The book "Apache Kafka. Stream processing and data analysis "
 When any enterprise application is running, data is generated: these are log files, metrics, information about user activity, outgoing messages, etc. Proper manipulation of all this data is just as important as the data itself. If you are an architect, developer or issuing engineer who wants to solve such problems, but are not familiar with Apache Kafka, then it is from this wonderful book that you will learn how to work with this free streaming platform that allows you to process data queues in real time.
When any enterprise application is running, data is generated: these are log files, metrics, information about user activity, outgoing messages, etc. Proper manipulation of all this data is just as important as the data itself. If you are an architect, developer or issuing engineer who wants to solve such problems, but are not familiar with Apache Kafka, then it is from this wonderful book that you will learn how to work with this free streaming platform that allows you to process data queues in real time.Who is this book for?
“Apache Kafka. Stream processing and analysis of data was written for developers who use Kafka APIs in their work, as well as process engineers (also called SRE, DevOps or system administrators) involved in installing, configuring, configuring and monitoring its work in commercial operation. We also did not forget about data architects and analysis engineers - those responsible for designing and building the entire data infrastructure of a company. Some chapters, in particular, 3, 4 and 11, are focused on Java developers. To assimilate them, it is important that the reader is familiar with the basics of the Java programming language, including issues such as exception handling and concurrency.
In other chapters, especially 2, 8, 9, and 10, it is assumed that the reader has experience with Linux and is familiar with configuring the network and data storage on Linux. In the remainder of the book, Kafka and software architecture are discussed in more general terms, so some special knowledge from readers is not required.
Another category of people who may be interested in this book is managers and architects who work not directly with Kafka, but with those who work with it. It is no less important for them to understand what the guarantees provided by the platform and what the compromises may be, which will have to go to their subordinates and colleagues when creating systems based on Kafka. This book will be useful to those managers who would like to train their employees to work with Kafka or to make sure that the development team has the necessary information.
')
Chapter 2. Installing Kafka
Apache Kafka is a Java application that can run on a variety of operating systems, including Windows, MacOS, Linux, etc. In this chapter, we will focus on installing Kafka on Linux, since it is on this operating system that the platform is installed most often. Linux is also the recommended operating system to deploy Kafka for general use. Information on installing Kafka on Windows and MacOS can be found in Appendix A.
Install Java
Before installing ZooKeeper or Kafka, you need to install and configure a Java environment. It is recommended to use Java 8, and this may be the version included in your operating system or directly downloaded from java.com. Although ZooKeeper and Kafka will work with the Java Runtime Edition, it is more convenient to use the full Java Development Kit (JDK) when developing utilities and applications. The above installation steps assume that you have installed JDK version 8.0.51 in the /usr/java/jdk1.8.0_51 directory.
Install ZooKeeper
Apache Kafka uses ZooKeeper to store metadata about the Kafka cluster, as well as details about customer-consumers (Fig. 2.1). Although you can also run ZooKeeper using the scripts included in the Kafka distribution, installation of the full version of the ZooKeeper repository from the distribution is very simple.

Kafka has been thoroughly tested with the stable version 3.4.6 of the ZooKeeper repository, which can be downloaded from apache.org.
Standalone server
The following example demonstrates the installation of ZooKeeper with the basic settings in the / usr / local / zookeeper directory with data stored in the / var / lib / zookeeper directory:
# tar -zxf zookeeper-3.4.6.tar.gz # mv zookeeper-3.4.6 /usr/local/zookeeper # mkdir -p /var/lib/zookeeper # cat > /usr/local/zookeeper/conf/zoo.cfg << EOF > tickTime=2000 > dataDir=/var/lib/zookeeper > clientPort=2181 > EOF # /usr/local/zookeeper/bin/zkServer.sh start JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED # export JAVA_HOME=/usr/java/jdk1.8.0_51 # /usr/local/zookeeper/bin/zkServer.sh start JMX enabled by default Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED # Now you can check that ZooKeeper, as it should be, works offline by connecting to the client port and sending the four-letter srvr command:
# telnet localhost 2181 Trying ::1... Connected to localhost. Escape character is '^]'. srvr Zookeeper version: 3.4.6-1569965, built on 02/20/2014 09:09 GMT Latency min/avg/max: 0/0/0 Received: 1 Sent: 0 Connections: 1 Outstanding: 0 Zxid: 0x0 Mode: standalone Node count: 4 Connection closed by foreign host. # ZooKeeper Ensemble
The ZooKeeper cluster is called an ensemble. Due to the nature of the algorithm itself, it is recommended that an ensemble include an odd number of servers, for example, 3, 5, etc., since in order for ZooKeeper to respond to requests, most of the members of the ensemble (quorum) must function. This means that an ensemble of three nodes can work with one idle node. If there are three knots in the ensemble, there may be two.
