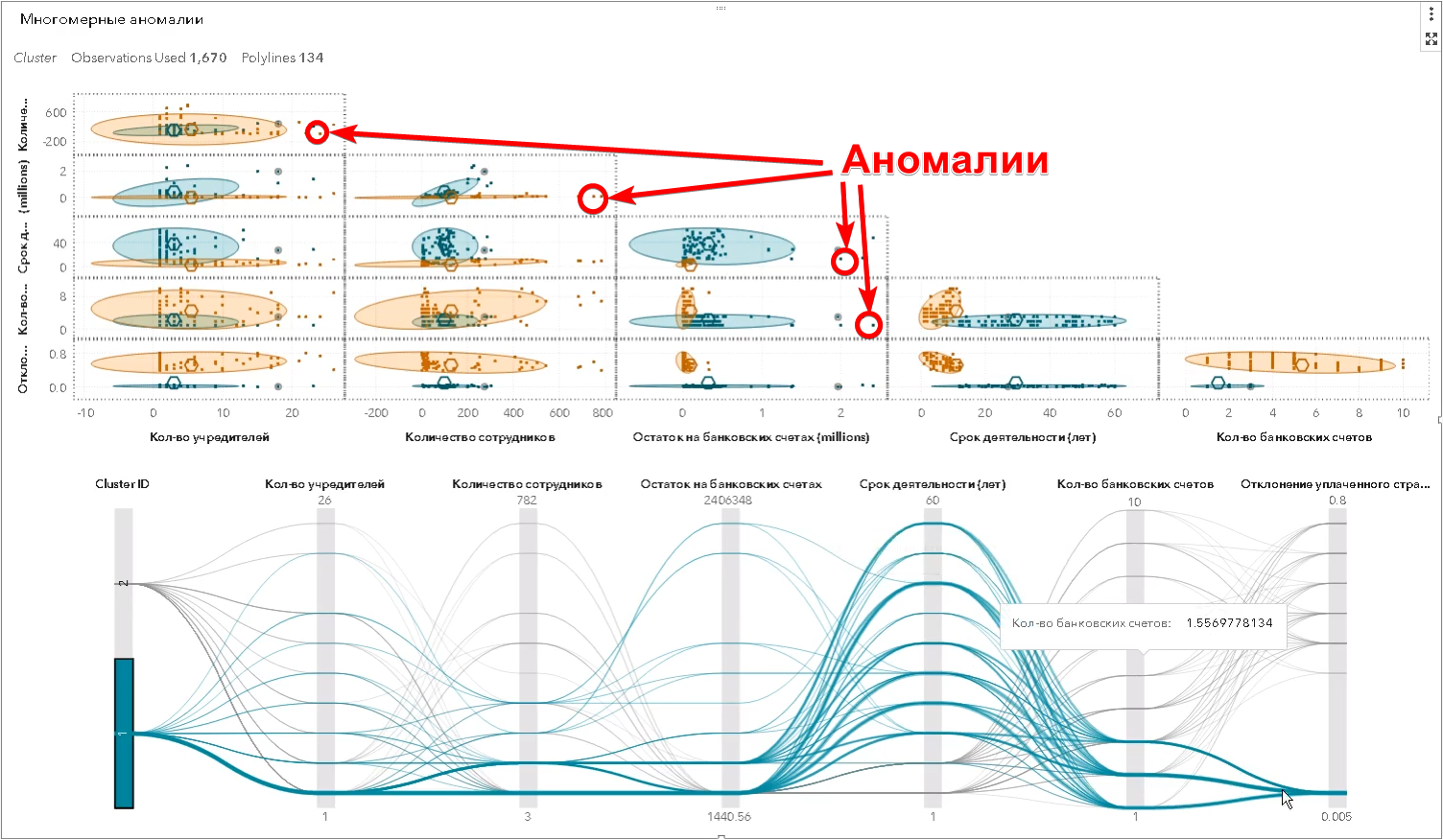
However, these are the simplest examples that a person is able to see. In reality, the search for anomalies occurs in the multidimensional space of attributes - there may be hundreds of them. The algorithm does what a person cannot do — finds objects that are significantly different from the rest of the same at the same time for a large number of features, and defines so-called multidimensional spikes (in the screenshot of SAS Visual Statistics):
Also outside of human perception is the diversity of legal relations between various companies, which are visualized using a graph (in the screenshot of SAS Social Network Analysis):
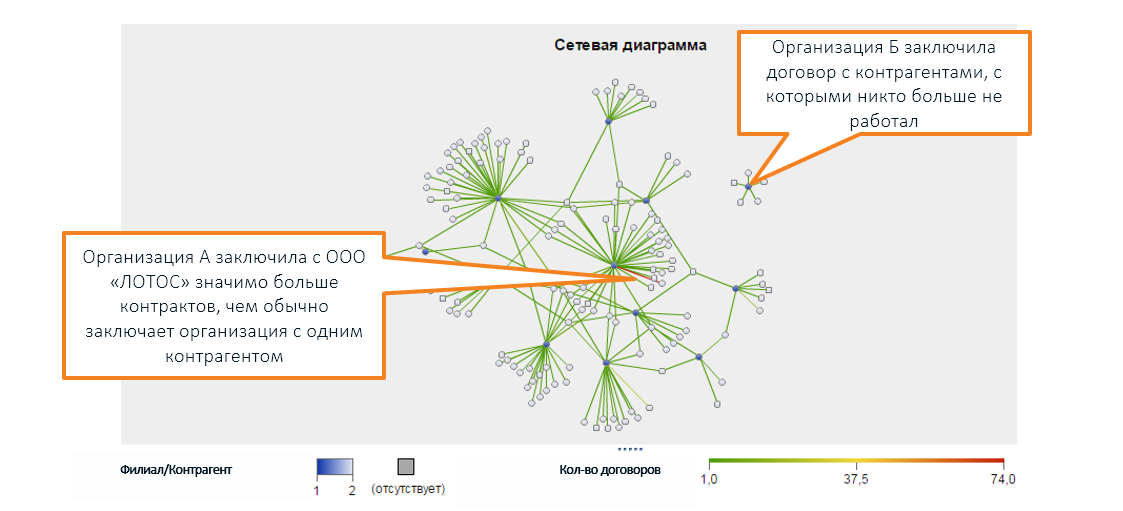
* the names of organizations are invented, coincidences with real companies are random
Unusual characteristics do not necessarily talk about the problem. The check may not show anything: yes, the indicators are strange, but there is no violation.
