Deep learning to identify paintings
Hi, Habr! Today I want to talk about how deep learning helps us better understand art. The article is divided into parts in accordance with the tasks that we solved:
- search for a picture in the database of a photo taken by a mobile phone;
- definition of the style and genre of the picture, which is not in the database.
All this was to be part of the Arthive DB service and its mobile applications.
The task of identifying the paintings was to find the corresponding picture in the database, coming from the mobile application, in less than one second. Processing entirely in the mobile device was excluded at the stage of the pre-project study. In addition, it turned out that it is impossible to guarantee the separation of the picture from the background in real conditions of shooting on a mobile device. Therefore, we decided that our service would accept a photo from the mobile phone as a whole, with all distortions, noises and possible partial overlapping.

Will we help Dasha find these pictures in a database of more than 200,000 images?
The artwork base of Arthive includes almost 250,000 images, along with various metadata. The base is continuously updated - from tens to hundreds of images per day. Even downloaded with limited resolution (no more than 1400 pixels on most of the sides) images occupy more than 80 gigabytes. Unfortunately, the base is “dirty”: there are broken or too small files, unaligned and unprocessed images, duplicate images. However, this is generally good data.
Comparison of pictures
Let's see how the images look in the database:
 Mark Rothko Orange, Red, Yellow |  Ilya Repin Nun |  David Burliuk Tropic women |
Basically, in the base of the image are aligned, cropped along the edges of the canvas, the colors are saved.
This is how requests from mobile devices might look like:

The colors are almost always distorted - there is a complex lighting, there are highlights, there are even reflections of other paintings in the glass. The images themselves are perspective distorted, may be partially cropped or, alternatively, occupy less than half of the image, may be partially closed, for example, by people.
In order to identify pictures you need to be able to compare images from queries with images in the database.
To compare images prone to perspective distortion and color distortion, we use the mapping of key points. To do this, we find key points with descriptors on the images, find their correspondence, and then a homographic mapping of the corresponding points using the RANSAC method. This is done as a whole in the same way as described in the OpenCV example. If the number of “good points” (inlier) found by RANSAC is large enough, and the homographic transformation found looks quite plausible (does not have strong scaling or rotations), then we can assume that the desired images are the same picture, subject to perspective distortions .
Example of matching key points:








