Google Hadoop Review (dataproc)
Some time ago I activated a free trial for Google under their cloud, I didn’t solve my problem, it turned out Google gives $ 300 for 12 months for a trial, but contrary to my expectations, other limits are imposed as well as the budget limit. For example, I did not allow virtual users to use more than 8 vcpu in one region. After half a year, I decided to use the trial budget for acquaintance with dataproc, the pre-installed Hadup cluster from Google. The task is to try to estimate how easy it would be for me to start a project on Google’s Hadup, is there any sense in it, or is it better to focus on your hardware and think through administration. I have a vague feeling that the modern iron and bigdat stack should already easily adapt to small databases of tens or hundreds of GB, brutally loading if not all, then the overwhelming part of the cluster memory. Some separate subd data marts may not be necessary.
In short, dataproc was impressed with the ease of launching and configuration, against the background of Oracle and Cloudera. At the first stage, I played with one node cluster at 8 vCpu, the maximum that a completely free trial allows. If you look at simplicity, then their technologies already allow a Hindu in 15 minutes to start a cluster, load sample data and prepare an ordinary BI tool, without any intermediate sub-windows. Any deep knowledge about Khadup is no longer required.
In principle, I saw that a wonderful thing for a quick start and for the sane money you can run a prototype, evaluate what kind of hardware you need for the task. However, a larger cluster, in dozens of nodes, will obviously eat significantly more than rent + a couple of admins looking after the cluster. Far from the fact that cloud will look cost effective. At the first stage I tried to evaluate a completely micro version with one node cluster 8 vCpu and 0.5 TB of raw data. In principle, the spark + hadoop tests on clusters are larger and more complete on the Internet, but I plan to test a bit larger version later.
Literally in an hour, I nagulit scripts creating a cluster of hadup, setting up its firewall and setting up a thrift server, which allowed jdbc from a home Windows to connect to the spark sql. I spent another two or three hours optimizing the default spark settings and loading a couple of small tables about 10 GB in size (the size of the data files in Oracle). I pushed the tables into memory (alter table cache;) and it was possible to work with them from my Windows machine from Dbeaver and Tableau (via spark sql connector).
')
By default, Spark used only 1 executor on 4 vCpu, I edited spark-defaults.conf, put 3 executers, 2 vCpu each, and for a long time could not understand why I really only have 1 executer. It turned out that I had not edited the memory, the other two yarn simply could not allocate memory. I put 6.5 GB on the executer, after that, as expected, all three began to rise.
Then I decided to play with a bit more serious volumes and a task closer to DWH from the TPC-DS tests. To begin with, I officially generated the tables with a scale factor of 500. It turned out to be about 480 GB of raw data (text with separator). The TPC-DS test is a typical DWH, with facts and dimensions. I did not understand how to generate the data immediately on google storage, I had to generate a virtual disk on disk and then copy it to google storage. Google, as I understand it, thinks that Hadup works fine with google storage and the speed there promises a little better than if the data were inside a cluster on HDFS. At the same time, part of the load is transferred from HDFS to google storage.
Having connected via Dbeaver, I converted text files into SQL commands into parquet-based tablets with snappy packaging. 480 GB of text data were packed into 187 GB parquet files. The process took about two hours, the largest table took 188 GB in the text, 3 spark executers in the parquet turned them in 74 minutes, the size of the SUV was 66.8 GB. On my desktop with about the same 8 vCpu (i7-3770k) I think “insert into table select * ...” into an 8k block table would take a day, and how many data files would be even scary to imagine.
