Translation of Andrew Un’s Passion for Machine Learning, Chapter 1-14
Some time ago, a link to my Andrew Ng book “Machine Learning Yearning” appeared in my Facebook feed, which can be translated as “Passion for machine learning” or “Thirst for machine learning”.

People who are interested in machine learning or working in this field do not need to represent Andrew. For the uninitiated, it is enough to say that he is the star of world magnitude in the field of artificial intelligence. Scientist, engineer, entrepreneur, one of the founders of Coursera . He is the author of an excellent course on introducing machine learning and courses that make up the Deep Learning specialization.
I have deep respect for Andrew, he took his courses, so I immediately decided to read the book being published. It turned out that the book has not yet been written and is published in parts, as the author writes it. In general, this is not even a book, but a draft of a future book (it is not known whether it will be published in paper form). Then came the idea to translate the released chapters. Currently he has translated 14 chapters (this is the first excerpt from the book). I plan to continue this work and translate the entire book. Translated chapters will be published in my blog on Habré.
At the time of this writing, the author has published 52 chapters out of 56 conceived (a notification of readiness of 52 chapters came to me by mail on July 4). All currently available chapters can be downloaded here or independently found on the Internet.
Before publishing my translation, I looked for other translations, found this one , also published on Habré. True translated only the first 7 chapters. I can not judge whose translation is better. Neither I nor IliaSafonov (according to the sensations from reading) are not professional translators. I like some parts of me more, some of Ilya. In Illya's preface, you can read interesting details about the book, which I omit.
I publish my translation without reading, “out of the oven”, I plan to return to some places and correct it (this is especially true of confusion with train / dev / test datasets). I would be grateful if the comments will contain comments on stylistics, mistakes, etc., as well as informative, concerning the text of the author.
All the pictures are original (from Andrew Un), without them the book would be more boring.
So, to the book:
Chapter 1. Why do we need a machine learning strategy?
Machine learning is at the heart of countless important applications, including web search, email antispam, speech recognition, product recommendations, and others. I assume that you or your team are working on machine learning applications. And that you want to accelerate your progress in this work. This book will help you do this.
Example: Creating a startup for the recognition of cat images
Suppose you work in a startup that processes an endless stream of cat photos for cat lovers.

You use a neural network to build a computer vision system to recognize cats in photographs.
But unfortunately, the quality of your learning algorithm is still not good enough, and the need to improve the cat detector puts pressure on you with tremendous force.
What to do?
Your team has many ideas, such as:
- Get more data: collect more photos of cats.
- Collect more heterogeneous dataset. For example, photos in which cats are in unusual positions; photos of cats with an unusual color; pictures with various settings of the camera; ...
- It is longer to train the algorithm by increasing the number of iterations of the gradient descent
- Try to increase the neural network, with a large number of layers / hidden neurons / parameters.
- Try to reduce the neural network.
- Try adding regularization (such as L2 regularization)
- Change the neural network architecture (activation function, number of hidden neurons, etc.)
- ...
If you successfully choose between these possible destinations, you will build a leading cat image processing platform, and lead your company to success. If your choice is unsuccessful, you may lose months of work in vain.
How to proceed?
This book will tell you how.
Most machine learning tasks have hints that can tell you that it would be useful to try and that it is useless to try. If you learn to read these tips, you can save months and years of development.
2. How to use this book to help guide your team’s work.
After you finish reading this book, you will have a deep understanding of how to choose the technical direction of work for a machine learning project.
But your teammates may not be clear why you are recommending a certain direction. Perhaps you want your team to use a one-parameter metric when evaluating the quality of the algorithm, but colleagues are not sure that this is a good idea. How do you convince them?
That's why I made the chapters short: So that you can print them out and give your colleagues one or two pages containing the material you need to familiarize the team with.
Small changes in prioritization can have a huge effect on the productivity of your team. By helping with these minor changes, I hope you can become the superhero of your team!

3. Background and remarks
If you have completed a machine learning course, such as my MOOC course on the Coursera, or if you have experience learning algorithms with a teacher, it will not be difficult for you to understand this text.
I assume that you are familiar with “learning with a teacher”: learning the function that connects x with y using marked up training examples (x, y). Teacher-learning algorithms include linear regression, logistic regression, neural networks, and others. To date, there are many forms and approaches to machine learning, but most of the approaches that have practical value are derived from the algorithms of the “learning with the teacher” class.