Of course, the search for key points is usually quite a slow process, but to search the database you can find the key points of all the pictures in advance and save some of them. In our experiments, we came to the conclusion that less than 1000 points are enough for a confident search for pictures. When using 64 bytes per point (coordinates + AKAZE descriptor), 64 Kb for each image or about 15 GB for the entire base is enough to store 1024 points.
Comparison of pictures on key points in our case took about 15 ms, that is, for a complete search of the base of 250,000 pictures, it takes about 1 hour. It's a lot.
On the other hand, if we learn how to quickly select several (say, 100) most likely candidates from the entire base, we will meet the target time of 1 second per request.
Ranking pictures by similarity
Deep convolutional networks have proven to be a good way to search for similar images. The network is used to extract features and compute a descriptor based on them, which has the property that the distance (Euclidean, cosine or other) between similar image descriptors will be less than for different images.
It is possible to train the network in such a way that for the image of a picture from the base and its distorted image from a photo it gives out similar descriptors, and for different pictures - more distant ones. Further, this network is used to calculate the descriptors of all images in the database and photo descriptors in the requests. Quickly enough, you can select the nearest images and arrange them according to the distance between the descriptors.
The basic way to train a network to calculate a descriptor is to use the Siamese network.
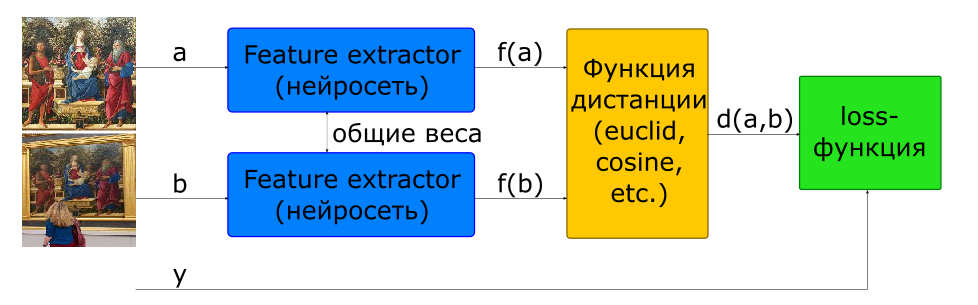
- input images
, if a and - one class if different
- image descriptors
- distance between a pair of feature vectors
- objective function
To build such an architecture, the network that calculates the descriptor (Feature Extractor) is used in the model 2 times with common weights. A couple of images are fed to the network. The Network's Feature Extractor calculates image descriptors, then the network calculates the distance according to a given metric (the Euclidean or cosine distance is usually used). The objective function of network learning is constructed in such a way that for positive pairs (images of one picture) the distance decreases, and for negative pairs (images of different pictures) it increases. To reduce the effect of negative pairs, the distance between them is limited by the margin value.
Thus, it can be said that in the process of learning the network tends to calculate descriptors of similar images inside a hypersphere with a radius of margin, and descriptors of different images push it out of this sphere.
For example, this is how a two-dimensional descriptor training with the help of a Siamese network on the MNIST dataset can look like.
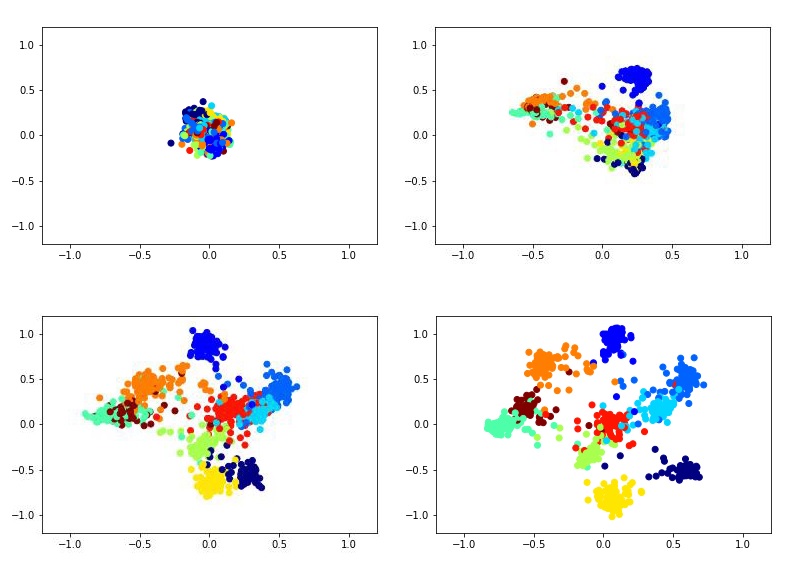
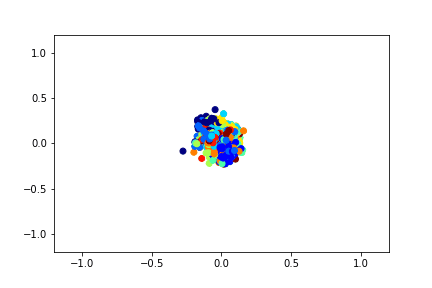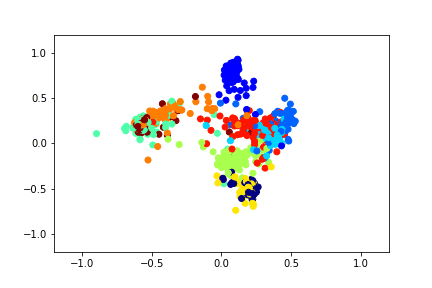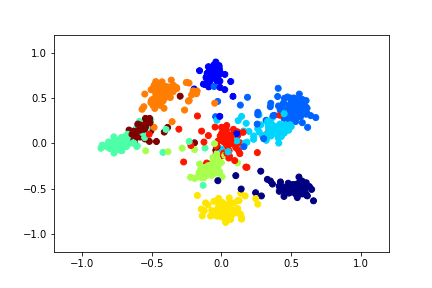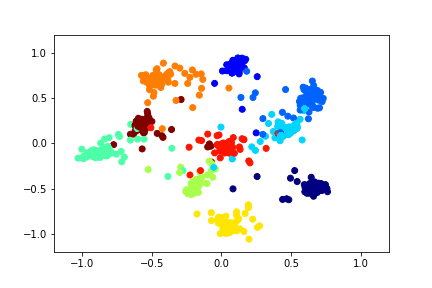
To train the Siamese network, you need to input a pair of pictures and a label that is equal to 1 if the pictures belong to the same class, or 0 if they are different. There is the problem of choosing the proportion of positive and negative pairs. Ideally, of course, all the possible combinations of pairs from the training set should be submitted to the network training, but this is technically impossible. And the number of negative pairs in this case significantly exceeds the number of positive ones, which is also not very good for the learning process.
Part of the problem with choosing the proportion of pairs for training is solved by using the triplet architecture.
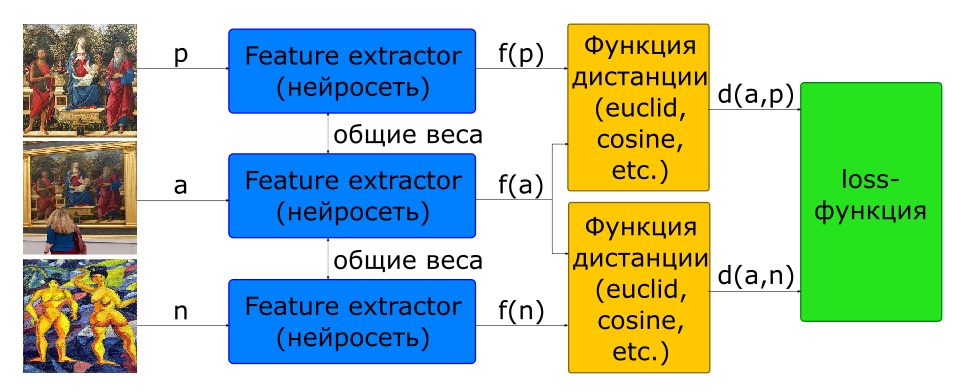
- input images: - one picture - another
- objective function
At the entrance of such a network, 3 pictures are immediately served, which form positive and negative pairs.
In addition, almost all researchers agree that the choice of negative pairs is crucial for network learning. The objective function for many samples (pairs for siamese, triples for triplet) is equal to 0, if they do not violate the margin limit, therefore, such samples do not participate in network training. Over time, the learning process slows down even more, as samples with a non-zero value of the objective function become smaller. To solve this problem, negative pairs are not chosen by chance, but by using hard case mining. In practice, several candidates of negatives are selected for this, for each of which a descriptor is calculated using the latest version of the weights of the network (from the previous era or even the current one). Having a descriptor, you can choose a negative in each of the three that produces a deliberately non-zero loss.
To search for similar images from the network, they separate Feature Extractor and use it to calculate descriptors. For images in the database descriptors are calculated in advance when they are added. Thus, the task of searching for similar images is to calculate the image descriptor in the query and search for the descriptors in the database that are closest in a given metric.
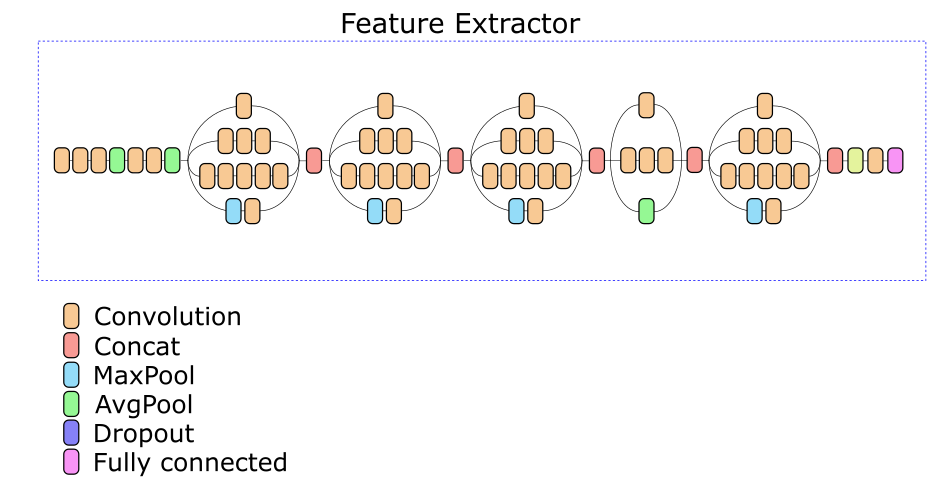
The feature extractor of our network is based on the Inception v3 architecture. Experimentally, one of the intermediate layers was chosen, on the basis of the output of which a descriptor of 512 real numbers is calculated.
Data augmentation
It would be nice if we could put each picture in a different frame, on different walls and take a picture each time from a different angle on different phones. In practice, this is of course impossible. Therefore it is necessary to generate training data.
To generate data, about 500 photographs of various pictures with different backgrounds under different lighting were collected. For each photo 4 points were selected, corresponding to the corners of the canvas of the picture. For four points, we can arbitrarily enter any image into the frame, thereby replacing the image and receiving an almost random perspective distortion of the picture from the database. Complementing this process with random crops, noises and color distortions, we are able to generate perfectly suitable images that imitate photographs of paintings.

