Continuous Cloud Infrastructure
Demonstrate the use of open source tools, such as Packer and Terraform, for the continuous delivery of infrastructure changes to the users' favorite cloud environment.
The material is based on Paul Stack’s speech at our DevOops 2017 autumn conference . Paul is an infrastructure developer who used to work at HashiCorp and participated in the development of tools used by millions of people (for example, Terraform). He often speaks at conferences and communicates practice from the leading edge of CI / CD implementations, the principles of proper organization of operations-parts, and is able to clearly communicate why administrators do this at all. Further in the article the narration is conducted in the first person.
So let's start right away with a few key findings.

')
I previously worked in an organization where we deployed Windows Server 2003 back in 2008, and today they are still in production. And such a company is not alone. Using remote desktop on these servers, they install software on them manually by downloading binary files from the Internet. This is a very bad idea, because the servers are not typical. You cannot guarantee that the same thing happens in production as in your development environment, in an intermediate environment, in a QA environment.
In 2013, an article appeared in Chad Foiler’s blog “Throw away your servers and burn the code: unchanging infrastructure and disposable components” (Chad Foiler “Trash your servers and burn your infrastructure and disposable components” ). This is a conversation mostly about the fact that unchanging infrastructure is the way forward. We have created an infrastructure, and if we need to change it, we create a new infrastructure. This approach is very common in the cloud, because here it is fast and cheap. If you have physical data centers, it is a bit more complicated. Obviously, if you run data center virtualization, everything becomes easier. However, if you still run physical servers every time, it takes a little longer to enter a new one than to change an existing one.
According to functional programmers, “unchangeable” is actually the wrong term for this phenomenon. Because to be truly immutable, your infrastructure needs a read-only file system: no files will be written locally, no one will be able to use SSH or RDP, etc. Thus, it seems that the infrastructure is actually not immutable.
Terminology has been discussed on Twitter for six or even eight days by several people. As a result, they agreed that “one-time infrastructure” is a more appropriate formulation. When the life cycle of a “one-time infrastructure” ends, it can be easily destroyed. You do not need to hold on to it.
I will give an analogy. Cows on farms are usually not considered as pets.

When you have cattle on your farm, you do not give it individual names. Each individual has a number and tag. Same with servers. If you still have production servers manually created in 2006, they have meaningful names, for example, “SQL database on production 01”. And they have a very specific meaning. And if one of the servers falls, hell begins.
If one of the animal herds dies, the farmer simply buys a new one. This is the "one-time infrastructure."
So how to combine this with Continuous Delivery?
Everything that I am talking about now exists for quite some time. I'm just trying to combine the ideas of infrastructure development and software development.
Software developers have been practicing continuous delivery and continuous integration for a long time. For example, Martin Fowler ( Martin Fowler ) wrote about continuous integration in his blog in the early 2000s. Jez Humble has been pushing for a continuous supply for a long time.
If you take a closer look, there is nothing created specifically for the software source code. There is a standard definition from Wikipedia: continuous delivery is a set of practices and principles aimed at creating, testing and releasing software as quickly as possible .
The definition does not speak about web applications or APIs, it is about software as a whole. Creating a working software requires many pieces of the puzzle. In this way, you can also practice continuous delivery for infrastructure code in the same way.
Development of infrastructure and applications are pretty close directions. And people who write application code also write infrastructure code (and vice versa). These worlds are beginning to unite. There is no longer such a separation and specific traps of each of the worlds.
Continuous delivery has a number of principles:
But more importantly, continuous delivery has four practices. Take them and transfer directly to the infrastructure:
Has anyone read the book "Continuous Delivery" ?

I am sure your companies will pay you a copy that you can transfer within the team. I am not saying that you should sit down and spend the day off reading it. If you do, you probably want to leave IT. But I recommend periodically learning small pieces of a book, digesting them and thinking about how to transfer this to your environment, to your culture and to your process. One small piece at a time. Because continuous delivery is a conversation about continuous improvement. It’s not easy to sit in the office with your colleagues and boss and start a conversation with the question: “How will we introduce a continuous supply?”, Then write 10 things on the blackboard and in 10 days understand that you implemented it. It takes a lot of time, causes a lot of protests, as the culture changes as it is introduced.
Today we will use two tools: Terraform and Packer (both developed by Hashicorp). A further story will be about why we should use Terraform and how to integrate it into our environment. I do not accidentally talk about these two tools. Until recently, I also worked at Hashicorp. But even after I left Hashicorp, I still contribute to the code of these tools, because I actually find them very useful.
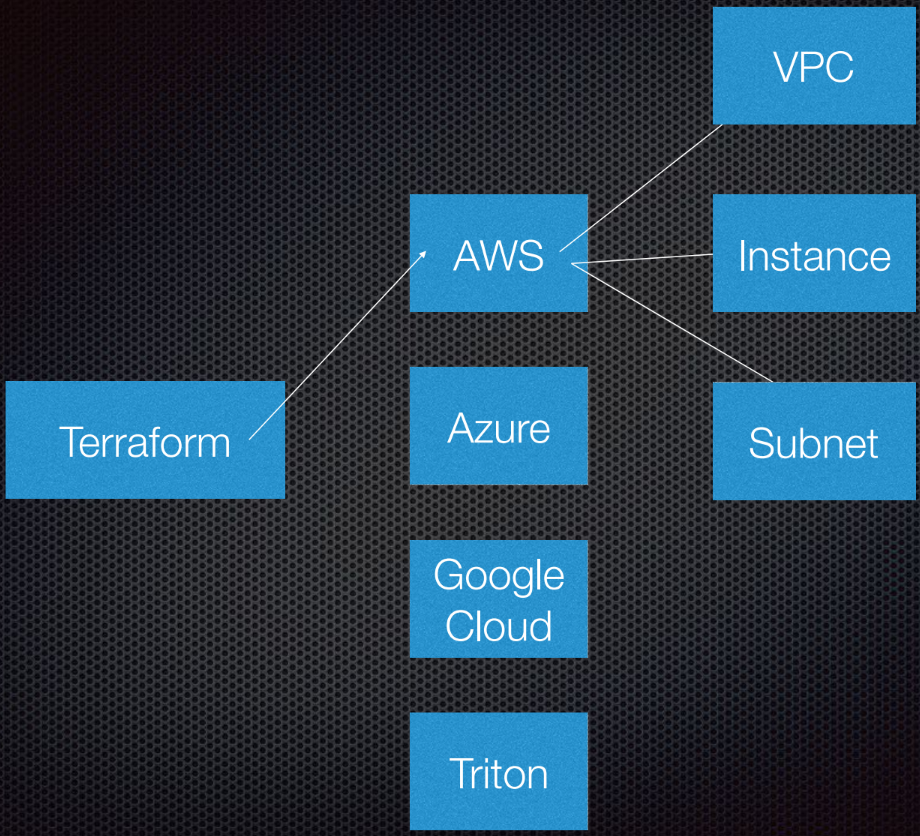
Terraform supports interaction with providers. Providers are clouds, Saas services, etc.
Within each cloud service provider there are several resources, such as a subnet, VPC, load balancer, etc. With DSL (domain-specific language), you specify Terraform what your infrastructure will look like.
Terraform uses graph theory.

You probably know graph theory. Nodes are parts of our infrastructure, such as a load balancer, subnet, or VPC. Ribs are the relationships between these systems. This is all that I personally consider necessary to know about graph theory for using Terraform. The rest is left to the experts.