To set up ZooKeeper servers in an ensemble, they must have a single configuration with a list of all servers, and each server in the data directory must have a myid file with the identifier of this server. If the hosts in the ensemble are named zoo1.example.com, zoo2.example.com, and zoo3.example.com, then the configuration file might look something like this:
tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 initLimit=20 syncLimit=5 server.1=zoo1.example.com:2888:3888 server.2=zoo2.example.com:2888:3888 server.3=zoo3.example.com:2888:3888 In this configuration, initLimit is a period of time during which slave nodes can connect to the master. The value of syncLimit limits the lag of the slave nodes from the master. Both values are given in tickTime units, that is, initLimit = 20 · 2000 ms = 40 s. The configuration also lists all servers in the ensemble. They are in server.X = hostname: peerPort: leaderPort with the following parameters:
- X - server identifier. Must be an integer, but the count may not be from zero and not be consistent;
- hostname is the host name or IP address of the server;
- peerPort - TCP port through which the servers of the ensemble interact with each other;
- leaderPort - TCP port through which the selection of the host node.
It is enough that clients can connect to the ensemble via the clientPort port, but the ensemble members should be able to exchange messages with each other on all three ports.
In addition to a single configuration file, each server in the dataDir directory must have a myid file. It should contain the server identifier corresponding to the one given in the configuration file. After completing these steps, you can start the servers, and they will interact with each other in an ensemble.
Installation broker Kafka
After completing the configuration of Java and ZooKeeper, you can install Apache Kafka. The current release of Apache Kafka can be downloaded at kafka.apache.org/downloads.html .
In the following example, we will install the Kafka platform in the / usr / local / kafka directory, configuring it to use the ZooKeeper server running earlier and save the message log segments in the / tmp / kafka-logs directory:
# tar -zxf kafka_2.11-0.9.0.1.tgz # mv kafka_2.11-0.9.0.1 /usr/local/kafka # mkdir /tmp/kafka-logs # export JAVA_HOME=/usr/java/jdk1.8.0_51 # /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties # After starting the Kafka broker, you can test its operation by performing some simple cluster operations, including the creation of a test topic, the generation of messages and their consumption.
Creating and checking topics:
# /usr/local/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test Created topic "test". # /usr/local/kafka/bin/kafka-topics.sh --zookeeper localhost:2181 --describe --topic test Topic:test PartitionCount:1 ReplicationFactor:1 Configs: Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0 # Generating messages for the test topic:
# /usr/local/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test Test Message 1 Test Message 2 ^D # Consumption of messages from the test topic:
# /usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning Test Message 1 Test Message 2 ^C Consumed 2 messages # Broker configuration
An example broker configuration that comes with the Kafka distribution is quite suitable for a trial run of a standalone server, but for most installations it will not be enough. There are many Kafka configuration options that govern all aspects of installation and configuration. For many of them, you can leave the default values, as they relate to the nuances of the Kafka broker settings, which are not applied until you work with a specific script that requires their use.
Basic broker settings
There are several Kafka broker settings that you should consider when deploying a platform in any environment other than a standalone broker on a separate server. These parameters belong to the main settings of the broker, and most of them need to be changed so that the broker can work in a cluster with other brokers.
broker.id
Each Kafka broker must have an integer identifier specified by the broker.id parameter. By default, this value is 0, but can be any number. The main thing is that it does not happen within the same Kafka cluster. The choice of a number can be arbitrary, and if necessary, for the sake of convenience, it can be transferred from one broker to another. It is desirable that this number be somehow related to the host, then it will be more transparent to match the broker identifiers to the hosts under maintenance. For example, if your host names contain unique numbers (for example, host1.example.com, host2.example.com, etc.), these numbers would be a good choice for broker.id values.
port
A generic configuration file launches Kafka with a listener on TCP port 9092. You can change this port to any other available port by changing the port configuration parameter. Keep in mind that when choosing a port with a number less than 1024, Kafka should run as root. And running Kafka as root is not recommended.
zookeeper.connect
The path that ZooKeeper uses to store broker metadata is specified using the zookeeper.connect configuration parameter. In the sample configuration, ZooKeeper runs on port 2181 on the local host machine, which is listed as localhost: 2181. The format of this parameter is a semicolon-separated list of hostname: port / path strings, including:
- hostname is the hostname or IP address of the ZooKeeper server;
- port - client port number for the server;
- / path is an optional ZooKeeper path used as the new root (chroot) path of the Kafka cluster. If not specified, the root path is used.
