As I wrote and defended a degree in DEVOPS and engineering practices in 1C from scratch
Foreword
It all started more than 2 years ago, and I switched to the 4th year of the specialty "Business Informatics" of the Tomsk State University of Control Systems and Radio Electronics (TUSUR). Until the end of the university there was not much time, and the prospect of writing a diploma already loomed before my eyes. The idea of buying finished work was not considered. I really wanted to do something myself. There were a lot of options for graduation projects: configuration projects for automating the production needs of the company and the project for implementing Document management on its own into 3 territorial units and over 500 active users and introducing EDM. In short, a lot of everything was in my head, but none of this inspired. And this was the main thing.
At that time I was working in a reputable company and for the affairs of the service I met one cool programmer and generally a good man Andrei Shcheglov (Hello Andrei!) And how = during a conversation he asked me if I heard anything about OneScript and scripting language gherkin. To which he received the answer, no, I did not hear. Naturally, the evening google / indexing and sleepless night led to the idea that here it is - the world of the unknown. But the idea that this could be the topic of a thesis has not yet been born. Routine terms of reference constituted the usual work in the Configurator 1C in a task-by-way manner, as you understand, with manual testing and did not allow fully immersing yourself in the new approach in the 1C world.
Unfamiliar concepts
The first difficulty I encountered was an incredible amount of different terminologies and tools that I hadn’t heard about at all - since I was a “typical student” at that moment (holivar starts at that moment ...) Especially not owning any other programming languages, and besides, the methodology of large IT was absolutely unfamiliar to me, I had to jump from topic to topic in order to at least somehow fill my glossary.
Practically at the same moment I (we, and my colleagues) faced a rather specific problem. They accepted the software module from the contractor, checked on a copy. It seems everything works. But since there was a lot of work, they signed an act of completed work and threw it into productive. Everything was good for six months, while the data in this subsystem did not exceed the allowable. And very strange things began to happen. The document from the module began to occur for 5-10 minutes, a bunch of errors appeared, well, and so on. View of the program code horrified (do not ask why it was not done before when accepting ...). The number of nested loops was just beyond reasonable. The only request in the fourth cycle and address through 4 points were trifles, enumeration of all previous documents to fill out the current document, 10-fold copy-paste of the same block and much more.
Example of nesting:

Duplicate fields in the layout:

And to fill these fields, 14-fold kopispast.
Cycle start:
')

And until the variable FF reaches 15:

Well, a bunch of other equally unique works of art.
Suddenly, I remembered that for OneScript there is a simple library for calculating the "cyclomaticity" of the module (1) (the complexity of the module or method). Found, calculated. Received a value of 163 units, with an acceptable value of no more than 10. And I came to the conclusion that acceptance testing of the program code should be mandatory and it should be automatic and continuous. Then I learned about Continuous Inspection - and as it turned out in 2006, IBM made (2) a publication on this topic.
The rule to avoid excessive complexity in miscrosoft even has a special CA1502 code https://msdn.microsoft.com/ru-ru/library/ms182212.aspx
Presentation of the concept and tool for analyzing java projects based on ant - https://www.ibm.com/developerworks/library/j-ap08016/j-ap08016-pdf.pdf
Further more. Probably many working in large companies encountered the problem of deploying a copy of the working base on the local developer’s machine. When this base weighs 5-10 GB is not a problem, and when it only weighs almost a terabyte in the backup, this is serious. As a result, in order to deploy a fresh copy, 5-6 hours of working time was spent. When I got tired of it, I started using a very good tool 1C-Deploy-and-CopyDB (Anton, thank you!) Then I realized that automation is great.
Then there were other tasks, for example, regular updating of the main and distributed database from the repository at night, testing forms, script tests, etc. Something from this was realized, but something was not.
But all this was necessary only for me. When searching for like-minded people in your city, it practically failed. They are not. Although it is terribly strange, since the problems are typical. At that moment I already knew that I wanted to write my thesis on this topic. But what to write - did not know. Therefore, I had to connect to the community as not just a reader, but at least a writer and a questioner. The main places where you can ask questions were
Github projects:
• https://github.com/silverbulleters/add
• https://github.com/oscript-library/opm
• https://github.com/EvilBeaver/OneScript
• https://github.com/silverbulleters/vanessa-runner/
XDD forum:
Well, as a means of fast communication - profile groups in Gitter
Began collecting material. By the will of fate, I managed to get in touch on the XDD forum with Alexey Lustin, alexey-lustin (Hello Alexey!), And tell me about my diploma idea. I was surprised to hear that they received an approving comment and even an invitation to undergo a pre-diploma practice at Silver Bullet. It was already a victory. For several hours we invented the topic and content of the diploma. Set tasks for practical work. Received the head of the graduation project from the company - Arthur Ayuhanov (Hi Arthur!). As a young Padawan, he got access to the video course of the release engineer and the opportunity to get Nikita Gryzlov (Hi Nikita) unlimitedly with his questions, for which he is very grateful.
Eventually:
The topic of the diploma is “Automated management of the life cycle of information systems - system and software engineering of solutions on the 1C: Enterprise platform in the context of continuous improvement of the quality of the production process”.

