Making Shrimp More Useful: Adding Recoding Images to Other Formats
Since the beginning of 2017, our small team has been developing the RESTinio OpenSource library for embedding an HTTP server in a C ++ application. To our great surprise, from time to time, we get questions from the category “But why might we need an embedded HTTP server in C ++?” Unfortunately, simple questions are the most difficult to answer. Sometimes the best answer is sample code.
A couple of months ago, we started a small Shrimp demo project , which clearly demonstrates a typical scenario under which our library is “honed”. The demo project is a simple Web service that receives requests for scaling of the pictures stored on the server and which responds with a picture of the size the user needs.
')
This demo project is good because firstly, it requires integration with a long time ago written and properly working code in C or C ++ (in this case, ImageMagick). Therefore, it should be clear why it makes sense to build an HTTP server in a C ++ application.
And, secondly, in this case, asynchronous processing of requests is required so that the HTTP server does not block while the image is scaled (and this can take hundreds of milliseconds or even seconds). And we started the development of RESTinio precisely because we could not find a sane C ++ embedded server that was focused on asynchronous request processing.
We built the work on Shrimp in an iterative way: first, the simplest version that just scaled the pictures was made and described . Then we eliminated a number of shortcomings of the first version and described it in the second article . Finally got around to expand the functionality of Shrimp-and again: added the conversion of images from one format to another. About how this was done and will be discussed in this article.
Target-format support
So, in the next version of Shrimp, we added the ability to render the scaled image in a different format. So, if you issue a Shrimp request type:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920" Shrimp will render the image in the same JPG format as the original image.
But if you add the target-format parameter to the URL, then Shrimp will convert the image to the specified target format. For example:
curl "http://localhost:8080/my_picture.jpg?op=resize&max=1920&target-format=webp" In this case, Shrimp will give the image in webp format.
The updated Shrimp supports five image formats: jpg, png, gif, webp and heic (also known as HEIF). You can experiment with different formats on a special web-page :
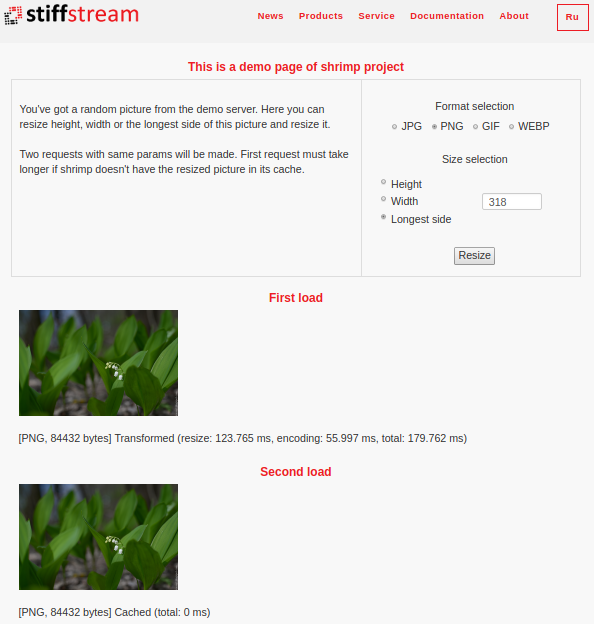
(on this page it is not possible to select the heic format, since regular desktop browsers do not support this format by default).
In order to maintain the target-format in Shrimp, it took a little bit to refine the Shrimp code (which we were surprised by, because there really were a few changes). But then I had to mess around with the ImageMagick build, which we were even more surprised by, since before, we were faced with this kitchen, by a happy coincidence, it was not necessary. But let's talk about everything in order.
ImageMagick must understand different formats.
ImageMagick for encoding / decoding images uses external libraries: libjpeg, libpng, libgif, etc. These libraries must be installed on the system before ImageMagick is configured and built.
The same thing should happen in order for ImageMagick to support webp and heic formats: first you need to build and install libwebp and libheif, then configure and install ImageMagick. And if everything is simple with libwebp, then around libheif I had to dance with a tambourine. Although after a while, after everything as a result gathered and started working, it is already incomprehensible: why did you have to resort to a tambourine, everything seems to be trivial? ;)
In general, if someone wants to make friends with heic and ImageMagick, you will have to install:
In that order (you may have to install nasm in order for x265 to work at maximum speed). After that, when issuing the ./configure command, ImageMagick will be able to find everything it needs to support .heic-files.