If the specified chroot path does not exist, it will be created when the broker starts.
log.dirs
Kafka saves all messages to the hard disk, and these log segments are stored in the directories specified in the log.dirs setting. It is a comma-separated list of paths on the local system. If several paths are specified, the broker will save sections in them according to the principle of the least used, while preserving the log segments of the same section along the same path. Note that the broker will place the new section in the directory where the least partitions are currently stored, and not the least amount of space used, so that even distribution of data across partitions is not guaranteed.
num.recovery.threads.per.data.dir
Kafka uses a custom thread pool to process log segments. Currently it is applied:
- during normal start - to open the log segments of each of the sections;
- run after a crash — to check and truncate the log segments of each section;
- stop - for accurate closing of log segments.
By default, only one stream is enabled per log directory. Since this happens only at start and stop, it makes sense to use a larger number of them to parallelize operations. When recovering from an incorrect shutdown, the benefits of using this approach can reach several hours if the broker restarts with a large number of partitions! Remember that the value of this parameter is determined based on one log directory from the number specified using log.dirs. That is, if the value of the num.recovery.threads.per.data.dir parameter is 8, and three paths are indicated in log.dirs, then the total number of threads is 24.
auto.create.topics.enable
In accordance with the Kafka default configuration, the broker should automatically create a theme when:
- the manufacturer begins to write in the subject of the message;
- the consumer starts reading from the message subject;
- any client requests topic metadata.
In many cases, this behavior may be undesirable, especially due to the fact that it is not possible to verify the existence of a topic using the Kafka protocol without causing its creation. If you manage the creation explicitly, manually or through an initialization system, you can set the auto.create.topics.enable parameter to false.
Default Theme Settings
The Kafka server configuration sets a variety of default settings for themes created. Some of these parameters, including the number of sections and message storage options, can be set for each topic separately using administrator tools (discussed in Chapter 9). The default values in the server configuration should be set equal to the reference values suitable for most cluster topics.
num.partitions
The num.partitions parameter defines with how many sections a new topic is created, mainly when automatic creation of topics is enabled (which is the default behavior). The default value of this parameter is 1. Keep in mind that the number of sections for a topic can only be increased, but not reduced. This means that if it requires fewer sections than indicated in num.partitions, you will have to carefully create it manually (this is discussed in Chapter 9).
As discussed in Chapter 1, sections are a way of scaling up topics in a Kafka cluster, so it is important that there are as many as you need to balance the load on messages across the cluster as brokers are added. Many users prefer the number of sections to be equal to or a multiple of the number of brokers in a cluster. This makes it possible to evenly distribute sections across brokers, which will lead to an even distribution of the load across messages. However, this is not a mandatory requirement, because the presence of several themes allows to equalize the load.
log.retention.ms
Most often, the duration of storing messages in Kafka is limited in time. The default value is specified in the configuration file using the log.retention.hours parameter and is equal to 168 hours, or 1 week. However, two other parameters can be used - log.retention.minutes and log.retention.ms. All these three parameters define the same thing - a period of time after which messages are deleted. But it is recommended to use the log.retention.ms parameter, because if several parameters are specified, the priority is in the smallest unit of measure, so the value of log.retention.ms will always be used.
log.retention.bytes
Another way to limit the expiration of a message is based on the total size (in bytes) of the messages that are saved. The value is set using the log.retention.bytes parameter and is applied separately. This means that in the case of a topic of eight sections and a value of 1 GB equal to log.retention.bytes, the maximum amount of data stored for this topic will be 8 GB. Note that the amount of preservation depends on the individual sections, and not on the topic. This means that in the case of increasing the number of sections for a topic, the maximum amount of data stored using log.retention.bytes will also increase.
log.segment.bytes
The log save settings mentioned are for log segments, not for individual messages. As messages are generated by Kafka broker, they are added to the end of the current log segment of the corresponding section. When the log segment reaches the size specified by the parameter log.segment.bytes and is equal to 1 GB by default, this segment closes and a new one opens. After closing a segment of the journal can be withdrawn from circulation. The smaller the size of the log segments, the more often you have to close the files and create new ones, which reduces the overall efficiency of write operations to the disk.