Terraform actually uses a directed graph, because it knows not only the relationship, but also their order: that A (suppose A - VPC) must be set before B, which is a subnet. And B must be created before C (instance), because there is a prescribed order for creating abstractions in Amazon or any other cloud.
Further information on this topic is available on YouTube by Paul Henze (Paul Hinze), who still works at Hashicorp as infrastructure director. The link is a great conversation about infrastructure and graph theory.
Write the code, it is much better than discussing the theory.
I previously created AMI (Amazon Machine Images). To create them, I use Packer and I'm going to show you how to do it.
AMI is an instance of a virtual server in Amazon, it is predefined (in terms of configuration, applications, etc.) and is created from an image. I love that I can create new AMIs. In essence, AMI are my Docker containers.
So, I have an AMI, they have an ID. Going to the Amazon interface, we see that we have only one AMI and nothing more:

I can show you what is in this AMI. Everything is very simple.
I have a JSON file template:
We have variables that we pass, and Packer has a list of so-called Builders for different areas; many of them. Builder uses a special AMI source, which I pass to the AMI identifier. I give him an SSH username and password, and also indicate if he needs a public IP address so that people can access it from outside. In our case, this does not really matter, because this is the AWS instance for the Packer.
We also set AMI name and tags.
You do not need to parse this code. He is here only to show you how he works. The most important part here is the version. It will become relevant later when we enter Terraform.
After the builder calls an instance, provisioners run on it. I actually install NCP and nginx to show you what I can do here. I copy some files and just configure the nginx configuration. Everything is very simple. Then I activate nginx so that it starts when the instance is started.
So, I have an application server, and it works. I can use it in the future. However, I always check my Packer templates. Because it is a JSON configuration where you may encounter some problems.
To do this, I run the command:
I get the answer that the Packer template was verified successfully:
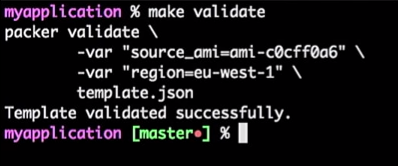
This is just a command, so I can connect it to the CI tool (anyone). In fact, it will be a process: if the developer changes the template, a pull request is formed, the CI tool checks the request, performs the equivalent of the template validation, and publishes the template if the validation is successful. All this can be combined in the "Master".
We get the stream for AMI templates - you just need to raise the version.
Suppose a developer has created a new version of AMI.
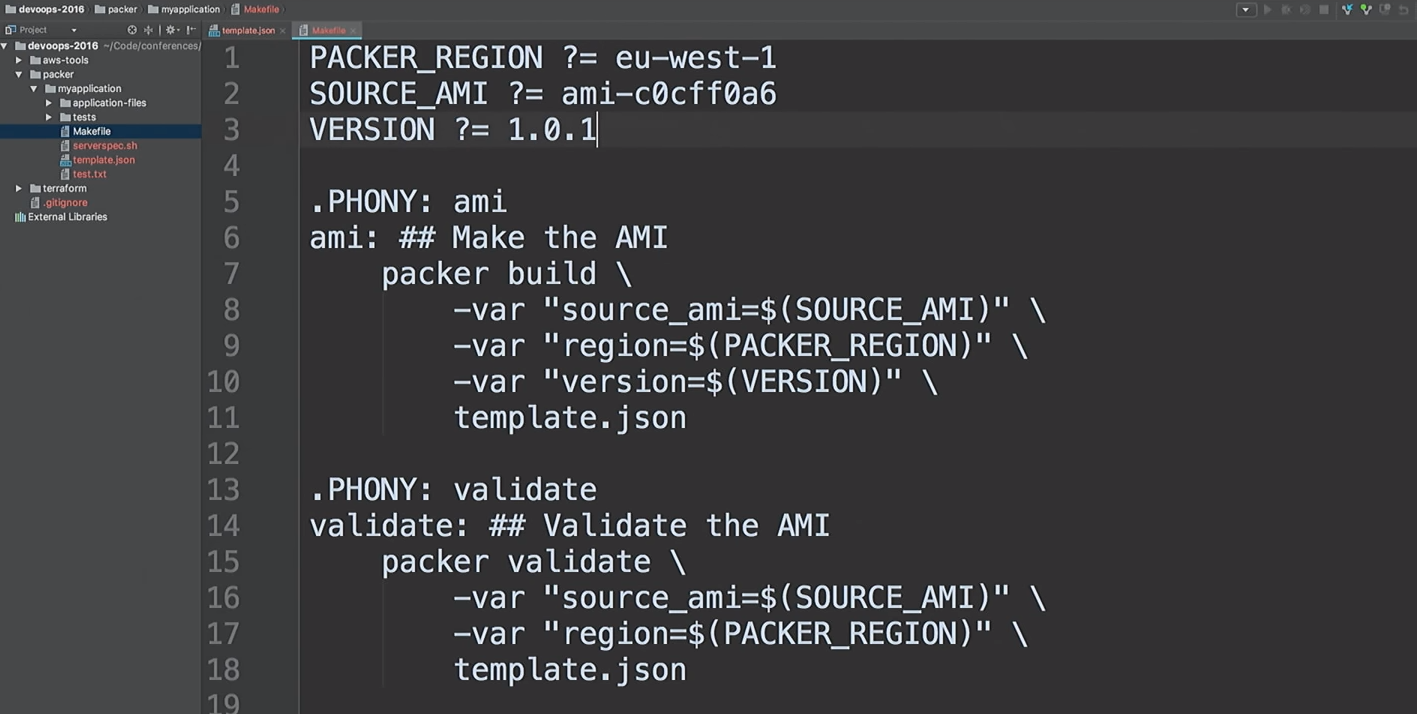
I'll just fix the version in files from 1.0.0 to 1.0.1 to show you the difference:
Return to the command line and launch the creation of AMI.
I do not like to run the same commands. I like to create AMIs quickly, so I use makefiles. Let's take a look at

This is my makefile. I even provided Help: I type

So, we are going to create a new AMI version 1.0.1.