Support for target-format in query string incoming requests
After we made ImageMagick friends with the webp and heic formats, it was time to modify the Shrimp code. First of all, we need to learn to recognize the target-format argument in incoming HTTP requests.
From the point of view of RESTinio, this is not a problem at all. Well, another argument appeared in the query string, so what? But from the point of view of Shrimp, the situation turned out to be somewhat more complicated, which is why the function code that was responsible for parsing the HTTP request became more complicated.
The fact is that before it was necessary to distinguish only two situations:
- A request came in the form "/filename.ext" without any other parameters. So you just need to give the file "filename.ext" as it is;
- A request came in the form "/filename.ext?op=resize & ...". In this case, you need to scale the image from the file «filename.ext».
But after adding the target-format, we need to distinguish four situations:
- A request came in the form "/filename.ext" without any other parameters. So you just need to give the file "filename.ext" as it is, without scaling and without recoding to another format;
- A request came in the form "/filename.ext?target-format=fmt" without any other parameters. It means to take an image from the file “filename.ext” and transcode it to the format “fmt” while maintaining the original dimensions;
- A request came in the form "/filename.ext?op=resize & ..." but without target-format. In this case, you need to scale the image from the file “filename.ext” and give it in the original format;
- A request came in the form "/ filename.ext?op=resize&...&target-format=fmt". In this case, you need to perform scaling, and then re-encode the result in the format "fmt".
As a result, the function for determining the request parameters took the following form :
void add_transform_op_handler( const app_params_t & app_params, http_req_router_t & router, so_5::mbox_t req_handler_mbox ) { router.http_get( R"(/:path(.*)\.:ext(.{3,4}))", restinio::path2regex::options_t{}.strict( true ), [req_handler_mbox, &app_params]( auto req, auto params ) { if( has_illegal_path_components( req->header().path() ) ) { // . return do_400_response( std::move( req ) ); } // . const auto qp = restinio::parse_query( req->header().query() ); const auto target_format = qp.get_param( "target-format"sv ); // // . target-format, // . target-format // , , // . const auto image_format = try_detect_target_image_format( params[ "ext" ], target_format ); if( !image_format ) { // . . return do_400_response( std::move( req ) ); } if( !qp.size() ) { // , . return serve_as_regular_file( app_params.m_storage.m_root_dir, std::move( req ), *image_format ); } const auto operation = qp.get_param( "op"sv ); if( operation && "resize"sv != *operation ) { // , resize. return do_400_response( std::move( req ) ); } if( !operation && !target_format ) { // op=resize, // target-format=something. return do_400_response( std::move( req ) ); } handle_resize_op_request( req_handler_mbox, *image_format, qp, std::move( req ) ); return restinio::request_accepted(); } ); } In the previous version of Shrimp, where it was not necessary to transcode the image, working with the request parameters looked a bit simpler .
Request queue and image cache with target-format
The next point in the implementation of target-format support was the work to the queue of waiting requests and the cache of finished pictures in the a_transform_manager agent. More about these things discussed in the previous article , but slightly recall what we are talking about.
When a request comes to convert images, it may be that the finished image with such parameters is already in the cache. In this case, you don’t need to do anything, just send the image from the cache in response. If the picture needs to be converted, it may turn out that there are no free workers at the moment and you need to wait until it appears. For this information about the request must be put in the waiting queue. But at the same time, it is necessary to check the uniqueness of requests - if we are waiting for processing three identical requests (that is, we need to convert the same image in the same way), then we should process the image only once, and return the result of processing for these three requests. Those. waiting queues for the same requests must be grouped.
Earlier in Shrimp, we used a simple composite key for searching the image cache and waiting queue: a combination of the original file name + parameters for resizing the image . Now it was necessary to take into account two new factors:
- first, the target image format (i.e., the source image may be in jpg, and the resulting image may be in png);
- secondly, the fact that image scaling may not be necessary. This happens in a situation where the customer orders only the conversion of the image from one format to another, but with preservation of the original image size.
It must be said that here we went along the simplest path, without trying to somehow optimize anything. For example, one could try to make two caches: one would store images in the original format, but scaled to the desired size, and in the second, scaled images converted to the target format.
Why would such double caching be needed? The fact is that during the transformation of images, the two most expensive operations in time are the resizing and serialization of the image into the target format. Therefore, if we received a request for scaling the example.jpg image to the size of 1920 in width and transforming it into webp format, we could save two images in memory: example_1920px_width.jpg and example_1920px_width.webp. Picture example_1920px_width.webp we would give when we receive a second request. But the picture example_1920px_width.jpg could be used when receiving requests for scaling example.jpg up to size 1920 by width and transforming it into heic format. We could skip the resizing operation and only do the format conversion (i.e. the ready-made image of example_1920px_width.jpg would be encoded into the heic format).