I will often refer to neural networks (to "deep learning"). You need only basic ideas about what they are for understanding this text.
If you are not familiar with the concepts mentioned here, watch the video of the first three weeks of the Machine Learning course at Coursera http://ml-class.org/
4. Scale of progress in machine learning
Many ideas of deep learning (neural networks) have existed for decades. Why did these ideas soar just today?
The two biggest drivers of recent progress are:
- Data availability Today, people spend a lot of time with computing devices (laptops, mobile devices). Their digital activity generates huge amounts of data that we can feed our learning algorithms.
- Computational capacities Only a few years ago it became possible to train neural networks of sufficiently large sizes, which allow us to take advantage of the use of huge datasets that we have.
I will clarify, even if you accumulate a lot of data, usually, the growth curve of the accuracy of old learning algorithms, such as logistic regression is “flat”. This implies that the learning curve "flattens out" and the quality of the prediction algorithm stops growing even though you give it more training data.
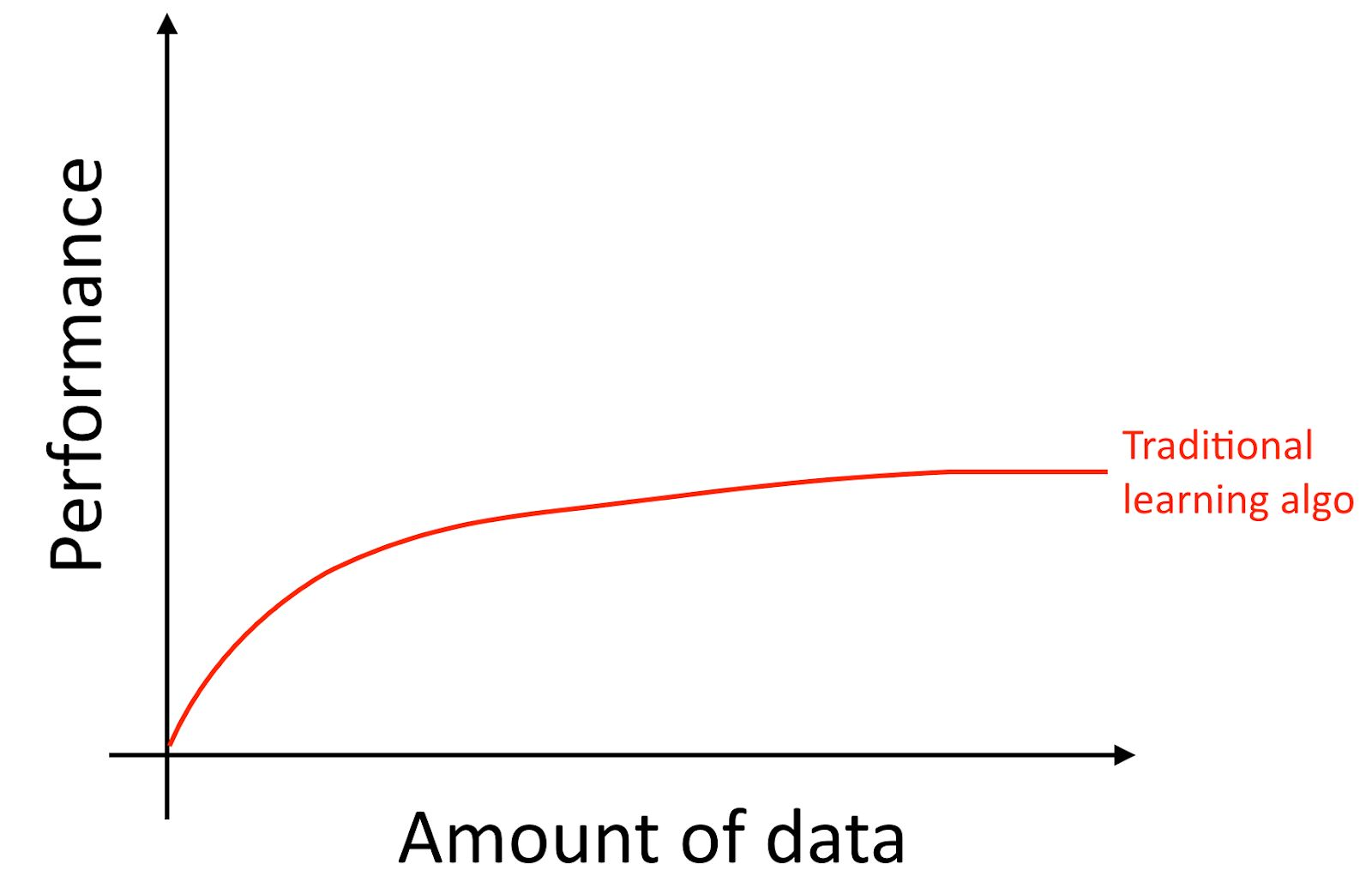
It looks as if the old algorithms do not know what to do with all this data, which is now at our disposal.