Let's go back to Terraform.
I emphasize that this is not a production code. This is a demonstration. There are ways to do the same thing better.
I use Terraform modules everywhere. Since I no longer work on Hashicorp, so I can express my opinion about the modules. For me, the modules are at the level of encapsulation. For example, I like to encapsulate everything related to VPC: networks, subnets, routing tables, etc.
What happens inside? The developers who work with it may not care about it. They need to have a general understanding of how the cloud works, what a VPC is. But it is not necessary to delve into the details. Only people who really need to change the module should understand it.
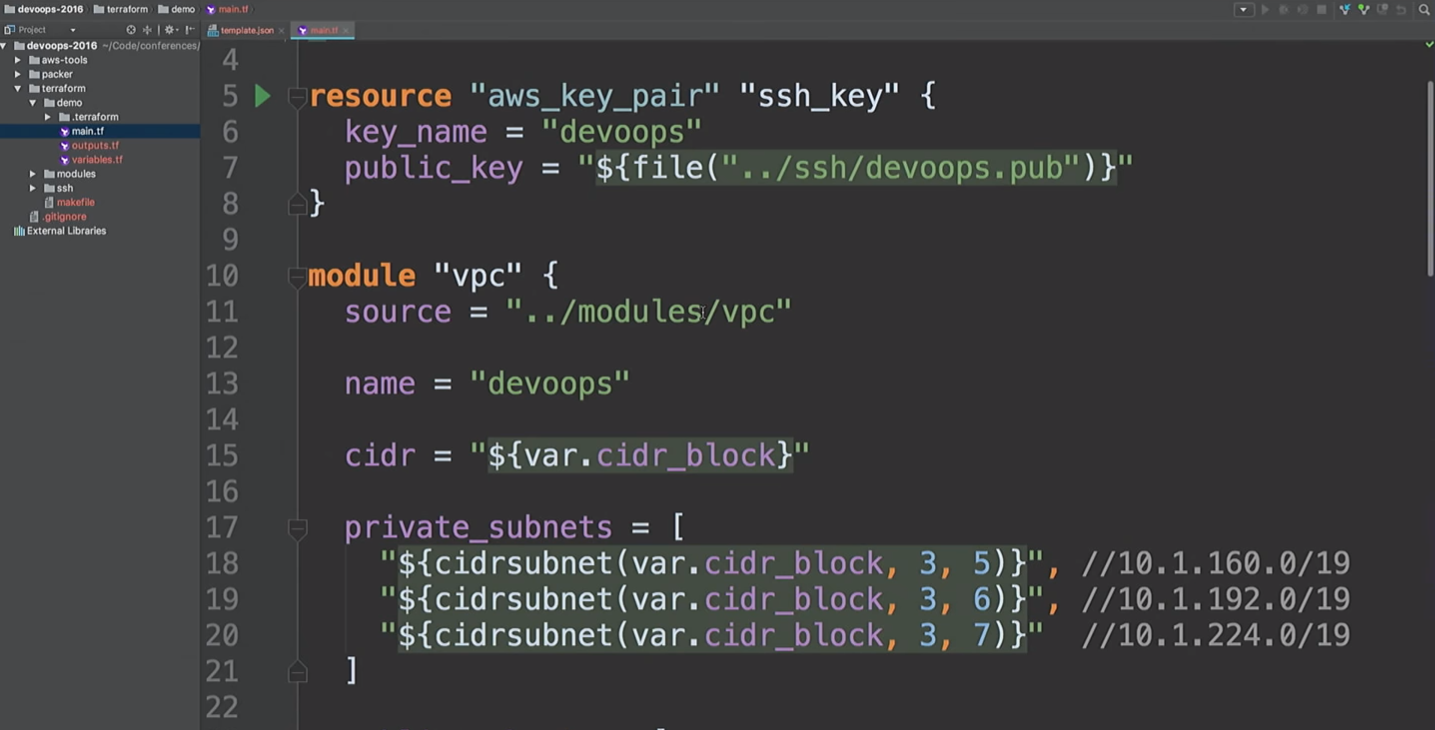

Here I am going to create an AWS resource and a VPC module. What's going on here?

We are going to create a VPN. Just do not use this VPN module. This is openVPN, which creates one AWS instance that does not have a certificate. It uses only the public IP address and is mentioned here only to show you that we can connect to the VPN. There are more convenient tools for creating a VPN. It took me about 20 minutes and two beers to write my own.


Then we create an
Let's return to this in a second.
I have already mentioned the accessibility zones. They differ for different AWS accounts. My US account in the East can have access to zones A, B, and D. Your AWS account can have access to B, C, and E. Thus, fixing these values in code, we will encounter problems. At Hashicorp, we assumed that we could create such data sources so that we could ask Amazon what is available to us. Under the hood, we request a description of accessibility zones, and then return a list of all zones for your account. Because of this, we can use data sources for AMI.
Now we get to the bottom of my demonstration. I created an auto scaling group in which three instances are running. By default, they all have version 1.0.0.
When we finish the new version of AMI, I will launch the Terraform configuration again, this will change the launch configuration, and the new service will receive the next version of code, etc. And we can manage it.

We see that the work of the Packer is over and we have a new AMI.
I go back to Amazon, refresh the page and see the second AMI.

Let's go back to Terraform.
Starting with version 0.10, Terraform has split providers into separate repositories. And the

Providers are loaded. We are ready to move forward.
Next, we have to run
The next step we want to build a graph.
Let's start with

Terraform will take the current local state and compare it with the AWS account, indicating the differences. In our case, it will create 35 new resources.
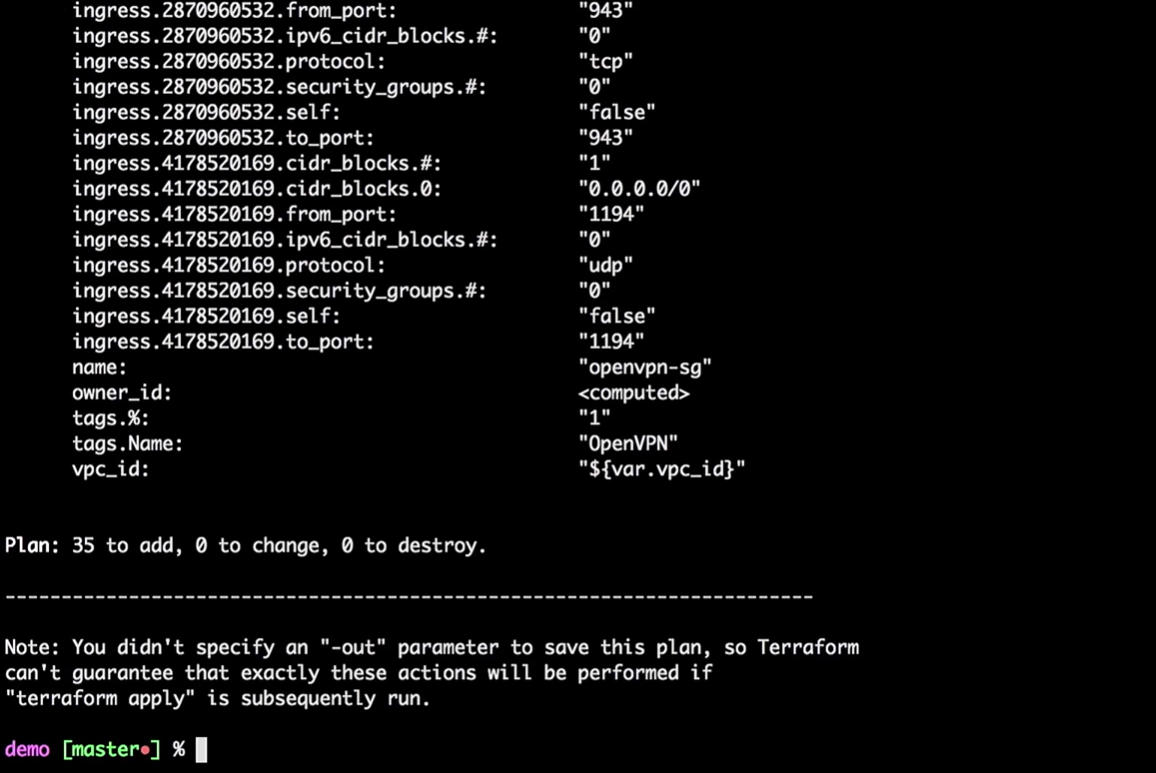
Now we will apply the changes:
You do not need to do all this from the local machine. These are just commands, passing variables to Terraform. You can transfer this process to CI tools.
If you want to move it to CI, you must use the remote state. I would like everyone who ever uses Terraform to work with a remote state. Please do not use local state.
One of my buddies noted that even after all the years of working with Terraform, he still discovers something new. For example, if you create an AWS instance, you need to give it a password, and it can save it in your state. When I worked in Hashicorp, we assumed that there would be a joint process that changes this password. So do not try to store everything locally. And then you can put all this in the CI tools.
So, the infrastructure for me is created.

Terraform can build a graph:
As I said, he builds a tree. In fact, it gives you the opportunity to assess what is happening in your infrastructure. He will show you the relationship between all the different parts - all nodes and edges. Since connections have directions, we are talking about a directed graph.
The graph will be a JSON list that can be saved in a PNG or DOC file.
Return to Terraform. We really create an auto scaling group.

The Auto scaling group has a capacity of 3.