Separating the painting from the background
The quality of work and patterns of identification of paintings, and models of classification of genres / styles largely depends on how well the picture is separated from the background. Ideally, before you feed the picture into the model, you need to find the 4 corners of its canvas and map it perspectively to the square. In practice, it was very difficult to implement an algorithm to do this with guarantee. On the one hand, there is a significant variety of backgrounds, frames and objects that can get into the frame near the picture. On the other hand, there are paintings, inside of which there are quite noticeable outlines of rectangular shapes (windows, facades of buildings, picture-in-picture). As a result, it is often very difficult to say where the picture ends and its environment begins.
Ultimately, we stopped at a simple implementation based on classical methods of computer vision (border detection + morphological filtering + analysis of connected components), which allows you to confidently cut off monochromatic backgrounds, but not to lose some of the picture.
Work speed
The query processing algorithm consists of the following basic steps:
- preparation - the simplest detector of the picture is actually implemented, which works well if the image contains a plain background;
- the calculation of the picture descriptor using a deep network;
- ranking of pictures by distance to the descriptors in the database;
- search for key points in the picture;
- check candidates in order of ranking.
We tested the speed of the network on 200 requests, we got the following processing time for each of the stages (time in seconds):
| stage | min | Max | the average |
|---|---|---|---|
| Preparation (search picture) | 0.008 | 0.011 | 0.016 |
| Handle Calculation (GPU) | 0.082 | 0.092 | 0.088 |
| KNN (k <500, CPU, brute force) | 0.199 | 0.820 | 0.394 |
| Search key points | 0.031 | 0.432 | 0.156 |
| Check key points | 0.007 | 9.844 | 2.585 |
| Total Request Time | 0.358 | 10.386 | 3.239 |
Since the check of candidates stops immediately, as the picture will be found with sufficient confidence, we can assume that the minimum request processing time corresponds to the pictures found among the first candidates. The maximum request time is obtained for pictures that were not found at all - the check is terminated after 500 candidates.
It can be seen that most of the time is spent on the selection of candidates and their verification. It is worth noting that the implementation of these steps has been done very suboptimally and has great potential for acceleration.
Duplicate search
Having built a complete index of the database of paintings, we applied it to search for duplicates in the database. After about 3 hours of viewing the database, it was found that at least 13657 images are repeated in the database two times (and some three).
At the same time, very interesting cases were found that are not duplicates.

