PostgreSQL: how and why swells wal
 In order to make monitoring useful, we have to work out different scenarios of probable problems and design dashboards and triggers in such a way that the cause of the incident is immediately clear from them.
In order to make monitoring useful, we have to work out different scenarios of probable problems and design dashboards and triggers in such a way that the cause of the incident is immediately clear from them.
In some cases, we are well aware of how a particular component of the infrastructure works, and then we know in advance which metrics will be useful. And sometimes we remove almost all possible metrics with maximum detail and then we look at how these or other problems are visible.
Today we will look at how and why Write-Ahead Log (WAL) can swell postgres. As usual - examples from real life in pictures.
A bit of WAL theory in postgresql
Any change in the database is first recorded in WAL, and only after that the data in the buffer cache page is changed and it is marked as dirtied - which needs to be saved to disk. In addition, the CHECKPOINT process is periodically launched, which saves all dirtied pages to disk and saves the number of the WAL segment, up to which all modified pages are already written to disk.
If postgresql suddenly crashes for some reason and starts up again, the recovery process will play all WAL segments since the last checkpoint.
The WAL segments preceding the checkpoint will no longer be useful for the post-accident database recovery, but in the post-session WAL is also involved in the replication process, and the backup copy of all the segments can be configured for Point In Time Recovery - PITR.
An experienced engineer has probably already understood everything, how it breaks down in real life :)
Let's watch the graphics!
WAL is swollen # 1
Our monitoring agent for each found postgres instance calculates the path on disk to the directory with wal and removes both the total size and the number of files (segments):
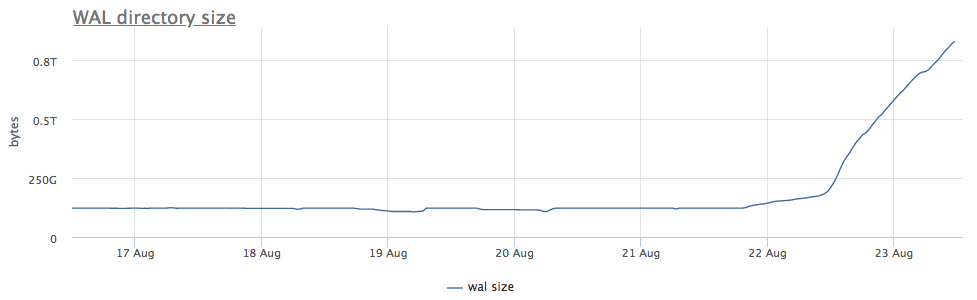
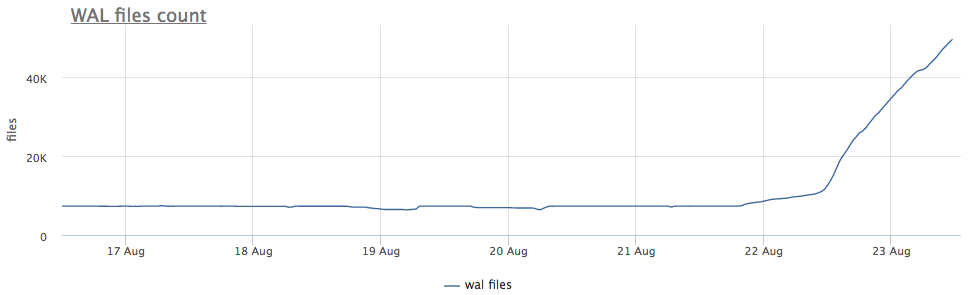
First of all, we look at how long CHECKPOINT has been running.
Metrics we take from pg_stat_bgwriter:
- checkpoints_timed - counter of checkpointer launches that occurred by the condition of exceeding the time from the last checkpoint by more than pg_settings.checkpoint_timeout
- checkpoints_req - count of start points for checkpoints based on the condition of exceeding the size of wal from the last checkpoint
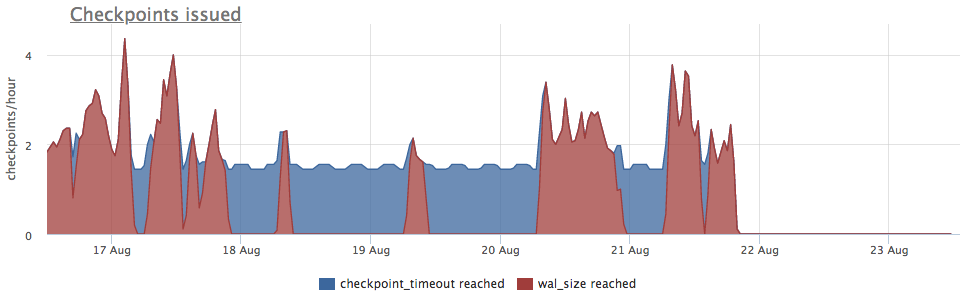
We see that checkpoint did not start long ago. In this case, it is impossible to directly understand the reason for the non-launching of this process (and it would be cool of course), but we know that in the post-grease a lot of problems arise due to long transactions!
Checking:

Further it is clear what to do:
- kill transaction
- deal with the reasons why it is long
- wait but check that there is enough space
Another important point: on the replicas connected to this server, wal is also swollen !