If you train a small neural network (NN) for the same “learning with the teacher” task, you can get a little better result than the “old algorithms”.
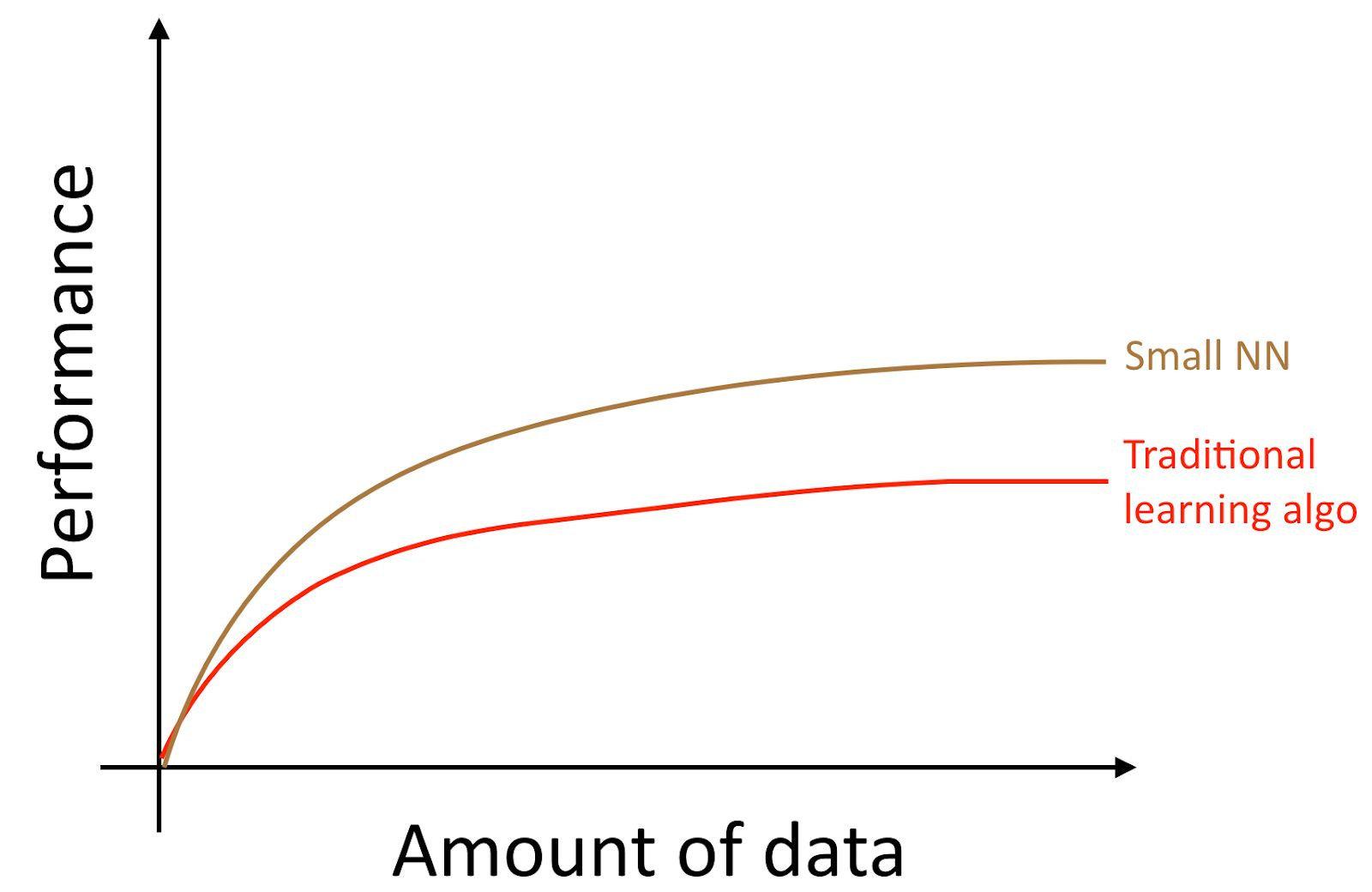
Here, by “Small NN” we mean a neural network with a small number of hidden neurons / layers / parameters. Finally, if you start to train all large and large neural networks, you can get higher and higher quality.
