How to write programs at the junction of mobile development and algorithms? Yandex Contest and Stories
From 10 to 22 September will be a Yandex. Blitz competition on mobile development. Registration is open . Blitz is a short way to Yandex: it will be enough for participants in the top 5 to successfully complete one interview section instead of the standard four in order to receive a job offer.
On the occasion of the competition, we talked with colleagues about interesting tasks related immediately to mobile platforms and algorithms. Today we will share their stories with readers of Habr.

')
There is an opinion that the development of mobile applications is something special, far from programming in a general sense, and specialists who write under Android and iOS never encounter the solution of algorithmic problems, limited to connecting ready-made libraries, screen layouts, writing simple business logic and research of bugs of a specific platform. But not everything is so simple.
Creating software for mobile devices is always fraught with limitations. Even in top devices, not so powerful CPU and GPU and not so much memory as in a modern computer. At the same time, budget smartphones with even weaker hardware make up the bulk of the market. Their owners are particularly hard hit by a lack of resources.
The development of a complex competitive project is impossible without the use of solutions that cope with the tasks faster than in quadratic time. Users can go to a competitor if they don’t like the speed or how your application consumes battery power.
Historically, Blitz is a competition for knowledge of algorithms and the ability to translate the idea of a solution in code. Blitz, which will be held in September, will not be an exception. We tried to select tasks with algorithms similar to those that had to be used by Yandex mobile developers in real projects for Android and iOS.
Mikhail Efimov, lead developer :
Sergey Kuznetsov, Lead Developer :

Alexander Yashkin, head of the portal backend group :

Oleg Maksimenko, Lead Developer :
On the occasion of the competition, we talked with colleagues about interesting tasks related immediately to mobile platforms and algorithms. Today we will share their stories with readers of Habr.
')
There is an opinion that the development of mobile applications is something special, far from programming in a general sense, and specialists who write under Android and iOS never encounter the solution of algorithmic problems, limited to connecting ready-made libraries, screen layouts, writing simple business logic and research of bugs of a specific platform. But not everything is so simple.
Creating software for mobile devices is always fraught with limitations. Even in top devices, not so powerful CPU and GPU and not so much memory as in a modern computer. At the same time, budget smartphones with even weaker hardware make up the bulk of the market. Their owners are particularly hard hit by a lack of resources.
The development of a complex competitive project is impossible without the use of solutions that cope with the tasks faster than in quadratic time. Users can go to a competitor if they don’t like the speed or how your application consumes battery power.
Historically, Blitz is a competition for knowledge of algorithms and the ability to translate the idea of a solution in code. Blitz, which will be held in September, will not be an exception. We tried to select tasks with algorithms similar to those that had to be used by Yandex mobile developers in real projects for Android and iOS.
Acceleration of the Sadzhest Browser
Mikhail Efimov, lead developer :
- I was engaged in the omnibox - browser search string. Autocomplete works in it - just enter the beginning of the word, and we will suggest the whole word. The initial task can be simplified to the following: having received a string at the input, find all the words from a predetermined set in which the entered string occurs as a substring. To do this, we take all the suffixes of the word - all the substrings with which it ends. For example, for the word "table" it will be "table" and "tol". Suffixes of one and two characters - here we would have “ol” and “l” - are not taken into account, because by them garbage falls into the sadjest.
Thus, instead of one word, we get two. If it consisted of five letters, you would get three, etc. Further, for example, you can build a well-known data structure trie, which allows you to search for them. But this structure has a flaw - it can take up a lot of space in the memory.
We, in turn, kept a sorted list of suffixes - suffix array. An element in the array is not the entire suffix — then the structure would take up too much memory, a quadratic number — but just a couple of pointers. The first one indicates the word or phrase to be used, the second one - to the character in the word or phrase from which the suffix begins. This approach perfectly saves memory. We have only two pointers, two eight-byte numbers instead of very long words.
Then the question arises how to store the already sorted list. It can be stored as a simple array - but new entries will then be inserted into it for a very long time. Therefore, I chose to store an “augmented” binary search tree - augmented binary search tree. As a key, each node of the tree contains a certain suffix of a certain word, and as a “supplement”, information on priorities is stored in the nodes. All that needs to be done is to find the tree node corresponding to the entered prefix. You can then analyze this and neighboring nodes in order to understand which words can be used for issuing.
