The book Algorithms and Data Structures. Extracting Java Information
 Hi, Habr! Learn how to implement efficient algorithms based on the most important data structures in Java, and how to measure the performance of these algorithms. Each chapter is accompanied by exercises that help to consolidate the material.
Hi, Habr! Learn how to implement efficient algorithms based on the most important data structures in Java, and how to measure the performance of these algorithms. Each chapter is accompanied by exercises that help to consolidate the material.- Learn how to work with data structures, such as lists and dictionaries, understand how they work.
- Write an application that reads Wikipedia pages, parses and navigates through the resulting data tree.
- Analyze the code and learn how to predict how fast it will work and how much memory to consume.
- Write classes that implement the Map interface, use the hash table and binary search tree.
- Create a simple web search engine with your own search robot: it will index the web pages, save their contents and return the desired results.
Excerpt "Walk the tree"
In this chapter, we will look at a search engine application that we will develop throughout the remainder of the book. I (the author) describe the elements of a search engine and present the first application, a search robot, that loads and analyzes pages from Wikipedia. This chapter also presents a recursive implementation of the depth search and an iterative implementation that uses Deque from Java to implement the “last entered, first out” stack.
Search engines
A search engine such as Google Search or Bing takes a set of search terms and returns a list of web pages that are relevant to these terms. On thinkdast.com you can read more, but I will explain what you need as you progress.
')
Consider the main components of a search engine.
- Crawling data. You need a program that can load a web page, analyze it and extract text and any links to other pages.
- Indexing. We need an index that will allow you to find a search query and the pages containing it.
- Search (retrieval). A way to collect results from an index and identify pages that are most relevant to search terms is needed.
Let's start with the search robot. Its purpose is to detect and download a collection of web pages. For search engines such as Google and Bing, the challenge is to find all the web pages, but often these robots are limited to a smaller domain. In our case, we will only read pages from Wikipedia.
As a first step, we will create a search robot that reads the Wikipedia page, finds the first link, navigates to another page, and repeats the previous steps. We will use this search engine to test the Getting to Philosophy hypothesis (“Path to Philosophy”). It says:
“Clicking on the first link in lower case, in the main text of the Wikipedia article and then repeating this action for subsequent articles, you will most likely be taken to the page with the article on philosophy.”
You can view this hypothesis and its history at thinkdast.com/getphil .
Testing the hypothesis will allow you to create the main parts of the search robot, without needing to bypass the entire Internet or even the entire Wikipedia. And I think this exercise is quite interesting!
In several chapters we will work on an indexer, and then proceed to the search engine.
HTML parsing
When you load a webpage, its content is written in HyperText Markup Language (HTML). For example, the following is the simplest HTML document:
<!DOCTYPE html> <html> <head> <title>This is a title</title> </head> <body> <p>Hello world!</p> </body> </html> The phrases This is a title (“This is the title”) and Hello world! ("Hello world!") - text that is actually displayed on the page; other elements are tags indicating how the text should be displayed.
When loading the page, our robot needs to analyze the HTML code in order to extract text and find links. To do this, we will use jsoup, an open source Java library for loading and parsing (parsing) HTML.
The result of HTML parsing is a DOM (Document Object Model) tree containing document elements, including text and tags.
A tree is a related data structure consisting of vertices that represent text, tags, and other document elements.
The relationship between the vertices is determined by the structure of the document. In the previous example, the first node, called the root, is a tag that includes references to the two vertices it contains and; these nodes are children of the root node.
A node has one child node and a node has one child node.
(paragraph, from the English. paragraph). In fig. 6.1 presents a graphic image of the tree.
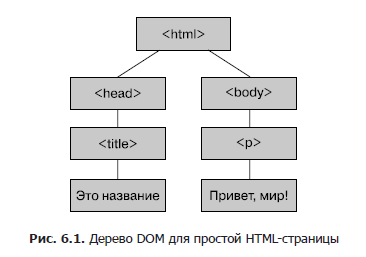
Each vertex includes links to its child nodes; In addition, each node contains a link to its parent, so you can move up and down the tree from any node. A DOM tree for real pages is usually more complicated than the example described.
Most browsers have tools for checking the DOM of the page you are viewing. In Chrome, you can right-click on any part of the webpage and select View Code from the menu that appears. In Firefox, you can right-click and select Explore item from the context menu. Safari provides a Web Inspector tool, which is located on the site thinkdast.com/safari . Instructions for Internet Explorer can be found by clicking on the link: thinkdast.com/explorer .