Author's note : This diagram shows that neural networks work better in small dataset mode. This effect is less stable than the effect of neural networks that work well in the mode of huge datasets. In the small data mode, depending on how the signs were processed (depending on the quality of the pattern engineering), traditional algorithms can work both better and worse than neural networks. For example, if you have 20 examples for training, it does not matter much whether you use logistic regression or a neural network; preparation of signs has a greater effect than the choice of algorithm. However, if you have 1 million learning examples, I would prefer a neural network.

Thus, you get the best quality of the algorithm when you (i) train a very large neural network, in this case you are on the green curve in the picture above; (ii) a huge amount of data is at your disposal.
Many other details, such as the neural network architecture, are also important, and many innovative solutions have been created in this area. But the most reliable way to improve the quality of the algorithm for today is still (i) increasing the size of the trained neural network (ii) getting more data for training.
The process of joint implementation of conditions (i) and (ii) in practice is surprisingly difficult. In this book, its details will be discussed in detail. We will start with general strategies that are equally useful for both traditional algorithms and neural networks, and then we will explore the most advanced strategies used in the design and development of depth learning systems.
5. Creating samples for learning and testing algorithms
Let's go back to our cat photo example, discussed above: You launched a mobile application and users upload a large number of different photos into your application. You want to automatically find photos of cats.
Your team gets a large training set by downloading photos of cats (positive examples) and photos that do not have cats (negative examples) from various websites. They cut the datasets divided into training and test for 70% to 30%. Using this data, they built an algorithm that finds cats, works well on both training and test data.
However, when you implemented this classifier in a mobile application, you found that the quality of its work is very low!

What happened?
You suddenly find out that the photos that users upload to your mobile application have a completely different look than the photos from the websites that your training datasets consist of: users upload photos taken with mobile phone cameras, which usually have lower resolution, less clear and made in low light. After training on your training / test samples collected from photos from websites, your algorithm was unable to qualitatively summarize the results on the actual distribution of data relevant to your application (in the photos taken by mobile phone cameras).
Before the advent of the modern era of big data, the general rule of machine learning was the partitioning of data into training and test for 70% to 30%. Although this approach still works, it would be a bad idea to use it in more and more applications, where the distribution of the training sample (photos from websites in the example above) differs from the distribution of data that will be used in combat. mode of your application (photos from the camera of mobile phones).
The following definitions are commonly used:
- Training set - a sample of data that is used to train the algorithm
- Validation sampling (Dev for development Dev (set) set) - data sampling, which is used to select parameters, select features and make other decisions regarding the learning algorithm. It is also sometimes called a hold-down cross-validation set.
- A test sample is a sample that is used to assess the quality of the operation of the algorithm, but it is not used to train the algorithm or the parameters used in this training.
Translator's note: Andrew Un uses the notion of development set or dev set, in Russian and Russian-language machine learning terminology such a term is not found. “Sampling for development” or “Development sampling” (direct translation of English words) sounds cumbersome. Therefore, I will continue to use the phrase "validation sample" as a translation dev set.
Note from translator 2: DArtN proposed to translate the dev set as a "debug sample", I think this is a very good idea, but I have already used the term "validation sample" on a large amount of text and replace it now with a lot of work. For the sake of fairness, I note that the term “validation sample” has one advantage - this sample is used to evaluate the quality of the algorithm (to evaluate the quality of the algorithm trained in the training sample), so in a sense it is “test”, the term “validation” in itself includes this aspect. The adjective "debug" focuses on tuning parameters. But overall, this is a very good term (especially from the point of view of the Russian language) and if it had occurred to me earlier, I would use it instead of the term "validation sample".
Choose a validation and test sample so that it (except for the selection of parameters) reflects the data you expect to receive in the future and you want your algorithm to work well on them.
In other words, your test sample should not be just 30% of the available data, especially if you expect data to come in the future (photos from mobile phones) will be different in nature from your training sample (photos from the web). sites).