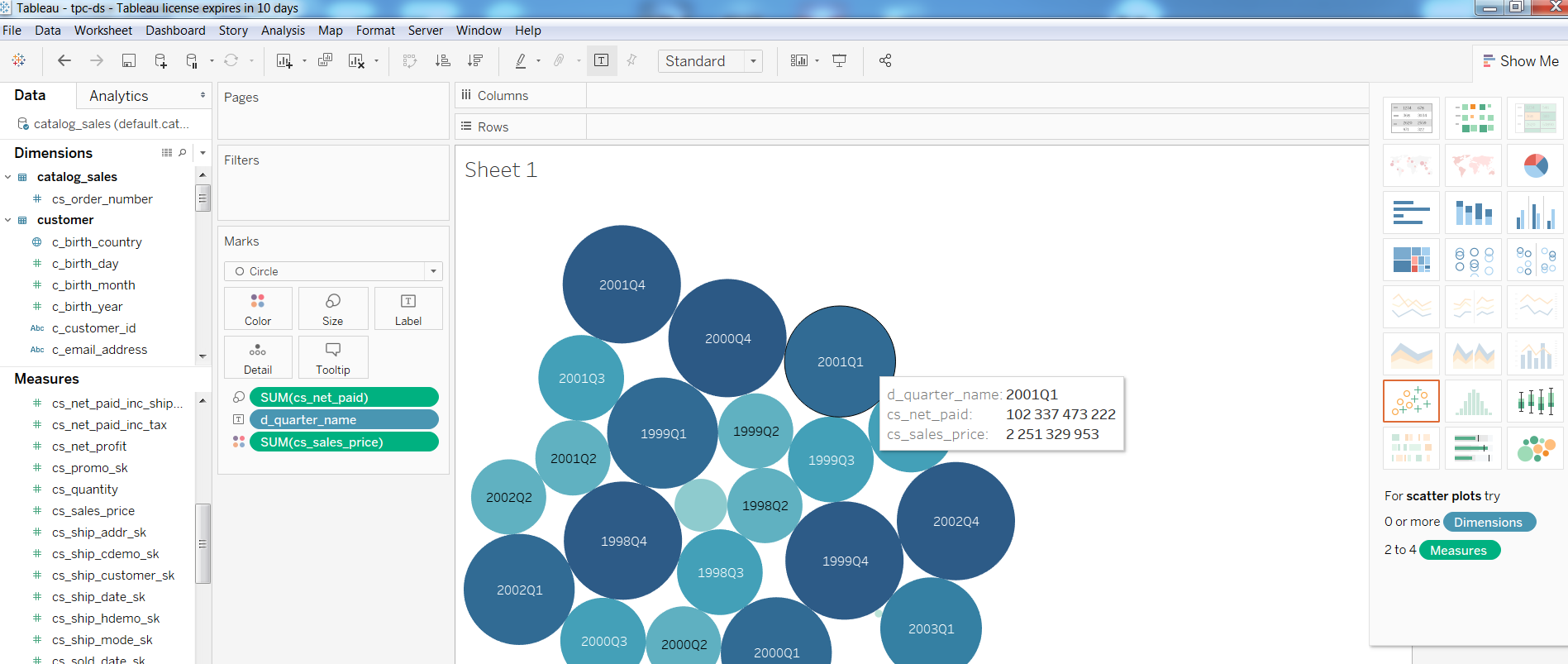
Next, I checked the performance of BI tools on such a config, built a simple report in Tableua
As for queries, Query1 from the TPC-DS test
executed in 1:08, Query2 with the participation of the largest tables (catalog_sales, web_sales)
executed in 4:33 minutes, Query3 in 3.6, Query4 in 32 minutes.
If someone is interested in the settings, under the cut are my notes on creating a cluster. In principle, there are only a couple of gcloud commands and setting up HIVE_SERVER2_THRIFT_PORT.
To be continued ...
In short, dataproc was impressed with the ease of launching and configuration, against the background of Oracle and Cloudera. At the first stage, I played with one node cluster at 8 vCpu, the maximum that a completely free trial allows. If you look at simplicity, then their technologies already allow a Hindu in 15 minutes to start a cluster, load sample data and prepare an ordinary BI tool, without any intermediate sub-windows. Any deep knowledge about Khadup is no longer required.
In principle, I saw that a wonderful thing for a quick start and for the sane money you can run a prototype, evaluate what kind of hardware you need for the task. However, a larger cluster, in dozens of nodes, will obviously eat significantly more than rent + a couple of admins looking after the cluster. Far from the fact that cloud will look cost effective. At the first stage I tried to evaluate a completely micro version with one node cluster 8 vCpu and 0.5 TB of raw data. In principle, the spark + hadoop tests on clusters are larger and more complete on the Internet, but I plan to test a bit larger version later.