Selection of the size of the journal segments is important in the case when the topics are characterized by a low frequency of message generation. For example, if the topic receives only 100 MB of messages per day, and the default value for the log.segment.bytes parameter is set, it will take 10 days to fill one segment. And since messages cannot be declared invalid until the log segment is closed, with a value of 604,800,000 (1 week) of the parameter log.retention.ms, by the time the closed log segment is withdrawn from circulation, messages for 17 days can accumulate. This is because when a segment closes with messages accumulated over 10 days, it has to be stored for another 7 days before it can be taken out of circulation in accordance with the provisional rules, since the segment cannot be deleted before the last message in it expires. .
log.segment.ms
Another way to control the closure of a log segment is by using the log.segment.ms parameter, which specifies the length of time after which the log segment closes. Like the log.retention.bytes and log.retention.ms parameters, the log.segment.bytes and log.segment.ms parameters are not mutually exclusive. Kafka closes the log segment when either the time period expires or the specified size limit is reached, depending on which of these events occurs first. By default, the value of the log.segment.ms parameter is not specified, resulting in the closure of log segments due to their size.
message.max.bytes
Kafka broker allows you to limit the maximum size of generated messages using the message.max.bytes parameter. The default value for this parameter is 1,000,000 (1 MB). The manufacturer who tries to send a larger message will receive an error notification from the broker, and the message will not be accepted. As in the case of all other sizes in bytes, specified in the broker settings, we are talking about the size of the compressed message, so that manufacturers can send messages, the size of which in uncompressed form is much larger if they can be compressed to the limits specified by the message.max.bytes parameter .
Increasing the permissible message size seriously affects performance. A larger message size means that broker threads that handle network connections and requests will take longer to process each request. Also, larger messages increase the amount of data written to disk, which affects I / O throughput.
Choice of hardware
Choosing the right hardware for a Kafka broker is more an art than a science. The Kafka platform itself does not have any strict hardware requirements, it will work without problems on any system. But if we talk about performance, then it is influenced by several factors: the capacity and throughput of disks, RAM, network and CPU.
First, you need to decide which types of performance are most important for your system, after which you can choose the best hardware configuration that fits into the budget.
Disk Bandwidth
The throughput of broker disks, which are used to store log segments, directly affects the performance of manufacturing customers. Kafka messages should be recorded in the local storage, which would confirm their record. Only after this can the dispatch operation be considered successful. This means that the faster the write operations to disk, the less delay in the generation of messages will be.
The obvious action in case of problems with disk bandwidth is to use hard disk drives with unwinding plates (HDD) or solid state drives (SSD). The SSD is orders of magnitude lower than the search / access time and higher performance. HDDs are more economical and have a higher relative capacity. HDD performance can be improved by increasing their number in a broker, or using several data directories, or installing disks into an array of independent disks with redundancy (redundant array of independent disks, RAID). Other factors also affect throughput, such as hard drive technology (for example, SAS or SATA), as well as the characteristics of a hard disk controller.
Disk capacity
Capacity is another aspect of storage. The amount of disk space needed is determined by how many messages you need to store simultaneously. If the broker is expected to receive 1 Tbyte of traffic per day, then with 7-day storage, he will need available for use storage for log segments of at least 7 Tbytes. You should also take into account the overrun of at least 10% for other files, not counting the buffer for possible fluctuations of traffic or its growth over time.
Storage capacity is one of the factors that must be considered when determining the optimal size of a Kafka cluster and deciding on its expansion. The overall cluster traffic can be balanced with several sections for each topic, which allows using additional brokers to increase the available capacity in cases when there is not enough data density per broker. The decision on how much disk space is needed is also determined by the replication strategy chosen for the cluster (discussed in more detail in Chapter 6).
Memory
In the normal mode of operation, the Kafka consumer reads from the end of the section, with the consumer constantly catching up for lost time and only slightly lagging behind the producers, if at all. , , . , , -.
Kafka JVM . , X X , 5 . Kafka . Kafka , , , Kafka.
, Kafka, . ( ) . Kafka ( ) . 1 , , . , (. 6) ( 8). , .
CPU
, , . . Kafka, , . . Kafka ' . .