The purpose of the final qualifying work (WRC) is to identify the relationship of software tools and the description of the business process of the DevOps contour in the field of 1C.
The theoretical justification of the project was the standard of continuous improvement of the quality of service from ITIL 3.0, and as a practical object was chosen to build a contour of continuous integration for the new application solution that we developed - the personal account of the buyer. To do this, the GitLab source code server and the Jenkins build path were deployed. Run tests carried out on a dedicated server (Windows Slave). The configuration was unloaded from the 1C storage using the Gitsync library, revision 3.0
(currently located in the develop branch) already with the developments of Aleksey Khorev (hello Lech!) with a frequency of 30 minutes per develop branch. The reason for choosing this particular version was the ability to connect to the repository via the tcp protocol, which, unfortunately, did not support typical GitSync 2.x at that time. If changes were fixed in GitLab, the continuous integration loop run was automatically started.Since the budget of the entire event was zero, and it was impossible to build a full-fledged quality check of the program code without purchasing a module for SonarQube, the typical 1C syntax check was used as a simplified solution. Although one-time downloads were still made, and the results were obtained and analyzed. Additional checks for cyclomaticity and for the presence of reusable code were also used.
At the functional testing stage, two Vanessa-Behavior and XUnitFor1C frameworks were used in their combined version called Vanessa Automation Driven Development (Vanessa ADD). The first was used to start testing the expected behavior, and the second was to check the opening of the forms (smoke testing). The result of passing the continuous integration loop was automatically generated reports.
According to the results of testing, the release - the engineer decided to merge the develop and master branch, and started (manually) the third task - the publication of changes to the productive base. The productive base is not connected to the repository and is completely closed to manual changes. Updating is carried out only through delivery, and in automatic mode.
To describe the business process of the contour, an IDEF0 diagram was formed consisting of 4 consecutive blocks that form the contour passing. The error occurring during the passage of any of the stages interrupts the assembly process with notification of the release engineer and transfers control to block 5 of the assembly process, where reports are generated in the format ALLURE, JUNIT and of course cucumber.json.
IDEF0 Model Description
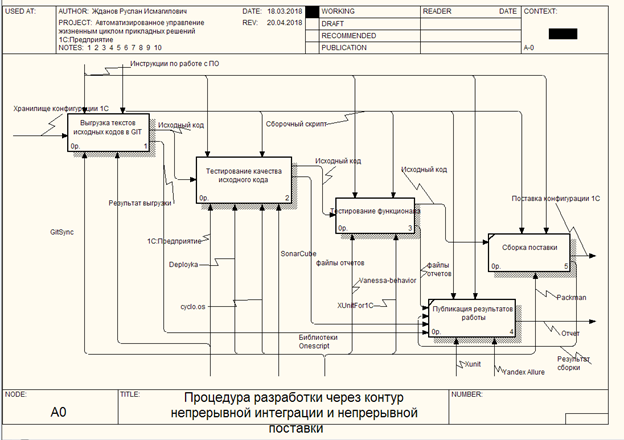
The process of "Unloading sources in GIT"
Input data (Input): - Configuration storage
Output data: - Source code
Control (Control): Software instructions, build script
Mechanism (Mechanism): 1C: Enterprise, Gitsync .
A prerequisite for the existence of the contour is the presence of source text files. From platform version 8.3.6, 1C has provided the ability to upload configuration source codes to files. It should be noted that this process may have several variants of execution, depending on the specifics of development in the IT department. In the current version, in order to simplify the process of transition of employees to the new methodology, integration was carried out with the current development process through the configuration repository and using the 1C configurator.
At the stage of executing the “Source unloading in GIT” process, the file and service information base 1C will be created; made it connected to the configuration storage under the service account; all changes for the current time are received (or the last commit in the repository); source codes were uploaded to the build directory; A commit has been made to the GIT version storage system; Changes are sent to the GitLab source server.
Process "Testing the quality of the source code"
Input (Input): - Source Code
Output data: - Source code
Control (Control): Software instructions, build script
Mechanism (Mechanism): 1C: Enterprise, Deployka , SonarQube , Cyclo.os - (unfortunately no links)
At the time of the start of this process, the source code is stored in the GitLab repository. With the help of the manager (assembly) script, it is received in the assembly directory. Using the 1C: Enterprise platform, the service information base is deployed on the basis of these source codes. Error analysis is performed by means of the platform. If during the analysis errors of the program code are detected that do not allow to collect the configuration, the process will be interrupted. The purpose of this step is to eliminate the loss of time for analyzing the program code of an inoperable configuration.
After checking for errors, the calculation of the cyclomatic complexity of the program code is started. An increase in this coefficient significantly affects debugging and analysis of program code. The maximum allowable value is 10. If exceeded, an exception is thrown, and the code is returned for revision.
The final step in analyzing the quality of the program code is checking for compliance with the development standards. For these purposes, the proposed scheme uses the SonarQube service and the 1C syntax support module from Silver Bulletin developed for it. According to the results of the analysis, the system calculates the technical debt value for each employee who posted the program code.
Process "Testing functionality"
Input (Input): - Source Code
Output data: - Source code
Control (Control): Software instructions, build script
Mechanism (Mechanism): 1C: Enterprise, Vanessa-Behavior, XunitFor1C .
In the development process, situations may occur that a new functionality may disrupt the work of already existing subsystems. This can manifest itself as the formation of exceptions, and the conclusion is not the expected result. For these purposes, the expected behavior of the system is tested.
Several development and testing methods are applicable for this circuit: TDD (Test Driven Development) and BDD (Behavior Driven Development)
At the time of writing the WRC, the Vanessa-bahavior framework , for TDD - XunitFor1C , was used to perform the tests according to the BDD Technique . At the moment they are united under one product Vanessa-ADD. Support for old products by the developer is discontinued. Test results are output to the Yandex Allure and Xunit report files.
Process "Build Delivery"
Input (Input): - Source Code
Output data: - Configuration delivery
Control (Control): Software instructions, build script
Mechanism (Mechanism): 1C: Enterprise, packman .
In this process, the final delivery of the configuration delivery is made for deployment to the target system. The verified source code is located in the develop branch of the GitLab source code repository. To form a delivery, it is necessary that changes from the develop branch appear in the master branch. This action can occur both manually and automatically and is governed by the requirements of the IT department using the CI / CD circuit. After the branches merge, the assembly process starts. To this end, a service information base is created again in the build directory, on the basis of existing sources, and then, using the 1C: Enterprise platform, the configuration delivery is formed and archived. Configuration delivery is the final product of the assembly process and is delivered to the customer via the established communication channels or installed directly into the productive information system.
The process "Publishing results"
Input data (Input): - Result of upload, report files
Output data: - Report
Control (Control): Software instructions, build script
Mechanism (Mechanism): Yandex Allure , Xunit .
During the process steps, the test tools create as a by-product report files in specific formats. The task of this process is to group, transform and publish for ease of data analysis. If an exception is raised at some stage of the assembly and if the necessary configuration is available, the system should automatically notify the contour administrator of any problems. This stage is carried out in post-processing of the assembly process and should be performed regardless of the results of previous processes.
For feedback, in addition to the mailing, integration with the Slack corporate manager was used, where all informational messages were sent about the build status, the appearance of new commits, the formation of backups, as well as monitoring the functioning of services both related to the DevOps circuit and 1C in whole
The results of my project was the defense of the WRC at the end of May of this year with the result “excellent”. Additionally, the methodological information on contour formation was updated.