WAL archiver
On occasion, I remind you: replication is not a backup!
A good backup should allow you to recover at any time. For example, if someone "accidentally" performed
DELETE FROM very_important_tbl; So we should be able to restore the database to a state exactly before this transaction. This is called PITR (point-in-time recovery) and is implemented in postgresql with periodic full database backups + saving all WAL segments after a dump.
For backup wal is responsible setting archive_command, postgres simply runs the command you specified, and if it completes without an error, the segment is considered to be successfully copied. If you get a mistake, it will try to win, the segment will lie on the disk.
Well, as an illustration, the graphs of broken archiving wal:
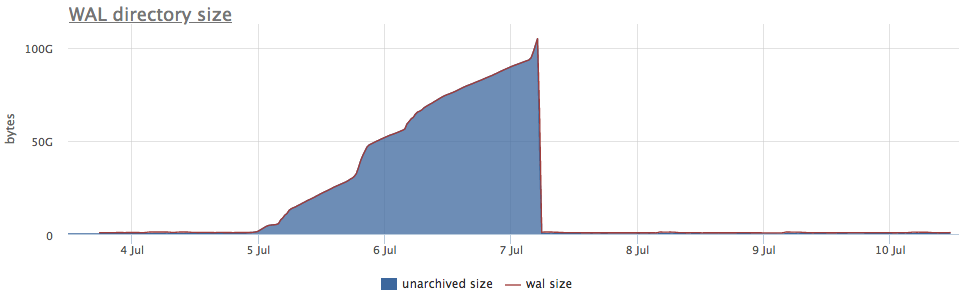
Here, in addition to the size of all segments of the wal, there is an unarchived size — this is the size of the segments that are not yet considered successfully stored.
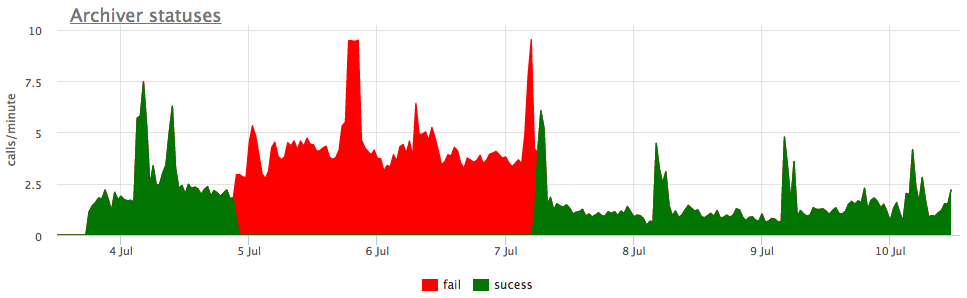
The statuses are counted by the pg_stat_archiver counters. We have made the auto-trigger for all clients for the number of files, since it often breaks down, especially when some cloud storage is used as a destination (S3 for example).
Replication lag
Streaming replication in the program works by transmitting and playing the wal on replicas. If for some reason the replica has lagged behind and has not lost a certain number of segments, the master will store for it pg_settings.wal_keep_segments segments. If the replica lags behind a greater number of segments, it will no longer be able to connect to the master (you will have to re-fill).
In order to guarantee the preservation of any desired number of segments, in 9.4 there appeared the functionality of replication slots, which will be discussed further.
Replication slots
If replication is configured using replication slot and there was at least one successful replica connection to the slot, then in case the replica disappears, the postgres will store all new segments of the wal until the place runs out.
That is, a forgotten replication slot may be the cause of the swelling wal. But fortunately, we can monitor the status of the slots via pg_replication_slots.
Here is how it looks on a live example:
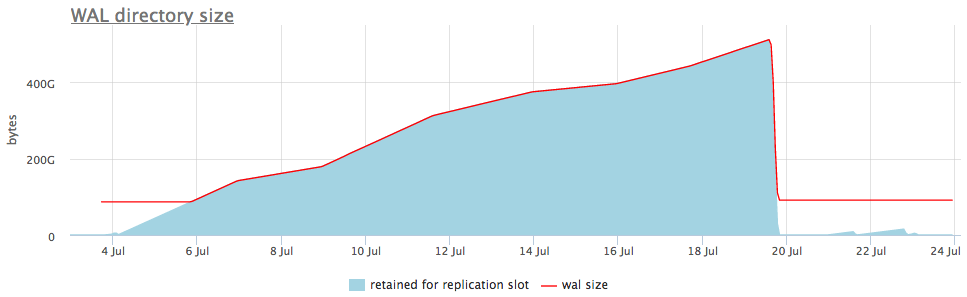

On the upper graph, we always show either a slot with the maximum number of accumulated segments next to the size of wal, but there is also a detailed graph that shows which slot is swollen.
Once we understand what data is being saved for the slot, we can either fix the replicas associated with it, or simply delete it.
I gave the most common cases of swelling wal, but I am sure there are other cases (bugs in the postgres are also sometimes found). Therefore, it is important to monitor the size of the wal and respond to problems before the disk space runs out and the database stops servicing requests.
Our monitoring service has already been able to collect all this, correctly visualize and alert. And we also have an on-plan delivery option for those to whom the cloud is not suitable.
')
Source: https://habr.com/ru/post/421061/
All Articles