ClassicAI genre: ML is looking for himself in poetry
 Now in the press often there are news like "AI learned to write in the style of the author X", or "ML creates art." Looking at it, we decided - it would be great if these loud statements could be verified in practice.
Now in the press often there are news like "AI learned to write in the style of the author X", or "ML creates art." Looking at it, we decided - it would be great if these loud statements could be verified in practice.Is it possible to arrange a bots fighting for writing poems? Is it possible to make a clear and repeatable competitive story out of this? Now you can say for sure that this is possible. And how to write your first algorithm for generating poems, read on.
Article layout
1. ClassicAI
The task of the participants
Under the terms of the competition, participants need to build a model that generates poems on a given topic in the style of one of the Russian classics. The theme and the author are served as models for input, and a poem is expected at the output. Full description is in the repository of the competition.
')
Subject conditions are mild: it can be a short sentence, a phrase or a few words. The only limitation is on the size: not more than 1000 characters. The topics on which algorithms will be tested will be compiled by experts. Some of the topics will be open and publicly available, but a hidden set of topics will be used to determine the best algorithm.
The global idea of the competition is this: for any poem, you can make a brief summary of several words. Let's show by example.
If you take an excerpt from "Eugene Onegin" A.S. Pushkin :
"... That year the autumn weatherThen briefly, the contents of it can fit in "Tatiana sees the first snow in the window." And then the ideal poetic model on this entry will give something very close to the original.
It was a long time in the yard
Waiting for winters, waiting for nature.
Snow fell only in January
On the third in the night. Waking up early
The window saw Tatiana
In the morning the yard turned white,
Curtains, roofs and fence,
On the glass light patterns,
Trees in winter silver,
Forty fun on the yard
And gently lined mountains
Winters are a brilliant carpet.
Everything is bright, everything is white all around ... ”1823–1830
For training in this competition it is proposed to dataset from more than 3000 works of five famous Russian poets:
1. Pushkin
2. Yesenin
3. Mayakovsky
4. Block
5. Tyutchev
The algorithm must be written so that it generates quickly enough and has the necessary interface. The speed can be equal to the power average modern PC. The interface and limitations are described in detail in the "Decision Format" section.
In order to be able to track the progress of their decisions, as well as to compare them with other decisions of the participants, the markup of solutions through the chat bot will be held throughout the competition. The results of the algorithms will be evaluated by two criteria:
- The quality of versification and compliance with the style of a given classical poet
- Completeness of the disclosure of a given topic in a poem
For each criterion, a 5-point scale will be provided. The algorithm will have to write poems for each topic from the test set. The topics on which algorithms will be tested will be compiled by experts. Some of the topics will be open and publicly available, but a hidden set of topics will be used to identify the best algorithm.
The poem received as a result of the algorithm may be rejected for the following reasons:
- generated text is not a poem in Russian
- generated text contains obscene language
- generated text contains intentionally offensive phrases or subtext
Competition program
Unlike many, in this competition there is only one online stage: from 30.07 to 26.08.
During this period, you can send solutions daily with the following restrictions:
- no more than 200 decisions during the competition
- no more than 2 successful decisions per day
- do not take into account the daily limit of the decision, the check of which ended with an error
The prize fund corresponds to the complexity of the task: the first three places will receive 1,000,000 rubles!
2. Approaches to the creation of generators of poetry
As has already become clear, the task is not trivial, but not new. Let's try to figure out how the researchers approached this problem earlier? Let's look at the most interesting approaches to the creation of generators of poems of the past 30 years.
1989
In the journal Scientific American N08, 1989 , an article by A.K. Dyudni "Computer tries his hand at prose and poetry." We will not retell the article, there is a link to the full text, we just want to draw your attention to the description of POETRY GENERATOR from Rosemary West.
This generator was fully automated. At the core of this approach is a large dictionary, phrases from which are chosen randomly, and phrases are formed from them according to a set of grammatical rules. Each line is divided into parts of the sentence, and then it is randomly replaced by other words.
