Theory and practice of backups with Borg

To our great surprise at Habré there was not a single material about the wonderful Open Source-tool for data backup - Borg (not to be confused with the Kubernetes progenitor of the same name!) . Since we have been using it in production for more than a year now, in this article I’ll share our impressions of Borg.
Background: Experience with Bacula and Bareos
In 2017, we were tired of Bacula and Bareos, who used from the very beginning of their activities (ie, about 9 years in production at that time). Why? During the operation, we have accumulated a lot of discontent:
')
- Hangs SD (Storage Daemon). If you have configured parallelism, then the SD maintenance becomes more complicated, and its hangup blocks further backups on a schedule and the possibility of recovery.
- It is necessary to generate configs for both the client and the director. Even if you automate this (in our case, Chef, Ansible, and its own development were used at different times), you need to monitor that the director after his reload 'actually picked up the config. This is monitored only in the output of the reload command and after the messages are called (to get the error text itself).
- Schedule backups. The developers of Bacula decided to go their own way and wrote their own timetable format, which cannot be simply parsed or converted to another. Here are examples of standard backup schedules in our old installations:
- Daily full backup on Wednesdays and incremental on other days:
Run = Level=Full Pool="Foobar-low7" wed at 18:00
Run = Level=Incremental Pool="Foobar-low7" at 18:00 - Full backup of wal-files 2 times a month and increment every hour:
Run = Level=Full FullPool=CustomerWALPool 1st fri at 01:45
Run = Level=Full FullPool=CustomerWALPool 3rd fri at 01:45
Run = Level=Incremental FullPool=CustomerWALPool IncrementalPool=CustomerWALPool on hourly - Generated
schedulefor all occasions (on different days of the week every 2 hours) we got about 1665 ... because of what Bacula / Bareos periodically went crazy.
- Daily full backup on Wednesdays and incremental on other days:
- At bacula-fd (and bareos-fd) on directories with a large amount of data (say, 40 TB, of which 35 TB have large files [100+ MB], and the remaining 5 TB are small [from 1 KB to 100 MB ]) a slow memory leak begins, which in production is a completely unpleasant situation.
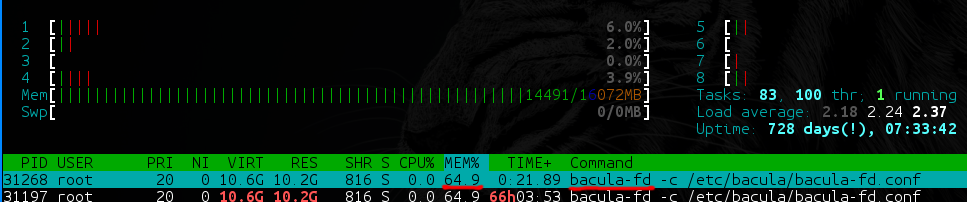
- On backups with a large number of files, Bacula and Bareos are very dependent on the performance of the used DBMS. What drives it on? How skillfully can you tailor her for these specific needs? And in the database, by the way, one (!) Non-partisable table is created with a list of all files in all backups and a second one with a list of all paths in all backups. If you are not ready to allocate at least 8 GB of RAM for the base + 40 GB SSD for your backup server - immediately get ready for the brakes.
- Dependence on a DB is worthy one more point. Bacula / Bareos for each file ask the director if there was already such a file. The director, of course, climbs into the database, into those very huge tables ... It turns out that backups can be blocked simply by the fact that several heavy backups were launched at the same time - even if there is a diff for several megabytes.
It would be unfair to say that no problems were solved at all, but we got to the point where we were really tired of various workarounds and wanted a reliable solution "here and now."
Bacula / Bareos work fine with a small number (10-30) of uniform jobs. Broke a trifle once a week? Do not worry: they gave the task to the duty officer (or another engineer) - they fixed it. However, we have projects where the number of jobs is in the hundreds, and the number of files in them is in the hundreds of thousands. As a result, 5 minutes a week for repairing the backup (not counting several hours of adjustment before this) began to multiply. All this led to the fact that 2 hours a day it was necessary to repair backups in all projects, because literally everywhere there was something trivial or seriously broken.
