Enterprise DevOps: as in the big company collect microservices
Hello!
For many years, Netracker has been developing and delivering enterprise applications for the global telecom operator market. The development of such solutions is quite complex: hundreds of people participate in projects, and the number of active projects is in the tens.
Previously, the products were monolithic, but now we are confidently moving in the direction of microservice applications. DevOps faced a rather ambitious task - to ensure this technological leap.
As a result, we got a good assembly concept, which we want to share as a best practice. The description of the implementation with the technical details will be quite voluminous, in this article we will not do that.
In the general case, an assembly is the transformation of some artifacts into others.
Who it will be interesting
Those companies that supply complete software completely third-party organizations and get paid for it.
Here is what a development without external delivery might look like:
- The IT department at the plant develops software for its enterprise.
- The company is engaged in outsourcing for a foreign customer. The customer independently compiles and exploits this code on his own web server.
- The company supplies software to external customers, but under an open source license. Most of the responsibility is thus lifted.
If you are not confronted with an external delivery, then a lot written below will seem superfluous or even paranoid.
In practice, everything must be done in compliance with international requirements for licenses and encryption used, otherwise there will be at least legal consequences.
An example of a violation is to take code from a library with a GPL3 license and embed it in a commercial application.
The emergence of microservices requires changes
We have a lot of experience in assembling and supplying monolithic applications.
Several Jenkins servers, thousands of CI jobs, several fully automated Jenkins-based assembly lines, dozens of dedicated release-engineers, and their own configuration management expert group.
Historically, the approach in the company was as follows: the source code is written by the developers, and the configuration of the build system is devised and written by DevOps.
As a result, we had two or three typical assembly configurations designed for operation in the corporate ecosystem. Schematically it looks like this:
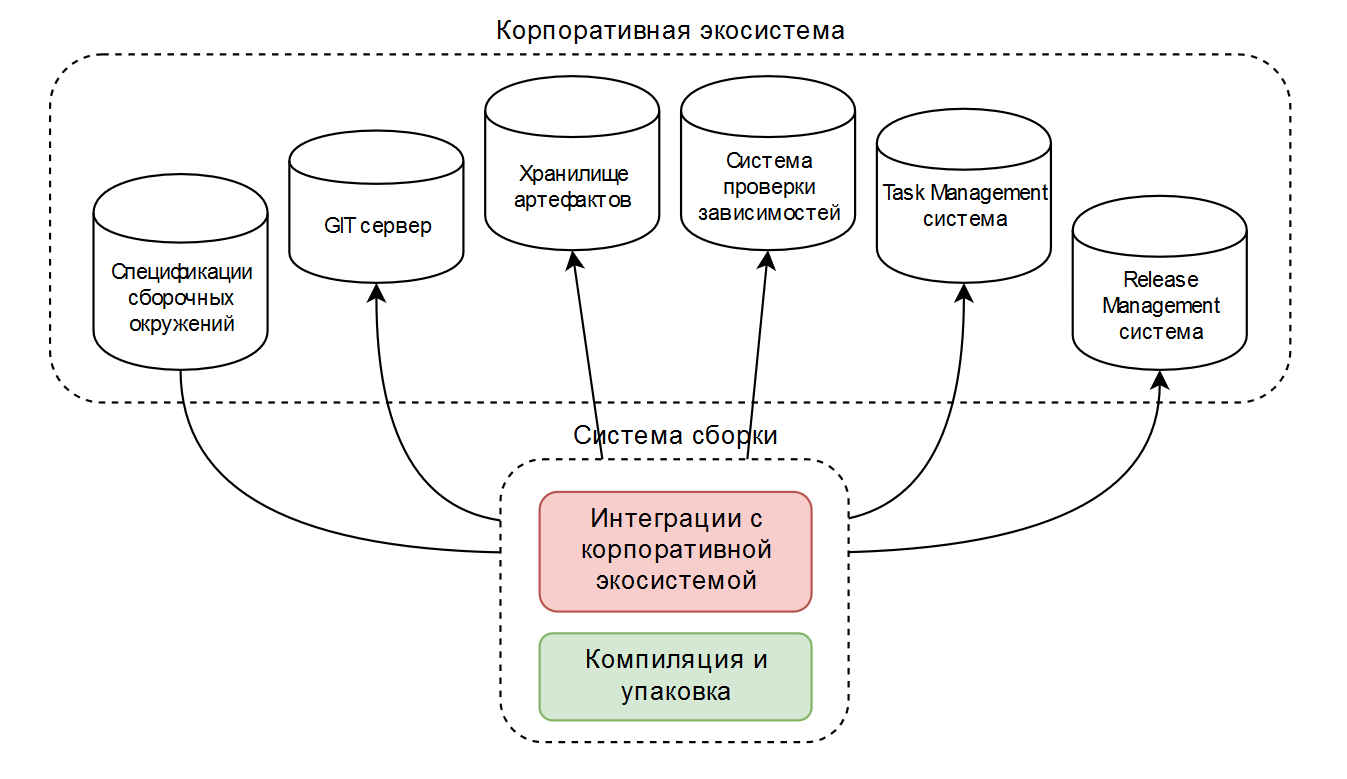
As an assembly tool, ant or maven is usually used, and something is implemented by publicly available plug-ins, something is written on its own. This works well when a company uses a narrow set of technologies.