Among them are those with higher priority. The priority is affected by the length of the indentation suffix from the beginning of the word. Words with zero indent have a higher priority — say, if a user entered “st”, then the word “table” will be much higher in priority than the word “bridge”. But in principle, you can enter a sequence of characters that the browser will reply with a word where this sequence occurs in the middle or the end. For example - if there is no word that begins with this sequence.
Displaying CCTV cameras on mobile Yandex.Maps
Sergey Kuznetsov, Lead Developer :
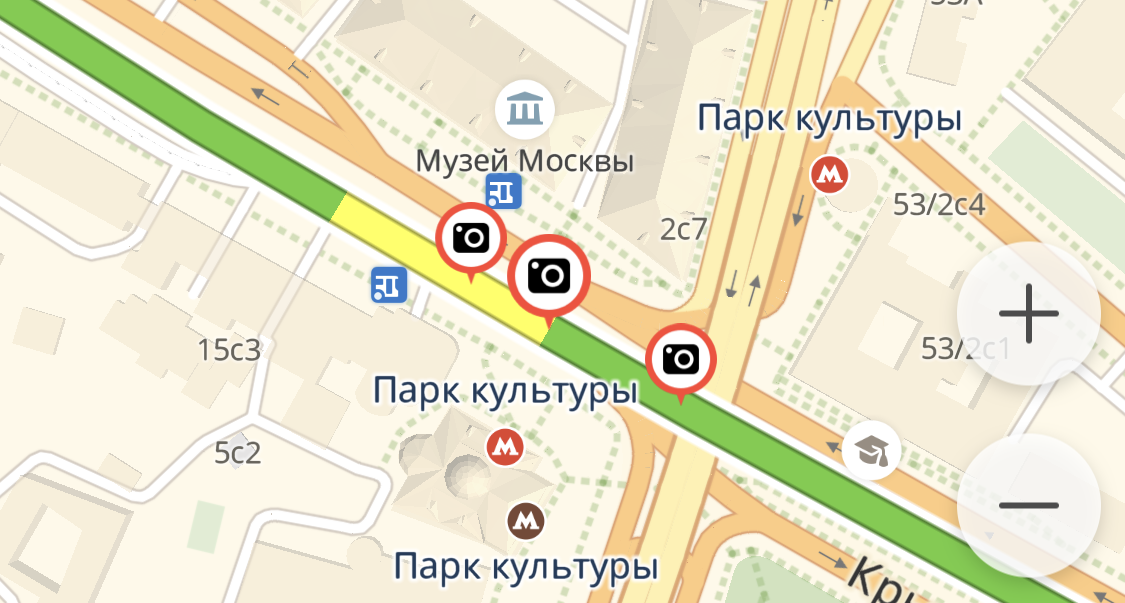
- We had an algorithm that displayed the cameras on the map. He worked in quadratic time, not very fast. There was a thought that it is possible to improve it, and without resorting to some frills.
If we talk about the formulation of the problem, then we had a lot of cameras that need to be displayed. On the high scales of the map, they could intersect with each other, and it was ugly - it was required to display one camera instead of many intersecting ones.
If this task is formalized, then it comes down to the following: there are n identical squares on the plane with sides parallel to the axes of coordinates, and you need to choose from them so many squares that they do not intersect inside it, and all other squares intersect at least one of squares of the original set. The simplest solution algorithm — when we selected a square and intersected it with all the others — worked for n 2 . But the problem can also be solved for n * log (n), using a certain class of algorithms, which in the literature is called the “scanning straight line”. If you do not know about this approach, then this problem, of course, can be solved, but if you know, it is much easier to solve. Immediately you know in which direction to think.
Cameras on mobile Maps. If you zoom out, only one icon remains.
Retrieving data from one of the sources of the Sadgest Browser
Alexander Yashkin, head of the portal backend group :
- There are several "heavy" sources of prompts that are displayed when typing in the browser omnibox. One such source is the user's local history. Tips from history unloads historical provider - component came to us from Chromium. What is the feature of the omnibox? It should be very fast, prompt immediately as you type, so the sources are mostly synchronous. When the browser starts, the provider builds a fast index of history tips for the last week. In Chromium, the history index for omnibox used associative containers std :: set and std :: map from the standard C ++ library. Red-ebony is usually used to store data inside such containers.