Another potential opportunity: when a request comes to transcode an image into another format without resizing, you can determine the actual size of the image and use this size inside the composite key. For example, let example.jpg be 3000x2000 pixels. If we then receive a request for scaling example.jpg up to 2000px in height, then we can immediately determine that we already have a picture of this size.
In theory, all these arguments deserve attention. But from a practical point of view, it is not clear how high the probability of such a development is. Those. how often will we receive a request for scaling example.jpg up to 1920px with conversion to webp, and then a request for the same scaling of the same picture, but with conversion into png? Without real statistics it is difficult to say. Therefore, we decided not to complicate our lives in our demo project, but to go first along the simplest path. Assuming that if someone needs more advanced caching schemes, this can be added later, starting from real, not fictional, scenarios for using Shrimp.
As a result, in the updated version of Shrimp, we slightly expanded the key, adding to it another parameter such as the target format:
class resize_request_key_t { std::string m_path; image_format_t m_format; resize_params_t m_params; public: resize_request_key_t( std::string path, image_format_t format, resize_params_t params ) : m_path{ std::move(path) } , m_format{ format } , m_params{ params } {} [[nodiscard]] bool operator<(const resize_request_key_t & o ) const noexcept { return std::tie( m_path, m_format, m_params ) < std::tie( o.m_path, o.m_format, o.m_params ); } [[nodiscard]] const std::string & path() const noexcept { return m_path; } [[nodiscard]] image_format_t format() const noexcept { return m_format; } [[nodiscard]] resize_params_t params() const noexcept { return m_params; } }; Those. request for resizing example.jpg up to size 1920px with conversion to png differs from the same resizing, but with conversion to webp or heic.
But the main focus is hiding in the new implementation of the resize_params_t class , which defines the new dimensions of the scaled image. Previously, this class supported three options: only the width is specified, only the height is specified or the long side is specified (the height or width is determined by the actual size of the picture). Accordingly, the resize_params_t :: value () method always returned some real value (which value was determined by the resize_params_t :: mode () method).
But in the new Shrimp one more mode has been added - keep_original, which means that the scaling is not performed and the picture is given in its original size. To support this mode, some changes had to be made to resize_params_t. First, the resize_params_t :: make () method now determines whether the keep_original mode is used (this mode is considered to be used if none of the width, height, and max parameters in the query query query string is specified). This allowed us not to rewrite the function handle_resize_op_request () , which pushes the request to scale the image for execution.
Secondly, the resize_params_t :: value () method can now not always be called, but only when the scaling mode is different from keep_original.
But the most important thing is that resize_params_t :: operator <() continued to work as intended.
Thanks to all these changes, a_transform_manager and the cache of scaled images, and the queue of waiting requests, remain the same. But now in these data structures information about various queries is stored. Thus, the key {"example.jpg", "jpg", keep_original} will be different from the key {"example.jpg", "png", keep_original}, and from the key {"example.jpg", "jpg", width = 1920px}.
It turned out that by shaming a bit with defining such simple data structures as resize_params_t and resize_params_key_t, we avoided reworking more complex structures, such as the cache of the resulting images and the queue of pending requests.
Target-format support in a_transformer
Well, the final step in the support of target-format is an extension of the logic of the a_transformer agent so that the picture, possibly already scaled, is then converted to the target format.
It was easiest to do this; all you had to do was to expand the code of the a_transform_t :: handle_resize_request () method:
[[nodiscard]] a_transform_manager_t::resize_result_t::result_t a_transformer_t::handle_resize_request( const transform::resize_request_key_t & key ) { try { m_logger->trace( "transformation started; request_key={}", key ); auto image = load_image( key.path() ); const auto resize_duration = measure_duration( [&]{ // // keep_original. if( transform::resize_params_t::mode_t::keep_original != key.params().mode() ) { transform::resize( key.params(), total_pixel_count, image ); } } ); m_logger->debug( "resize finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( resize_duration).count() ); image.magick( magick_from_image_format( key.format() ) ); datasizable_blob_shared_ptr_t blob; const auto serialize_duration = measure_duration( [&] { blob = make_blob( image ); } ); m_logger->debug( "serialization finished; request_key={}, time={}ms", key, std::chrono::duration_cast<std::chrono::milliseconds>( serialize_duration).count() ); return a_transform_manager_t::successful_resize_t{ std::move(blob), std::chrono::duration_cast<std::chrono::microseconds>( resize_duration), std::chrono::duration_cast<std::chrono::microseconds>( serialize_duration) }; } catch( const std::exception & x ) { return a_transform_manager_t::failed_resize_t{ x.what() }; } } Compared with the previous version, there are two principal additions.