This generator was fully automated. At the core of this approach is a large dictionary, phrases from which are chosen randomly, and phrases are formed from them according to a set of grammatical rules. Each line is divided into parts of the sentence, and then it is randomly replaced by other words.
1996
More than 20 years ago, a graduate of a well-known Moscow university defended a diploma on the topic “Linguistic modeling and artificial intelligence”: the author is Leonid Kaganov . Here is a link to the full text.
By 1996, such generators had already been written:
The main advantages are the following:
Algorithm and code can be read here.
"Linguistic modeling and artificial intelligence" - so it sounds
the name of my topic. “A program that composes poetry,” I reply to
questions of friends. “But do you already have such programs?” They tell me. “Yes - I answer, - but mine differs in that it does not use the original templates.”
(c) Kaganov L.A.
By 1996, such generators had already been written:
- BRED.COM creating a pseudoscientific phrase
- TREPLO.EXE generating a fun literary text
- POET.EXE, composing poems with a given rhythm
- DUEL.EXE
“For example, in POET.EXE there is a dictionary of words with accented accents and some other information about them, as well as a rhythm is set and it is indicated which strings to rhyme (for example, 1 and 4). And all these programs have one common feature - they use templates and pre-prepared dictionaries. ”
The main advantages are the following:
- uses associative experience
- produces rhyme independently
- has the possibility of thematic writing
- allows you to set any rhythm of the verse
Algorithm and code can be read here.
2016
Scientists from China generate poems in their own language. They have a live project repository that can be useful in the current competition.
In short, it works like this ( link to the source of the image ):
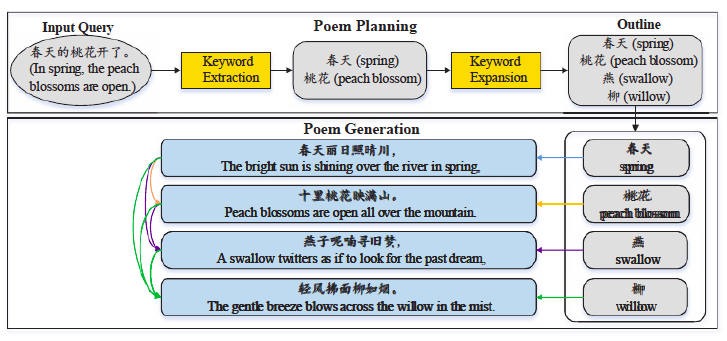
Also in 2016, another group presented its development of Hafez (repository here ).
This generator “composes” poems on a given topic using:
Their algorithm ( link to image source ):
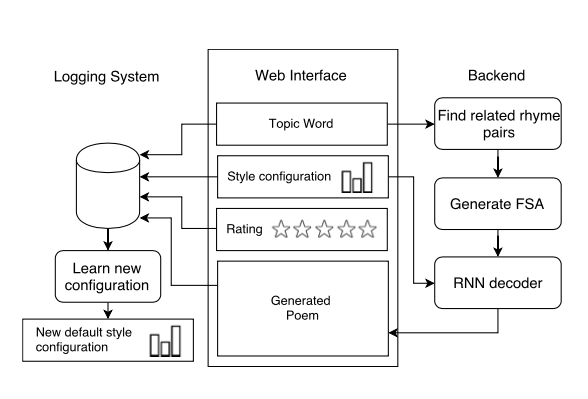
They taught the algorithm not only in English, but also in Spanish. They promise that everything should work almost everywhere. The statement is quite loud, so we recommend that you treat with caution.
"Chinese Poetry Generation with Planning Neural Network"
Scientists from China generate poems in their own language. They have a live project repository that can be useful in the current competition.
In short, it works like this ( link to the source of the image ):
Generating Topical Poetry
Also in 2016, another group presented its development of Hafez (repository here ).