Literally in an hour, I nagulit scripts creating a cluster of hadup, setting up its firewall and setting up a thrift server, which allowed jdbc from a home Windows to connect to the spark sql. I spent another two or three hours optimizing the default spark settings and loading a couple of small tables about 10 GB in size (the size of the data files in Oracle). I pushed the tables into memory (alter table cache;) and it was possible to work with them from my Windows machine from Dbeaver and Tableau (via spark sql connector).
')
By default, Spark used only 1 executor on 4 vCpu, I edited spark-defaults.conf, put 3 executers, 2 vCpu each, and for a long time could not understand why I really only have 1 executer. It turned out that I had not edited the memory, the other two yarn simply could not allocate memory. I put 6.5 GB on the executer, after that, as expected, all three began to rise.
Then I decided to play with a bit more serious volumes and a task closer to DWH from the TPC-DS tests. To begin with, I officially generated the tables with a scale factor of 500. It turned out to be about 480 GB of raw data (text with separator). The TPC-DS test is a typical DWH, with facts and dimensions. I did not understand how to generate the data immediately on google storage, I had to generate a virtual disk on disk and then copy it to google storage. Google, as I understand it, thinks that Hadup works fine with google storage and the speed there promises a little better than if the data were inside a cluster on HDFS. At the same time, part of the load is transferred from HDFS to google storage.
Having connected via Dbeaver, I converted text files into SQL commands into parquet-based tablets with snappy packaging. 480 GB of text data were packed into 187 GB parquet files. The process took about two hours, the largest table took 188 GB in the text, 3 spark executers in the parquet turned them in 74 minutes, the size of the SUV was 66.8 GB. On my desktop with about the same 8 vCpu (i7-3770k) I think “insert into table select * ...” into an 8k block table would take a day, and how many data files would be even scary to imagine.
Next, I checked the performance of BI tools on such a config, built a simple report in Tableua
As for queries, Query1 from the TPC-DS test
Query1
WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100; executed in 1:08, Query2 with the participation of the largest tables (catalog_sales, web_sales)
Query2
WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1; executed in 4:33 minutes, Query3 in 3.6, Query4 in 32 minutes.
If someone is interested in the settings, under the cut are my notes on creating a cluster. In principle, there are only a couple of gcloud commands and setting up HIVE_SERVER2_THRIFT_PORT.
Notes
one node cluster option:
gcloud dataproc --region europe-north1 clusters create test1 \
--subnet default \
--bucket tape1 \
--zone europe-north1-a \
- single-node \
--master-machine-type n1-highmem-8 \
--master-boot-disk-size 500 \
--image-version 1.3 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--project 123
option for 3 nodes:
gcloud dataproc --region europe-north1 clusters \
create cluster-test1 --bucket tape1 \
--subnet default --zone europe-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-workers 2 \
--worker-machine-type n1-standard-1 --worker-boot-disk-size 10 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--project 123
gcloud compute --project = 123 \
firewall-rules create allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--source-ranges = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
at master node:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
change: export HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
gcloud dataproc --region europe-north1 clusters create test1 \
--subnet default \
--bucket tape1 \
--zone europe-north1-a \
- single-node \
--master-machine-type n1-highmem-8 \
--master-boot-disk-size 500 \
--image-version 1.3 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--project 123
option for 3 nodes:
gcloud dataproc --region europe-north1 clusters \
create cluster-test1 --bucket tape1 \
--subnet default --zone europe-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-workers 2 \
--worker-machine-type n1-standard-1 --worker-boot-disk-size 10 \
--initialization-actions gs: //dataproc-initialization-actions/hue/hue.sh \
--initialization-actions gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--initialization-actions gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--project 123
gcloud compute --project = 123 \
firewall-rules create allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--source-ranges = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
at master node:
sudo su - vi /usr/lib/spark/conf/spark-env.sh
change: export HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark /usr/lib/spark/sbin/start-thriftserver.sh
To be continued ...
Source: https://habr.com/ru/post/421021/
All Articles