An interesting question: can we use Vault to manage secrets in Terraform? Unfortunately no. No Vault data source for reading secrets in Terraform. There are other methods, such as environment variables. With their help, you do not need to enter secrets into the code, you can read them as environment variables.
So, we have some infrastructure facilities:
I log into my very secret VPN (do not hack my VPN).
The most important thing here is that we have three copies of the application. I, however, should have noted what version of the application is running on them. It is very important.
Everything really is behind the VPN:

If I take it (

Let me remind you, I am connected to a VPN. If I log out, the specified address will not be available.
We see version 1.0.0. And no matter how much we refresh the page, we get 1.0.0.
What happens if I change the version from 1.0.0 to 1.0.1 in the code?
Obviously, CI tools will provide you with the right version.
No manual updates! We are not perfect, we make mistakes and we can deliver with manual update version 1.0.6 instead of 1.0.1.
But let's move on to our version (1.0.1).
Terraform updates the state:
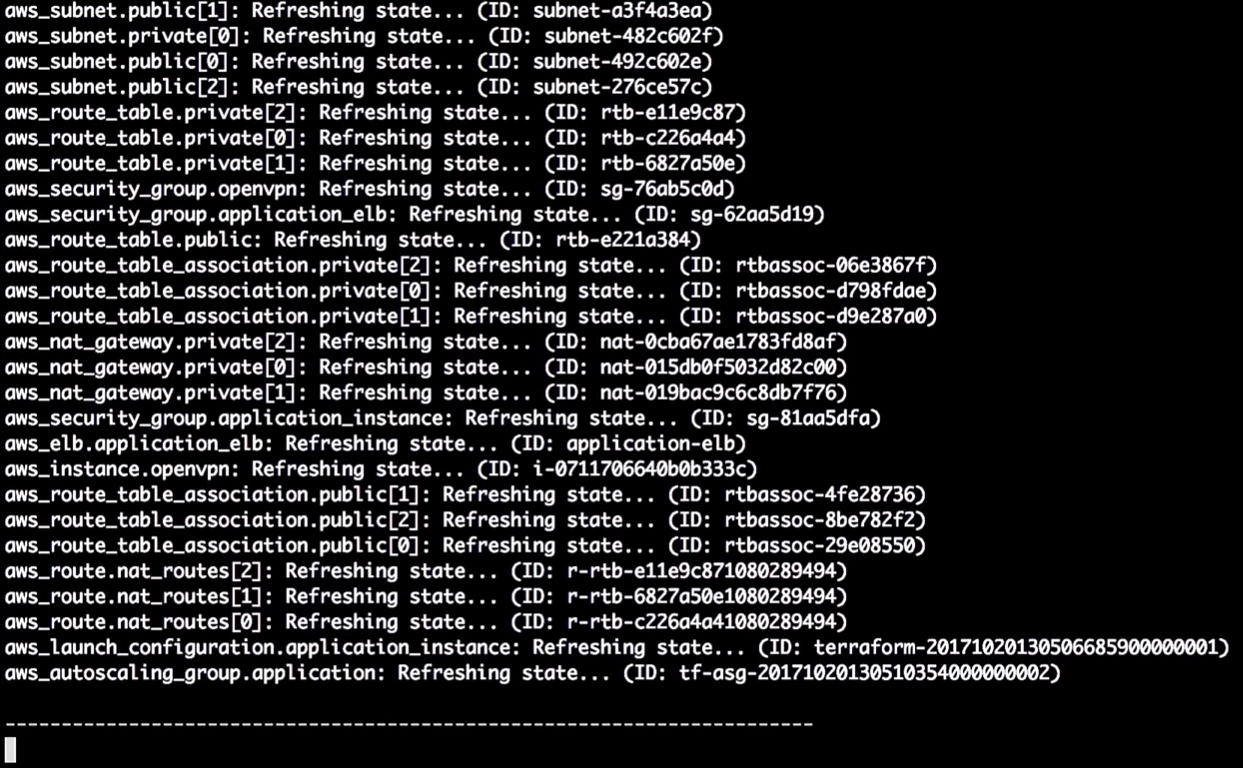

So at this moment he tells me that he is going to change the version in the configuration. Due to the change of the identifier, it will force the restart of the configuration, and the auto scaling group will change (this is necessary to enable the new launch configuration).
This does not change the running instances. This is really important. You can follow this process and test it without changing the instances in production.
Note: you must always create a new launch configuration before you destroy the old one, otherwise there will be an error.
Let's apply the changes:
Now back to AWS. When all changes are applied, we go to the auto scaling group.
Let's go to the AWS configuration. We see that there are three instances with one launch configuration. They are the same.
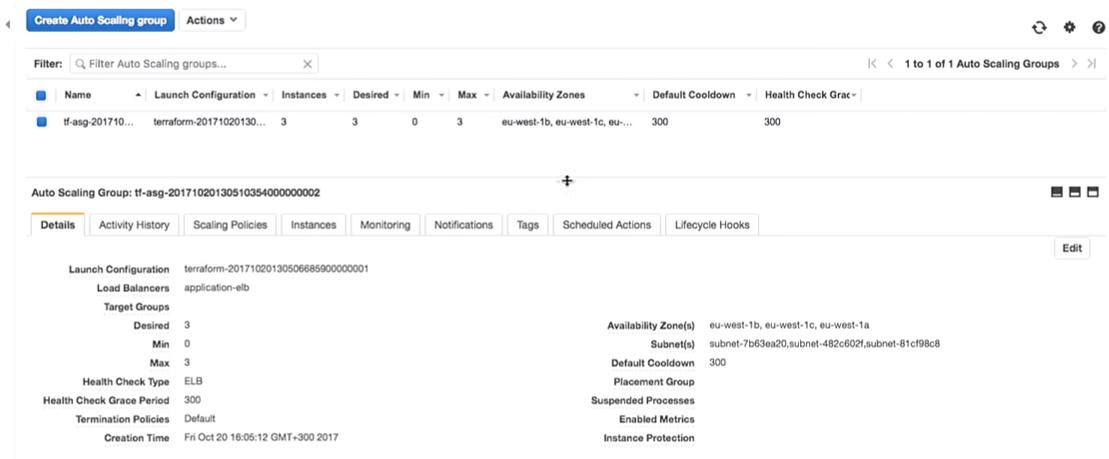
Amazon guarantees that if we want to run three instances of the service, they will indeed be running. That's why we pay them money.
Let's move on to the experiments.
A new launch configuration has been created. Therefore, if I delete one of the instances, the rest will not be damaged. It is important. However, if you use instances directly, while changing user data, it will destroy the “live” instances. Please, do not do that.
So, delete one of the instances:

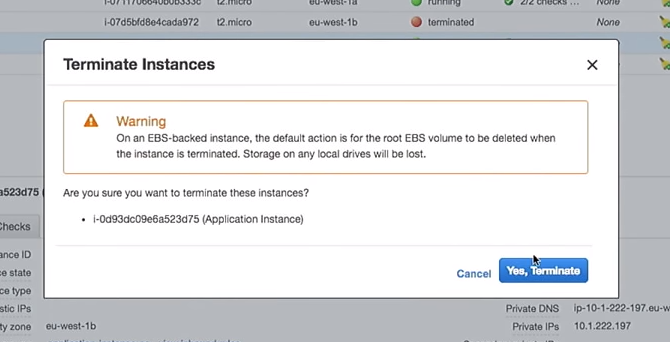
What happens in the auto scaling group when it turns off? In its place will be a new instance.
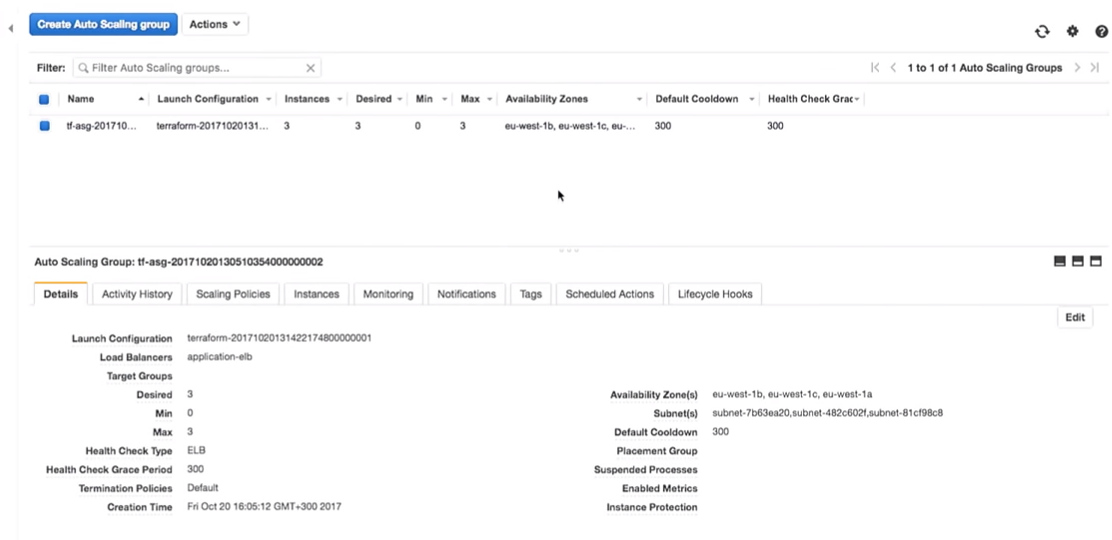
Here you find yourself in an interesting situation. The instance will be launched with the new configuration. That is, in the system you may have several different images (with different configurations). Sometimes it is better not to immediately delete the old startup configuration in order to connect as needed.
Here, everything becomes more interesting. Why not do it with scripts and CI tools, rather than manually, as I show? There are tools that can do this, such as the excellent AWS-missing-tools on GitHub.

And what does this tool do? This bash script, which runs through all instances in the load balancer, destroys them one by one, ensuring the creation of new ones in their place.
If I lost one of my instances with version 1.0.0 and a new one appeared - 1.1.1, I want to kill all 1.0.0, transferring everything to a new version. Because I always move forward. Let me remind you, I do not like it when the application server lives for a long time.
In one of the projects, every seven days I had a control script that would destroy all instances in my account. So the server was no more than seven days. Another thing (my favorite) is to mark servers as “stained” with SSH in a box and destroy them every hour using a script — we don’t want people to do it manually.
Such control scripts allow you to always have the latest version with bug fixes and security updates.
You can use the script just by running:
You can do this in QA or in production. You can even do this in your local AWS account. You do whatever you want, each time using the same mechanism.
Let's go back to Amazon. We have a new instance:

By refreshing the page in the browser, where we previously saw version 1.0.0, we get:

The interesting thing is that since we created the AMI creation script, we can test the creation of AMI.
There are some great tools, such as ServerScript or Serverspec.
Serverspec allows you to create Ruby-style specifications to check how your application server looks. For example, below I give a test that verifies that nginx is installed on the server.
Nginx must be installed and running on the server and listen to port 80. You can say that user X must be available on the server. And you can put all these tests in their place. That way, when you create an AMI, the CI tool can check if the AMI is appropriate for a given purpose. You will know that AMI is ready for production.
Mary Poppendieck is probably one of the most amazing women I have ever heard of. At one time, she talked about how lean software development has evolved over the years. And how it was connected with 3M in the 60s, when the company really was engaged in lean development.
And she asked the question: How long will your organization need to deploy changes associated with a single line of code? Can you make this process reliable and easy to repeat?
As a rule, this question has always concerned the software code. How long will it take me to fix one mistake in this application when deploying to production? But there is no reason why we cannot use the same question as applied to infrastructure or databases.
I worked for a company called OpenTable. In it we called it the duration of the cycle. And in OpenTable, she was seven weeks. And this is relatively good. I know companies that need months when they send a code in production. At OpenTable, we reviewed the process for four years. It took a lot of time, since the organization is large - 200 people. And we reduced the cycle time to three minutes. This was possible thanks to the measurements of the effect of our transformations.
Now everything is scripted. We have so many tools and examples, there is GitHub. So take ideas from conferences like DevOops, embed in your organization. Do not try to implement everything. Take one tiny thing and sell it. Show it to someone. The effect of a small change can be measured, measured and moved on!
The material is based on Paul Stack’s speech at our DevOops 2017 autumn conference . Paul is an infrastructure developer who used to work at HashiCorp and participated in the development of tools used by millions of people (for example, Terraform). He often speaks at conferences and communicates practice from the leading edge of CI / CD implementations, the principles of proper organization of operations-parts, and is able to clearly communicate why administrators do this at all. Further in the article the narration is conducted in the first person.
So let's start right away with a few key findings.
Long-lasting servers - sucks
')
I previously worked in an organization where we deployed Windows Server 2003 back in 2008, and today they are still in production. And such a company is not alone. Using remote desktop on these servers, they install software on them manually by downloading binary files from the Internet. This is a very bad idea, because the servers are not typical. You cannot guarantee that the same thing happens in production as in your development environment, in an intermediate environment, in a QA environment.
Immutable infrastructure
In 2013, an article appeared in Chad Foiler’s blog “Throw away your servers and burn the code: unchanging infrastructure and disposable components” (Chad Foiler “Trash your servers and burn your infrastructure and disposable components” ). This is a conversation mostly about the fact that unchanging infrastructure is the way forward. We have created an infrastructure, and if we need to change it, we create a new infrastructure. This approach is very common in the cloud, because here it is fast and cheap. If you have physical data centers, it is a bit more complicated. Obviously, if you run data center virtualization, everything becomes easier. However, if you still run physical servers every time, it takes a little longer to enter a new one than to change an existing one.
One-time infrastructure
According to functional programmers, “unchangeable” is actually the wrong term for this phenomenon. Because to be truly immutable, your infrastructure needs a read-only file system: no files will be written locally, no one will be able to use SSH or RDP, etc. Thus, it seems that the infrastructure is actually not immutable.
Terminology has been discussed on Twitter for six or even eight days by several people. As a result, they agreed that “one-time infrastructure” is a more appropriate formulation. When the life cycle of a “one-time infrastructure” ends, it can be easily destroyed. You do not need to hold on to it.
I will give an analogy. Cows on farms are usually not considered as pets.
When you have cattle on your farm, you do not give it individual names. Each individual has a number and tag. Same with servers. If you still have production servers manually created in 2006, they have meaningful names, for example, “SQL database on production 01”. And they have a very specific meaning. And if one of the servers falls, hell begins.
If one of the animal herds dies, the farmer simply buys a new one. This is the "one-time infrastructure."
Continuous delivery
So how to combine this with Continuous Delivery?
Everything that I am talking about now exists for quite some time. I'm just trying to combine the ideas of infrastructure development and software development.
Software developers have been practicing continuous delivery and continuous integration for a long time. For example, Martin Fowler ( Martin Fowler ) wrote about continuous integration in his blog in the early 2000s. Jez Humble has been pushing for a continuous supply for a long time.
If you take a closer look, there is nothing created specifically for the software source code. There is a standard definition from Wikipedia: continuous delivery is a set of practices and principles aimed at creating, testing and releasing software as quickly as possible .
The definition does not speak about web applications or APIs, it is about software as a whole. Creating a working software requires many pieces of the puzzle. In this way, you can also practice continuous delivery for infrastructure code in the same way.
Development of infrastructure and applications are pretty close directions. And people who write application code also write infrastructure code (and vice versa). These worlds are beginning to unite. There is no longer such a separation and specific traps of each of the worlds.
Continuous Delivery Principles and Practices
Continuous delivery has a number of principles:
- The software release / deployment process must be repeatable and reliable.
- Automate everything!
- If a procedure is difficult or painful, do it more often.
- Keep everything in a version control system.
- Made - means "released".
- Integrate work with quality!
- Everyone is responsible for the release process.
- Increase continuity.
But more importantly, continuous delivery has four practices. Take them and transfer directly to the infrastructure:
- Create binary files only once. Create your server once. Here we are talking about “disposability” from the very beginning.
- Use the same deployment mechanism in each environment. Do not practice different deploy in development and production. You must use the same path in each environment. It is very important.
- Test your patch. I have created many applications. I created a lot of problems because I did not follow the deployment mechanism. You should always check what happens. And I'm not saying that you should spend five or six hours on extensive testing. Enough "smoke test". You have a key part of the system that, as you know, allows you and your company to make money. Do not be lazy to start testing. If you do not do this, there may be interruptions that will cost your company money.
- And finally, the most important thing. If something breaks, stop and fix it immediately! You cannot let the problem grow and get worse and worse. You need to fix this. This is really important.
Has anyone read the book "Continuous Delivery" ?
I am sure your companies will pay you a copy that you can transfer within the team. I am not saying that you should sit down and spend the day off reading it. If you do, you probably want to leave IT. But I recommend periodically learning small pieces of a book, digesting them and thinking about how to transfer this to your environment, to your culture and to your process. One small piece at a time. Because continuous delivery is a conversation about continuous improvement. It’s not easy to sit in the office with your colleagues and boss and start a conversation with the question: “How will we introduce a continuous supply?”, Then write 10 things on the blackboard and in 10 days understand that you implemented it. It takes a lot of time, causes a lot of protests, as the culture changes as it is introduced.