This generator “composes” poems on a given topic using:
- Dictionary with stress
- Related words
- Rhyming words from a set of words on the topic
- Finite-state acceptor (FSA)
- Choosing the best path through FSA using RNN
Their algorithm ( link to image source ):
They taught the algorithm not only in English, but also in Spanish. They promise that everything should work almost everywhere. The statement is quite loud, so we recommend that you treat with caution.
2017
Finally, I want to mention a very detailed article on Habré "How to teach your neural network to generate poems . " If you have never been involved in such models, then you are here. There is a poem generator on neuron points: about language models, N-gram language models, about the assessment of language models, about how to grind architecture and modify the input and output layers.
For example, the morphological markup is added to the word ( link to the source of the picture ):

That article was written jointly with Ilya Gusev, who has a library for analyzing and generating poems in Russian and the Russian poetry corpus .
For example, the morphological markup is added to the word ( link to the source of the picture ):
That article was written jointly with Ilya Gusev, who has a library for analyzing and generating poems in Russian and the Russian poetry corpus .
3. Programming an artificial poet
An example of a simple poetic generator
Competition on the one hand may seem rather difficult, but for him it is quite possible to make a simple, but working baseline .
According to the condition, the author's identifier (author_id) and the text of the topic (seed) arrive at the input of this program, in response to this the model must return the poem.
Let's try to formalize the theme so that it can be easily operated with within a certain vector semantic space. The easiest way out of this is to get the semantic vector of each word (for example, Word2Vec) and then average them.
Thus, we get a kind of “seed2vec”, which allows us to translate the theme into a vector.
In fact, here opens a wide topic for research, because The task of identifying a topic has been confronting scientists for quite some time, here are just a few examples:
- Isolation of topics through LDA
- lda2vec
- sent2vec
- WMD
Now, you need to understand how author_id is used to generate a poem in the style of this author.
Here, the idea is no less simple: let's take the author's random poem from the corpus of verses, after which we will replace each word with another, which is most consonant with the original (it has the same number of syllables, the same stress, and the last three letters are most similar to the original by Levenshtein) and it has the most similar vector with the theme vector. For example, for the “Football” theme and the “And glowed like amber” line, the output line could be “A was played as a goalkeeper”. Thus, we get a kind of text styling.
A dataset was used as a base for replacement words, which contains small paragraphs of Wikipedia texts (a description of its use can be found in the baseline code on GitHub).
After such processing, there will be texts that will outwardly resemble the verses of the author, but at the same time contain some topic that the author has not laid.
Baseline work result:
Topic: Physics
Stylistics: Block
lead and bismuth units
buffalo ancient nonlinear environments
i'm on a particle board kelvin
your phenomena your scientific after
faraday seville cockroach
his Tver now invented
Wednesday phonon facet of
positron ghost school smoke
Subject: Math
Stylistics: Block
like a circle of leibniz among ideas
crooked and school to learn
but flock herd in creativity learn
curve for examples brain kids
curves taken swimmer knows from goba
and in the plank will pass and the court will be held in the Senate
than the daughter of the rut the more ancient goba
and surya endure
swimmer all shadow learns over Euclid
title is published and quota
masters he stapling labor
Professor training joke
Obviously, baseline is not perfect, that's why it is baseline.
You can easily add a few features to help improve the generation and raise you at the top:
- It is necessary to remove repeated words, because rhyming a word to itself is not healthy for a good poet.
- Now the words are not consistent with each other, because we do not use information about parts of speech and cases of words
- You can use a richer corpus of words, such as a wikipedia dump.
- The use of other embendings can also improve, for example, FastText works not at the word level, but at the n-gram level, which allows it to make embending for unknown words.
- Use IDF as a weight when weighing words to calculate the theme vector.
Here you can add many more points, at your discretion.
Preparation of the decision for sending
After the model is trained, it is necessary to send the algorithm code packed in a ZIP archive to the testing system.