Then someone might think that a dedicated engineer should be engaged in backups. Certainly, he will be as bearded and stern as possible, and from his gaze backups are repaired instantly while he sips his coffee calmly. And this idea may be true in some way ... But there is always a but. Not everyone can afford to repair around the clock and watch backups, and even more so - the engineer selected for these purposes. We are just sure that it is better to spend these 2 hours a day for something more productive and useful. Therefore, we turned to the search for alternative solutions that “just work”.
Borg as a new way
The search for other Open Source variants was spread over time, so it’s difficult to estimate the total costs, but at one point (last year) our attention was directed to the “ hero of the occasion” - BorgBackup (or simply Borg). Partly due to the real experience of its use by one of our engineers (at the previous place of work).
Borg is written in Python (version> = 3.4.0 is required), and performance-sensitive code (compression, encryption, etc.) is implemented in C / Cython. Distributed under the free BSD license (3-clause). Supports many platforms including Linux, * BSD, macOS, as well as at the experimental level of Cygwin and Linux Subsystem of Windows 10. For the installation of BorgBackup, packages are available for popular Linux distributions and other operating systems, as well as source files installed, including via pip, - more information about this can be found in the project documentation .
Why did Borg bribe us so much? Here are its main advantages:
- Deduplication : real and very effective (examples will be below). Files within one Borg repository (that is, a special directory in the Borg-specific format) are divided into blocks of n megabytes, and repeated Borg blocks deduplicate. Deduplication occurs just before compression.
- Compression : after deduplication, the data is also compressed. Different compression algorithms are available: lz4, lzma, zlib, zstd. The standard feature of any backup, but no less useful for it.
- Work on SSH : Borg backed up to a remote server via SSH. On the server side, you just need an installed Borg and that's it! This immediately implies such advantages as security and encryption. You can configure access only by keys and, moreover, Borg executes only one of his commands when entering the server. For example:
$ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc… - It is delivered both in PPA (we mainly use Ubuntu), and static binary . Borg as a static binary allows you to run it almost anywhere where there is at least a minimally modern glibc. (But not everywhere - for example, failed to run on CentOS 5.)
- Flexible cleaning of old backups . You can set the storage of the last n backups, and 2 backups per hour / day / week. In the latter case, the last backup will be left at the end of the week. Conditions can be combined by making a storage of 7 daily backups in the last 7 days and 4 weeks.
The transition to Borg started slowly, on small projects. At first, these were simple cron scripts that did their job every day. Everything went on for about six months. During this time we had to get backups many times ... and it turned out that Borg didn’t have to be repaired at all! Why? Because the simple principle works here: “The simpler the mechanism, the fewer places where it will break.”
Practice: how to backup Borg?
Consider a simple backup creation example:
- Download the latest release binary to the backup server and machine, which we will back up from the official repository :
sudo wget https://github.com/borgbackup/borg/releases/download/1.1.6/borg-linux64 -O /usr/local/bin/borg sudo chmod +x /usr/local/bin/borg
Note : If you use a local machine for the test, both as a source and as a receiver, then all the difference will be only in the URI that we pass, but we remember that the backup should be stored separately and not on the same machine. - On the server backups create user
borg:sudo useradd -m borg
Simple: no groups and with a standard shell, but always with a home directory. - An SSH key is generated on the client:
ssh-keygen - On the server, add the generated key to the
borguser:mkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.sshlocal / bin / borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf / XmSVWfF7PfjGlbKW00MJ63zal / E / mxm + vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU / JNU0jITLx + vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk / QmteOOclzx684t9d6BhMvFE9w9r + c76aVBIdbEyrkloiYd + vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44 / Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam + 9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y + IQM7fbDR'> ~ borg / .sshmkdir ~borg/.ssh echo 'command="/usr/local/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDNdaDfqUUf/XmSVWfF7PfjGlbKW00MJ63zal/E/mxm+vJIJRBw7GZofe1PeTpKcEUTiBBEsW9XUmTctnWE6p21gU/JNU0jITLx+vg4IlVP62cac71tkx1VJFMYQN6EulT0alYxagNwEs7s5cBlykeKk/QmteOOclzx684t9d6BhMvFE9w9r+c76aVBIdbEyrkloiYd+vzt79nRkFE4CoxkpvptMgrAgbx563fRmNSPH8H5dEad44/Xb5uARiYhdlIl45QuNSpAdcOadp46ftDeQCGLc4CgjMxessam+9ujYcUCjhFDNOoEa4YxVhXF9Tcv8Ttxolece6y+IQM7fbDR' > ~borg/.ssh/authorized_keys chown -R borg:borg ~borg/.ssh - Initialize borg repo on the server from the client:
ssh borg@172.17.0.3 hostname # borg init -e none borg@172.17.0.3:MyBorgRepo
The-eswitch is used to select the repository encryption method (yes, you can additionally encrypt each repository with your password!). In this case, because This is an example, we do not use encryption.MyBorgRepois the name of the directory in which borg repo will be (you do not need to create it in advance - Borg will do everything by itself). - We start the first backup using Borg:
borg create --stats --list borg@172.17.0.3:MyBorgRepo::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}" /etc /root
About the keys:--statsand--listgive us statistics on the backup and files in it;borg@172.17.0.3:MyBorgRepo- everything is clear here, this is our server and directory. And what's next for the magic? ..::"MyFirstBackup-{now:%Y-%m-%d_%H:%M:%S}"is the name of the archive inside the repository. It is arbitrary, but we follow the format_-timestamp(timestamp in Python format).