Kafka
Kafka , , Amazon Web Services (AWS). AWS , CPU, . Kafka. , . / SSD. (, AWS Elastic Block Store). CPU .
, AWS m4 r3. m4 , , . r3 SSD-, . i2 d2.
Kafka
Kafka , (. 2.2). — . — . Kafka . Kafka. 6.
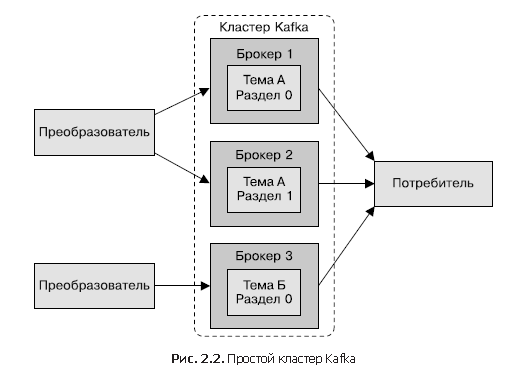
?
Kafka . — . 10 , 2 , — . , 100 % ( ) (. 6). , .
, , — . , ( ). 80 % , , . , , . , , .
Kafka. — zookeeper.connect. ZooKeeper . — broker.id. broker.id , . , , , .
Linux , , Kafka. , , . /etc/sysctl.conf, Linux, .
Linux . , «» , Kafka.
, , , () . , , Kafka. , Kafka , , .
— . — , - . . vm.swappiness , 1. ( ) , . , .
, «» , , . Kafka /. : (, SSD), NVRAM (, RAID). «» , . vm.dirty_background_ratio , ( 10). ( ), 5. 0, .
«» , , vm.dirty_ratio , — 20 ( ). , 60 80. , / . vm.dirty_ratio Kafka, .
«» Kafka . /proc/vmstat:
# cat /proc/vmstat | egrep "dirty|writeback" nr_dirty 3875 nr_writeback 29 nr_writeback_temp 0 # Disk
, RAID- , . , EXT4 (fourth extended file system — ) XFS (Extents File System — ). EXT4 , . , (5), . EXT4 , . XFS , , EXT4. XFS Kafka , , . , /.
, , noatime. /: (ctime), (mtime) (atime). atime . . atime , , , ( realtime). Kafka atime, . noatime /, ctime mtime.
Linux — , , . Kafka , - . ( ) , . . net.core.wmem_default net.core.rmem_default , 2 097 152 (2 ). , , .
TCP net.ipv4.tcp_wmem net.ipv4.tcp_rmem. , , . — 4096 65536 2048000 — , 4 , — 64 , — 2 . , net.core.wmem_max net.core.rmem_max. Kafka .
. TCP 1 net.ipv4.tcp_window_scaling, . net.ipv4.tcp_max_syn_backlog , 1024, . net.core.netdev_max_backlog, 1000, , , , .
Kafka , .
Java , , . , Java 7 Garbage First (G1). G1 . , , .
G1 . .
- MaxGCPauseMillis. . — G1 . 200 . , G1 , , , , 200 .
- InitiatingHeapOccupancyPercent. , . 45. , G1 , 45 % , (Eden), .
Kafka , . 64 , Kafka 5 . 20 MaxGCPauseMillis. InitiatingHeapOccupancyPercent 35, , .
Kafka G1, . . :
# export JAVA_HOME=/usr/java/jdk1.8.0_51 # export KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+DisableExplicitGC -Djava.awt.headless=true" # /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties # Kafka , . - , . Kafka (. 6), . Kafka, .
Kafka , , ( , , AWS), , . . , «» (. 6).
: Kafka , , , . ( ) . , , .
ZooKeeper
Kafka ZooKeeper , . ZooKeeper Kafka. , ZooKeeper Kafka . ZooKeeper Kafka ( ZooKeeper , ).
ZooKeeper . ZooKeeper, Kafka, . ZooKeeper , ZooKeeper . — 1 , . ZooKeeper, , . ZooKeeper , . , Kafka Kafka ZooKeeper.
Kafka, , . Kafka ZooKeeper, . ZooKeeper, . , , , . , , .
Summary
, Apache Kafka. , , . , Kafka, Kafka. Kafka ( 3), ( 4).
»More information about the book can be found on the publisher site.
» Table of Contents
» Excerpt
20% — Apache Kafka
Source: https://habr.com/ru/post/421519/
All Articles