Microservices are different from monolithic applications in the first place a variety of technologies.
It turns out a lot of assembly configurations for at least each programming language. Centralized control becomes impossible.
It is required to simplify the build scripts as much as possible and give developers the opportunity to edit them themselves.
In addition to simple compilation and packaging (in the diagram in green ), these scripts contain a lot of code for integration with the corporate ecosystem (in the diagram in red ).
Therefore, it was decided to perceive the assembly as a “black box”, in which the “smart” assembly environment can solve all the tasks, except for the compilation and packaging itself.
At the beginning of the work it was not clear how to get such a system. The adoption of architectural solutions for DevOps tasks requires experience and knowledge. How to get them? The options below are:
- Search for information on the Internet.
- DevOps-team own experience and knowledge. To do this, it is good to compile this team of programmers with diverse experience.
- Experience and knowledge gained outside the DevOps team. Many developers in the company have good ideas - you need to hear them. Communication is helpful.
- We invent and experiment!
Do you need automation?
To answer this question, you need to understand at what stage of evolution our approaches to assemblies are located. In general, the task passes the following levels.
- The level of "unconscious"

We need to produce one assembly per week, our guys do an excellent job. It is natural, why talk about it?
- The level of "artisan", with time transformed into the level of "trickster"
')
It is necessary to produce two assemblies per day stable and without errors. We have Vasya, he does it coolly, and no one, except him, spends time on it.
- The level of "manufactory"

Things went far. You need 20 assemblies per day, Vasya does not cope, and now a team of ten people is sitting. They have a boss, plans, vacations, sick leave, motivation, teambuilding, training, traditions and rules. This is a specialization, their work must be learned.
At this level, the task is separated from the specific executor and thus becomes a process.
The result will be a clear, worked out, run-in and corrected text description of the process hundreds of times.
- Level "automated production"

Modern requirements for assemblies are growing: everything must be fast, trouble-free, 800 assemblies must be provided per day. This is critical, because without such volumes the company will lose competitive advantages.
There is costly automation, and already a couple of qualified DevOps can keep the process running. Further scaling is no longer a problem.
Not every task should go to the last stage of automation.
Often, one team-maker will solve problems easily and efficiently.
Automation "freezes" the process, reduces the cost of operation and increases the cost of change.
Immediately you can go to the auto assemblies, but the system will be inconvenient, will not keep pace with the requirements of the business and as a result will become morally obsolete.
What are the assembly and why the problem is not solved ready assembly systems

We use the following classification to determine the aggregation levels of assemblies.
L1. A small independent part of a large application. This can be a single component, microservice, or one auxiliary library. L1 assembly is a solution of linear technical problems: compilation, packaging, work with dependencies. Maven, gradle, npm, grunt and other build systems do an excellent job with this. There are hundreds of them.
L1 assembly needs to be done using ready-made third-party tools.
L2 +. Integration entities. L1 entities are combined into larger formations, for example, into full-fledged microservice applications. Several such applications can be bundled as a single solution. We use the “+” sign, because, depending on the aggregation level of the assembly, L3 or even L4 can be assigned.
An example of such assemblies in the third-party world is the preparation of Linux distributions. Metapacks there.
In addition to fairly complex technical tasks (such as this: ru.wikipedia.org/wiki/Dependency_hell ). L2 + assemblies are often the final product and therefore have many process requirements: a system of rights, securing responsible people, the absence of legal errors, the supply of various documents.
At the L2 + level, process requirements take precedence over automation.
If the automatic solution does not work as it is convenient to interested people, it will not be implemented.
L2 + assemblies will most likely be performed by a proprietary tool, sharpened specifically for the company's processes. What do you think, package managers in Linux just come up with it?
Our best practices
Infrastructure
Permanent iron availability
The entire assembly infrastructure is located on closed servers within the corporate network. In some cases, commercial cloud services are possible.
Autonomy
In all CI processes, the Internet is not available. All necessary resources are mirrored and cached within the company. Partially even github.com (thank you, npm!) Most of these issues are solved by Artifactory.