One , Two . It seems that these are two stages of one work.

')
One , Two , Three . Do not pay attention to the name - all three paintings are different.
As well as an example of incorrect triggering of identification by key points.
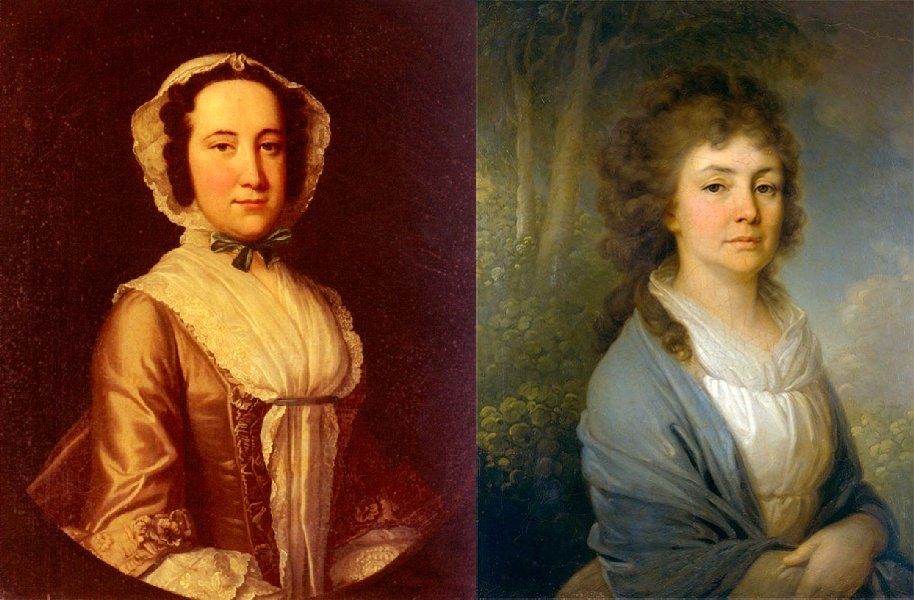
One , Two .

Instead of conclusion
In general, we are satisfied with the result of the service.
On test kits, identification accuracy in excess of 80% is achieved. In practice, it often turns out that if a picture is not found the first time, then it is enough to photograph it from a different angle, and it is located. Errors, when there is an incorrect image, practically do not occur.
All together, the solution was wrapped in a docker container and given to the customer. Now the identification of pictures by photo is available in applications using the Arthive service, for example, the “Pushkin Museum” available in the Play Market (however, there is a separation of the picture from the background, which requires the background to be light, which sometimes makes photographing difficult).
Source: https://habr.com/ru/post/421187/
All Articles