In fig. 6.2 shows a screenshot showing a DOM tree for the Wikipedia page on Java . The selected element is the first paragraph of the main text of the article, which is contained in the <div> element with id = "mw-content-text". We will use this item identifier to determine the main text of each article we download.
Jsoup application
The jsoup library makes it easy to load and analyze web pages and navigate the DOM tree. For example:
String url = "http://en.wikipedia.org/wiki/Java_(programming_language)"; // Connection conn = Jsoup.connect(url); Document doc = conn.get(); // Element content = doc.getElementById("mw-content-text"); Elements paragraphs = content.select("p"); The Jsoup.connect element accepts a URL as a string and establishes a connection to a web server; The get method loads HTML code, parses it, and returns a Document object, which is a DOM.

This object includes methods for navigating the tree and selecting nodes. In fact, it provides so many methods that it can be confusing. The following example demonstrates two ways to select nodes.
- getElementByld accepts a string type parameter and searches for a tree for an element with the corresponding id field. When he finds it, he chooses a node <div id = "mw-content-text" lang = "en" dir = "ltr" class = "mw-content-ltr"> that appears on every Wikipedia page to identify the element <div> containing the main text of the page, unlike the side navigation bar and other elements.
- select accepts a String, traverses the tree, and returns all elements with tags matching the String. In this example, it returns all the paragraph tags that appear in the content. The return value is an object of type Elements.
Before proceeding, you must review the documentation for these classes to know what actions they can perform. The most important classes are Element, Elements and Node, which you can read about by clicking on the links thinkdast.com/jsoupelt , thinkdast.com/jsoupelts and thinkdast.com/jsoupnode .
The Node class is a vertex in the DOM tree. There are several subclasses that extend Node, including Element, TextNode, DataNode, and Comment. The Elements class is a collection of Element type objects.
In fig. Figure 6.3 is a UML class diagram showing the relationships between them. A line with an empty arrow indicates the expansion of one class to another. For example, this diagram indicates that Elements extends an ArrayList. We will return to the UML class diagrams in the section of chapter 11 of the same name.

DOM iteration
In order to make life easier for you, I provide a WikiNodelterable class that allows you to walk through the DOM tree. Below is an example that shows how to use this class:
Elements paragraphs = content.select("p"); Element firstPara = paragraphs.get(0); Iterable<Node> iter = new WikiNodeIterable(firstPara); for (Node node: iter) { if (node instanceof TextNode) { System.out.print(node); } } This example starts from the point at which the previous one stopped. It selects the first paragraph in paragraphs and then creates a WikiNodeIterable class that implements the Iterable interface. This class performs a depth search, creating nodes in the order in which they appear on the page.
In the current example, we display the Node only if it is a TextNode, and ignore its other types, in particular, objects of type Element that represent tags. The result is simple HTML paragraph text without any markup. His conclusion:
Java is a concurrent, class-based, object-oriented, [13] and specifically designed ...
Java is a universal computer programming language that is an object-oriented language based on classes, with the possibility of parallel programming [13] and specially designed ...
Depth search
There are several ways to intelligently traverse a tree. We start with depth search (depth-first search, DFS). The search starts from the root of the tree and selects the first child node. If the latter has children, then the first child node is selected again. When a peak without children comes across, you need to return, moving up the tree to the parent node, where the next child is selected, if there is one. Otherwise, you need to return again. When the last child of the root is examined, the traversal is completed.
There are two generally accepted ways to implement depth-first search: recursive and iterative. Recursive implementation is simple and elegant:
private static void recursiveDFS(Node node) { if (node instanceof TextNode) { System.out.print(node); } for (Node child: node.childNodes()) { recursiveDFS(child); } } This method is called for each Node in the tree, starting from the root. If the Node is a TextNode, then its contents are printed. If Node has children, it calls the recursiveDFS for each of them in order.
In the current example, we print the contents of each TextNode before visiting its child nodes, that is, it is an example of a direct (pre-order) walk. You can read about direct, reverse (post-order) and symmetrical (in-order) traversal by clicking on the link thinkdast.com/treetrav . The traversal order does not matter for this application.
When performing recursive calls, recursiveDFS uses a call stack (see thinkdast.com/callstack ) to track the child vertices and process them in the correct order. Alternatively, you can use the stack data structure to track the nodes yourself; this will avoid recursion and iterate around the tree.