Today we will use two tools: Terraform and Packer (both developed by Hashicorp). A further story will be about why we should use Terraform and how to integrate it into our environment. I do not accidentally talk about these two tools. Until recently, I also worked at Hashicorp. But even after I left Hashicorp, I still contribute to the code of these tools, because I actually find them very useful.
Terraform supports interaction with providers. Providers are clouds, Saas services, etc.
Within each cloud service provider there are several resources, such as a subnet, VPC, load balancer, etc. With DSL (domain-specific language), you specify Terraform what your infrastructure will look like.
Terraform uses graph theory.
You probably know graph theory. Nodes are parts of our infrastructure, such as a load balancer, subnet, or VPC. Ribs are the relationships between these systems. This is all that I personally consider necessary to know about graph theory for using Terraform. The rest is left to the experts.
Terraform actually uses a directed graph, because it knows not only the relationship, but also their order: that A (suppose A - VPC) must be set before B, which is a subnet. And B must be created before C (instance), because there is a prescribed order for creating abstractions in Amazon or any other cloud.
Further information on this topic is available on YouTube by Paul Henze (Paul Hinze), who still works at Hashicorp as infrastructure director. The link is a great conversation about infrastructure and graph theory.
Practice
Write the code, it is much better than discussing the theory.
I previously created AMI (Amazon Machine Images). To create them, I use Packer and I'm going to show you how to do it.
AMI is an instance of a virtual server in Amazon, it is predefined (in terms of configuration, applications, etc.) and is created from an image. I love that I can create new AMIs. In essence, AMI are my Docker containers.
So, I have an AMI, they have an ID. Going to the Amazon interface, we see that we have only one AMI and nothing more:
I can show you what is in this AMI. Everything is very simple.
I have a JSON file template:
{ "variables": { "source_ami": "", "region": "", "version": "" }, "builders": [{ "type": "amazon-ebs", "region": "{{user 'region'}}", "source_ami": "{{user 'source_ami'}}", "ssh_pty": true, "instance_type": "t2.micro", "ssh_username": "ubuntu", "ssh_timeout": "5m", "associate_public_ip_address": true, "ami_virtualization_type": "hvm", "ami_name": "application_instance-{{isotime \"2006-01-02-1504\"}}", "tags": { "Version": "{{user 'version'}}" } }], "provisioners": [ { "type": "shell", "start_retry_timeout": "10m", "inline": [ "sudo apt-get update -y", "sudo apt-get install -y ntp nginx" ] }, { "type": "file", "source": "application-files/nginx.conf", "destination": "/tmp/nginx.conf" }, { "type": "file", "source": "application-files/index.html", "destination": "/tmp/index.html" }, { "type": "shell", "start_retry_timeout": "5m", "inline": [ "sudo mkdir -p /usr/share/nginx/html", "sudo mv /tmp/index.html /usr/share/nginx/html/index.html", "sudo mv /tmp/nginx.conf /etc/nginx/nginx.conf", "sudo systemctl enable nginx.service" ] } ] } We have variables that we pass, and Packer has a list of so-called Builders for different areas; many of them. Builder uses a special AMI source, which I pass to the AMI identifier. I give him an SSH username and password, and also indicate if he needs a public IP address so that people can access it from outside. In our case, this does not really matter, because this is the AWS instance for the Packer.
We also set AMI name and tags.
You do not need to parse this code. He is here only to show you how he works. The most important part here is the version. It will become relevant later when we enter Terraform.
After the builder calls an instance, provisioners run on it. I actually install NCP and nginx to show you what I can do here. I copy some files and just configure the nginx configuration. Everything is very simple. Then I activate nginx so that it starts when the instance is started.
So, I have an application server, and it works. I can use it in the future. However, I always check my Packer templates. Because it is a JSON configuration where you may encounter some problems.
To do this, I run the command:
make validate
I get the answer that the Packer template was verified successfully:
This is just a command, so I can connect it to the CI tool (anyone). In fact, it will be a process: if the developer changes the template, a pull request is formed, the CI tool checks the request, performs the equivalent of the template validation, and publishes the template if the validation is successful. All this can be combined in the "Master".
We get the stream for AMI templates - you just need to raise the version.
Suppose a developer has created a new version of AMI.
I'll just fix the version in files from 1.0.0 to 1.0.1 to show you the difference:
<html> <head> <tittle>Welcome to DevOops!</tittle> </head> <body> <h1>Welcome!</h1> <p>Welcome to DevOops!</p> <p>Version: 1.0.1</p> </body> </html> Return to the command line and launch the creation of AMI.
I do not like to run the same commands. I like to create AMIs quickly, so I use makefiles. Let's take a look at
cat in my makefile:cat Makefile
This is my makefile. I even provided Help: I type
make and press the tab, and it shows me all the target.So, we are going to create a new AMI version 1.0.1.
make ami
Let's go back to Terraform.
I emphasize that this is not a production code. This is a demonstration. There are ways to do the same thing better.
I use Terraform modules everywhere. Since I no longer work on Hashicorp, so I can express my opinion about the modules. For me, the modules are at the level of encapsulation. For example, I like to encapsulate everything related to VPC: networks, subnets, routing tables, etc.
What happens inside? The developers who work with it may not care about it. They need to have a general understanding of how the cloud works, what a VPC is. But it is not necessary to delve into the details. Only people who really need to change the module should understand it.
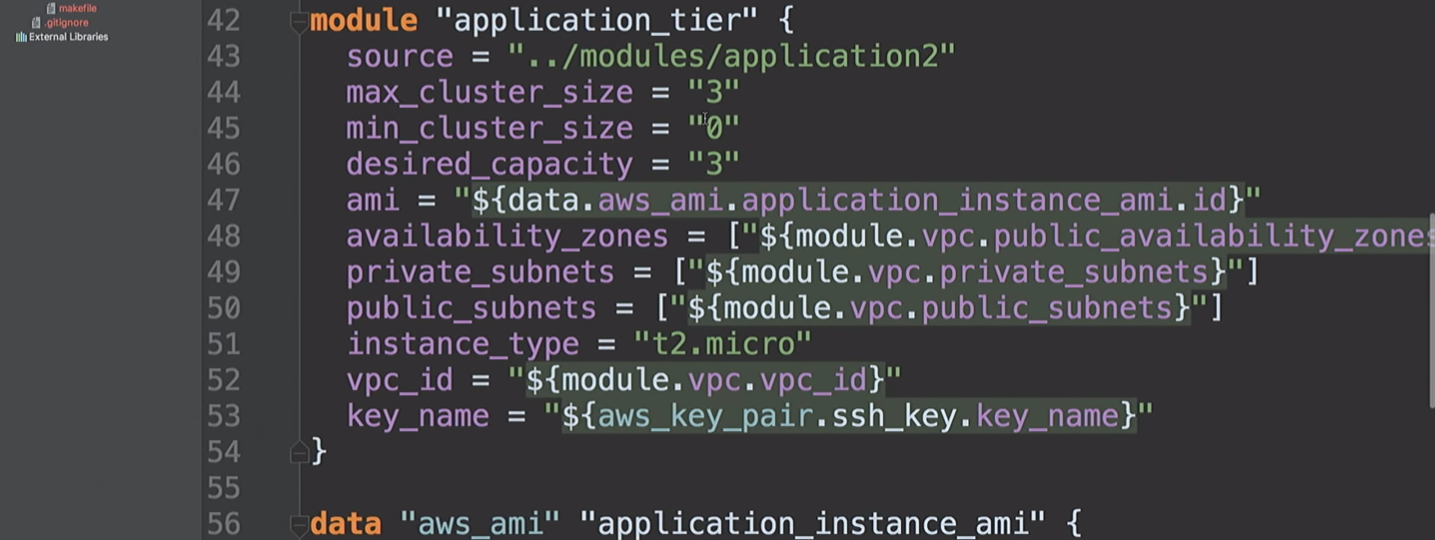
Here I am going to create an AWS resource and a VPC module. What's going on here?
cidr_block top-level cidr_block taken and three private subnets and three public subnets are created. Next, the acailability_zones list is taken. But we do not know what these access zones are.We are going to create a VPN. Just do not use this VPN module. This is openVPN, which creates one AWS instance that does not have a certificate. It uses only the public IP address and is mentioned here only to show you that we can connect to the VPN. There are more convenient tools for creating a VPN. It took me about 20 minutes and two beers to write my own.
Then we create an
application_tier , which is an auto scaling group - a load balancer. Some startup configuration is based on AMI-ID, and it combines several subnets and availability zones, and also uses an SSH key.Let's return to this in a second.
I have already mentioned the accessibility zones. They differ for different AWS accounts. My US account in the East can have access to zones A, B, and D. Your AWS account can have access to B, C, and E. Thus, fixing these values in code, we will encounter problems. At Hashicorp, we assumed that we could create such data sources so that we could ask Amazon what is available to us. Under the hood, we request a description of accessibility zones, and then return a list of all zones for your account. Because of this, we can use data sources for AMI.
Now we get to the bottom of my demonstration. I created an auto scaling group in which three instances are running. By default, they all have version 1.0.0.
When we finish the new version of AMI, I will launch the Terraform configuration again, this will change the launch configuration, and the new service will receive the next version of code, etc. And we can manage it.
We see that the work of the Packer is over and we have a new AMI.
I go back to Amazon, refresh the page and see the second AMI.
Let's go back to Terraform.
Starting with version 0.10, Terraform has split providers into separate repositories. And the
init terraform command gets a copy of the provider you need to run.Providers are loaded. We are ready to move forward.
Next, we have to run
terraform get - load the necessary modules. They are now on my local machine. So Terraform will get all the modules at the local level. In general, modules can be stored in their own repositories on GitHub or elsewhere. That is why I talked about the VPC module. You can give the networker team access to make changes. And this is the API for the development team to work with them. Really helpful.The next step we want to build a graph.
Let's start with