Therefore, we are calm when removing artifacts from the maven central or closing popular repositories. There is an example: community.oracle.com/community/java/javanet-forge-sunset .
Mirroring significantly reduces assembly time, frees the corporate Internet channel. Fewer critical network resources increase assembly stability.
Three repositories for each artifact type
- Dev is a repository in which everyone can publish artifacts of any origin. Here you can experiment with fundamentally new approaches, not adapting them to corporate standards from day one.
- Staging is a repository filled only with an assembly line.
- Release - single assembly, ready for external delivery. Filled with a special transfer operation with manual confirmation.
30 day rule
From the Dev and Staging repositories we delete everything that is older than 30 days. This helps ensure equal publishing opportunities for all, at the cost of a finite amount of server disks.
Release is stored forever, if necessary, archiving is done.
Clean build environment
Often after assemblies in the system there are auxiliary files that may affect other assembly processes. Typical examples:
- the most common problem is a cache corrupted by one incorrect build (how to deal with caches, described below);
- some utilities, for example npm, leave service files in the $ HOME-directory, which affect all further launches of these utilities;
- a specific assembly can spend all disk space in a / tmp partition, which will lead to a general inaccessibility of the environment.
Therefore, it is better to abandon a single environment in favor of docker containers. Containers should contain only what is necessary for a specific build of software with fixed versions.
DevOps maintains a collection of docker build images that is constantly updated. At first there were about six of them, then it was under 30, then we set up automatic generation of the image according to the software list. Now we simply specify the requirements of the require ('maven 3.3.9', 'python') type - and the environment is ready.
Self test
It is necessary not only to organize user support for appeals, it is necessary to analyze the behavior of your own system. Constantly we collect logs, we look for in them the keywords showing problems.
It is enough to write 20-30 regular expressions on the “live” system so that for each assembly you can tell the reason for its fall at the level:
- git server failure;
- there is no more disk space;
- Build error due to developer’s fault;
- known bug in docker.
If something fell, but no known problem was found - this is the reason for replenishing the collection of masks.
Then we go to the user and say that his build is falling and this can be fixed in this way.
You will be surprised how many problems users do not report in support. It is better to repair them in advance and at a convenient time. Often, a minor publication error is ignored for two weeks, and on Friday evening it turns out that this blocks the external issue.
Carefully choose which systems the assembly depends on.
Ideally, to ensure complete autonomy of the assembly, but most often it is impossible. For java-based builds, at least Artifactory is needed for mirroring - see above about autonomy. Each integrated system increases the risk of failure. It is desirable that all systems work in decent HA mode.
Assembly line interface
Unified interface to call assembly
We produce any type of assembly with one system. Assemblies of all levels (L1, L2 +) are described by the program code and called up through one Jenkins job.
However, this approach is not perfect. It is better to use Jenkins autogeneration job mechanisms: for example, 1 job = 1 git repository or 1 job = 1 git branch. This will achieve the following:
- logs from different types of assemblies are not confused in one story on the Jenkins job page;
- in fact, they get comfortable selected jobs for a team or a developer; the feeling of comfort can be enhanced by adjusting the graphs of the results of junit, cobertura, sonar.
Freedom of choice of technology
Running the build is a call to the bash script "./build.sh". And further - any assembly systems, programming languages and everything else needed to complete a business task. This provides an approach to assembly as a “black box”.
Smart publishing
The assembly pipeline intercepts publications from the “black box” and puts them into the corporate repository. For this, boring questions such as generating names of docker images, choosing the right repository for publication are automatically solved.
Staging and release repositories are always in order. It is required to support the specifics of publications of different types: maven, npm, file, docker.
Assembly descriptor
Build.sh describes how to build code, but this is not enough for an assembly container.
It is also necessary to know:
- which build environment to use;
- environment variables available in build.sh;
- what publications will be executed;
- other specific options.
We chose a convenient way to describe this information in the form of a yaml file, remotely resembling .gitlab-ci.yaml.
Build Parameterization
The user can specify arbitrary parameters without executing the “git commit” command right at the start of the assembly.
We have this implemented through the definition of environment variables directly from the Jenkins job interface.
For example, we bring in the version of the dependent library to such an assembly parameter and in some cases we redefine this version to some experimental one. Without such a mechanism, the user would have to execute the git commit command every time.
System portability
It is necessary to be able to reproduce the assembly process not only on the main CI server, but also on the developer’s computer. This helps in debugging complex build scripts. In addition, instead of Jenkins, it will sometimes be more convenient to use Gitlab CI. Therefore, the build system should be an independent java-application. We implemented it as a gradle plugin.
One artifact can be published under different names.
There are two opposite requirements for publication that may arise at the same time.