Anomaly is not a risk, it is just “something unusual.” Profiles of anomalies are needed to provide new “raw materials” for building expert or statistical profiles, since the result of checking the anomalies is included in the history of observations of objects of control.
Hybrid approach
The best results in the control and supervisory activities of state bodies (and not only in them) can be achieved by combining all three ways to identify risks: expert rules, statistical risk profiles based on machine learning technologies and anomalies profiles. At the same time, it is better to reduce the coverage of objects with expert rules, leaving them only for targeted administrative actions (for example, imposed sanctions - blocking goods from these countries):
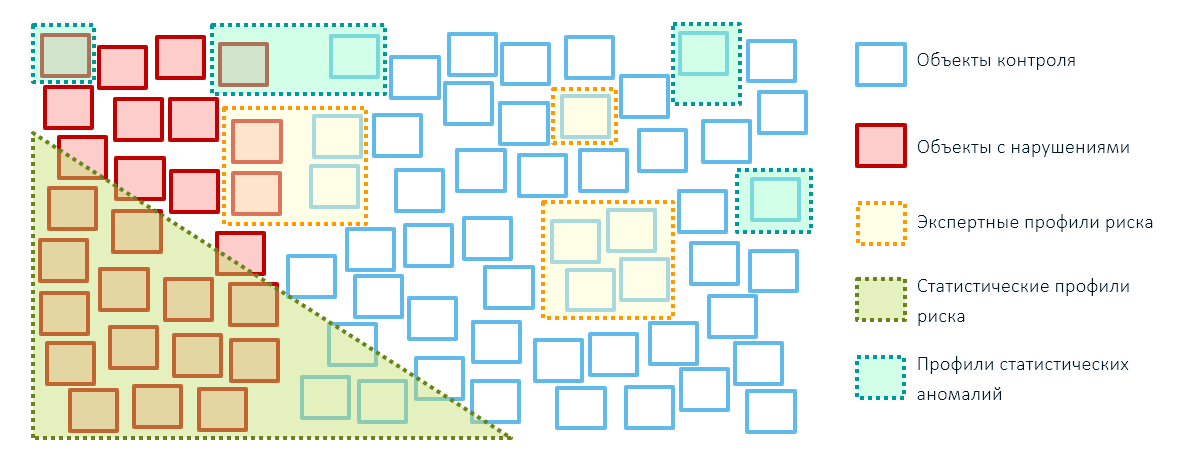
Without expert rules, it is impossible to do at the initial stage of building a risk management system, since a base of precedents is needed to create analytical models. In order to create it, it will be necessary to conduct checks based on expert risk profiles and only then proceed to mathematical models.
We at SAS believe that the future of state control and supervisory activities is based on a hybrid approach that combines the experience of government agencies and the expertise of its employees with modern machine learning technologies. In this case, we reduce the work results of all three modules into one integral risk assessment:
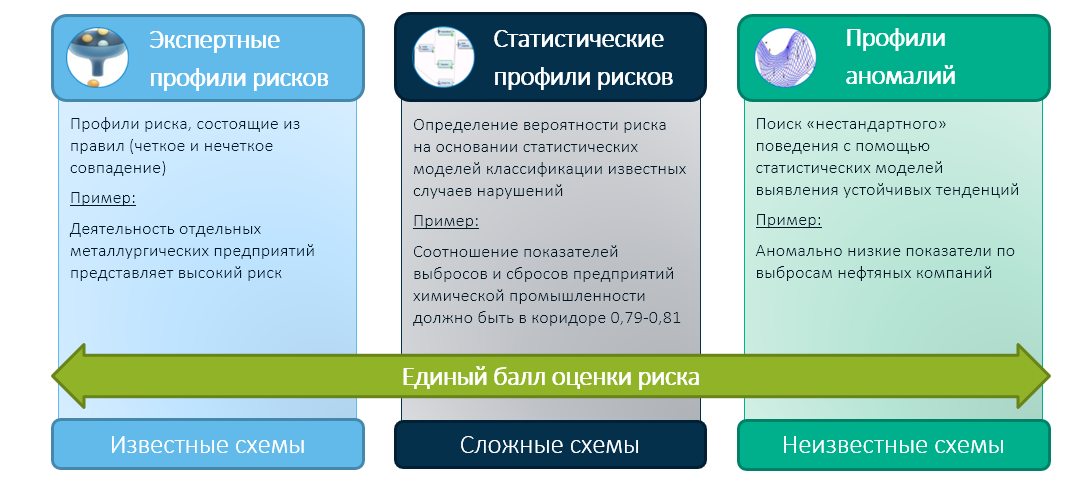
And already the integral assessment (for example, on the basis of the expert matrix of decisions) determines the choice of the control body - who to check and who to trust.
In the next article, we will analyze the methods for minimizing the identified threats and consider why feedback and dynamic reassessment of risks are so important.
Source: https://habr.com/ru/post/421677/
All Articles