terraform plan
Terraform will take the current local state and compare it with the AWS account, indicating the differences. In our case, it will create 35 new resources.
Now we will apply the changes:
terraform apply
You do not need to do all this from the local machine. These are just commands, passing variables to Terraform. You can transfer this process to CI tools.
If you want to move it to CI, you must use the remote state. I would like everyone who ever uses Terraform to work with a remote state. Please do not use local state.
One of my buddies noted that even after all the years of working with Terraform, he still discovers something new. For example, if you create an AWS instance, you need to give it a password, and it can save it in your state. When I worked in Hashicorp, we assumed that there would be a joint process that changes this password. So do not try to store everything locally. And then you can put all this in the CI tools.
So, the infrastructure for me is created.
Terraform can build a graph:
terraform graph
As I said, he builds a tree. In fact, it gives you the opportunity to assess what is happening in your infrastructure. He will show you the relationship between all the different parts - all nodes and edges. Since connections have directions, we are talking about a directed graph.
The graph will be a JSON list that can be saved in a PNG or DOC file.
Return to Terraform. We really create an auto scaling group.
The Auto scaling group has a capacity of 3.
An interesting question: can we use Vault to manage secrets in Terraform? Unfortunately no. No Vault data source for reading secrets in Terraform. There are other methods, such as environment variables. With their help, you do not need to enter secrets into the code, you can read them as environment variables.
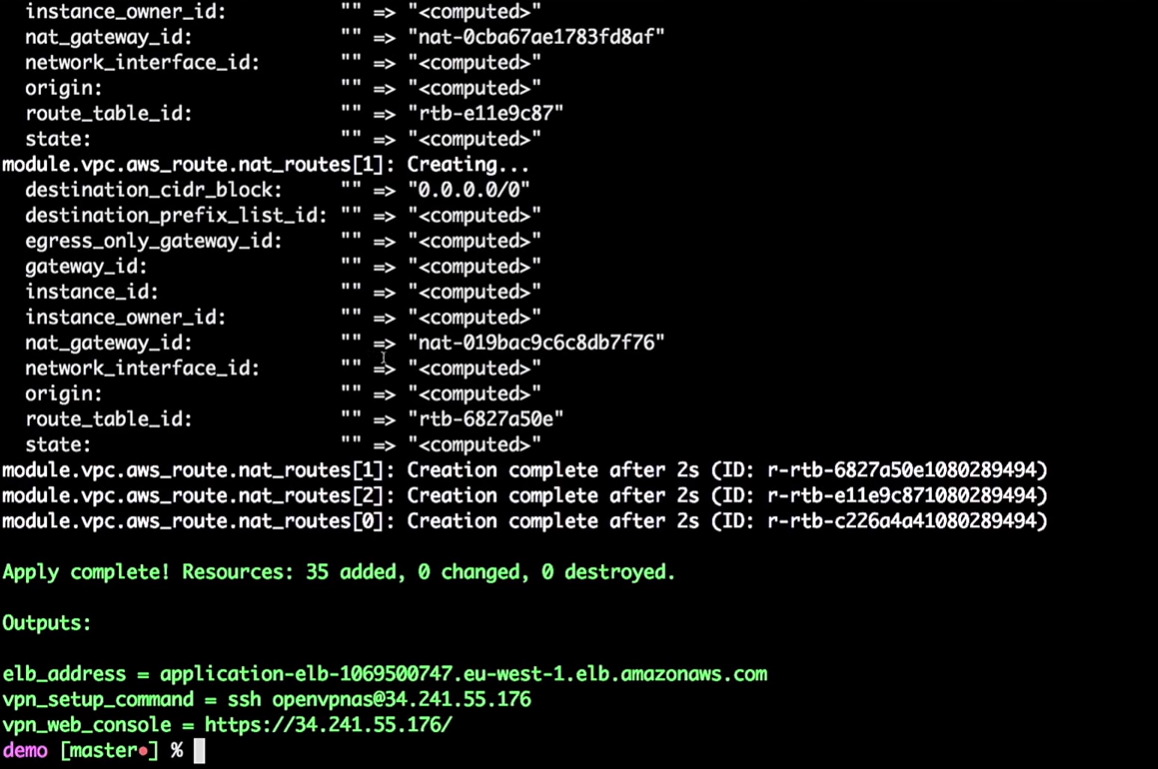
So, we have some infrastructure facilities:
I log into my very secret VPN (do not hack my VPN).
The most important thing here is that we have three copies of the application. I, however, should have noted what version of the application is running on them. It is very important.
Everything really is behind the VPN:
If I take it (
application-elb-1069500747.eu-west-1.elb.amazonaws.com ) and paste it into the address bar of the browser, I get the following:Let me remind you, I am connected to a VPN. If I log out, the specified address will not be available.
We see version 1.0.0. And no matter how much we refresh the page, we get 1.0.0.
What happens if I change the version from 1.0.0 to 1.0.1 in the code?
filter { name = "tag:Version" values = ["1.0.1"] } Obviously, CI tools will provide you with the right version.
No manual updates! We are not perfect, we make mistakes and we can deliver with manual update version 1.0.6 instead of 1.0.1.
filter { name = "tag:Version" values = ["1.0.6"] } But let's move on to our version (1.0.1).
terraform plan
Terraform updates the state:
So at this moment he tells me that he is going to change the version in the configuration. Due to the change of the identifier, it will force the restart of the configuration, and the auto scaling group will change (this is necessary to enable the new launch configuration).
This does not change the running instances. This is really important. You can follow this process and test it without changing the instances in production.
Note: you must always create a new launch configuration before you destroy the old one, otherwise there will be an error.
Let's apply the changes:
terraform apply
Now back to AWS. When all changes are applied, we go to the auto scaling group.
Let's go to the AWS configuration. We see that there are three instances with one launch configuration. They are the same.
Amazon guarantees that if we want to run three instances of the service, they will indeed be running. That's why we pay them money.
Let's move on to the experiments.
A new launch configuration has been created. Therefore, if I delete one of the instances, the rest will not be damaged. It is important. However, if you use instances directly, while changing user data, it will destroy the “live” instances. Please, do not do that.
So, delete one of the instances:
What happens in the auto scaling group when it turns off? In its place will be a new instance.
Here you find yourself in an interesting situation. The instance will be launched with the new configuration. That is, in the system you may have several different images (with different configurations). Sometimes it is better not to immediately delete the old startup configuration in order to connect as needed.
Here, everything becomes more interesting. Why not do it with scripts and CI tools, rather than manually, as I show? There are tools that can do this, such as the excellent AWS-missing-tools on GitHub.
And what does this tool do? This bash script, which runs through all instances in the load balancer, destroys them one by one, ensuring the creation of new ones in their place.
If I lost one of my instances with version 1.0.0 and a new one appeared - 1.1.1, I want to kill all 1.0.0, transferring everything to a new version. Because I always move forward. Let me remind you, I do not like it when the application server lives for a long time.
In one of the projects, every seven days I had a control script that would destroy all instances in my account. So the server was no more than seven days. Another thing (my favorite) is to mark servers as “stained” with SSH in a box and destroy them every hour using a script — we don’t want people to do it manually.
Such control scripts allow you to always have the latest version with bug fixes and security updates.
You can use the script just by running:
aws-ha-relesae.sh -a my-scaling-group
-a is your auto scaling group. The script will go through all instances of your auto scaling group and replace it. It can be run not only manually, but also from the CI tool.You can do this in QA or in production. You can even do this in your local AWS account. You do whatever you want, each time using the same mechanism.
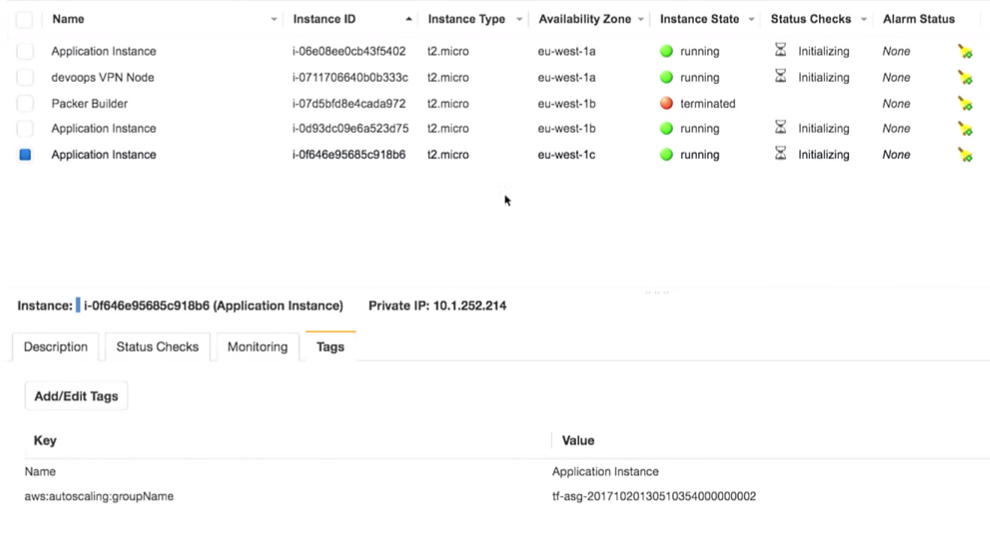
Let's go back to Amazon. We have a new instance:
By refreshing the page in the browser, where we previously saw version 1.0.0, we get:
The interesting thing is that since we created the AMI creation script, we can test the creation of AMI.
There are some great tools, such as ServerScript or Serverspec.
Serverspec allows you to create Ruby-style specifications to check how your application server looks. For example, below I give a test that verifies that nginx is installed on the server.
require 'spec_helper' describe package('nginx') do it { should be_installed } end describe service('nginx') do it { sould be_enabled } it { sould be_running } end describe port(80) do it { should be_listening } end Nginx must be installed and running on the server and listen to port 80. You can say that user X must be available on the server. And you can put all these tests in their place. That way, when you create an AMI, the CI tool can check if the AMI is appropriate for a given purpose. You will know that AMI is ready for production.
Instead of conclusion
Mary Poppendieck is probably one of the most amazing women I have ever heard of. At one time, she talked about how lean software development has evolved over the years. And how it was connected with 3M in the 60s, when the company really was engaged in lean development.
And she asked the question: How long will your organization need to deploy changes associated with a single line of code? Can you make this process reliable and easy to repeat?
As a rule, this question has always concerned the software code. How long will it take me to fix one mistake in this application when deploying to production? But there is no reason why we cannot use the same question as applied to infrastructure or databases.
I worked for a company called OpenTable. In it we called it the duration of the cycle. And in OpenTable, she was seven weeks. And this is relatively good. I know companies that need months when they send a code in production. At OpenTable, we reviewed the process for four years. It took a lot of time, since the organization is large - 200 people. And we reduced the cycle time to three minutes. This was possible thanks to the measurements of the effect of our transformations.
Now everything is scripted. We have so many tools and examples, there is GitHub. So take ideas from conferences like DevOops, embed in your organization. Do not try to implement everything. Take one tiny thing and sell it. Show it to someone. The effect of a small change can be measured, measured and moved on!
Paul Stack will arrive in St. Petersburg at the DevOops 2018 conference with the report “Sustainable system testing with Chaos” . Paul will talk about the Chaos Engineering methodology and show how to use this methodology on real projects.
Source: https://habr.com/ru/post/420661/
All Articles