Java stacks
Before explaining the iterative version of the depth search, I’ll look at the stack data structure. We begin with a general stack concept, and then talk about two Java interfaces that define stack methods: Stack and Deque.
A stack is a list-like data structure: a collection that maintains the order of the elements. The main difference between the stack and the list is that the first includes fewer methods. By convention, the stack provides methods:
- push, which adds an element to the top of the stack;
- pop, which deletes and returns the value of the topmost item in the stack;
- peek, which returns the topmost element of the stack without changing the stack itself;
- isEmpty, which indicates whether the stack is empty.
Since pop always returns the topmost element, the stack is also called LIFO, which means “last entered, first out” (last in, first out). An alternative to a stack is a queue that returns items in the same order in which they were added, that is, “first in, first out,” or FIFO.
At first glance, it is not clear why stacks and queues are useful: they do not provide any special features that could not be obtained from the lists; in fact, they have even fewer opportunities. So why not always use lists? There are two reasons justifying the use of stacks and queues.
1. If you limit yourself to a small set of methods (that is, a small API), then your code will be more readable and less error prone. For example, when using a list to represent a stack, you can accidentally delete an item in the wrong order. With the stack API, this error is literally impossible. And the best way to avoid mistakes is to make them impossible.
2. If the data structure provides a small API, then it is easier to implement effectively. For example, a simple way to implement a stack is a single list. Pushing an element onto the stack, we add it to the top of the list; pushing an element, we remove it from the very beginning. For a linked list, adding and removing from the beginning are operations of constant time, therefore this implementation is effective. Conversely, larger APIs are more difficult to implement effectively.
Implement the stack in Java in three ways.
1. Apply ArrayList or LinkedList. When using an ArrayList, you need to remember to add and remove from the end so that these operations are performed in constant time. You should avoid adding items to the wrong place or removing them in the wrong order.
2. Java has a Stack class that provides a standard set of stack methods. But this class is the old part of Java: it is incompatible with the Java Collections Framework, which appeared later.
3. Probably the best choice is to use one of the implementations of the Deque interface, for example, ArrayDeque.
Deque is derived from double-ended queue, which means "two-way queue." In Java, Deque provides push, pop, peek, and isEmpty methods, so you can use it as a stack. It contains other methods that are available on thinkdast.com/deque , but for now we will not use them.
Iterative depth search
The following is an iterative version of DFS, using ArrayDeque to represent a stack of Node objects:
private static void iterativeDFS(Node root) { Deque<Node> stack = new ArrayDeque<Node>(); stack.push(root); while (!stack.isEmpty()) { Node node = stack.pop(); if (node instanceof TextNode) { System.out.print(node); } List<Node> nodes = new ArrayList<Node>(node. chiidNodesQ); Collections.reverse(nodes); for (Node child: nodes) { stack.push(chiid); } } } The root parameter is the root of the tree that we want to go around, so we start by creating a stack and adding this parameter to it.
The cycle continues until the stack is empty. On each pass, a Node is pushed out of the stack. If TextNode is received, its contents are printed. Then the child vertices are added to the stack. To process descendants in the correct order, you need to push them onto the stack in the reverse order; this is done by copying the child vertices in an ArrayList, rearranging the elements in place, and then iterating the reversed ArrayList.
One of the advantages of an iterative version of depth search is that it is easier to implement it as an Iterator in Java; how to do this is described in the next chapter.
But first, a final note about the Deque interface: in addition to ArrayDeque, Java provides another implementation of Deque, our old friend LinkedList. The latter implements both interfaces: List and Deque. The resulting interface depends on its use. For example, when assigning a LinkedList object to a Deque variable:
Deqeue<Node> deque = new LinkedList<Node>(); You can apply methods from the Deque interface, but not all methods from the List interface. Assigning it to a List variable:
List<Node> deque = new LinkedList<Node>(); List methods can be used, but not all Deque methods. And assigning them as follows:
LinkedList<Node> deque = new LinkedList<Node>(); all methods can be used. But when combining methods from different interfaces, the code will be less readable and more error prone.
»More information about the book can be found on the publisher site.
» Table of Contents
» Excerpt
For Habrozhiteley a 20% discount on coupon - Java
Source: https://habr.com/ru/post/419503/
All Articles