Tame and Consolidate: The Story of Moving to the Oracle Supercluster
DBMS grow and multiply, automation scripts are becoming more and more complex, and time is spent more and more. In such conditions, sooner or later, the administrator comes to a bright thought: you need to change something. In this post, we will tell you by example how to solve the issue if you are dealing with Oracle databases of different colors and colors.
That's how it all began. By 2013, we have accumulated dozens of all databases running on Oracle. Some were small, but with heavy queries — for example, regulatory repositories or collection systems. Some could be attributed to OLTP, with a huge number of small queries - risk monitoring, sms-engine and others. There were systems that became very active only by payment dates or by the end of the month. In general, everyone has different tasks and load profiles, respectively. To be safe, for each system we kept a serious supply of computing power for peak loads, as well as a reserve of disk resources in case of a sudden increase. It took a lot of time and effort to support all this.
To reduce hardware costs, we decided to combine the Oracle databases of all midrange systems in one server. We had a good experience with Oracle Exadata: a replica on this system closed the problem with the construction of reporting processing. But the databases in Exadata work in Real Application Cluster, which imposes some restrictions on applications and requires thorough testing. Yes, and third-party software complex Exadata put on top of itself does not allow, which reduces the number of portable IT systems.
')
What are the options? The class of engineering systems Oracle also includes Supercluster. In addition to the advantages of Exadata, it has the ability to use databases in the RAC one node mode, essentially stand-alone, which minimizes the risks of migration. We calculated the economic effect of the transition to Supercluster: it turned out that for the cost of additional equipment that supports the natural growth of systems for the next year, we can purchase 2 new Superclusters. We successfully defended this decision in front of the business and in 2014 we acquired two halves of the Supercluster T5-8 for the main and backup complexes.
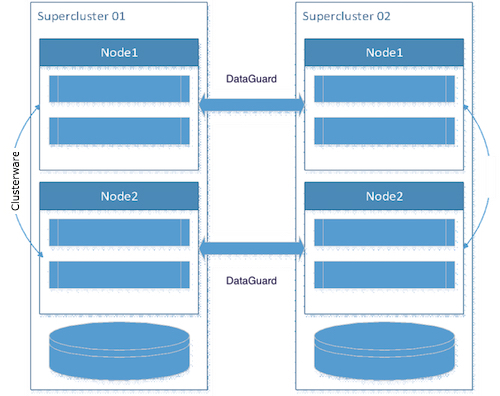
Each Supercluster half contained two compute nodes with four 16-core processors and 1 TB of memory. We put critical bases for business on the first nodes of the two superclusters, on the second nodes - all the rest, standby-bases. They were configured with less memory so that when problems arise on the primary node, the clusterware automatically raises resources on another, live node. In case of failure of the entire node, set up a failover switch using Data Guard. And to simplify the redundancy, we added additional FC-cards and Veritas Netbackup media servers to the nodes. Thus, we maximally used resources and ensured fault tolerance and disaster recovery.
The transfer of systems was accompanied by versatile testing. We had concerns that competition for the resources of many bases could lead to the degradation of services, but after transferring more than 30 systems, they realized that the speed of work had only increased. And even in those systems that were not helped by either the addition of processors with memory, or the transfer of databases to full-flash arrays. For example, in our main antifraud system, Risk Monitoring, which until then began to fail due to an increase in the load from source systems. Obviously, the matter is not only in the equipment itself, but also in the "mathematics" of the engineering systems of Oracle, which speeds up queries.
Today Supercluster has been working with us for more than four years. Here's what we like besides performance:
Separately, it is worth mentioning the versatile technical support for Oracle. For software and hardware systems, in addition to the standard Premier Support and partner support, we received free support for Platinum Service, which includes:
That's how it all began. By 2013, we have accumulated dozens of all databases running on Oracle. Some were small, but with heavy queries — for example, regulatory repositories or collection systems. Some could be attributed to OLTP, with a huge number of small queries - risk monitoring, sms-engine and others. There were systems that became very active only by payment dates or by the end of the month. In general, everyone has different tasks and load profiles, respectively. To be safe, for each system we kept a serious supply of computing power for peak loads, as well as a reserve of disk resources in case of a sudden increase. It took a lot of time and effort to support all this.
To reduce hardware costs, we decided to combine the Oracle databases of all midrange systems in one server. We had a good experience with Oracle Exadata: a replica on this system closed the problem with the construction of reporting processing. But the databases in Exadata work in Real Application Cluster, which imposes some restrictions on applications and requires thorough testing. Yes, and third-party software complex Exadata put on top of itself does not allow, which reduces the number of portable IT systems.
')
What are the options? The class of engineering systems Oracle also includes Supercluster. In addition to the advantages of Exadata, it has the ability to use databases in the RAC one node mode, essentially stand-alone, which minimizes the risks of migration. We calculated the economic effect of the transition to Supercluster: it turned out that for the cost of additional equipment that supports the natural growth of systems for the next year, we can purchase 2 new Superclusters. We successfully defended this decision in front of the business and in 2014 we acquired two halves of the Supercluster T5-8 for the main and backup complexes.
Each Supercluster half contained two compute nodes with four 16-core processors and 1 TB of memory. We put critical bases for business on the first nodes of the two superclusters, on the second nodes - all the rest, standby-bases. They were configured with less memory so that when problems arise on the primary node, the clusterware automatically raises resources on another, live node. In case of failure of the entire node, set up a failover switch using Data Guard. And to simplify the redundancy, we added additional FC-cards and Veritas Netbackup media servers to the nodes. Thus, we maximally used resources and ensured fault tolerance and disaster recovery.
The transfer of systems was accompanied by versatile testing. We had concerns that competition for the resources of many bases could lead to the degradation of services, but after transferring more than 30 systems, they realized that the speed of work had only increased. And even in those systems that were not helped by either the addition of processors with memory, or the transfer of databases to full-flash arrays. For example, in our main antifraud system, Risk Monitoring, which until then began to fail due to an increase in the load from source systems. Obviously, the matter is not only in the equipment itself, but also in the "mathematics" of the engineering systems of Oracle, which speeds up queries.
Today Supercluster has been working with us for more than four years. Here's what we like besides performance:
- IT costs have declined as we wanted.
- Reduced costs and administration. Previously, database support required not only DBMS administrators, but also unix administrators, storage administrators, and SAN administrators. Now, all supported by one person, and 90% of the administration is carried out through Oracle Cloud Control.
- The term for introducing new information systems has decreased, since no longer need to wait for the acquisition and supply of equipment for the database.
- In addition to useful Exadata pieces like smart scan, storage index and hybrid compression, we used the Exadata tool, IO Resource Manager, which is very useful for consolidating databases. With it, we prioritize the use of disk resources.
Separately, it is worth mentioning the versatile technical support for Oracle. For software and hardware systems, in addition to the standard Premier Support and partner support, we received free support for Platinum Service, which includes:
- The “call home” service is an automatic monitoring of equipment by the vendor: for example, in the event of a disk failure, the vendor will know about it first and organize the replacement procedure.
- Regular free system software updates.
- Much faster recovery of the complex via the Advanced Platinum Support Gateway system.
We are developing a Oracle Supercluster-based DBMS Oracle consolidation platform and at the end of 2017 the first three Supercluster M8s sold in the world came to us:
If you have any questions about our Supercluster usage scenarios, we’ll be happy to answer them in the comments.
Source: https://habr.com/ru/post/421425/
All Articles