What's next? Of course, see what got into our backup! List of archives inside the repository:
borg@b3e51b9ed2c2:~$ borg list MyBorgRepo/ Warning: Attempting to access a previously unknown unencrypted repository! Do you want to continue? [yN] y MyFirstBackup-2018-08-04_16:55:53 Sat, 2018-08-04 16:55:54 [89f7b5bccfb1ed2d72c8b84b1baf477a8220955c72e7fcf0ecc6cd5a9943d78d] We see a backup with a timestamp and how Borg asks us if we really want to access an unencrypted repository, which we have never been to before.
See the list of files:
borg list MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 We get the file from the backup (you can and the whole directory):
borg@b3e51b9ed2c2:~$ borg extract MyBorgRepo::MyFirstBackup-2018-08-04_16:55:53 etc/hostname borg@b3e51b9ed2c2:~$ ll etc/hostname -rw-r--r-- 1 borg borg 13 Aug 4 16:27 etc/hostname Congratulations, your first Borg backup is ready!
Practice: automate it [with GitLab]!
Having wrapped all this in scripts, we set up backups manually in a similar way on about 40 hosts. Realizing that Borg really works, they began to transfer more and larger projects to it ...
And here we are confronted with what is in Bareos, but not at Borg! Namely: WebUI or some centralized place for setting up backups. And we very much hope that this is a temporary phenomenon, but so far we have had to solve something. Googling the finished tools and gathered in a videoconference, we set to work. There was a great idea to integrate Borg with our internal services, as we did before with Bacula (Bacula herself took the list of jobs from our central API, to which we had our own interface integrated with other project settings). We thought about how to do it, outlined a plan, how and where it can be embedded, but ... Normal backups are needed now, and there is no place to take on grandiose time plans. What to do?
Questions and requirements were approximately as follows:
- What to use as centralized backup management?
- What can any Linux administrator do?
- What can even a manager showing backups of clients be able to understand and set up?
- What does the scheduled task on your system do every day?
- What will not be difficult to configure and will not break? ..
The answer was obvious: this is the good old crond who heroically performs his duty every day. Plain. Does not hang. Even the manager who is from Unix to “you” can fix it.
So crontab, but where does all this hold? Is it possible to go to the project machine every time and edit the file with your hands? Of course not. We can put our schedule in the Git repository and set up GitLab Runner, which will update it on the host by commit.
Note : It was GitLab that was chosen as a means of automation, because it is convenient for the task and in our case is almost everywhere. But I must say that in no case is it a necessity.
You can lay out a crontab for backups using your usual automation tool or manually (for small projects or home installations).