General conclusions:
- The economic effect is possible only in the long term. From experience it has been noticed that when a project is launched, the implementation of engineering practices records a decrease in development productivity by 20-30% from the current level. This period is temporary and, as a rule, productivity returns to its original values after three to four months of operation. The decrease in performance is primarily due to the fact that the developer has to get used to the new requirements of development: writing scripts, tests, the formation of technical documentation.
- The stability of the productive information system has significantly increased due to the testing of program code. Guaranteed operation of critical subsystems is provided with coverage of scenario tests. Due to this, the risks of the company in a critical direction have decreased - prompt interaction with customers.
- The exclusion of dynamic corrections on the productive information base allowed us to plan development more constructively and to eliminate the ingress of program code to bypass the testing loop.
- Reduction of labor costs for maintenance of the information base, due to automation of the assembly circuit.
- The use of feedback through Slack allowed on-line monitoring and correction of system life cycle problems. According to the team, the use of the messenger is more convenient than the mailing list (although it is also present).
- The use of automated software code verification (Continuous Inspection) for compliance with development standards (SonarQube) forces developers to independently increase their competence, and correcting the identified technical debt directly while developing a software module is much faster, since there is no need to waste time on restoring the task context.
- - - .
- -, 1, . , 1.
, :
- , " 1. - , , ( 5 ).
- “ 1”. . ( , " ". ).
- CICD 1 , 5.5.0 .
, , 1 , DevOps. , — DevOps 1 .
, DevOps 1. ?
Source: https://habr.com/ru/post/420547/
All Articles