Solutions run in isolated environments using Docker, time and resources for testing are limited. The solution must meet the following technical requirements:
It should be implemented as an HTTP server available on port 8000, which responds to two types of requests:
GET /ready The request must be answered with the code 200 OK in case the solution is ready to work. Any other code means that the solution is not ready yet. The algorithm has a limited time for preparation for work, during which you can read data from a disk, create the necessary data structures in RAM.
POST /generate/<poet_id> Request for poem generation. The ID of the poet, in the style of which you want to write, is listed in the URL The content of the request is JSON with a single seed field containing the subject line:
{"seed": " "} In response, it is necessary to provide JSON with the generated composition in the poem field in the allotted time:
{"poem": " \n \n..."} The request and response must have Content-Type: application / json. It is recommended to use UTF-8 encoding.
The solution container is launched under the following conditions:
- resources available to the solution:
- 16 GB of RAM
- 4 vCPU
- GPU Nvidia K80
- the solution does not have access to Internet resources
- shared data sets are available to the solution in the / data / directory
- preparation time for work: 120 seconds (after which the / ready request must be answered with code 200)
- time for one query / generate /: 5 seconds
- the solution should take HTTP requests from external machines (not only localhost / 127.0.0.1)
- when testing requests are made sequentially (no more than 1 request at the same time)
- maximum size of the packaged and unpacked archive with the solution: 10 GB
The generated poem (poem) must satisfy the format:
- verse size - from 3 to 8 lines
- each line contains no more than 120 characters
- lines are separated by \ n
- blank lines are ignored.
The theme of the composition (seed) does not exceed 1000 characters in length.
When testing, only the styles of 5 selected poets listed above are used.
- 16 GB of RAM
- 4 vCPU
- GPU Nvidia K80
- the solution does not have access to Internet resources
- shared data sets are available to the solution in the / data / directory
- preparation time for work: 120 seconds (after which the / ready request must be answered with code 200)
- time for one query / generate /: 5 seconds
- the solution should take HTTP requests from external machines (not only localhost / 127.0.0.1)
- when testing requests are made sequentially (no more than 1 request at the same time)
- maximum size of the packaged and unpacked archive with the solution: 10 GB
The generated poem (poem) must satisfy the format:
- verse size - from 3 to 8 lines
- each line contains no more than 120 characters
- lines are separated by \ n
- blank lines are ignored.
The theme of the composition (seed) does not exceed 1000 characters in length.
When testing, only the styles of 5 selected poets listed above are used.
Detailed information on sending the solution to the system with analysis of the most frequent errors is available here .
4. Hackathon platform
The platform with all the necessary information on this contest is on classic.sberbank.ai . Detailed rules can be found here . At the forum, you can get an answer both on the task and on technical issues if something goes wrong.

Creative competitions ML models are not easy. Many have come up to the task of generating poetry, but there is still no significant breakthrough. Already, on our classic.sberbank.ai platform, participants from all over Russia are competing to solve this complex task. We hope that the decisions of the winners will surpass all the decisions created earlier!
5. References
useful links
AI Classic Hackathon Platform
In the World of Science - Computer tries its hand at prose and poetry
Hafez - Poetry Generation
Kaganov L.A. "Linguistic design in artificial intelligence systems"
N + 1 "Artificial Pushkin"
Generating Poetry with PoetRNN
The teenager wrote an artificial intelligence that writes poetry
“Poems” of Google’s artificial intelligence hit the net
Cyber poetry and cyber prose: just a little artificial intelligence
In the World of Science - Computer tries its hand at prose and poetry
Hafez - Poetry Generation
Kaganov L.A. "Linguistic design in artificial intelligence systems"
N + 1 "Artificial Pushkin"
Generating Poetry with PoetRNN
The teenager wrote an artificial intelligence that writes poetry
“Poems” of Google’s artificial intelligence hit the net
Cyber poetry and cyber prose: just a little artificial intelligence
Source: https://habr.com/ru/post/419745/
All Articles