If you have not yet launched your mobile application, you may not have users, and as a result, there may not be available data reflecting the combat data that your algorithm should handle. But you can try to approximate them. For example, ask your friends to take photos of cats using mobile phones and send them to you. After launching your application, you will be able to update your validation and test samples using up-to-date user data.
If you do not have the opportunity to obtain data that approximate those that users will download, you can probably try to start using photos from websites. But you should be aware that this carries the risk that the system will work poorly with combat data (its generalizing ability will not be enough for them).
The development of validation and test samples requires a serious approach and thorough reflection. Do not initially postulate that the distribution of your training set should be exactly the same as the distribution of the test sample. Try to choose test cases in such a way that they reflect the distribution of the data on which you want your algorithm to work well in the long run, and not the data that you have at your disposal during the formation of the training set.
6. Validation and test samples should have the same distribution.

Suppose your cat photographic application data are segmented into four regions that correspond to your largest markets: (i) USA, (ii) China, (iii) India, (iv) Other.
Suppose we formed a validation sample from data obtained from the American and Indian markets, and a test sample based on Chinese and other data. In other words, we can randomly assign two segments to get a validation sample and two others to get a test sample. Right?
After you have determined the validation and test samples, your team will focus on improving the performance of the algorithm on the validation sample. Thus, a validation sample should reflect the tasks that are most important in advancing the solution — the algorithm should work well in all four geographic segments, and not only in two.
The second problem arising from the different distributions of validation and test samples is that it is likely that your team will develop something that will work well on a validation sample only to find out that it produces poor quality on a test sample. I have watched a lot of frustration and wasted effort because of this. Avoid this happening to you.
For example, suppose your team has developed a system that works well on a validation sample, but does not work on a test sample. If your validation and test samples are obtained from the same distribution, you [get a very clear diagnosis of that] can easily diagnose what went wrong: your algorithm has retrained on a validation sample. An obvious treatment for this problem is to use more data for validation sampling.
But if validation and test samples are obtained from different data distributions, then the possible reasons for the poor performance of the algorithm are less obvious.
- You have received a retrained algorithm on validation sampling.
- The test sample is more complex for the algorithm than the validation one. Your algorithm is already working as well as possible and no significant quality improvement is possible.
- A test sample is not necessarily more complex, it may just be different, not validation. And what works well for a validation sample simply does not give good quality for the test. In this case, a large number of your work to improve the quality of the algorithm on the validation sample will be in vain.
Working on machine learning applications is pretty hard. Having different test and validation samples, we are confronted with additional uncertainty - whether the improvements in the performance of the algorithm on the validation sample lead to an improvement in its performance on the test sample. If the distributions of test and validation samples do not match, it is difficult to understand what improves the quality of the algorithm and what hinders its improvement, and as a result, it becomes difficult to prioritize the work.
If you are working on a problem posed to you by an external customer, the one who formulated it could give you validation and test samples from different data distributions (you cannot change this). In this case, success is more likely than experience will be of greater importance for the quality of your algorithm, the opposite is true if the validation and test samples have the same distribution. This is a serious research problem - to develop learning algorithms that will train on one data distribution and should work well on another. But if your task is to develop a specific application, based on machine learning, rather than research in this area, I recommend trying to choose validation and test samples that have the same data distribution. Working with such samples will make your team more efficient.
7. How large should validation and test samples be?
Validation sampling should be sufficient to determine the differences between the algorithms that you experience. For example, if Classifier A has an accuracy of 90.0% and Classifier B has an accuracy of 90.1%, in this case, it is impossible to detect this difference of 0.1% in a validation sample consisting of 100 examples.
Author's note: In theory, one can check whether the change in the quality of the algorithm's work with a change in the size of a validation sample is of statistical significance. In practice, most teams don’t worry about it (if it’s not about publishing academic results), and I usually don’t find it useful to use tests of statistical significance to evaluate intermediate progress when working on an algorithm.
For mature and important applications — for example, adware, Internet search, and advisory services, I met teams that were highly motivated to fight for even a 0.01% improvement, as this directly affects the company's profits. In this case, the validation sample must be much more than 10,000, in order to detect even smaller improvements.