So, this is what you need for simple automation:
1. GitLab and a repository in which to start there will be two files:
schedule- backup schedule,borg_backup_files.shis a simple file backup script (as in the example above).
schedule Example: # WARNING! CRONTAB MANAGED FROM GITLAB CI RUNNER IN ${CI_PROJECT_URL} # CI_COMMIT_SHA: ${CI_COMMIT_SHA} # Branch/tag: ${CI_COMMIT_REF_NAME} # Timestamp: ${TIMESTAMP} PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin # MyRemoteHost 0 0 * * * ${CI_PROJECT_DIR}/borg_backup_files.sh 'SYSTEM /etc,/opt' CI variables are used to check the success of the crontab update, and
CI_PROJECT_DIR is the directory in which the repository will appear after cloning with the runner. The last line indicates that the backup is performed every day at midnight.Example
borg_backup_files.sh : #!/bin/bash BORG_SERVER="borg@10.100.1.1" NAMEOFBACKUP=${1} DIRS=${2} REPOSITORY="${BORG_SERVER}:$(hostname)-${NAMEOFBACKUP}" borg create --list -v --stats \ $REPOSITORY::"files-{now:%Y-%m-%d_%H:%M:%S}" \ $(echo $DIRS | tr ',' ' ') || \ echo "borg create failed" The first argument here is the name of the backup, and the second is the list of directories for backup, separated by commas. Strictly speaking, a list may be a set of individual files.
2. GitLab Runner , running on a machine that needs to be backed up, and blocked only for execution of the jobs of this repository.
3. The CI script itself , implemented by the
.gitlab-ci.yml : stages: - deploy Deploy: stage: deploy script: - export TIMESTAMP=$(date '+%Y.%m.%d %H:%M:%S') - cat schedule | envsubst | crontab - tags: - borg-backup 4. The SSH key of the
gitlab-runner user with access to the gitlab-runner server (in the example, this is 10.100.1.1). By default, it should be in the .ssh/id_rsa home directory ( gitlab-runner ).5. The
borg user on the same 10.100.1.1 with access only to the borg serve command: $ cat .ssh/authorized_keys command="/usr/bin/borg serve" ssh-rsa AAAAB3NzaC1yc2EAA... Now when comming to the repository, the Runner fills the crontab contents. And when the cron's response time comes, the
/etc and /opt directories will be MyHostname-SYSTEM , which will be on the backup server in the MyHostname-SYSTEM directory of the MyHostname-SYSTEM server.
Instead of a conclusion: what else can?
The application of Borg does not, of course, end there. Here are some ideas for further implementation, some of which we have already implemented:
- Add universal scripts for different backups, which at the end of execution run
borg_backup_files.sh, aimed at the directory with the result of their work. For example, you can back up PostgreSQL (pg_basebackup), MySQL (innobackupex), GitLab (built-in rake job, creating an archive). - Central host with schedule for backup . Do not configure the same on every GitLab Runner host? Let it be one on the server backups, and crontab at startup transfers the backup script to the machine and runs it there. To do this, of course, you will need the
borguser on the client machine andssh-agentin order not to spread the key to the backup server on each machine. - Monitoring Where do without him! Alerts about incorrectly completed backup must be.
- Cleaning borg repository from old archives. Despite good deduplication, old backups still have to be cleaned. To do this, you can make a call to
borg pruneat the end of the backup script. - Web interface to the schedule. It is useful if editing crontab with your hands or in the web-interface for you does not look solid / inconvenient.
- Pie charts . There are some graphs for visual representation of the percentage of successfully completed backups, their execution time, the width of the “eaten” channel. No wonder I already wrote that there is not enough WebUI, as in Bareos ...
- Simple actions that I would like to receive by the button: run backup on demand, restore to the machine, etc.
And at the very end, I would like to add an example of deduplication efficiency in a real working backup of PostgreSQL WAL files in a production environment:
borg@backup ~ $ borg info PROJECT-PG-WAL Repository ID: 177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Location: /mnt/borg/PROJECT-PG-WAL Encrypted: No Cache: /mnt/borg/.cache/borg/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 Security dir: /mnt/borg/.config/borg/security/177eeb28056a60487bdfce96cfb33af1c186cb2a337226bc3d5380a78a6aeeb6 ------------------------------------------------------------------------------ Original size Compressed size Deduplicated size All archives: 6.68 TB 6.70 TB 19.74 GB Unique chunks Total chunks Chunk index: 11708 3230099 This is 65 days of backup WAL-files that were made every hour. When using Bacula / Bareos, i.e. without deduplication, we would get 6.7 TB of data. Just think: we can afford to store almost 7 terabytes of data passed through PostgreSQL, just 20 GB of space actually occupied.
PS
Read also in our blog:
Source: https://habr.com/ru/post/420055/
All Articles