Our task was to speed up the search through the history in the omnibox. By histograms from users, we have seen that historical search takes the most time, and people really suffer on slow computers. For some, the expectation was one-tenth of a second — when you quickly type the characters in the omnibox, it is too long, and it can be even worse.
I made several approaches, optimizations, upstream in Chromium. In parallel, I made changes to our code. Then the task passed to our developer Denis Yaroshevsky. He is a passionate developer — interested in C ++, STL, algorithms. Having rummaged, he suggested to act radically: replace std :: set with flat_set, and std :: map with flat_map. That is, just change the basic structure. std :: set and std :: map store their elements in tree nodes, and flat_set and flat_map are, in essence, wrappers over a sorted vector. Flat-containers are one of the most popular containers that are not included in the standard C ++ library. Perhaps in the next standard, they still fall into it.
At first there was some distrust: the proposed path seemed too simple, lay on the surface. To prove its effectiveness, we made perf test: took the profile of one of our colleagues, built an index of history from it and drove popular queries on it. Chose 10 queries and counted the times. Denis showed me the result, the improvements were obvious, and I also believed in his idea.
The problem found was not specific to Yandex. Browser. It was reflected in any Chromium-based browser, so at first we, as members of the Chromium project, decided to make upstream. But in Chromium many who commit, and part of the proposed ideas - wild. The developers of Chromium have a rather cautious attitude towards everyone who offers to change something outside, all the more drastically. At first, they did not want to take our patch. They offered to prove their effectiveness and write a mini-design-doc, so that they could understand the idea, the benefits and criticize the proposal.
In addition, they said: once you need, write and add separate implementations of flat-containers. Do not add to our project any new libraries - implementations already exist in boost, eastl. Flat-containers had to be added to the base-components of Chromium. This is an analogue of the standard library, and chromiummen are very worried that nothing superfluous falls into it.
Denis Yaroshevsky did all this, spent time writing a design document, wrote flat_set implementation in C ++ templates, applied a lot of template magic, wrote tests covering the functionality of containers, created another synthetic perf test - we could not send perf test with this one colleague profile. Denis argued with the owners of the base code and the omnibox, significantly reworked the code based on the review results - and finally overcame them and updated the code in Chromium.
This whole epic lasted six months. Chromiums then wrote: “Yes, we did see a 10–20% improvement on all histograms. Cool, thanks!". From them it is already through downstream came to us in the browser, and then happy end. Indeed, the historical index has significantly accelerated on all configurations, on all platforms. In this index, the advantages of flat-containers appeared much better than the disadvantages.
After the upstream, flat_set and flat_map were used much more often - now you can find several hundred places in the code where they are involved. The moral is patience and hard work, and carefully choose not only algorithms for your code, but also suitable data structures.
See the left side of the graph. The sharp decrease in the load time of the omnibox results in early 2017 is connected precisely with the transition to flat_set and flat_map
Acceleration of one of HashMap in Chromium
Oleg Maksimenko, Lead Developer :
- The task was to speed up the preservation of ordinary HTML pages in one of our subprojects. I used the standard code profiling tools - I looked at which pieces of code were “hot” during the save process. Stumbled upon an unexpected place. That is, this is not the main logic, but simply a search on the HashMap container, which should occupy a small percentage of the total work time. Instead, there were really strong costs.
I decided to replace the existing implementation. It was an internal HashMap, from Chromium. I replaced it and received a win several times. Then I went a little further and made sure that this was not the mistake of the guys from Google, that it was not the implementation of the entire HashMap, but the hash function. This is an external thing. And it turned out that they had a trivial hash in the code we used, the address in memory was used as a hash. Perhaps due to some peculiarities, for example, a small volume, this solution suited them. Maybe their HashMap was not a hot place, but it became with us when we applied this structure. By simply replacing the naive and trivial hash function with std :: hash, we obtained a speed increase of 3–10 times. As a result, this appeal to the hash-memory was lost from the list of hot spots, it began to occupy a small percentage, as expected at first. Everything became good and beautiful.
Source: https://habr.com/ru/post/420305/
All Articles