On the one hand, for long-term storage and release management, it is necessary to ensure the uniqueness of the names of published artifacts. This will at least protect artifacts from being overwritten.
On the other hand, it is sometimes convenient to have one actual artifact with a fixed name like latest. For example, the developer does not need to know the exact version of the dependency each time; you can simply work with the latest one.
The artifact in this case is published under two or more names, to whom it is convenient.
For example:
- unique name with a time stamp or UUID - for those who need accuracy;
- the name "latest" - for their developers, who always pick up the latest code;
- the name “<major version> .x-latest” is for the neighboring team, which is ready to pick up the latest versions, but only within a certain major version.
Something like maven does in its approach to SNAPSHOT.
Less security restrictions
Assembly can run everyone. This will not harm anyone, since the assembly only creates artifacts.
Compliance with legal requirements
Control of external interactions of the assembly process
The assembly can not use anything prohibited in its work.
For this purpose, recording of network traffic and access to file caches is implemented. We get the network activity log of the assembly as a list of url with sha256 hashes of the received data. Then each url is validated:
- static whitelist;
- dynamic base of permissible artifacts (for example, for maven, rpm, npm dependencies). Each dependency is considered individually. An automatic resolution or a ban on use may work, a long discussion with lawyers may also begin.
Transparent content of published artifacts
Sometimes a task comes in - to provide a list of third-party software inside an assembly. To do this, they made a simple composition analyzer that analyzes all files and archives in the assembly, identifies third-parties by hashes and makes a report.
Source code issued cannot be removed from GIT
Sometimes it may be necessary to find the source code, looking at a binary artifact collected two years ago. To do this, you need to assign tags to Git automatically upon external issuance, as well as to prohibit their removal.
Logistics and accounting
All assemblies are stored in a database.
We use the file repository in Artifactory for this purpose. There is all the supporting information: who launched, what were the results of the checks, what artifacts were published, what git-hash was used, etc.
We know how to reproduce the assembly as accurately as possible.
According to the results of the assembly, we store the following information:
- the exact status of the code that was collected;
- with what parameters the launch was made;
- what commands were called;
- what appeals to external resources occurred;
- used build environment.
If necessary, we can fairly accurately answer the question of how it was collected.
Two-way connection of the assembly with the JIRA ticket
Be sure to be able to solve the following tasks:
- to build a list of JIRA tickets included in it;
- write in JIRA ticket, in which assembly it is included.
A strong two-way connection of the assembly with git commit is provided. And then from the text of the comments you can already find out about all the links to JIRA.
Speed
Caches for assembly systems
The absence of a maven cache can increase the build time by an hour.
The cache breaks the isolation of the build environment and the cleanliness of the build. This problem can be solved by determining its origin for each cached artifact. We have every cache file associated with an https-link, on which it was once downloaded. Further we process cache reading as network access.
Network resource caches
The growth of the company geographically leads to the need to transfer files of 300 MB between the continents. It takes a lot of time, especially if you have to do it often.
Git-repositories, docker-images of build environments, file storages - everything must be carefully cached. And, of course, periodically clean.
Build - as fast as possible, everything else - then
The first stage: we do the assembly and immediately, without unnecessary gestures, give the result.
The second stage: validation, analysis, accounting and other bureaucracy. This can be done already in a separate Jenkins job without any strict time limits.
What is the result
- The main thing - the assembly has become clear to developers , they themselves can develop and optimize it.
- A foundation has been created for building business processes that depend on an assembly: installation, issuance management, testing, release management, etc.
- The DevOps team no longer writes build scripts: the developers do it.
- Complex corporate requirements turned into a transparent report with a final list of checks.
- Anyone can build any repository by simply calling build.sh through a single interface. It is enough for it to simply specify the git-coordinates of the source code. This person can be a team manager, QA / IT engineer, etc.
And some numbers
- Time costs An extra 15 seconds is needed from calling the Jenkins job to the immediate build.sh operation. In these 15 seconds, the docker build container starts, network monitors are turned on, and caches are prepared. The remaining time costs are even less noticeable. Typical assembly takes about three minutes.
- The number of assemblies. Confidently approaches an average of one thousand per day. On some days it reached 2,200 units. Most are on-commit assemblies.
- About 300 git repositories are currently being processed, and their number is constantly growing.
- An average of 30 GB of unique artifacts is published per day, most of which (25 GB) is a docker.
- Below is a list of technologies and assembly tools that we use today:
- glide, golang, promu;
- maven, gradle;
- python & pip;
- ruby;
- nodejs & npm;
- docker;
- rpm build tools & gcc;
- build Android with ADT;
- commercial utilities;
- utilities for our legacy products;
- homemade build scripts.
Source: https://habr.com/ru/post/421423/
All Articles