First, calling the truly magical method image.magick () after performing a resizing. This method specifies the ImageMagick image format. At the same time, the representation of the picture in memory does not change - ImageMagick continues to store it as it suits him. But then the value specified by the magick () method will be taken into account during the subsequent call to Image :: write ().
Secondly, the updated version marks the time of the serialization of the image in the specified format. The new version of Shrimp now records separately the time spent on scaling, and the time taken to convert to the target format.
For the rest, the a_transformer_t agent has not changed.
Parallelization of ImageMagick work
By default, ImageMagic is built with OpenMP support. Those. it is possible to parallelize operations on images that ImageMagick performs itself. You can control the number of worker threads that ImageMagick uses in this case by using the MAGICK_THREAD_LIMIT environment variable.
For example, on my test machine with MAGICK_THREAD_LIMIT = 1 (that is, without real parallelization), I get the following results:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:51:24 GMT < Last-Modified: Wed, 15 Aug 2018 11:51:24 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 1323 < Shrimp-Resize-Time: 1086.72 < Shrimp-Encoding-Time: 236.276 The time spent on resizing is indicated in the Shrimp-Resize-Time header. In this case, it is 1086.72ms.
But if you set MAGICK_THREAD_LIMIT = 3 on the same machine and run Shrimp, then we get different values:
curl "http://localhost:8080/DSC08084.jpg?op=resize&max=2400" -v > /dev/null > GET /DSC08084.jpg?op=resize&max=2400 HTTP/1.1 > Host: localhost:8080 > User-Agent: curl/7.47.0 > Accept: */* > < HTTP/1.1 200 OK < Connection: keep-alive < Content-Length: 2043917 < Server: Shrimp draft server < Date: Wed, 15 Aug 2018 11:53:49 GMT < Last-Modified: Wed, 15 Aug 2018 11:53:49 GMT < Access-Control-Allow-Origin: * < Access-Control-Expose-Headers: Shrimp-Processing-Time, Shrimp-Resize-Time, Shrimp-Encoding-Time, Shrimp-Image-Src < Content-Type: image/jpeg < Shrimp-Image-Src: transform < Shrimp-Processing-Time: 779.901 < Shrimp-Resize-Time: 558.246 < Shrimp-Encoding-Time: 221.655 Those. the resizing time was reduced to 558.25ms.
Accordingly, since ImageMagick provides the ability to parallelize calculations, you can use this opportunity. But at the same time it is desirable to be able to control how many worker threads Shrimp will take under it. In previous versions of Shrimp, it was impossible to influence how many workflows Shrimp created. And in the updated version of Shrimp, it can be done. Or through environment variables, for example:
SHRIMP_IO_THREADS=1 \ SHRIMP_WORKER_THREADS=3 \ MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ... Or through command line arguments, for example:
MAGICK_THREAD_LIMIT=4 \ shrimp.app -p 8080 -i ... --io-threads 1 --worker-threads 4 Values set via the command line have a higher priority.
It should be emphasized that MAGICK_THREAD_LIMIT affects only those operations that ImageMagick performs itself. For example, resizing is performed by ImageMagick. But converting from one format to another ImageMagick delegates to external libraries. And how operations in these external libraries are parallelized is a separate issue that we did not understand.
Conclusion
Perhaps, in this version of Shrimp, we have brought our demo project to an acceptable state. Those who want to watch and experiment can find the source code of Shrimp on BitBucket or GitHub . You can also find a Dockerfile there to build Shrimp for your experiments.
In general, we have achieved our goals, which we set for ourselves when starting this demo project. A number of ideas have emerged for the further development of both RESTinio and SObjectizer, and some of them have already been implemented. Therefore, whether Shrimp will develop somewhere further depends entirely on questions and wishes. If they are, then Shrimp can expand. If not, then Shrimp will remain a demo project and a testing ground for experiments with new versions of RESTinio and SObjectizer.
In conclusion, I would like to express special thanks to aensidhe for the help and advice, without which our dancing with a tambourine would be much longer and sad.
Source: https://habr.com/ru/post/420353/
All Articles