What can be said about the size of the test sample? It should be big enough to get high confidence in the quality of your system. One popular heuristic is the use of 30% of the training data available for a test sample. This works well if you have a small number of examples at your disposal, say from 100 to 10,000 examples. But in today's era of big data, when machine learning has tasks that sometimes have more than a billion examples, the proportion of data used for test and validation samples is reduced, even if the absolute number of examples grows in these samples. There is no need to use overly large validation / test samples, beyond what is needed to assess the performance of your algorithms.
8. Establish a one-parameter quality metric for your team to optimize.
Classification accuracy is an example of a one-parameter quality metric: you run your classifier on a validation sample (or on a test one), and you get one digit indicating how many examples are classified correctly. According to this metric, if Classifier A shows 97% accuracy, and Classifier B shows 90%, we consider Classifier A to be more preferable.
For contrast, consider the accuracy metric (precision) and completeness (recall), which are not one-parameter. It gives two numbers to evaluate your classifier. This multiparameter metric is more difficult to use for comparing algorithms. Suppose your algorithm shows the following results:
| Classifier | Precision | Recall |
|---|---|---|
| BUT | 95% | 90% |
| AT | 98% | 85% |
In this example, none of the classifiers clearly surpasses the other, so it is impossible to immediately select one of them.
| Classifier | Precision | Recall | F1 score |
|---|---|---|---|
| BUT | 95% | 90% | 92.4% |
Author's note: The accuracy (precision) of the cat classifier assesses the proportion of photographs in the validation (test) sample, in which cats are actually depicted in the classified ones, as an image of cats. The completeness (recall) shows the percentage of all images with cats in the validation (test) sample, which are correctly classified as the image of cats. , .
, , , , . . , (accuracy) , .
, , . , . F1 , , .
: F1 , . https://en.wikipedia.org/wiki/F1_score , « » , 2/((1/Precision)+(1/Recall)).
| Classifier | Precision | Recall | F1 score |
|---|---|---|---|
| BUT | 95% | 90% | 92.4% |
| B | 98% | 85% | 91.0% |
, . .
, , : (i) , (ii) , (iii) (iv) . . , . .
9.
.
, . :
| Classifier | Accuracy | Speed |
|---|---|---|
| BUT | 90% | 80 |
| B | 92% | 95 |
| WITH | 95% | 1500 |
, , [] — 0.5*[] , .
: -, , «». , 100 . , . (satisficing) — , , 100 . .
N , ( - , ), , , N-1 . . . , . (N-) , . , , , .
, , « », ( , ). , Amazon Echo «Alexa»; Apple Siri «Hey Siri»; Android «Okay, Google»; Baidu «Hello Baidu». false-positive — , , false-negative — . false-negative ( ) false positive 24 ( ).
.
10
, . - . , :
- ,
- ( )
- , . ( !) , .
. , . : , , .
, , . , - , , . ! , 95.0% 95.1%, 0.1% () . 0.1%- . , , ( ) , , .
11 (dev/test sets)
, , .
, . - , . , . , . , .
, dev/test , , . , + A , B, , , , dev/test .
, - :
1. , , dev/test
, dev/test . , , , . dev/test , , . dev/test , .

2. (dev set)
, (dev set) . , . , (dev set) , (test set), , . .
, , , , . , - , , . , , ( , , , , ).
3. - ,
, , . , . , , . , , , , . ?
, , , , . . . , , . , , , .
dev/test . dev/test . , dev/test , ! , .
12 : (development)
- dev test , , , . .
- (dev test sets) ,
- . , , ( ) .
- : , .
- dev/test , , .
- , dev/test , , . , .
- 70% 30% , ; dev / test , 30% .
- , : (i) (dev set), ( dev set) . (ii) , , () (dev / test sets), (dev / test sets), . (iii) , , .
13 ,
. :
- , . , : , ,
- / , , ,
- and so on
- , . , , .
. , , .
: , AI , , . .
«» , , , : , , . , .
14 : (dev set examples)

, . , !
, . , . ?
, , . , .
, :
- 100 (dev set), . . . , .
- , .
, « ». , , , 5% , , , , 5% . , 5% «» ( ) . , 90% (10% ), , 90.5% ( 9.5%, 5% , 10% )
, , 50% , , . 90% 95% (50% 10% 5%)
. .
, . , . - , , , . : , , , .
Manual checking of 100 samples from the sample is not long. Even if you spend one minute on the image, the entire check will take less than 2 hours. These two hours can save you a month of wasted effort.
')
Source: https://habr.com/ru/post/419757/
All Articles